我其实不想将它分解开给你看,用户应用程序其实就是一个可怜的 瓮中大脑 :
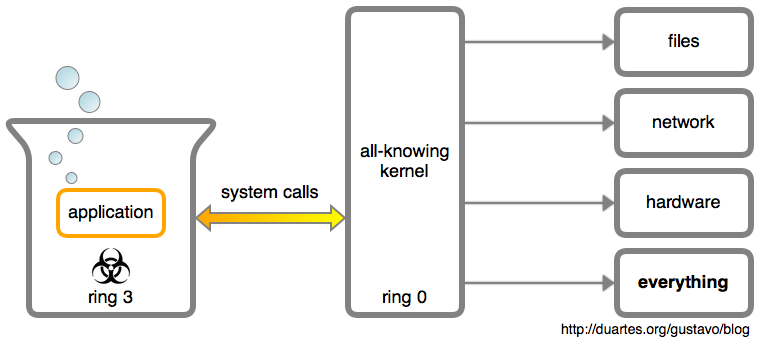
它与外部世界的每个交流都要在内核的帮助下通过系统调用才能完成。一个应用程序要想保存一个文件、写到终端、或者打开一个 TCP 连接,内核都要参与。应用程序是被内核高度怀疑的:认为它到处充斥着 bug,甚至是个充满邪恶想法的脑子。
这些系统调用是从一个应用程序到内核的函数调用。出于安全考虑,它们使用了特定的机制,实际上你只是调用了内核的 API。“ 系统调用 ”这个术语指的是调用由内核提供的特定功能(比如,系统调用 open())或者是调用途径。你也可以简称为:syscall。
这篇文章讲解系统调用,系统调用与调用一个库有何区别,以及在操作系统/应用程序接口上的刺探工具。如果彻底了解了应用程序借助操作系统发生的哪些事情,那么就可以将一个不可能解决的问题转变成一个快速而有趣的难题。
那么,下图是一个运行着的应用程序,一个用户进程:
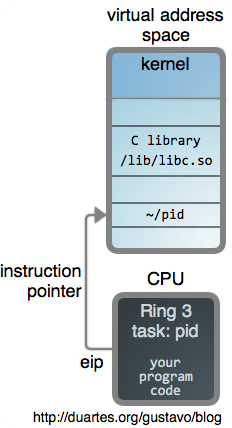
它有一个私有的 虚拟地址空间—— 它自己的内存沙箱。整个系统都在它的地址空间中(即上面比喻的那个“瓮”),程序的二进制文件加上它所使用的库全部都 被映射到内存中。内核自身也映射为地址空间的一部分。
下面是我们程序 pid 的代码,它通过 getpid(2) 直接获取了其进程 id:
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
pid_t p = getpid();
printf("%d\n", p);
}
pid.c download
在 Linux 中,一个进程并不是一出生就知道它的 PID。要想知道它的 PID,它必须去询问内核,因此,这个询问请求也是一个系统调用:
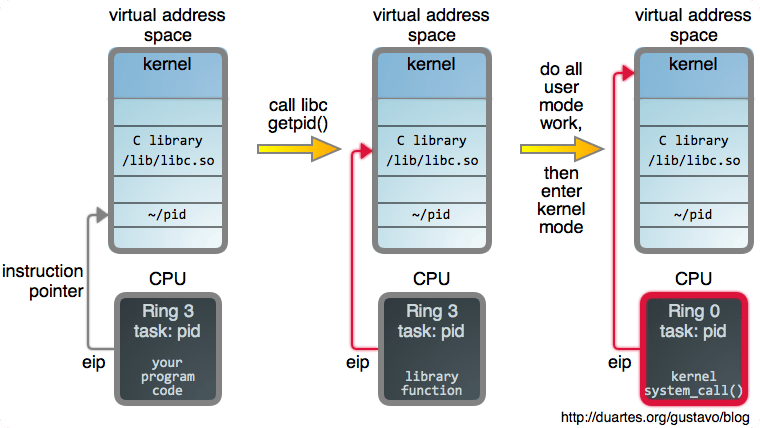
它的第一步是开始于调用 C 库的 getpid(),它是系统调用的一个封装。当你调用一些函数时,比如,open(2)、read(2) 之类,你是在调用这些封装。其实,对于大多数编程语言在这一块的原生方法,最终都是在 libc 中完成的。
封装为这些基本的操作系统 API 提供了方便,这样可以保持内核的简洁。所有的内核代码运行在特权模式下,有 bug 的内核代码行将会产生致命的后果。能在用户模式下做的任何事情都应该在用户模式中完成。由库来提供友好的方法和想要的参数处理,像 printf(3) 这样。
我们拿一个 web API 进行比较,内核的封装方式可以类比为构建一个尽可能简单的 HTTP 接口去提供服务,然后提供特定语言的库及辅助方法。或者也可能有一些缓存,这就是 libc 的 getpid() 所做的:首次调用时,它真实地去执行了一个系统调用,然后,它缓存了 PID,这样就可以避免后续调用时的系统调用开销。
