Up:在几秒钟内部署无服务器应用程序

去年,我为 Up 规划了一份蓝图,其中描述了如何以最小的成本在 AWS 上为大多数构建块创建一个很棒的无服务器环境。这篇文章则是讨论了 Up 的初始 alpha 版本。
为什么关注 无服务器 ?对于初学者来说,它可以节省成本,因为你可以按需付费,且只为你使用的付费。无服务器方式是自愈的,因为每个请求被隔离并被视作“无状态的”。最后,它可以无限轻松地扩展 —— 没有机器或集群要管理。部署你的代码就行了。
大约一个月前,我决定开始在 apex/up 上开发它,并为动态 SVG 版本的 GitHub 用户投票功能写了第一个小型无服务器示例程序 tj/gh-polls。它运行良好,成本低于每月 1 美元即可为数百万次投票服务,因此我会继续这个项目,看看我是否可以提供开源版本及商业的变体版本。
其长期的目标是提供“你自己的 Heroku” 的版本,支持许多平台。虽然平台即服务(PaaS)并不新鲜,但无服务器生态系统正在使这种方案日益萎缩。据说,AWS 和其他的供应商经常由于他们提供的灵活性而被人诟病用户体验。Up 将复杂性抽象出来,同时为你提供一个几乎无需运维的解决方案。
安装
你可以使用以下命令安装 Up,查看这篇临时文档开始使用。或者如果你使用安装脚本,请下载二进制版本。(请记住,这个项目还在早期。)
curl -sfL https://raw.githubusercontent.com/apex/up/master/install.sh | sh
只需运行以下命令随时升级到最新版本:
up upgrade
你也可以通过 NPM 进行安装:
npm install -g up
功能
这个早期 alpha 版本提供什么功能?让我们来看看!请记住,Up 不是托管服务,因此你需要一个 AWS 帐户和 AWS 凭证。如果你对 AWS 不熟悉,你可能需要先停下来,直到熟悉流程。
我遇到的第一个问题是:up(1) 与 apex(1) 有何不同?Apex 专注于部署功能,用于管道和事件处理,而 Up 则侧重于应用程序、API 和静态站点,也就是单个可部署单元。Apex 不为你提供 API 网关、SSL 证书或 DNS,也不提供 URL 重写,脚本注入等。
单命令无服务器应用程序
Up 可以让你使用单条命令部署应用程序、API 和静态站点。要创建一个应用程序,你只需要一个文件,在 Node.js 的情况下,./app.js 监听由 Up 提供的 PORT'。请注意,如果你使用的是package.json,则会检测并使用start和build` 脚本。
