如何在 Windows 上运行 Linux 容器
1、概述
现在能够在 Windows 10 和 Windows 服务器上运行 Docker 容器了,它是以 Ubuntu 作为宿主基础的。
想象一下,使用你喜欢的 Linux 发行版——比如 Ubuntu——在 Windows 上运行你自己的 Linux 应用。
现在,借助 Docker 技术和 Windows 上的 Hyper-V 虚拟化的力量,这一切成为了可能。
2、前置需求
你需要一个 8GB 内存的 64 位 x86 PC,运行 Windows 10 或 Windows Server。
只有加入了 Windows 预览体验计划(Insider),才能运行带有 Hyper-V 支持的 Linux 容器。该计划可以让你测试预发布软件和即将发布的 Windows。
如果你特别在意稳定性和隐私(Windows 预览体验计划允许微软收集使用信息),你可以考虑等待 2017 年 10 月发布的Windows 10 Fall Creator update,这个版本可以让你无需 Windows 预览体验身份即可使用带有 Hyper-V 支持的 Docker 技术。
你也需要最新版本的 Docker,它可以从 http://dockerproject.org 下载得到。
最后,你还需要确认你安装了 XZ 工具,解压 Ubuntu 宿主容器镜像时需要它。
3、加入 Windows 预览体验计划(Insider)
如果你已经是 Windows 预览体验计划(Insider)成员,你可以跳过此步。否则在浏览器中打开如下链接:
https://insider.windows.com/zh-cn/getting-started/
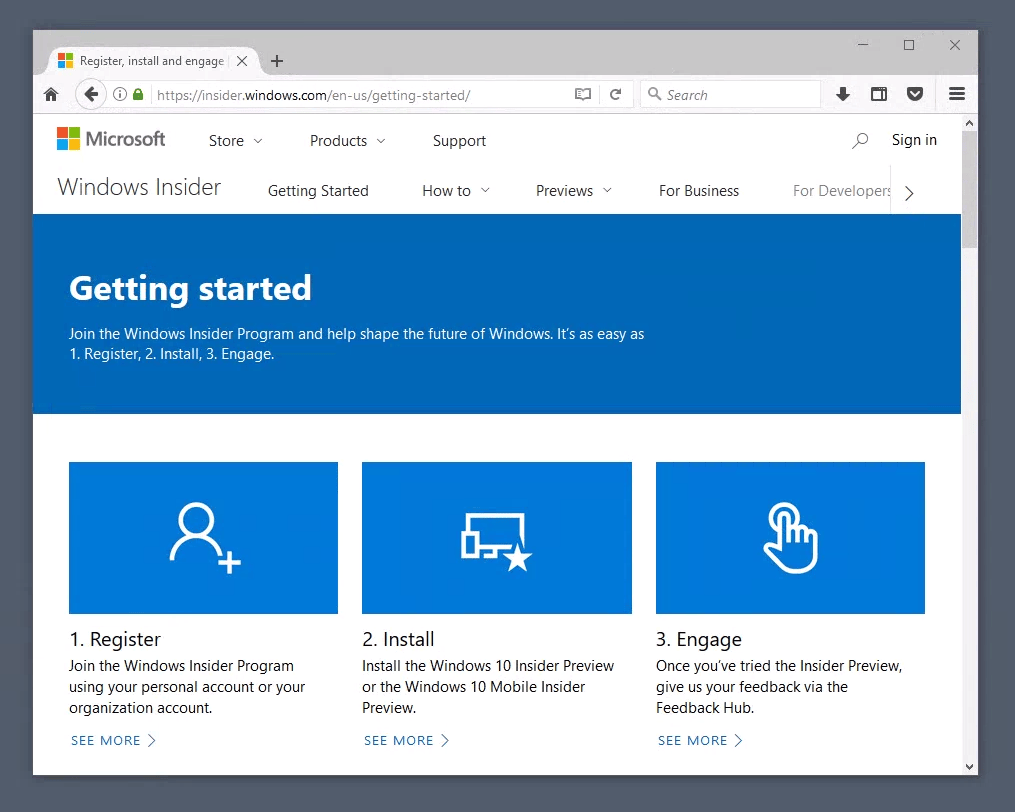
要注册该计划,使用你在 Windows 10 中的微软个人账户登录,并在预览体验计划首页点击“注册”,接受条款并完成注册。
然后你需要打开 Windows 开始菜单中的“更新和安全”菜单,并在菜单左侧选择“Windows 预览体验计划”。
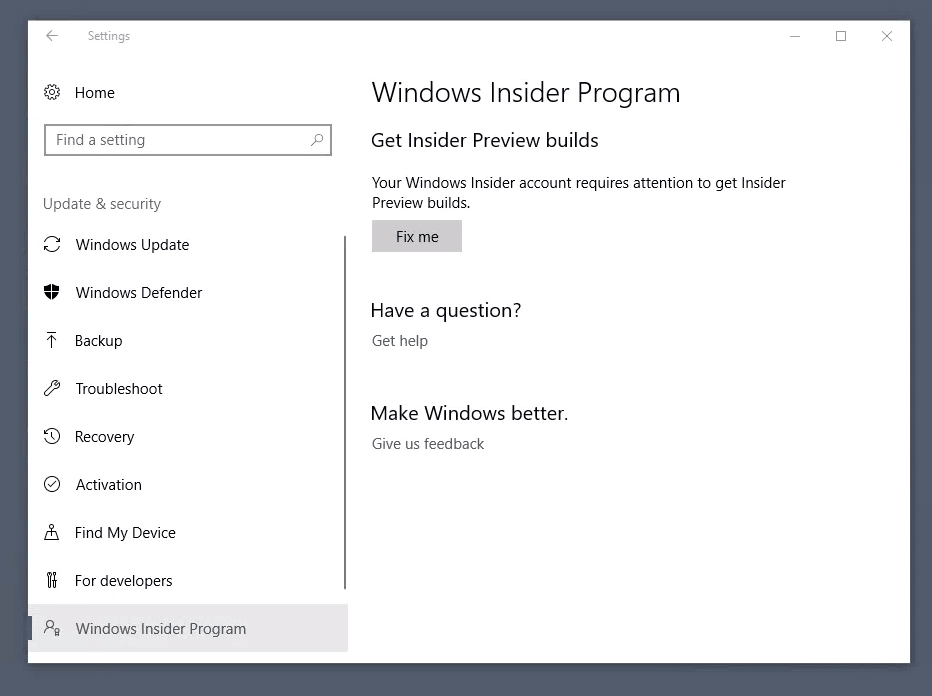
如果需要的话,在 Windows 提示“你的 Windows 预览体验计划账户需要关注”时,点击“修复”按钮。
4、 Windows 预览体验(Insider)的内容
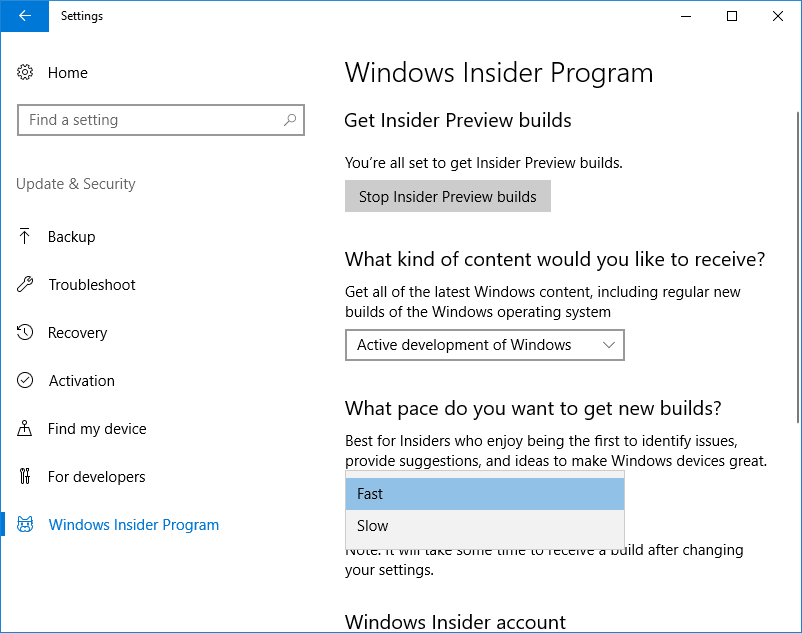