一旦封装完成,它做的第一件事就是进入了内核 超空间 。这种转换机制因处理器架构设计不同而不同。在 Intel 处理器中,参数和 系统调用号 是 加载到寄存器中的,然后,运行一个 指令 将 CPU 置于 特权模式 中,并立即将控制权转移到内核中的全局系统调用 入口。如果你对这些细节感兴趣,David Drysdale 在 LWN 上有两篇非常好的文章(其一,其二)。
内核然后使用这个系统调用号作为进入 sys_call_table 的一个 索引,它是一个函数指针到每个系统调用实现的数组。在这里,调用了 sys_getpid:
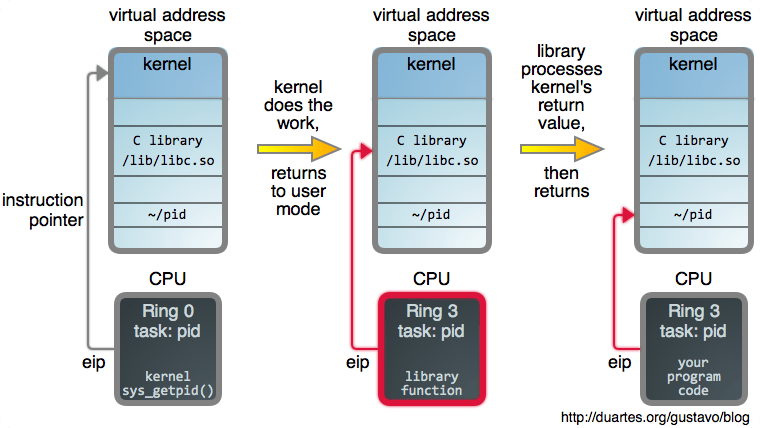
在 Linux 中,系统调用大多数都实现为架构无关的 C 函数,有时候这样做 很琐碎,但是通过内核优秀的设计,系统调用机制被严格隔离。它们是工作在一般数据结构中的普通代码。嗯,除了完全偏执的参数校验以外。
一旦它们的工作完成,它们就会正常返回,然后,架构特定的代码会接手转回到用户模式,封装将在那里继续做一些后续处理工作。在我们的例子中,getpid(2) 现在缓存了由内核返回的 PID。如果内核返回了一个错误,另外的封装可以去设置全局 errno 变量。这些细节可以让你知道 GNU 是怎么处理的。
如果你想要原生的调用,glibc 提供了 syscall(2) 函数,它可以不通过封装来产生一个系统调用。你也可以通过它来做一个你自己的封装。这对一个 C 库来说,既不神奇,也不特殊。
这种系统调用的设计影响是很深远的。我们从一个非常有用的 strace(1) 开始,这个工具可以用来监视 Linux 进程的系统调用(在 Mac 上,参见 dtruss(1m) 和神奇的 dtrace;在 Windows 中,参见 sysinternals)。这是对 pid 程序的跟踪:
~/code/x86-os$ strace ./pid
execve("./pid", ["./pid"], [/* 20 vars */]) = 0
brk(0) = 0x9aa0000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7767000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat64(3, {st_mode=S_IFREG|0644, st_size=18056, ...}) = 0
mmap2(NULL, 18056, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7762000
close(3) = 0
[...snip...]
getpid() = 14678
fstat64(1, {st_mode=S_IFCHR|0600, st_rdev=makedev(136, 1), ...}) = 0
mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7766000
write(1, "14678\n", 614678
) = 6
exit_group(6) = ?
输出的每一行都显示了一个系统调用、它的参数,以及返回值。如果你在一个循环中将 getpid(2) 运行 1000 次,你就会发现始终只有一个 getpid() 系统调用,因为,它的 PID 已经被缓存了。我们也可以看到在格式化输出字符串之后,printf(3) 调用了 write(2)。
strace 可以开始一个新进程,也可以附加到一个已经运行的进程上。你可以通过不同程序的系统调用学到很多的东西。例如,sshd 守护进程一天都在干什么?
~/code/x86-os$ ps ax | grep sshd
12218 ? Ss 0:00 /usr/sbin/sshd -D
~/code/x86-os$ sudo strace -p 12218
Process 12218 attached - interrupt to quit
select(7, [3 4], NULL, NULL, NULL
[
... nothing happens ...
No fun, it's just waiting for a connection using select(2)
If we wait long enough, we might see new keys being generated and so on, but
let's attach again, tell strace to follow forks (-f), and connect via SSH
]
~/code/x86-os$ sudo strace -p 12218 -f
[lots of calls happen during an SSH login, only a few shown]
[pid 14692] read(3, "-----BEGIN RSA PRIVATE KEY-----\n"..., 1024) = 1024
[pid 14692] open("/usr/share/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)
[pid 14692] open("/etc/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)
[pid 14692] open("/etc/ssh/ssh_host_dsa_key", O_RDONLY|O_LARGEFILE) = 3
[pid 14692] open("/etc/protocols", O_RDONLY|O_CLOEXEC) = 4
[pid 14692] read(4, "# Internet (IP) protocols\n#\n# Up"..., 4096) = 2933
[pid 14692] open("/etc/hosts.allow", O_RDONLY) = 4
[pid 14692] open("/lib/i386-linux-gnu/libnss_dns.so.2", O_RDONLY|O_CLOEXEC) = 4
[pid 14692] stat64("/etc/pam.d", {st_mode=S_IFDIR|0755, st_size=4096, ...}) = 0
[pid 14692] open("/etc/pam.d/common-password", O_RDONLY|O_LARGEFILE) = 8
[pid 14692] open("/etc/pam.d/other", O_RDONLY|O_LARGEFILE) = 4
看懂 SSH 的调用是块难啃的骨头,但是,如果搞懂它你就学会了跟踪。能够看到应用程序打开的是哪个文件是有用的(“这个配置是从哪里来的?”)。如果你有一个出现错误的进程,你可以 strace 它,然后去看它通过系统调用做了什么?当一些应用程序意外退出而没有提供适当的错误信息时,你可以去检查它是否有系统调用失败。你也可以使用过滤器,查看每个调用的次数,等等:
~/code/x86-os$ strace -T -e trace=recv curl -silent www.google.com. > /dev/null
recv(3, "HTTP/1.1 200 OK