const http = require('http')
const { PORT = 3000 } = process.env
http.createServer((req, res) => {
res.end('Hello World\n')
}).listen(PORT)
额外的运行时环境也支持开箱可用,例如用于 Golang 的 “main.go”,所以你可以在几秒钟内部署 Golang、Python、Crystal 或 Node.js 应用程序。
package main
import (
"fmt"
"log"
"net/http"
"os"
)
func main() {
addr := ":" + os.Getenv("PORT")
http.HandleFunc("/", hello)
log.Fatal(http.ListenAndServe(addr, nil))
}
func hello(w http.ResponseWriter, r *http.Request) {
fmt.Fprintln(w, "Hello World from Go")
}
要部署应用程序输入 up 来创建所需的资源并部署应用程序本身。这里没有模糊不清的地方,一旦它说“完成”了那就完成了,该应用程序立即可用 —— 没有远程构建过程。
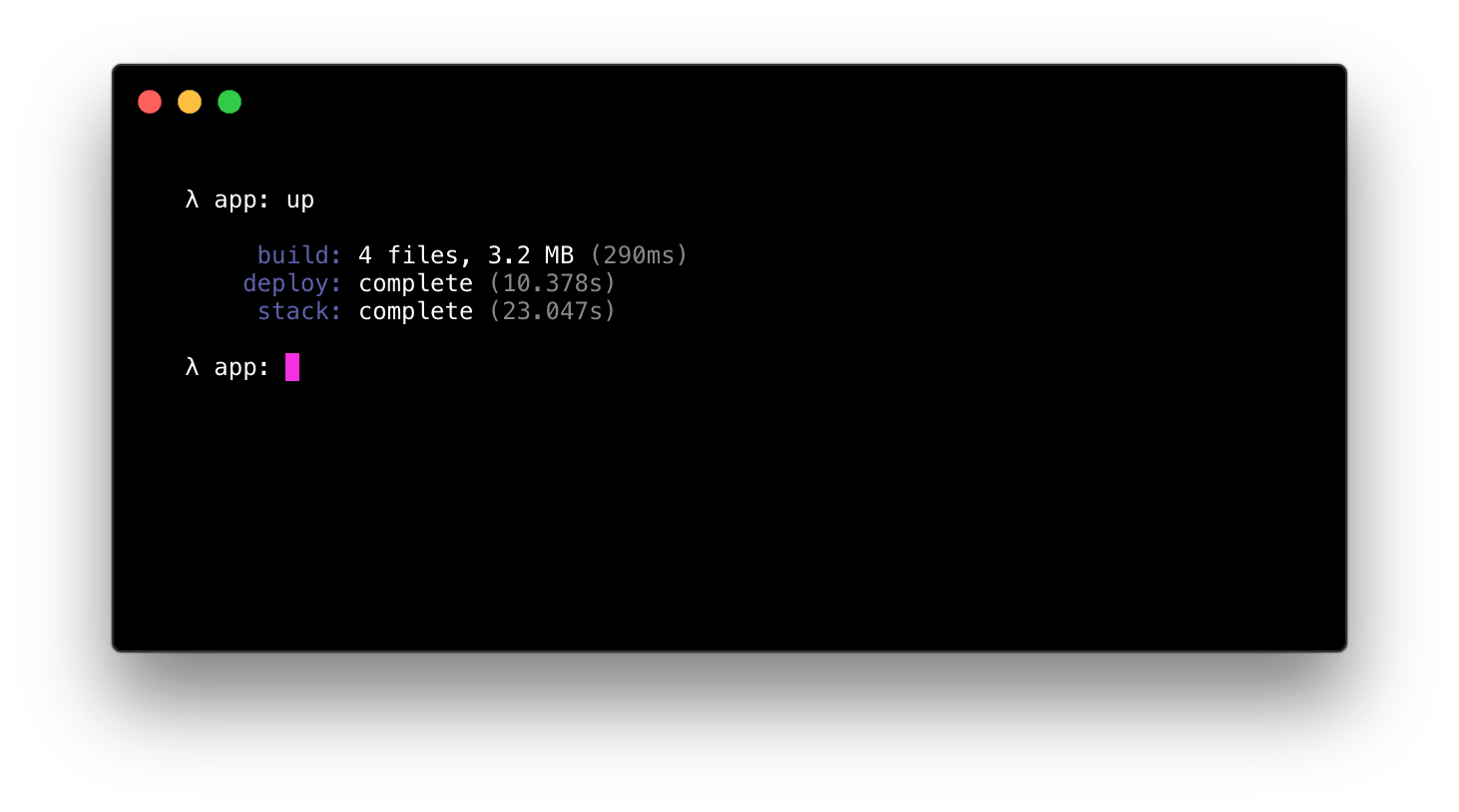
后续的部署将会更快,因为栈已被配置:
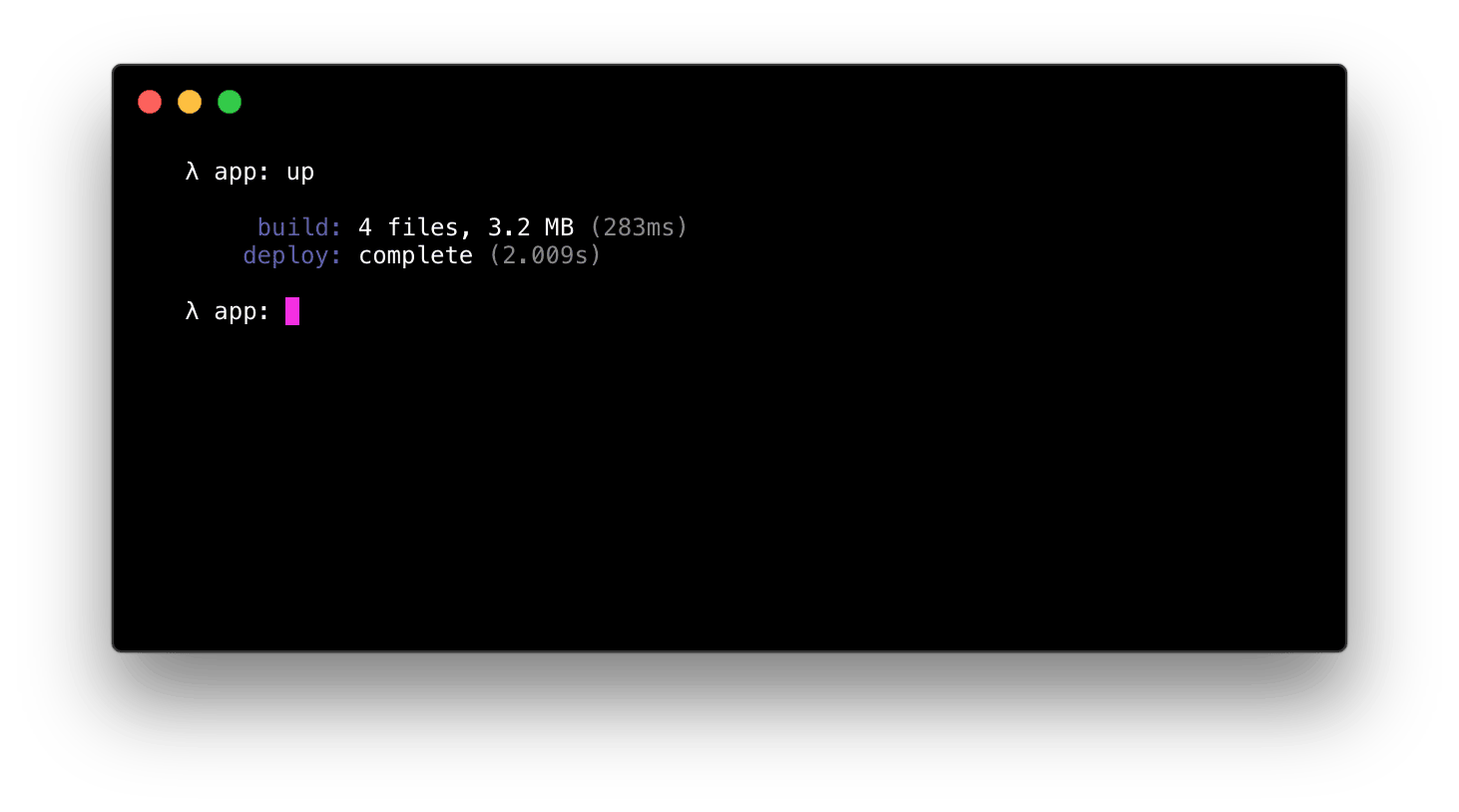
使用 up url --open 测试你的程序,以在浏览器中浏览它,up url --copy 可以将 URL 保存到剪贴板,或者可以尝试使用 curl:
curl `up url`
Hello World
要删除应用程序及其资源,只需输入 up stack delete:
例如,使用 up staging 或 up production 和 up url --open production 部署到预发布或生产环境。请注意,自定义域名尚不可用,它们将很快可用。之后,你还可以将版本“推广”到其他环境。
反向代理
Up 的一个独特的功能是,它不仅仅是简单地部署代码,它将一个 Golang 反向代理放在应用程序的前面。这提供了许多功能,如 URL 重写、重定向、脚本注入等等,我们将在后面进一步介绍。