从 Windows 预览体验计划面板,选择“开始使用”。如果你的微软账户没有关联到你的 Windows 10 系统,当提示时使用你要关联的账户进行登录。
然后你可以选择你希望从 Windows 预览体验计划中收到何种内容。要得到 Docker 技术所需要的 Hyper-V 隔离功能,你需要加入“快圈”,两次确认后,重启 Windows。重启后,你需要等待你的机器安装各种更新后才能进行下一步。
5、安装 Docker for Windows
从 Docker Store 下载 Docker for Windows。
下载完成后,安装,并在需要时重启。
重启后,Docker 就已经启动了。Docker 要求启用 Hyper-V 功能,因此它会提示你启用并重启。点击“OK”来为 Docker 启用它并重启系统。

6、下载 Ubuntu 容器镜像
从 Canonical 合作伙伴镜像网站下载用于 Windows 的最新的 Ubuntu 容器镜像。
下载后,使用 XZ 工具解压:
C:\Users\mathi\> .\xz.exe -d xenial-container-hyper-v.vhdx.xz
C:\Users\mathi\>7、准备容器环境
首先创建两个目录:

创建 C:\lcow,它将用于 Docker 准备容器时的临时空间。
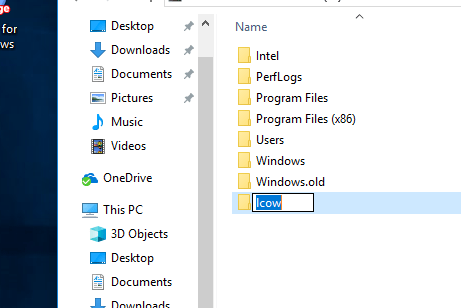
再创建一个 C:\Program Files\Linux Containers ,这是存放 Ubuntu 容器镜像的地方。
你需要给这个目录额外的权限以允许 Docker 在其中使用镜像。在管理员权限的 Powershell 窗口中运行如下 Powershell 脚本:
param(
[string] $Root
)
# Give the virtual machines group full control
$acl = Get-Acl -Path $Root
$vmGroupRule = new-object System.Security.AccessControl.FileSystemAccessRule("NT VIRTUAL MACHINE\Virtual Machines", "FullControl","ContainerInherit,ObjectInherit", "None", "Allow")
$acl.SetAccessRule($vmGroupRule)
Set-Acl -AclObject $acl -Path $Root将其保存为set_perms.ps1并运行它。