Date: Wed, 05 N"..., 16384, 0) = 4164 <0.000007>
recv(3, "fl a{color:#36c}a:visited{color:"..., 16384, 0) = 2776 <0.000005>
recv(3, "adient(top,#4d90fe,#4787ed);filt"..., 16384, 0) = 4164 <0.000007>
recv(3, "gbar.up.spd(b,d,1,!0);break;case"..., 16384, 0) = 2776 <0.000006>
recv(3, "$),a.i.G(!0)),window.gbar.up.sl("..., 16384, 0) = 1388 <0.000004>
recv(3, "margin:0;padding:5px 8px 0 6px;v"..., 16384, 0) = 1388 <0.000007>
recv(3, "){window.setTimeout(function(){v"..., 16384, 0) = 1484 <0.000006>
我鼓励你在你的操作系统中的试验这些工具。把它们用好会让你觉得自己有超能力。
但是,足够有用的东西,往往要让我们深入到它的设计中。我们可以看到那些用户空间中的应用程序是被严格限制在它自己的虚拟地址空间里,运行在 Ring 3(非特权模式)中。一般来说,只涉及到计算和内存访问的任务是不需要请求系统调用的。例如,像 strlen(3) 和 memcpy(3) 这样的 C 库函数并不需要内核去做什么。这些都是在应用程序内部发生的事。
C 库函数的 man 页面所在的节(即圆括号里的 2 和 3)也提供了线索。节 2 是用于系统调用封装,而节 3 包含了其它 C 库函数。但是,正如我们在 printf(3) 中所看到的,库函数最终可以产生一个或者多个系统调用。
如果你对此感到好奇,这里是 Linux (也有 Filippo 的列表)和 Windows 的全部系统调用列表。它们各自有大约 310 和 460 个系统调用。看这些系统调用是非常有趣的,因为,它们代表了软件在现代的计算机上能够做什么。另外,你还可能在这里找到与进程间通讯和性能相关的“宝藏”。这是一个“不懂 Unix 的人注定最终还要重新发明一个蹩脚的 Unix ” 的地方。(LCTT 译注:原文 “Those who do not understand Unix are condemned to reinvent it,poorly。” 这句话是 Henry Spencer 的名言,反映了 Unix 的设计哲学,它的一些理念和文化是一种技术发展的必须结果,看似糟糕却无法超越。)
与 CPU 周期相比,许多系统调用花很长的时间去执行任务,例如,从一个硬盘驱动器中读取内容。在这种情况下,调用进程在底层的工作完成之前一直处于休眠状态。因为,CPU 运行的非常快,一般的程序都因为 I/O 的限制在它的生命周期的大部分时间处于休眠状态,等待系统调用返回。相反,如果你跟踪一个计算密集型任务,你经常会看到没有任何的系统调用参与其中。在这种情况下,top(1) 将显示大量的 CPU 使用。
在一个系统调用中的开销可能会是一个问题。例如,固态硬盘比普通硬盘要快很多,但是,操作系统的开销可能比 I/O 操作本身的开销 更加昂贵。执行大量读写操作的程序可能就是操作系统开销的瓶颈所在。向量化 I/O 对此有一些帮助。因此要做 文件的内存映射,它允许一个程序仅访问内存就可以读或写磁盘文件。类似的映射也存在于像视频卡这样的地方。最终,云计算的经济性可能导致内核消除或最小化用户模式/内核模式的切换。
最终,系统调用还有益于系统安全。一是,无论如何来历不明的一个二进制程序,你都可以通过观察它的系统调用来检查它的行为。这种方式可能用于去检测恶意程序。例如,我们可以记录一个未知程序的系统调用的策略,并对它的异常行为进行报警,或者对程序调用指定一个白名单,这样就可以让漏洞利用变得更加困难。在这个领域,我们有大量的研究,和许多工具,但是没有“杀手级”的解决方案。
这就是系统调用。很抱歉这篇文章有点长,我希望它对你有用。接下来的时间,我将写更多(短的)文章,也可以在 RSS 和 Twitter 关注我。这篇文章献给 glorious Clube Atlético Mineiro。
via:https://manybutfinite.com/post/system-calls/
作者:Gustavo Duarte 译者:qhwdw 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出