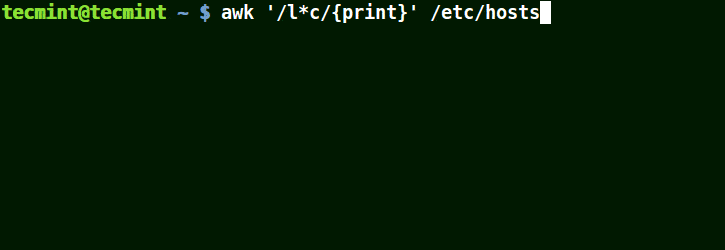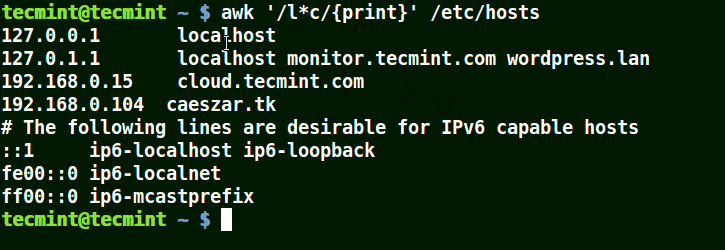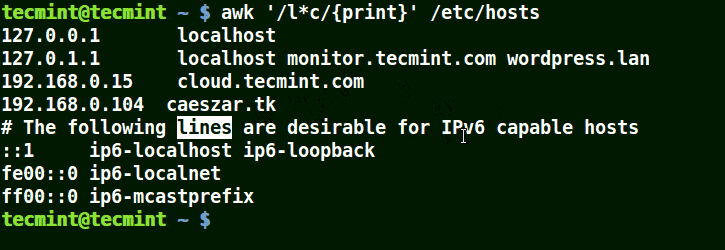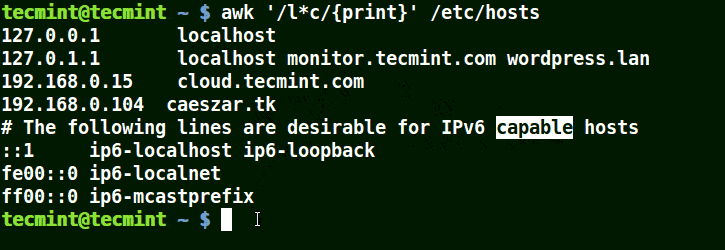
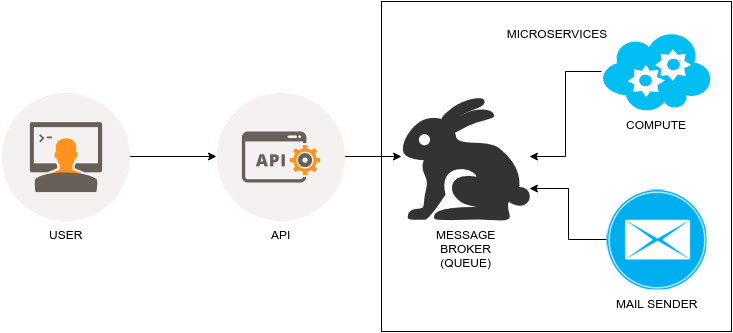
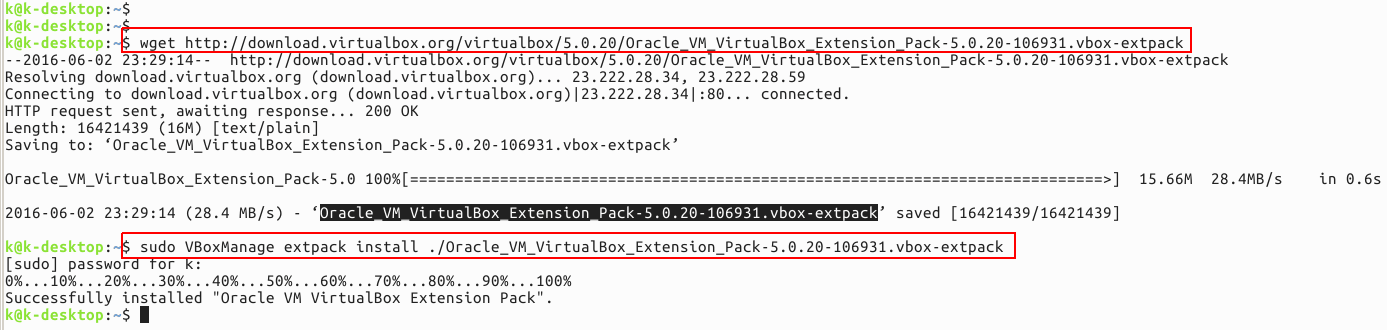
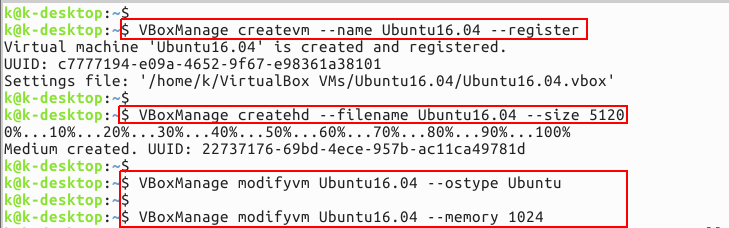
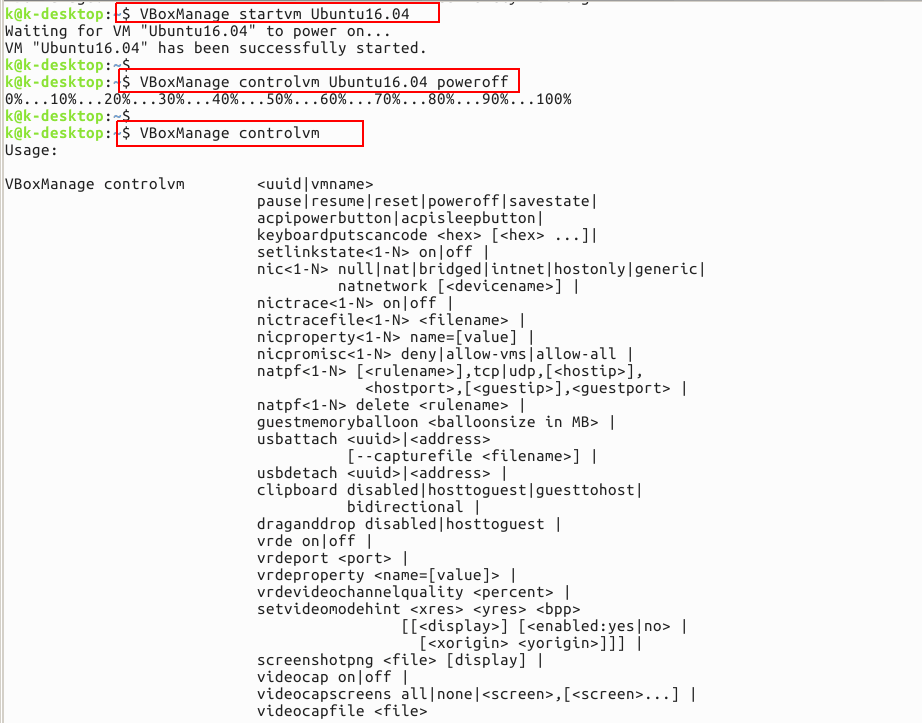
PHP 、Python 等网站应用惊爆远程代理漏洞:httpoxy

这是一个针对 PHP、Go、Python 等语言的 CGI 应用的漏洞。
httpoxy 是一系列影响到以 CGI 或类 CGI 方式运行的应用的漏洞名称。简单的来说,它就是一个名字空间的冲突问题。
- RFC 3875 (CGI)中定义了从 HTTP 请求的
Proxy头部直接填充到环境变量HTTP_PROXY的方式 HTTP_PROXY是一个常用于配置外发代理的环境变量
这个缺陷会导致远程攻击。如果你正在运行着 PHP 或 CGI 程序,你应该马上封挡 Proxy 头部!马上! 具体做法参见下面。httpoxy 是一个服务器端 web 应用漏洞,如果你没有在服务器端部署这些代码,则不用担心。
如果我的 Web 应用存在这种漏洞会怎么样?