基础设施即代码
在配置方面,Up 遵循现代最佳实践,因此对基础设施的更改都可以在部署之前预览,并且 IAM 策略的使用还可以限制开发人员访问以防止事故发生。一个附带的好处是它有助于自动记录你的基础设施。
以下是使用 Let's Encrypt 通过 AWS ACM 配置一些(虚拟)DNS 记录和免费 SSL 证书的示例。
{
"name": "app",
"dns": {
"myapp.com": [
{
"name": "myapp.com",
"type": "A",
"ttl": 300,
"value": ["35.161.83.243"]
},
{
"name": "blog.myapp.com",
"type": "CNAME",
"ttl": 300,
"value": ["34.209.172.67"]
},
{
"name": "api.myapp.com",
"type": "A",
"ttl": 300,
"value": ["54.187.185.18"]
}
]
},
"certs": [
{
"domains": ["myapp.com", "*.myapp.com"]
}
]
}
当你首次通过 up 部署应用程序时,需要所有的权限,它为你创建 API 网关、Lambda 函数、ACM 证书、Route53 DNS 记录等。
ChangeSets 尚未实现,但你能使用 up stack plan 预览进一步的更改,并使用 up stack apply 提交,这与 Terraform 非常相似。
详细信息请参阅配置文档。
全球部署
regions 数组可以指定应用程序的目标区域。例如,如果你只对单个地区感兴趣,请使用:
{
"regions": ["us-west-2"]
}
如果你的客户集中在北美,你可能需要使用美国和加拿大所有地区:
{
"regions": ["us-*", "ca-*"]
}
最后,你可以使用 AWS 目前支持的所有 14 个地区:
{
"regions": ["*"]
}
多区域支持仍然是一个正在进行的工作,因为需要一些新的 AWS 功能来将它们结合在一起。
静态文件服务
Up 默认支持静态文件服务,并带有 HTTP 缓存支持,因此你可以在应用程序前使用 CloudFront 或任何其他 CDN 来大大减少延迟。
当 type 为 static 时,默认情况下的工作目录是 .,但是你也可以提供一个 static.dir:
{
"name": "app",
"type": "static",
"static": {
"dir": "public"
}
}
构建钩子
构建钩子允许你在部署或执行其他操作时定义自定义操作。一个常见的例子是使用 Webpack 或 Browserify 捆绑 Node.js 应用程序,这大大减少了文件大小,因为 node 模块是很大的。
{
"name": "app",
"hooks": {
"build": "browserify --node server.js > app.js",
"clean": "rm app.js"
}
}
脚本和样式表插入
Up 允许你插入脚本和样式,无论是内联方式或声明路径。它甚至支持一些“罐头”脚本,用于 Google Analytics(分析)和 Segment,只需复制并粘贴你的写入密钥即可。
{
"name": "site",
"type": "static",
"inject": {
"head": [
{
"type": "segment",
"value": "API_KEY"
},
{
"type": "inline style",
"file": "/css/primer.css"
}
],
"body": [
{
"type": "script",
"value": "/app.js"
}
]
}
}
重写和重定向
Up 通过 redirects 对象支持重定向和 URL 重写,该对象将路径模式映射到新位置。如果省略 status 参数(或值为 200),那么它是重写,否则是重定向。
{
"name": "app",
"type": "static",
"redirects": {
"/blog": {
"location": "https://blog.apex.sh/",
"status": 301
},
"/docs/:section/guides/:guide": {
"location": "/help/:section/:guide",
"status": 302
},
"/store/*": {
"location": "/shop/:splat"
}
}
}
用于重写的常见情况是 SPA(单页面应用程序),你希望不管路径如何都提供 index.html,当然除非文件存在。
{
"name": "app",
"type": "static",
"redirects": {
"/*": {
"location": "/",
"status": 200
}
}
}
如果要强制实施该规则,无论文件是否存在,只需添加 "force": true 。
环境变量
密码将在下一个版本中有,但是现在支持纯文本环境变量:
{
"name": "api",
"environment": {
"API_FEATURE_FOO": "1",
"API_FEATURE_BAR": "0"
}
}
CORS 支持
CORS 支持允许你指定哪些(如果有的话)域可以从浏览器访问你的 API。如果你希望允许任何网站访问你的 API,只需启用它:
{
"cors": {
"enable": true
}
}
你还可以自定义访问,例如仅将 API 访问限制为你的前端或 SPA。
{
"cors": {
"allowed_origins": ["https://myapp.com"],
"allowed_methods": ["HEAD", "GET", "POST", "PUT", "DELETE"],
"allowed_headers": ["Content-Type", "Authorization"]
}
}
日志
对于 $0.5/GB 的低价格,你可以使用 CloudWatch 日志进行结构化日志查询和跟踪。Up 实现了一种用于改进 CloudWatch 提供的自定义查询语言,专门用于查询结构化 JSON 日志。
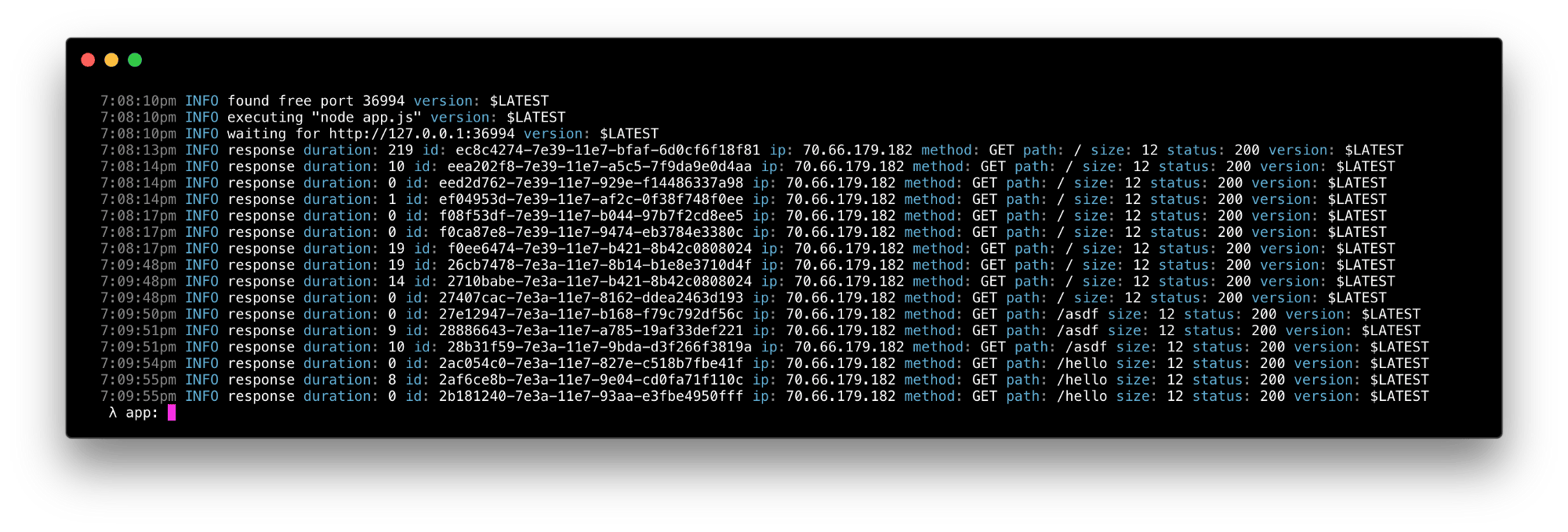
你可以查询现有日志:
up logs
跟踪在线日志:
up logs -f
或者对其中任一个进行过滤,例如只显示耗时超过 5 毫秒的 200 个 GET/HEAD 请求:
up logs 'method in ("GET", "HEAD") status = 200 duration >= 5'
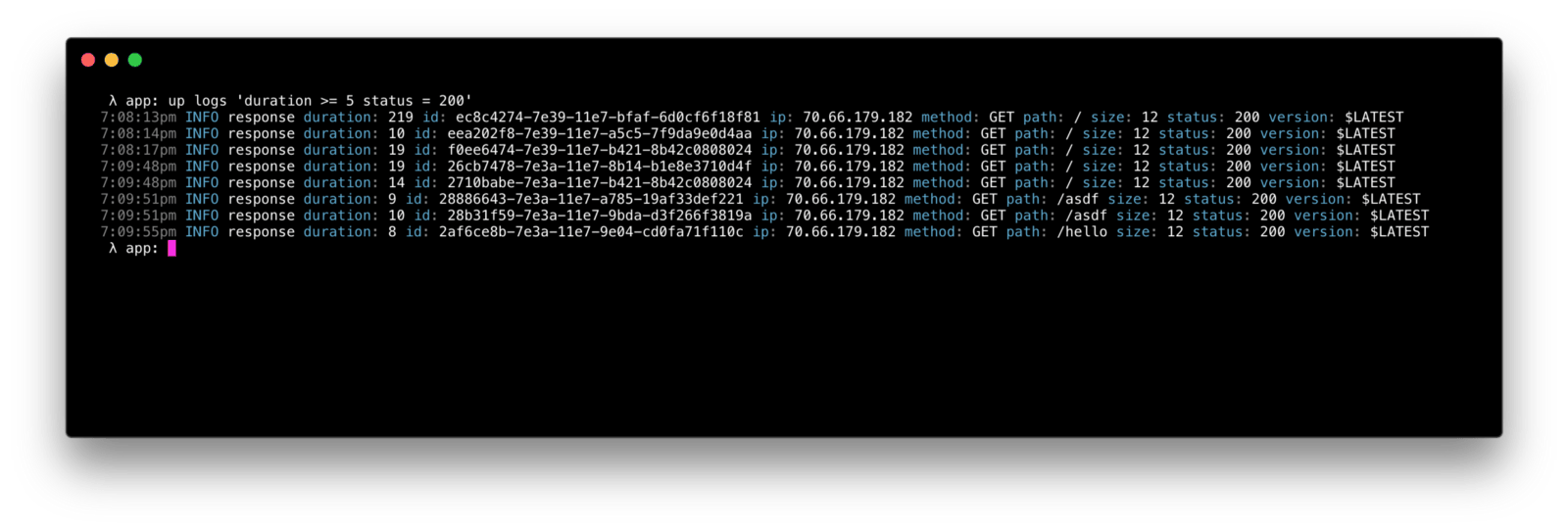
查询语言是非常灵活的,这里有更多来自于 up help logs 的例子
### 显示过去 5 分钟的日志
$ up logs
### 显示过去 30 分钟的日志
$ up logs -s 30m
### 显示过去 5 小时的日志
$ up logs -s 5h
### 实时显示日志
$ up logs -f
### 显示错误日志
$ up logs error
### 显示错误和致命错误日志
$ up logs 'error or fatal'
### 显示非 info 日志
$ up logs 'not info'
### 显示特定消息的日志
$ up logs 'message = "user login"'
### 显示超时 150ms 的 200 响应
$ up logs 'status = 200 duration > 150'
### 显示 4xx 和 5xx 响应
$ up logs 'status >= 400'
### 显示用户邮件包含 @apex.sh 的日志
$ up logs 'user.email contains "@apex.sh"'
### 显示用户邮件以 @apex.sh 结尾的日志
$ up logs 'user.email = "*@apex.sh"'
### 显示用户邮件以 tj@ 开始的日志
$ up logs 'user.email = "tj@*"'
### 显示路径 /tobi 和 /loki 下的错误日志
$ up logs 'error and (path = "/tobi" or path = "/loki")'
### 和上面一样,用 in 显示
$ up logs 'error and path in ("/tobi", "/loki")'
### 更复杂的查询方式
$ up logs 'method in ("POST", "PUT") ip = "207.*" status = 200 duration >= 50'
### 将 JSON 格式的错误日志发送给 jq 工具
$ up logs error | jq
请注意,and 关键字是暗含的,虽然你也可以使用它。
冷启动时间
这是 AWS Lambda 平台的特性,但冷启动时间通常远远低于 1 秒,在未来,我计划提供一个选项来保持它们在线。
配置验证
up config 命令输出解析后的配置,有默认值和推断的运行时设置 - 它也起到验证配置的双重目的,因为任何错误都会导致退出状态 > 0。
崩溃恢复
使用 Up 作为反向代理的另一个好处是执行崩溃恢复 —— 在崩溃后重新启动服务器,并在将错误的响应发送给客户端之前重新尝试该请求。
例如,假设你的 Node.js 程序由于间歇性数据库问题而导致未捕获的异常崩溃,Up 可以在响应客户端之前重试该请求。之后这个行为会更加可定制。