提示,你也许需要运行 Set-ExecutionPolicy -Scope process unrestricted 来允许运行未签名的 Powershell 脚本。
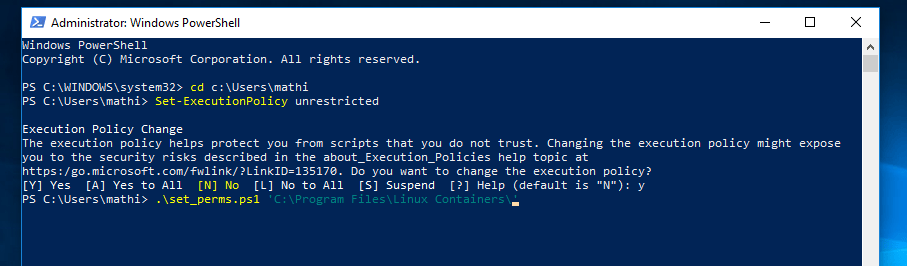
C:\Users\mathi\> .\set_perms.ps1 "C:\Program Files\Linux Containers"
C:\Users\mathi\>现在,将上一步解压得到的 Ubuntu 容器镜像(.vhdx)复制到 C:\Program Files\Linux Containers 下的 uvm.vhdx。
8、更多的 Docker 准备工作
Docker for Windows 要求一些预发布的功能才能与 Hyper-V 隔离相配合工作。这些功能在之前的 Docker CE 版本中还不可用,这些所需的文件可以从 master.dockerproject.org 下载。

从 master.dockerproject.org 下载 dockerd.exe 和 docker.exe,并将其放到安全的地方,比如你自己的文件夹中。它们用于在下一步中启动 Ubuntu 容器。
9、 在 Hyper-V 上运行 Ubuntu 容器
你现在已经准备好启动你的容器了。首先以管理员身份打开命令行(cmd.exe),然后以正确的环境变量启动 dockerd.exe。
C:\Users\mathi\> set LCOW_SUPPORTED=1
C:\Users\mathi\> .\dockerd.exe -D --data-root C:\lcow然后,以管理员身份启动 Powershell 窗口,并运行 docker.exe 为你的容器拉取镜像:
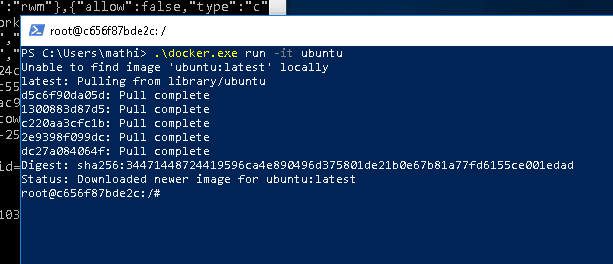
C:\Users\mathi\> .\docker.exe pull ubuntu


现在你终于启动了容器,再次运行 docker.exe,让它运行这个新镜像:
C:\Users\mathi\> .\docker.exe run -it ubuntu
恭喜你!你已经成功地在 Windows 上让你的系统运行了带有 Hyper-V 隔离的容器,并且跑的是你非常喜欢的 Ubuntu 容器。
10、获取帮助
如果你需要一些 Hyper-V Ubuntu 容器的起步指导,或者你遇到一些问题,你可以在这里寻求帮助: