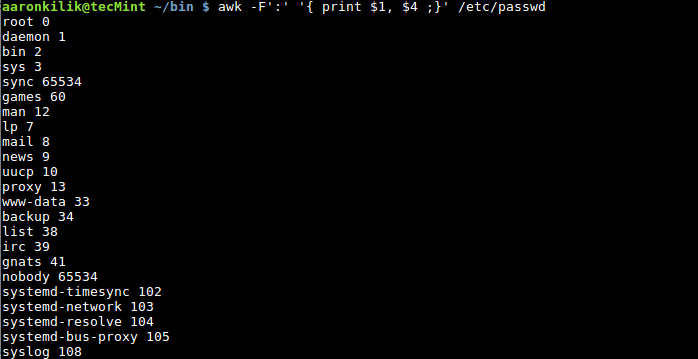
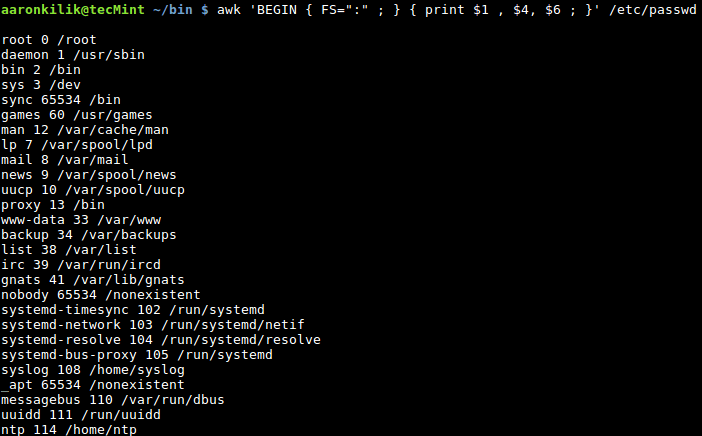
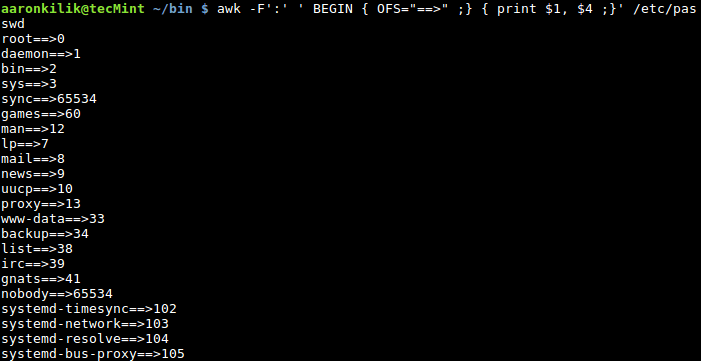
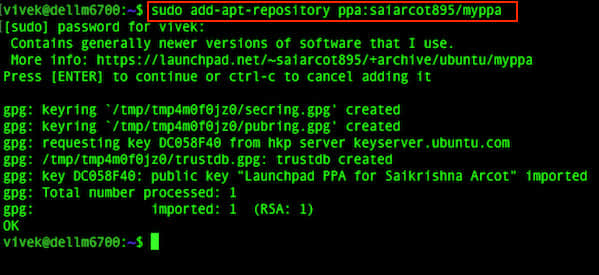
现在是时候学习怎样创建你自己的 Git 仓库了,还有怎样增加文件和完成提交。
在本系列前面的文章中,你已经学习了怎样作为一个最终用户与 Git 进行交互;你就像一个漫无目的的流浪者一样偶然发现了一个开源项目网站,克隆了仓库,然后你就可以继续钻研它了。你知道了和 Git 进行交互并不像你想的那样困难,或许你只是需要被说服现在去使用 Git 完成你的工作罢了。
虽然 Git 确实是被许多重要软件选作版本控制工具,但是并不是仅能用于这些重要软件;它也能管理你购物清单(如果它们对你来说很重要的话,当然可以了!)、你的配置文件、周报或日记、项目进展日志、甚至源代码!
使用 Git 是很有必要的,毕竟,你肯定有过因为一个备份文件不能够辨认出版本信息而抓狂的时候。

Git 无法帮助你,除非你开始使用它,而现在就是开始学习和使用它的最好时机。或者,用 Git 的话来说,“没有其他的 push 能像 origin HEAD 一样有帮助了”(千里之行始于足下的意思)。我保证,你很快就会理解这一点的。
类比于录音
我们经常用名词“快照”来指代计算机上的镜像,因为很多人都能够对插满了不同时光的照片的相册充满了感受。这很有用,不过,我认为 Git 更像是进行一场录音。
也许你不太熟悉传统的录音棚卡座式录音机,它包括几个部件:一个可以正转或反转的转轴、保存声音波形的磁带,可以通过拾音头在磁带上记录声音波形,或者检测到磁带上的声音波形并播放给听众。
除了往前播放磁带,你也可以把磁带倒回到之前的部分,或快进跳过后面的部分。
想象一下上世纪 70 年代乐队录制磁带的情形。你可以想象到他们一遍遍地练习歌曲,直到所有部分都非常完美,然后记录到音轨上。起初,你会录下鼓声,然后是低音,再然后是吉他声,最后是主唱。每次你录音时,录音棚工作人员都会把磁带倒带,然后进入循环模式,这样它就会播放你之前录制的部分。比如说如果你正在录制低音,你就会在背景音乐里听到鼓声,就像你自己在击鼓一样,然后吉他手在录制时会听到鼓声、低音(和牛铃声)等等。在每个循环中,你都会录制一部分,在接下来的循环中,工作人员就会按下录音按钮将其合并记录到磁带中。
你也可以拷贝或换下整个磁带,如果你要对你的作品重新混音的话。
现在我希望对于上述的上世纪 70 年代的录音工作的描述足够生动,这样我们就可以把 Git 的工作想象成一个录音工作了。
新建一个 Git 仓库
首先得为我们的虚拟的录音机买一些磁带。用 Git 的话说,这些磁带就是仓库;它是完成所有工作的基础,也就是说这里是存放 Git 文件的地方(即 Git 工作区)。
任何目录都可以成为一个 Git 仓库,但是让我们从一个新目录开始。这需要下面三个命令:
- 创建目录(如果你喜欢的话,你可以在你的图形化的文件管理器里面完成。)
- 在终端里切换到目录。
- 将其初始化成一个 Git 管理的目录。
也就是运行如下代码:
$ mkdir ~/jupiter # 创建目录
$ cd ~/jupiter # 进入目录
$ git init . # 初始化你的新 Git 工作区
在这个例子中,文件夹 jupiter 是一个空的但是合法的 Git 仓库。
有了仓库接下来的事情就可以按部就班进行了。你可以克隆该仓库,你可以在一个历史点前后来回穿梭(前提是你有一个历史点),创建交替的时间线,以及做 Git 能做的其它任何事情。
在 Git 仓库里面工作和在任何目录里面工作都是一样的,可以在仓库中新建文件、复制文件、保存文件。你可以像平常一样做各种事情;Git 并不复杂,除非你把它想复杂了。
在本地的 Git 仓库中,一个文件可以有以下这三种状态:
- 未跟踪文件 :你在仓库里新建了一个文件,但是你没有把文件加入到 Git 的管理之中。
- 已跟踪文件 :已经加入到 Git 管理的文件。
- 暂存区文件 :被修改了的已跟踪文件,并加入到 Git 的提交队列中。
任何你新加入到 Git 仓库中的文件都是未跟踪文件。这些文件保存在你的电脑硬盘上,但是你没有告诉 Git 这是需要管理的文件,用我们的录音机来类比,就是录音机还没打开;乐队就开始在录音棚里忙碌了,但是录音机并没有准备录音。
不用担心,Git 会在出现这种情况时告诉你:
$ echo "hello world" > foo
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
foo
nothing added but untracked files present (use "git add" to track)
你看到了,Git 会提醒你怎样把文件加入到提交任务中。
不使用 Git 命令进行 Git 操作
在 GitHub 或 GitLab 上创建一个仓库只需要用鼠标点几下即可。这并不难,你单击“New Repository”这个按钮然后跟着提示做就可以了。
在仓库中包括一个“README”文件是一个好习惯,这样人们在浏览你的仓库的时候就可以知道你的仓库是干什么的,更有用的是可以让你在克隆一个有东西的仓库前知道它有些什么。
克隆仓库通常很简单,但是在 GitHub 上获取仓库改动权限就稍微复杂一些,为了通过 GitHub 验证你必须有一个 SSH 密钥。如果你使用 Linux 系统,可以通过下面的命令生成:
$ ssh-keygen
然后复制你的新密钥的内容,它是纯文本文件,你可以使用一个文本编辑器打开它,也可以使用如下 cat 命令查看:
$ cat ~/.ssh/id_rsa.pub
现在把你的密钥粘贴到 GitHub SSH 配置文件 中,或者 GitLab 配置文件。
如果你通过使用 SSH 模式克隆了你的项目,你就可以将修改写回到你的仓库了。
另外,如果你的系统上没有安装 Git 的话也可以使用 GitHub 的文件上传接口来添加文件。
跟踪文件
正如命令 git status 的输出告诉你的那样,如果你想让 git 跟踪一个文件,你必须使用命令 git add 把它加入到提交任务中。这个命令把文件存在了暂存区,这里存放的都是等待提交的文件,或者也可以用在快照中。在将文件包括到快照中,和添加要 Git 管理的新的或临时文件时,git add 命令的目的是不同的,不过至少现在,你不用为它们之间的不同之处而费神。
类比录音机,这个动作就像打开录音机开始准备录音一样。你可以想象为对已经在录音的录音机按下暂停按钮,或者倒回开头等着记录下个音轨。
当你把文件添加到 Git 管理中,它会标识其为已跟踪文件:
$ git add foo
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: foo
加入文件到提交任务中并不是“准备录音”。这仅仅是将该文件置于准备录音的状态。在你添加文件后,你仍然可以修改该文件;它只是被标记为已跟踪和处于暂存区,所以在它被写到“磁带”前你可以将它撤出或修改它(当然你也可以再次将它加入来做些修改)。但是请注意:你还没有在磁带中记录该文件,所以如果弄坏了一个之前还是好的文件,你是没有办法恢复的,因为你没有在“磁带”中记下那个文件还是好着的时刻。
如果你最后决定不把文件记录到 Git 历史列表中,那么你可以撤销提交任务,在 Git 中是这样做的:
$ git reset HEAD foo
这实际上就是解除了录音机的准备录音状态,你只是在录音棚中转了一圈而已。
大型提交
有时候,你想要提交一些内容到仓库;我们以录音机类比,这就好比按下录音键然后记录到磁带中一样。
在一个项目所经历的不同阶段中,你会按下这个“记录键”无数次。比如,如果你尝试了一个新的 Python 工具包并且最终实现了窗口呈现功能,然后你肯定要进行提交,以便你在实验新的显示选项时搞砸了可以回退到这个阶段。但是如果你在 Inkscape 中画了一些图形草样,在提交前你可能需要等到已经有了一些要开发的内容。尽管你可能提交了很多次,但是 Git 并不会浪费很多,也不会占用太多磁盘空间,所以在我看来,提交的越多越好。
commit 命令会“记录”仓库中所有的暂存区文件。Git 只“记录”已跟踪的文件,即,在过去某个时间点你使用 git add 命令加入到暂存区的所有文件,以及从上次提交后被改动的文件。如果之前没有过提交,那么所有跟踪的文件都包含在这次提交中,以 Git 的角度来看,这是一次非常重要的修改,因为它们从没放到仓库中变成了放进去。
完成一次提交需要运行下面的命令:
$ git commit -m 'My great project, first commit.'
这就保存了所有提交的文件,之后可以用于其它操作(或者,用英国电视剧《神秘博士》中时间领主所讲的 Gallifreyan 语说,它们成为了“固定的时间点” )。这不仅是一个提交事件,也是一个你在 Git 日志中找到该提交的引用指针:
$ git log --oneline
55df4c2 My great project, first commit.
如果想浏览更多信息,只需要使用不带 --oneline 选项的 git log 命令。
在这个例子中提交时的引用号码是 55df4c2。它被叫做“ 提交哈希 ”(LCTT 译注:这是一个 SHA-1 算法生成的哈希码,用于表示一个 git 提交对象),它代表着刚才你的提交所包含的所有新改动,覆盖到了先前的记录上。如果你想要“倒回”到你的提交历史点上,就可以用这个哈希作为依据。
你可以把这个哈希想象成一个声音磁带上的 SMPTE 时间码,或者再形象一点,这就是好比一个黑胶唱片上两首不同的歌之间的空隙,或是一个 CD 上的音轨编号。
当你改动了文件之后并且把它们加入到提交任务中,最终完成提交,这就会生成新的提交哈希,它们每一个所标示的历史点都代表着你的产品不同的版本。
这就是 Charlie Brown 这样的音乐家们为什么用 Git 作为版本控制系统的原因。
在接下来的文章中,我们将会讨论关于 Git HEAD 的各个方面,我们会真正地向你揭示时间旅行的秘密。不用担心,你只需要继续读下去就行了(或许你已经在读了?)。
via: https://opensource.com/life/16/7/creating-your-first-git-repository
作者:Seth Kenlon 译者:vim-kakali 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出