使用 Docker 构建你的 Serverless 树莓派集群

这篇博文将向你展示如何使用 Docker 和 OpenFaaS 框架构建你自己的 Serverless 树莓派集群。大家常常问我能用他们的集群来做些什么?而这个应用完美匹配卡片尺寸的设备——只需添加更多的树莓派就能获取更强的计算能力。
“Serverless” (无服务器)是事件驱动架构的一种设计模式,与“桥接模式”、“外观模式”、“工厂模式”和“云”这些名词一样,都是一种抽象概念。

图片:3 个 Raspberry Pi Zero
这是我在本文中描述的集群,用黄铜支架分隔每个设备。
Serverless 是什么?它为何重要?
行业对于 “serverless” 这个术语的含义有几种解释。在这篇博文中,我们就把它理解为一种事件驱动的架构模式,它能让你用自己喜欢的任何语言编写轻量可复用的功能。更多关于 Serverless 的资料。
Serverless 架构也引出了“功能即服务服务”模式,简称 FaaS
Serverless 的“功能”可以做任何事,但通常用于处理给定的输入——例如来自 GitHub、Twitter、PayPal、Slack、Jenkins CI pipeline 的事件;或者以树莓派为例,处理像红外运动传感器、激光绊网、温度计等真实世界的传感器的输入。
Serverless 功能能够更好地结合第三方的后端服务,使系统整体的能力大于各部分之和。
了解更多背景信息,可以阅读我最近一偏博文:功能即服务(FaaS)简介。
概述
我们将使用 OpenFaaS,它能够让主机或者集群作为支撑 Serverless 功能运行的后端。任何能够使用 Docker 部署的可执行二进制文件、脚本或者编程语言都能在 OpenFaaS 上运作,你可以根据速度和伸缩性选择部署的规模。另一个优点是,它还内建了用户界面和监控系统。
这是我们要执行的步骤:
- 在一个或多个主机上配置 Docker (树莓派 2 或者 3);
- 利用 Docker Swarm 将它们连接;
- 部署 OpenFaaS;
- 使用 Python 编写我们的第一个功能。
Docker Swarm
Docker 是一项打包和部署应用的技术,支持集群上运行,有着安全的默认设置,而且在搭建集群时只需要一条命令。OpenFaaS 使用 Docker 和 Swarm 在你的可用树莓派上传递你的 Serverless 功能。
我推荐你在这个项目中使用带树莓派 2 或者 3,以太网交换机和强大的 USB 多端口电源适配器。
准备 Raspbian
把 Raspbian Jessie Lite 写入 SD 卡(8GB 容量就正常工作了,但还是推荐使用 16GB 的 SD 卡)。
注意:不要下载成 Raspbian Stretch 了
社区在努力让 Docker 支持 Raspbian Stretch,但是还未能做到完美运行。请从树莓派基金会网站下载 Jessie Lite 镜像。
我推荐使用 Etcher.io 烧写镜像。
在引导树莓派之前,你需要在引导分区创建名为 ssh 的空白文件。这样才能允许远程登录。接通电源,然后修改主机名
现在启动树莓派的电源并且使用 ssh 连接:
$ ssh [email protected]
默认密码是 raspberry使用 raspi-config 工具把主机名改为 swarm-1 或者类似的名字,然后重启。
当你到了这一步,你还可以把划分给 GPU (显卡)的内存设置为 16MB。
现在安装 Docker
我们可以使用通用脚本来安装:
$ curl -sSL https://get.docker.com | sh
这个安装方式在将来可能会发生变化。如上文所说,你的系统需要是 Jessie,这样才能得到一个确定的配置。
你可能会看到类似下面的警告,不过你可以安全地忽略它并且成功安装上 Docker CE 17.05:
WARNING: raspbian is no longer updated @ https://get.docker.com/
Installing the legacy docker-engine package...
之后,用下面这个命令确保你的用户帐号可以访问 Docker 客户端:
$ usermod pi -aG docker
如果你的用户名不是 pi,那就把它替换成你的用户名。修改默认密码
输入 $sudo passwd pi,然后设置一个新密码,请不要跳过这一步!
重复以上步骤
现在为其它的树莓派重复上述步骤。
创建你的 Swarm 集群
登录你的第一个树莓派,然后输入下面的命令:
$ docker swarm init
Swarm initialized: current node (3ra7i5ldijsffjnmubmsfh767) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-496mv9itb7584pzcddzj4zvzzfltgud8k75rvujopw15n3ehzu-af445b08359golnzhncbdj9o3 \
192.168.0.79:2377
你会看到它显示了一个口令,以及其它节点加入集群的命令。接下来使用 ssh 登录每个树莓派,运行这个加入集群的命令。
等待连接完成后,在第一个树莓派上查看集群的节点:
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
3ra7i5ldijsffjnmubmsfh767 * swarm1 Ready Active Leader
k9mom28s2kqxocfq1fo6ywu63 swarm3 Ready Active
y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
恭喜你!你现在拥有一个树莓派集群了!
更多关于集群的内容
你可以看到三个节点启动运行。这时只有一个节点是集群管理者。如果我们的管理节点死机了,集群就进入了不可修复的状态。我们可以通过添加冗余的管理节点解决这个问题。而且它们依然会运行工作负载,除非你明确设置了让你的服务只运作在工作节点上。
要把一个工作节点升级为管理节点,只需要在其中一个管理节点上运行 docker node promote <node_name> 命令。
注意: Swarm 命令,例如docker service ls或者docker node ls只能在管理节点上运行。
想深入了解管理节点与工作节点如何保持一致性,可以查阅 Docker Swarm 管理指南。
OpenFaaS
现在我们继续部署程序,让我们的集群能够运行 Serverless 功能。OpenFaaS 是一个利用 Docker 在任何硬件或者云上让任何进程或者容器成为一个 Serverless 功能的框架。因为 Docker 和 Golang 的可移植性,它也能很好地运行在树莓派上。

如果你支持 OpenFaaS,希望你能 星标 OpenFaaS 的 GitHub 仓库。
登录你的第一个树莓派(你运行 docker swarm init 的节点),然后部署这个项目:
$ git clone https://github.com/alexellis/faas/
$ cd faas
$ ./deploy_stack.armhf.sh
Creating network func_functions
Creating service func_gateway
Creating service func_prometheus
Creating service func_alertmanager
Creating service func_nodeinfo
Creating service func_markdown
Creating service func_wordcount
Creating service func_echoit
你的其它树莓派会收到 Docer Swarm 的指令,开始从网上拉取这个 Docker 镜像,并且解压到 SD 卡上。这些工作会分布到各个节点上,所以没有哪个节点产生过高的负载。
这个过程会持续几分钟,你可以用下面指令查看它的完成状况:
$ watch 'docker service ls'
ID NAME MODE REPLICAS IMAGE PORTS
57ine9c10xhp func_wordcount replicated 1/1 functions/alpine:latest-armhf
d979zipx1gld func_prometheus replicated 1/1 alexellis2/prometheus-armhf:1.5.2 *:9090->9090/tcp
f9yvm0dddn47 func_echoit replicated 1/1 functions/alpine:latest-armhf
lhbk1fc2lobq func_markdown replicated 1/1 functions/markdownrender:latest-armhf
pj814yluzyyo func_alertmanager replicated 1/1 alexellis2/alertmanager-armhf:0.5.1 *:9093->9093/tcp
q4bet4xs10pk func_gateway replicated 1/1 functions/gateway-armhf:0.6.0 *:8080->8080/tcp
v9vsvx73pszz func_nodeinfo replicated 1/1 functions/nodeinfo:latest-armhf
我们希望看到每个服务都显示 “1/1”。
你可以根据服务名查看该服务被调度到哪个树莓派上:
$ docker service ps func_markdown
ID IMAGE NODE STATE
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
状态一项应该显示 Running,如果它是 Pending,那么镜像可能还在下载中。
在这时,查看树莓派的 IP 地址,然后在浏览器中访问它的 8080 端口:
$ ifconfig
例如,如果你的 IP 地址是 192.168.0.100,那就访问 http://192.168.0.100:8080 。
这是你会看到 FaaS UI(也叫 API 网关)。这是你定义、测试、调用功能的地方。
点击名称为 “func\_markdown” 的 Markdown 转换功能,输入一些 Markdown(这是 Wikipedia 用来组织内容的语言)文本。
然后点击 “invoke”。你会看到调用计数增加,屏幕下方显示功能调用的结果。

部署你的第一个 Serverless 功能:
这一节的内容已经有相关的教程,但是我们需要几个步骤来配置树莓派。
获取 FaaS-CLI
$ curl -sSL cli.openfaas.com | sudo sh
armv7l
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
下载样例
$ git clone https://github.com/alexellis/faas-cli
$ cd faas-cli
为树莓派修补样例模版
我们临时修改我们的模版,让它们能在树莓派上工作:
$ cp template/node-armhf/Dockerfile template/node/
$ cp template/python-armhf/Dockerfile template/python/
这么做是因为树莓派和我们平时关注的大多数计算机使用不一样的处理器架构。
了解 Docker 在树莓派上的最新状况,请查阅: 你需要了解的五件事。
现在你可以跟着下面为 PC、笔记本和云端所写的教程操作,但我们在树莓派上要先运行一些命令。
注意第 3 步:
- 把你的功能放到先前从 GitHub 下载的
faas-cli文件夹中,而不是~/functinos/hello-python里。 - 同时,在
stack.yml文件中把localhost替换成第一个树莓派的 IP 地址。
集群可能会花费几分钟把 Serverless 功能下载到相关的树莓派上。你可以用下面的命令查看你的服务,确保副本一项显示 “1/1”:
$ watch 'docker service ls'
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
继续阅读教程: 使用 OpenFaaS 运行你的第一个 Serverless Python 功能
关于 Node.js 或者其它语言的更多信息,可以进一步访问 FaaS 仓库。
检查功能的指标
既然使用 Serverless,你也不想花时间监控你的功能。幸运的是,OpenFaaS 内建了 Prometheus 指标检测,这意味着你可以追踪每个功能的运行时长和调用频率。
指标驱动自动伸缩
如果你给一个功能生成足够的负载,OpenFaaS 将自动扩展你的功能;当需求消失时,你又会回到单一副本的状态。
这个请求样例你可以复制到浏览器中:
只要把 IP 地址改成你的即可。
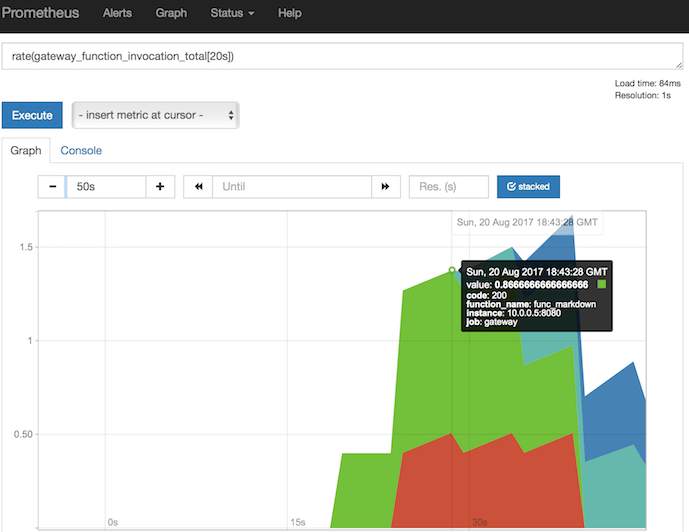
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
这些请求使用 PromQL(Prometheus 请求语言)编写。第一个请求返回功能调用的频率:
rate(gateway_function_invocation_total[20s])
第二个请求显示每个功能的副本数量,最开始应该是每个功能只有一个副本。
gateway_service_count
如果你想触发自动扩展,你可以在树莓派上尝试下面指令:
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
查看 Prometheus 的 “alerts” 页面,可以知道你是否产生足够的负载来触发自动扩展。如果没有,你可以尝试在多个终端同时运行上面的指令。
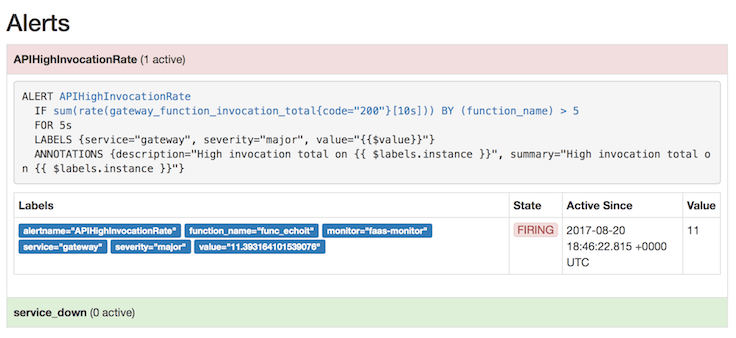
当你降低负载,副本数量显示在你的第二个图表中,并且 gateway_service_count 指标再次降回 1。
结束演讲
我们现在配置好了 Docker、Swarm, 并且让 OpenFaaS 运行代码,把树莓派像大型计算机一样使用。
希望大家支持这个项目,星标 FaaS 的 GitHub 仓库。
你是如何搭建好了自己的 Docker Swarm 集群并且运行 OpenFaaS 的呢?在 Twitter @alexellisuk 上分享你的照片或推文吧。
观看我在 Dockercon 上关于 OpenFaaS 的视频
我在 Austin 的 Dockercon 上展示了 OpenFaaS。——观看介绍和互动例子的视频: https://www.youtube.com/embed/-h2VTE9WnZs
有问题?在下面的评论中提出,或者给我发邮件,邀请我进入你和志同道合者讨论树莓派、Docker、Serverless 的 Slack channel。
想要学习更多关于树莓派上运行 Docker 的内容?
我建议从 你需要了解的五件事 开始,它包含了安全性、树莓派和普通 PC 间微妙差别等话题。
- Dockercon tips: Docker & Raspberry Pi
- Control GPIO with Docker Swarm
- Is that a Docker Engine in your pocket??
via: https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/
作者:Alex Ellis 译者:haoqixu 校对:wxy



 ")
") using PTC")
using PTC")