使用GDB命令行调试器调试C/C++程序
没有调试器的情况下编写程序时最糟糕的状况是什么?编译时跪着祈祷不要出错?用血祭召唤恶魔帮你运行程序?或者在每一行代码间添加printf("test")语句来定位错误点?如你所知,编写程序时不使用调试器的话是不方便的。幸好,linux下调试还是很方便的。大多数人使用的IDE都集成了调试器,但 linux 最著名的调试器是命令行形式的C/C++调试器GDB。然而,与其他命令行工具一致,DGB需要一定的练习才能完全掌握。这里,我会告诉你GDB的基本情况及使用方法。

安装GDB
大多数的发行版仓库中都有GDB
Debian 或 Ubuntu
$ sudo apt-get install gdb
Arch Linux
$ sudo pacman -S gdb
Fedora,CentOS 或 RHEL:
$sudo yum install gdb
如果在仓库中找不到的话,可以从官网中下载。
示例代码
当学习GDB时,最好有一份代码,动手试验。下列代码是我编写的简单例子,它可以很好的体现GDB的特性。将它拷贝下来并且进行实验——这是最好的方法。
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
int i;
int a=0, b=0, c=0;
double d;
for (i=0; i<100; i++)
{
a++;
if (i>97)
d = i / 2.0;
b++;
}
return 0;
}
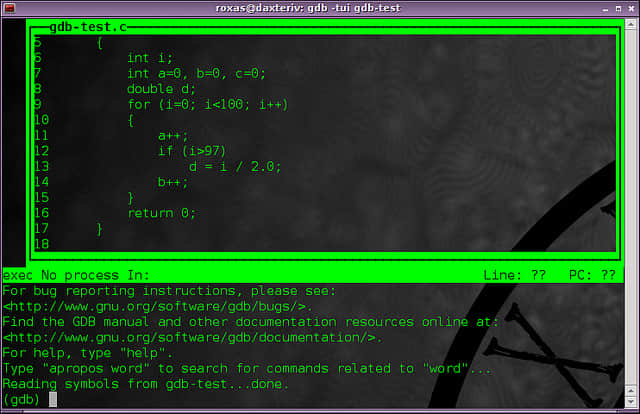
GDB的使用
首先最重要的,你需要使用编译器的 “-g“选项来编译程序,这样可执行程序才能通过GDB来运行。通过下列语句开始调试:
$ gdb -tui [可执行程序名]
使用”-tui“选项可以将代码显示在一个漂亮的交互式窗口内(所以被称为“文本用户界面 TUI”),在这个窗口内可以使用光标来操控,同时在下面的GDB shell中输入命令。
现在我们可以在程序的任何地方设置断点。你可以通过下列命令来为当前源文件的某一行设置断点。
break [行号]
或者为一个特定的函数设置断点:
break [函数名]
甚至可以设置条件断点
break [行号] if [条件]
例如,在我们的示例代码中,可以设置如下:
break 11 if i > 97
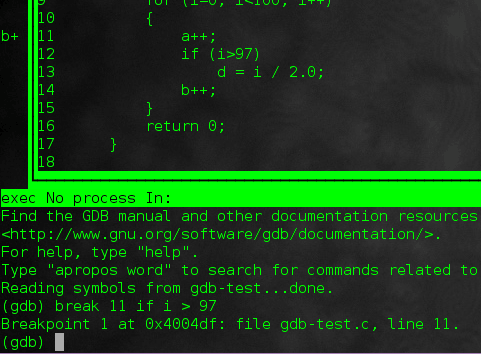
这样,程序循环97次之后停留在“a++”语句上。这样是非常方便的,避免了我们需要手动循环97次。
最后但也是很重要的是,我们可以设置一个“观察断点”,当这个被观察的变量发生变化时,程序会被停止。
watch [变量]
这里我们可以设置如下:
watch d
当d的值发生变化时程序会停止运行(例如,当i>97为真时)。
当设置断点后,使用"run"命令开始运行程序,或按如下所示:
r [程序的输入参数(如果有的话)]
gdb中,大多数的命令单词都可以简写为一个字母。
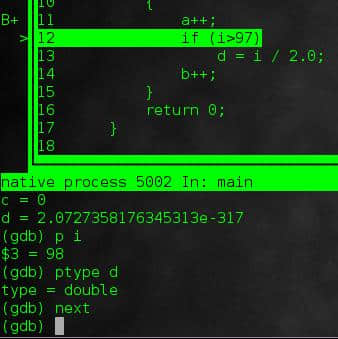
不出意外,程序会停留在11行。这里,我们可以做些有趣的事情。下列命令:
bt
回溯功能(backtrace)可以让我们知道程序如何到达这条语句的。

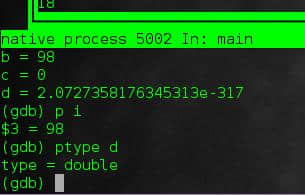
info locals
这条语句会显示所有的局部变量以及它们的值(你可以看到,我没有为d设置初始值,所以它现在的值是任意值)。
当然:

p [变量]
这个命令可以显示特定变量的值,而更进一步:
ptype [变量]
可以显示变量的类型。所以这里可以确定d是double型。
既然已经到这一步了,我么不妨这么做:
set var [变量] = [新的值]这样会覆盖变量的值。不过需要注意,你不能创建一个新的变量或改变变量的类型。我们可以这样做:
set var a = 0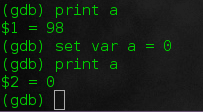
如其他优秀的调试器一样,我们可以单步调试:
step
使用如上命令,运行到下一条语句,有可能进入到一个函数里面。或者使用:
next
这可以直接运行下一条语句,而不进入子函数内部。
结束测试后,删除断点:
delete [行号]
从当前断点继续运行程序:
continue
退出GDB:
quit
总之,有了GDB,编译时不用祈祷上帝了,运行时不用血祭了,再也不用printf(“test“)了。当然,这里所讲的并不完整,而且GDB的功能远远不止于此。所以我强烈建议你自己更加深入的学习它。我现在感兴趣的是将GDB整合到Vim中。同时,这里有一个备忘录记录了GDB所有的命令行,以供查阅。
你对GDB有什么看法?你会将它与图形调试器对比吗,它有什么优势呢?对于将GDB集成到Vim有什么看法呢?将你的想法写到评论里。
via: http://xmodulo.com/gdb-command-line-debugger.html
作者:Adrien Brochard 译者:SPccman 校对:wxy