在 Linux 上用 SELinux 或 AppArmor 实现强制访问控制(MAC)
为了解决标准的“用户-组-其他/读-写-执行”权限以及访问控制列表的限制以及加强安全机制,美国国家安全局(NSA)设计出一个灵活的 强制访问控制 (MAC)方法 SELinux(Security Enhanced Linux 的缩写),来限制标准的权限之外的种种权限,在仍然允许对这个控制模型后续修改的情况下,让进程尽可能以最小权限访问或在系统对象(如文件,文件夹,网络端口等)上执行其他操作。

SELinux 和 AppArmor 加固 Linux 安全
另一个流行并且被广泛使用的 MAC 是 AppArmor,相比于 SELinux 它提供更多的特性,包括一个学习模式,可以让系统“学习”一个特定应用的行为,以及通过配置文件设置限制实现安全的应用使用。
在 CentOS 7 中,SELinux 合并进了内核并且默认启用 强制 模式(下一节会介绍这方面更多的内容),与之不同的是,openSUSE 和 Ubuntu 使用的是 AppArmor 。
在这篇文章中我们会解释 SELinux 和 AppArmor 的本质,以及如何在你选择的发行版上使用这两个工具之一并从中获益。
SELinux 介绍以及如何在 CentOS 7 中使用
Security Enhanced Linux 可以以两种不同模式运行:
- 强制 :这种情况下,SELinux 基于 SELinux 策略规则拒绝访问,策略规则是一套控制安全引擎的规则。
- 宽容 :这种情况下,SELinux 不拒绝访问,但如果在强制模式下会被拒绝的操作会被记录下来。
SELinux 也能被禁用。尽管这不是它的一个操作模式,不过也是一种选择。但学习如何使用这个工具强过只是忽略它。时刻牢记这一点!
使用 getenforce 命令来显示 SELinux 的当前模式。如果你想要更改模式,使用 setenforce 0(设置为宽容模式)或 setenforce 1(强制模式)。
因为这些设置重启后就失效了,你需要编辑 /etc/selinux/config 配置文件并设置 SELINUX 变量为 enforcing、permissive 或 disabled ,保存设置让其重启后也有效:
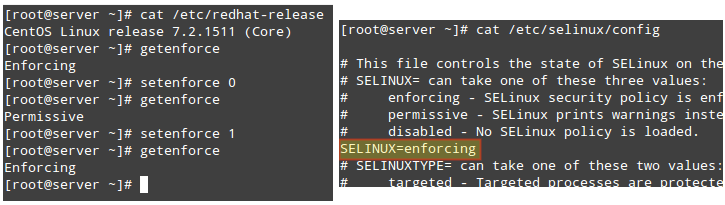
如何启用和禁用 SELinux 模式
还有一点要注意,如果 getenforce 返回 Disabled,你得编辑 /etc/selinux/config 配置文件为你想要的操作模式并重启。否则你无法利用 setenforce 设置(或切换)操作模式。
setenforce 的典型用法之一包括在 SELinux 模式之间切换(从强制到宽容或相反)来定位一个应用是否行为不端或没有像预期一样工作。如果它在你将 SELinux 设置为宽容模式正常工作,你就可以确定你遇到的是 SELinux 权限问题。
有两种我们使用 SELinux 可能需要解决的典型案例:
- 改变一个守护进程监听的默认端口。
- 给一个虚拟主机设置 /var/www/html 以外的文档根路径值。
让我们用以下例子来看看这两种情况。
例 1:更改 sshd 守护进程的默认端口
大部分系统管理员为了加强服务器安全首先要做的事情之一就是更改 SSH 守护进程监听的端口,主要是为了阻止端口扫描和外部攻击。要达到这个目的,我们要更改 /etc/ssh/sshd_config 中的 Port 值为以下值(我们在这里使用端口 9999 为例):
Port 9999
在尝试重启服务并检查它的状态之后,我们会看到它启动失败:
# systemctl restart sshd
# systemctl status sshd
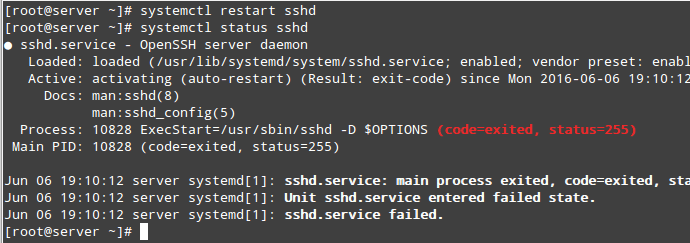
检查 SSH 服务状态
如果我们看看 /var/log/audit/audit.log,就会看到 sshd 被 SELinux 阻止在端口 9999 上启动,因为它是 JBoss 管理服务的保留端口(SELinux 日志信息包含了词语“AVC”,所以应该很容易把它同其他信息区分开来):
# cat /var/log/audit/audit.log | grep AVC | tail -1

检查 Linux 审计日志
在这种情况下大部分人可能会禁用 SELinux,但我们不这么做。我们会看到有个让 SELinux 和监听其他端口的 sshd 和谐共处的方法。首先确保你有 policycoreutils-python 这个包,执行:
# yum install policycoreutils-python
查看 SELinux 允许 sshd 监听的端口列表。在接下来的图片中我们还能看到端口 9999 是为其他服务保留的,所以我们暂时无法用它来运行其他服务:
# semanage port -l | grep ssh
当然我们可以给 SSH 选择其他端口,但如果我们确定我们不会使用这台机器跑任何 JBoss 相关的服务,我们就可以修改 SELinux 已存在的规则,转而给 SSH 分配那个端口:
# semanage port -m -t ssh_port_t -p tcp 9999
这之后,我们就可以用前一个 semanage 命令检查端口是否正确分配了,即使用 -lC 参数(list custom 的简称):
# semanage port -lC
# semanage port -l | grep ssh
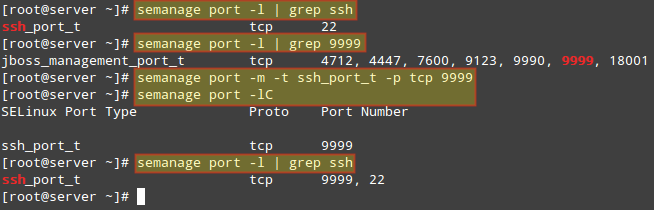
给 SSH 分配端口
我们现在可以重启 SSH 服务并通过端口 9999 连接了。注意这个更改重启之后依然有效。
例 2:给一个虚拟主机设置 /var/www/html 以外的 文档根路径
如果你需要用除 /var/www/html 以外目录作为 文档根目录 设置一个 Apache 虚拟主机(也就是说,比如 /websrv/sites/gabriel/public_html):
DocumentRoot “/websrv/sites/gabriel/public_html”
Apache 会拒绝提供内容,因为 index.html 已经被标记为了 default_t SELinux 类型,Apache 无法访问它:
# wget http://localhost/index.html
# ls -lZ /websrv/sites/gabriel/public_html/index.html
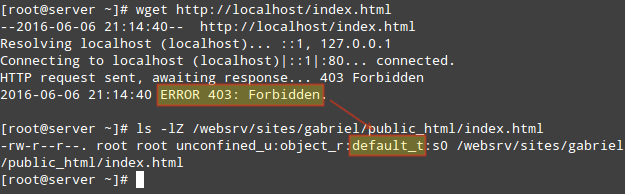
被标记为 default\_t SELinux 类型
和之前的例子一样,你可以用以下命令验证这是不是 SELinux 相关的问题:
# cat /var/log/audit/audit.log | grep AVC | tail -1

检查日志确定是不是 SELinux 的问题
要将 /websrv/sites/gabriel/public_html 整个目录内容标记为 httpd_sys_content_t,执行:
# semanage fcontext -a -t httpd_sys_content_t "/websrv/sites/gabriel/public_html(/.*)?"
上面这个命令会赋予 Apache 对那个目录以及其内容的读取权限。
最后,要应用这条策略(并让更改的标记立即生效),执行:
# restorecon -R -v /websrv/sites/gabriel/public_html
现在你应该可以访问这个目录了:
# wget http://localhost/index.html
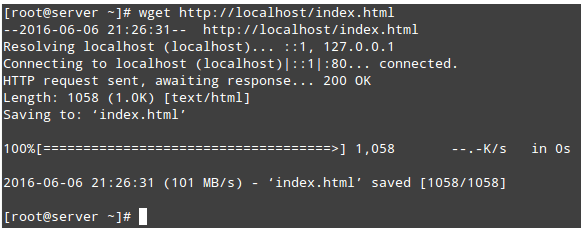
访问 Apache 目录
要获取关于 SELinux 的更多信息,参阅 Fedora 22 中的 SELinux 用户及管理员指南。
AppArmor 介绍以及如何在 OpenSUSE 和 Ubuntu 上使用它
AppArmor 的操作是基于写在纯文本文件中的规则定义,该文件中含有允许权限和访问控制规则。安全配置文件用来限制应用程序如何与系统中的进程和文件进行交互。
系统初始就提供了一系列的配置文件,但其它的也可以由应用程序在安装的时候设置或由系统管理员手动设置。
像 SELinux 一样,AppArmor 以两种模式运行。在 强制 模式下,应用被赋予它们运行所需要的最小权限,但在 抱怨 模式下 AppArmor 允许一个应用执行受限的操作并将操作造成的“抱怨”记录到日志里(/var/log/kern.log,/var/log/audit/audit.log,和其它放在 /var/log/apparmor 中的日志)。
日志中会显示配置文件在强制模式下运行时会产生错误的记录,它们中带有 audit 这个词。因此,你可以在 AppArmor 的 强制 模式下运行之前,先在 抱怨 模式下尝试运行一个应用并调整它的行为。
可以用这个命令显示 AppArmor 的当前状态:
$ sudo apparmor_status
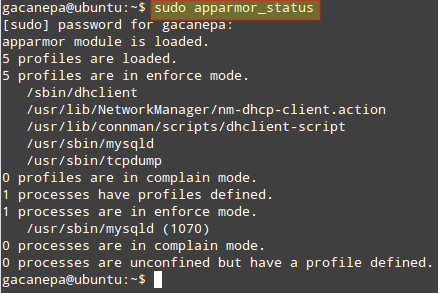
查看 AppArmor 的状态
上面的图片指明配置 /sbin/dhclient,/usr/sbin/,和 /usr/sbin/tcpdump 等处在 强制 模式下(在 Ubuntu 下默认就是这样的)。
因为不是所有的应用都包含相关的 AppArmor 配置,apparmor-profiles 包给其它没有提供限制的包提供了配置。默认它们配置在 抱怨 模式下运行,以便系统管理员能够测试并选择一个所需要的配置。
我们将会利用 apparmor-profiles,因为写一份我们自己的配置已经超出了 LFCS 认证的范围了。但是,由于配置都是纯文本文件,你可以查看并学习它们,为以后创建自己的配置做准备。
AppArmor 配置保存在 /etc/apparmor.d 中。让我们来看看这个文件夹在安装 apparmor-profiles 之前和之后有什么不同:
$ ls /etc/apparmor.d
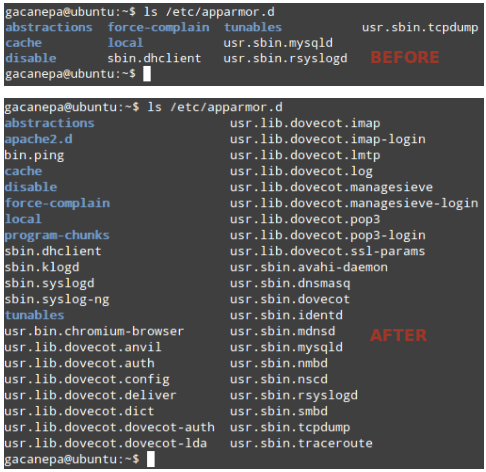
查看 AppArmor 文件夹内容
如果你再次执行 sudo apparmor_status,你会在 抱怨 模式看到更长的配置文件列表。你现在可以执行下列操作。
将当前在 强制 模式下的配置文件切换到 抱怨 模式:
$ sudo aa-complain /path/to/file
以及相反的操作(抱怨 –> 强制):
$ sudo aa-enforce /path/to/file
上面这些例子是允许使用通配符的。举个例子:
$ sudo aa-complain /etc/apparmor.d/*
会将 /etc/apparmor.d 中的所有配置文件设置为 抱怨 模式,反之
$ sudo aa-enforce /etc/apparmor.d/*
会将所有配置文件设置为 强制 模式。
要完全禁用一个配置,在 /etc/apparmor.d/disabled 目录中创建一个符号链接:
$ sudo ln -s /etc/apparmor.d/profile.name /etc/apparmor.d/disable/
要获取关于 AppArmor 的更多信息,参阅官方的 AppArmor wiki 以及 Ubuntu 提供的文档。
总结
在这篇文章中我们学习了一些 SELinux 和 AppArmor 这两个著名的强制访问控制系统的基本知识。什么时候使用两者中的一个或是另一个?为了避免提高难度,你可能需要考虑专注于你选择的发行版自带的那一个。不管怎样,它们会帮助你限制进程和系统资源的访问,以提高你服务器的安全性。
关于本文你有任何的问题,评论,或建议,欢迎在下方发表。不要犹豫,让我们知道你是否有疑问或评论。
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
作者:Gabriel Cánepa 译者:alim0x 校对:wxy