适合持续集成
很难说这是一个功能,但是感谢 Golang 相对较小和独立的二进制文件,你可以在一两秒中在 CI 中安装 Up。
HTTP/2
Up 通过 API 网关支持 HTTP/2,对于服务很多资源的应用和站点可以减少延迟。我将来会对许多平台进行更全面的测试,但是 Up 的延迟已经很好了:

错误页面
Up 提供了一个默认错误页面,如果你要提供支持电子邮件或调整颜色,你可以使用 error_pages 自定义。
{
"name": "site",
"type": "static",
"error_pages": {
"variables": {
"support_email": "[email protected]",
"color": "#228ae6"
}
}
}
默认情况下,它看上去像这样:
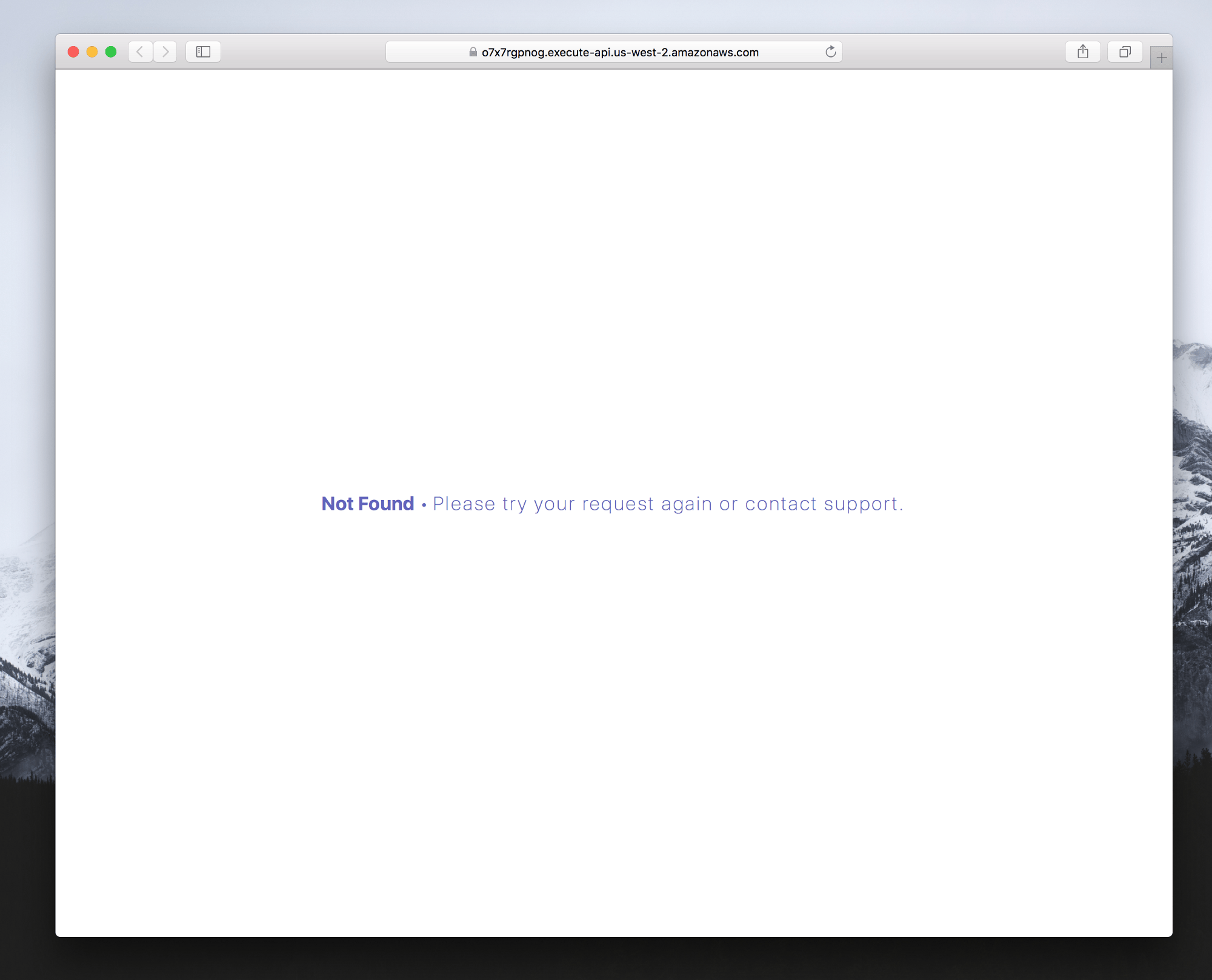
如果你想提供自定义模板,你可以创建以下一个或多个文件。特定文件优先。
error.html– 匹配任何 4xx 或 5xx5xx.html– 匹配任何 5xx 错误4xx.html– 匹配任何 4xx 错误CODE.html– 匹配一个特定的代码,如 404.html
查看文档阅读更多有关模板的信息。
伸缩和成本
你已经做了这么多,但是 Up 怎么伸缩?目前,API 网关和 AWS 是目标平台,因此你无需进行任何更改即可扩展,只需部署代码即可完成。你只需按需支付实际使用的数量并且无需人工干预。
AWS 每月免费提供 1,000,000 个请求,但你可以使用 http://serverlesscalc.com 来插入预期流量。在未来 Up 将提供更多的平台,所以如果一个成本过高,你可以迁移到另一个!
未来
目前为止就这样了!它可能看起来不是很多,但它已经超过 10,000 行代码,并且我刚刚开始开发。看看这个问题队列,假设项目可持续发展,看看未来会有什么期待。
如果你发现这个免费版本有用,请考虑在 OpenCollective 上捐赠我,因为我没有任何工作。我将在短期内开发早期专业版,对早期用户有年费优惠。专业或企业版也将提供源码,因此可以进行内部修复和自定义。
via: https://medium.freecodecamp.org/up-b3db1ca930ee
作者:TJ Holowaychuk 译者:geekpi 校对:wxy





