当一个利用了此漏洞的 HTTP 客户端发起请求时,它可以做到:
- 通过你的 Web 应用去代理请求别的 URL
- 直接让你的服务器打开指定的远程地址及端口
- 浪费服务器的资源,替攻击者访问指定的资源
httpoxy 漏洞非常容易利用。希望安全人员尽快扫描该漏洞并快速修复。
哪些受到影响?
以下情况会存在安全漏洞:
- 代码运行在 CGI 上下文中,这样
HTTP_PROXY就会变成一个真实的或模拟的环境变量 - 一个信任
HTTP_PROXY的 HTTP 客户端,并且支持代理功能 - 该客户端会在请求内部发起一个 HTTP(或 HTTPS)请求
下列情形是已经发现存在该缺陷的环境:
| 语言 | 环境 | HTTP 客户端 |
|---|---|---|
| PHP | php-fpm mod\_php | Guzzle 4+ Artax |
| Python | wsgiref.handlers.CGIHandler twisted.web.twcgi.CGIScript | requests |
| Go | net/http/cgi | net/http |
肯定还有很多我们没有确定是否存在缺陷的语言和环境。
PHP
- 是否存在缺陷依赖于你的应用代码和 PHP 库,但是影响面看起来似乎非常广泛
- 只要在处理用户请求的过程中使用了一个带有该缺陷的库,就可能被利用
如果你使用了有该缺陷的库,该缺陷会影响任意 PHP 版本
- 甚至会影响到替代的 PHP 运行环境,比如部署在 FastCGI 模式下的 HHVM
确认影响 Guzzle、Artax 等库,可能还有很多很多的库也受影响
- Guzzle 4.0.0rc2 及其以后版本受影响,Guzzle 3 及更低版本不受影响
- 其它的例子还有 Composer 的 StreamContextBuilder 工具类
举个例子说,如果你在 Drupal 中使用 Guzzle 6 模块发起外发请求(比如请求一个天气 API),该模块发起的请求就存在这个 httpoxy 缺陷。
Python
Python 代码只有部署在 CGI 模式下才存在缺陷,一般来说,存在缺陷的代码会使用类似
wsgiref.handlers.CGIHandler的 CGI 控制器- 正常方式部署的 Python web 应用不受影响(大多数人使用 WSGI 或 FastCGI,这两个不受影响),所以受到影响的 Python 应用要比 PHP 少得多
- wsgi 不受影响,因为 os.environ 不会受到 CGI 数据污染
- 存在缺陷的 requests 库必须信任和使用
os.environ['HTTP_PROXY'],并且不做内容检查
Go
Go 代码必须部署在 CGI 下才受影响。一般来说受到影响的代码会使用
net/http/cgi包- 像 Python 一样,这并不是部署 Go 为一个 Web 应用的通常方式。所以受到影响的情形很少
- 相较而言,Go 的
net/http/fcgi包并不设置实际的环境变量,所以不受影响
- 存在缺陷的
net/http版本需要在外发请求中信任并使用HTTP_PROXY,并不做内容检查
马上修复
最好的修复方式是在他们攻击你的应用之前尽早封挡 Proxy 请求头部。这很简单,也很安全。
- 说它安全是因为 IETF 没有定义
Proxy请求头部,也没有列在 IANA 的消息头部注册中。这表明对该头部的使用是非标准的,甚至也不会临时用到 - 符合标准的 HTTP 客户端和服务器绝不应该读取和发送这个头部
- 你可以从请求中去掉这个头部或者干脆整个封挡使用它的请求
你可以在上游没有发布补丁时自己来解决这个问题
- 当 HTTP 请求进来时就检查它,这样可以一次性修复好许多存在缺陷的应用
- 在反向代理和应用防火墙之后的应用剔除
Proxy请求头部是安全的
如何封挡 Proxy 请求头部依赖于你的配置。最容易的办法是在你的 Web 应用防火墙上封挡该头部,或者直接在 Apache 和 Nginx 上做也行。以下是一些如何做的指导:
Nginx/FastCGI
使用如下语句封挡传递给 PHP-FPM、PHP-PM 的请求头,这个语句可以放在 fastcgi.conf 或 fastcgi\_param 中(视你使用了哪个配置文件):
fastcgi_param HTTP_PROXY "";
在 FastCGI 模式下,PHP 存在缺陷(但是大多数使用 Nginx FastCGI 的其它语言则不受影响)。
