迁移到 Linux:安装软件
所有的 Linux 打包系统和工具都会让人迷惑,但是这篇面向初学者的教程可以帮助你搞明白。

如你所见,众所瞩目的 Linux 已经用在互联网,以及 Arduino、Beagle 和树莓派主板等设备上,或许你正在考虑是时候尝试一下 Linux 了。本系列将帮助你成功过渡到 Linux。如果你错过了本系列的早期文章,可以在这里找到它们:
安装软件
要在你的计算机上获得新软件,通常的方法是从供应商处获得软件产品,然后运行一个安装程序。过去,软件产品会出现在像 CD-ROM 或 DVD 一样的物理媒介上,而现在我们经常从互联网上下载软件产品。
使用 Linux,安装软件就像在你的智能手机上安装一样。如同你的手机应用商店一样,在 Linux 上有个提供开源软件工具和程序的 中央仓库 ,几乎任何你想要的程序都会出现在可用软件包列表中以供你安装。
每个程序并不需要运行单独的安装程序,而是你可以使用 Linux 发行版附带的软件包管理工具。(这里说的 Linux 发行版就是你安装的 Linux,例如 Ubuntu、Fedora、Debian 等)每个发行版在互联网上都有它自己的集中存储库(称为仓库),它们存储了数千个预先构建好的应用程序。
你可能会注意到,在 Linux 上安装软件有几种例外情况。有时候,你仍然需要去供应商那里获取他们的软件,因为该程序不存在于你的发行版的中央仓库中。当软件不是开源和/或自由软件的时候,通常就是这种情况。
另外请记住,如果你想要安装一个不在发行版仓库中的程序时,事情就不是那么简单了,即使你正在安装自由及开源程序。这篇文章没有涉及到这些更复杂的情况,请遵循在线的指引。
有了所有的 Linux 包管理系统和工具,接下来干什么可能仍然令人困惑。本文应该有助于澄清一些事情。
包管理
目前在 Linux 发行版中有几个相互竞争的用于管理、安装和删除软件的包管理系统。每个发行版都选择使用了一个 包管理工具 。Red Hat、Fedora、CentOS、Scientific Linux、SUSE 等使用 Red Hat 包管理(RPM)。Debian、Ubuntu、Linux Mint 等等都使用 Debian 包管理系统,简称 DPKG。还有一些其它包管理系统,但 RPM 和 DPKG 是最常见的。

图 1: Package installers
无论你使用的软件包管理是什么,它们通常都是一组构建于另外一种工具之上的工具(图 1)。最底层是一个命令行工具,它可以让你做任何与安装软件相关的一切工作。你可以列出已安装的程序、删除程序、安装软件包文件等等。
这个底层工具并不总是最方便使用的,所以通常会有一个命令行工具,它可以使用单个命令在发行版的中央仓库中找到软件包,并下载和安装它以及任何依赖项。最后,通常会有一个 图形应用程序 ,可以让你使用鼠标选择任何想要的内容,然后单击 “install” 按钮即可。
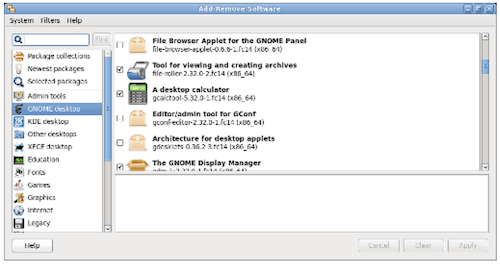
图 2: PackageKit
对于基于 Red Hat 的发行版,包括 Fedora、CentOS、Scientific Linux 等,它们的底层工具是 rpm,高级工具叫做 dnf(在旧系统上是 yum)。图形安装程序称为 PackageKit(图 2),它可能在系统管理菜单下显示名字为 “Add/Remove Software(添加/删除软件)”。
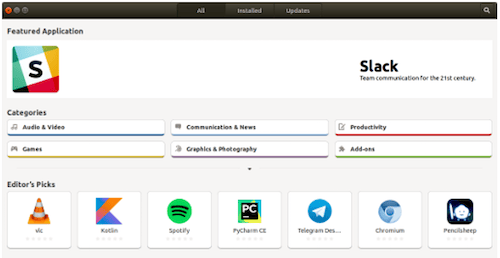
图 3: Ubuntu Software
对于基于 Debian 的发行版,包括 Debian、Ubuntu、Linux Mint、Elementary OS 等,它们的底层命令行工具是 dpkg,高级工具称为 apt。在 Ubuntu 上管理已安装软件的图形工具是 Ubuntu Software(图 3)。对于 Debian 和 Linux Mint,图形工具称为 新立得 ,它也可以安装在 Ubuntu 上。
你也可以在 Debian 相关发行版上安装一个基于文本的图形化工具 aptitude。它比 新立得 更强大,并且即使你只能访问命令行也能工作。如果你想通过各种选项进行各种“骚”操作,你可以试试这个,但它使用起来比新立得更复杂。其它发行版也可能有自己独特的工具。
命令行工具
在 Linux 上安装软件的在线说明通常描述了在命令行中键入的命令。这些说明通常更容易理解,并且将命令复制粘贴到命令行窗口中,可以在不出错的情况下一步步进行。这与下面的说明相反:“打开这个菜单,选择这个程序,输入这个搜索模式,点击这个标签,选择这个程序,然后点击这个按钮”,这经常让你在各种操作中迷失。
有时你正在使用的 Linux 没有图形环境,因此熟悉从命令行安装软件包是件好事。表 1 和表 2 列出了基于 RPM 和 DPKG 系统的一下常见操作及其相关命令。

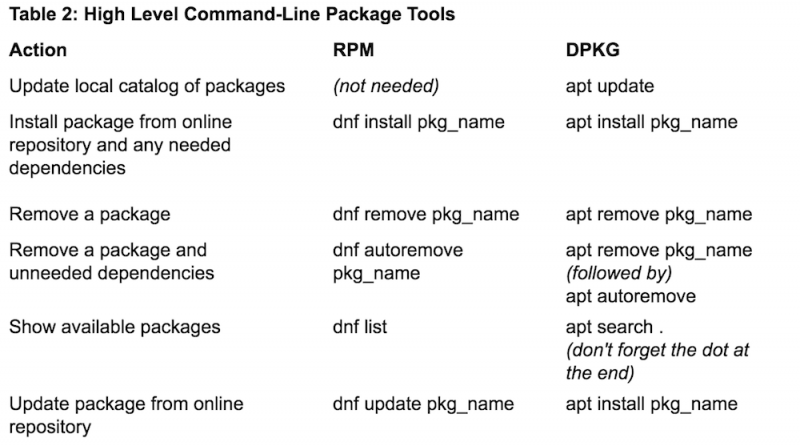
请注意 SUSE,它像 RedHat 和 Fedora 一样使用 RPM,却没有 dnf 或 yum。相反,它使用一个名为 zypper 的程序作为高级命令行工具。其他发行版也可能有不同的工具,例如 Arch Linux 上的 pacman 或 Gentoo 上的 emerge。有很多包管理工具,所以你可能需要查找哪个适用于你的发行版。
这些技巧应该能让你更好地了解如何在新的 Linux 中安装程序,以及更好地了解 Linux 中各种软件包管理方式如何相互关联。
通过 Linux 基金会和 edX 的免费 “Linux 入门”课程了解有关 Linux 的更多信息。
via: https://www.linux.com/blog/learn/2018/3/migrating-linux-installing-software
作者:JOHN BONESIO 译者:MjSeven 校对:pityonline, wxy