Apache
对于 Apache 受影响的具体程度,以及其它的 Apache 软件项目,比如 Tomcat ,推荐参考 Apache 软件基金会的官方公告。 以下是一些主要信息:
如果你在 Apache HTTP 服务器中使用 mod_cgi来运行 Go 或 Python 写的脚本,那么它们会受到影响(这里 HTTP_PROXY 环境变量是“真实的”)。而 mod_php 由于用于 PHP 脚本,也存在该缺陷。
如果你使用 mod\_headers 模块,你可以通过下述配置在进一步处理请求前就 unset 掉 Proxy 请求头部:
RequestHeader unset Proxy early
如果你使用 mod\_security 模块,你可以使用一个 SecRule 规则来拒绝带有 Proxy 请求头部的请求。下面是一个例子,要确保 SecRuleEngine 打开了。你可以根据自己的情况调整。
SecRule &REQUEST_HEADERS:Proxy "@gt 0" "id:1000005,log,deny,msg:'httpoxy denied'"
最后,如果你使用 Apache Traffic Server 的话,它本身不受影响。不过你可以用它来剔除掉 Proxy 请求头部,以保护其后面的其它服务。具体可以参考 ASF 指导。
HAProxy
通过下述配置剔除该请求头部:
http-request del-header Proxy
Varnish
通过下述语句取消该头部,请将它放到已有的 vcl\_recv 小节里面:
sub vcl_recv {
[...]
unset req.http.proxy;
[...]
}
OpenBSD relayd
使用如下语句移除该头部。把它放到已有的过滤器里面:
http protocol httpfilter {
match request header remove "Proxy"
}
lighttpd (<= 1.4.40)
弹回包含 Proxy 头部的请求。
- 创建一个
/path/to/deny-proxy.lua文件,让它对于 lighttpd 只读,内容如下:
if (lighty.request["Proxy"] == nil) then return 0 else return 403 end
- 修改
lighttpd.conf以加载mod_magnet模块,并运行如上 lua 代码:
server.modules += ( "mod_magnet" )
magnet.attract-raw-url-to = ( "/path/to/deny-proxy.lua" )
lighttpd2 (开发中)
从请求中剔除 Proxy 头部。加入如下语句到 lighttpd.conf中:
req_header.remove "Proxy";用户端的 PHP 修复没有作用
用户端的修复不能解决该缺陷,所以不必费劲:
- 使用
unset($_SERVER['HTTP_PROXY'])并不会影响到getenv()返回的值,所以无用 - 使用
putenv('HTTP_PROXY=')也没效果(putenv 只能影响到来自实际环境变量的值,而不是来自请求头部的)
httpoxy 的历史
该漏洞首次发现与15年前。
2001 年 3 月
Randal L. Schwartz 在 libwww-perl 发现该缺陷并修复。
2001 年 4 月
Cris Bailiff 在 curl 中发现该缺陷并修复。
2012 年 7 月
在Net::HTTP 的 HTTP_PROXY 实现中, Ruby 团队的 Akira Tanaka 发现了该缺陷
2013 年 11 月
在 nginx 邮件列表中提到了该缺陷。发现者 Jonathan Matthews 对此不太有把握,不过事实证明他是对的。
2015 年 2 月
Stefan Fritsch 在 Apache httpd-dev 邮件列表中提到了它。
2016 年 7 月
Vend 安全团队的 Scott Geary 发现了对该缺陷,并且它影响到了 PHP 等许多现代的编程语言和库。
所以,这个缺陷已经潜伏了许多年,许多人都在不同方面发现了它的存在,但是没有考虑到它对其它语言和库的影响。安全研究人员为此专门建立了一个网站: https://httpoxy.org/ ,可以在此发现更多内容。