搭建属于你自己的 Git 服务器
在本文中,我们的目的是让你了解如何设置属于自己的Git服务器。

Git 是由 Linux Torvalds 开发的一个版本控制系统,现如今正在被全世界大量开发者使用。许多公司喜欢使用基于 Git 版本控制的 GitHub 代码托管。根据报道,GitHub 是现如今全世界最大的代码托管网站。GitHub 宣称已经有 920 万用户和 2180 万个仓库。许多大型公司现如今也将代码迁移到 GitHub 上。甚至于谷歌,一家搜索引擎公司,也正将代码迁移到 GitHub 上。
运行你自己的 Git 服务器
GitHub 能提供极佳的服务,但却有一些限制,尤其是你是单人或是一名 coding 爱好者。GitHub 其中之一的限制就是其中免费的服务没有提供代码私有托管业务。你不得不支付每月 7 美金购买 5 个私有仓库,并且想要更多的私有仓库则要交更多的钱。
万一你想要私有仓库或需要更多权限控制,最好的方法就是在你的服务器上运行 Git。不仅你能够省去一笔钱,你还能够在你的服务器有更多的操作。在大多数情况下,大多数高级 Linux 用户已经拥有自己的服务器,并且在这些服务器上方式 Git 就像“啤酒一样免费”(LCTT 译注:指免费软件)。
在这篇教程中,我们主要讲在你的服务器上,使用两种代码管理的方法。一种是运行一个纯 Git 服务器,另一个是使用名为 GitLab 的 GUI 工具。在本教程中,我在 VPS 上运行的操作系统是 Ubuntu 14.04 LTS。
在你的服务器上安装 Git
在本篇教程中,我们考虑一个简单案例,我们有一个远程服务器和一台本地服务器,现在我们需要使用这两台机器来工作。为了简单起见,我们就分别叫它们为远程服务器和本地服务器。
首先,在两边的机器上安装 Git。你可以从依赖包中安装 Git,在本文中,我们将使用更简单的方法:
sudo apt-get install git-core
为 Git 创建一个用户。
sudo useradd git
passwd git
为了容易的访问服务器,我们设置一个免密 ssh 登录。首先在你本地电脑上创建一个 ssh 密钥:
ssh-keygen -t rsa
这时会要求你输入保存密钥的路径,这时只需要点击回车保存在默认路径。第二个问题是输入访问远程服务器所需的密码。它生成两个密钥——公钥和私钥。记下您在下一步中需要使用的公钥的位置。
现在您必须将这些密钥复制到服务器上,以便两台机器可以相互通信。在本地机器上运行以下命令:
cat ~/.ssh/id_rsa.pub | ssh git@remote-server "mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys"
现在,用 ssh 登录进服务器并为 Git 创建一个项目路径。你可以为你的仓库设置一个你想要的目录。
现在跳转到该目录中:
cd /home/swapnil/project-1.git
现在新建一个空仓库:
git init --bare
Initialized empty Git repository in /home/swapnil/project-1.git
现在我们需要在本地机器上新建一个基于 Git 版本控制仓库:
mkdir -p /home/swapnil/git/project
进入我们创建仓库的目录:
cd /home/swapnil/git/project
现在在该目录中创建项目所需的文件。留在这个目录并启动 git:
git init
Initialized empty Git repository in /home/swapnil/git/project
把所有文件添加到仓库中:
git add .
现在,每次添加文件或进行更改时,都必须运行上面的 add 命令。 您还需要为每个文件更改都写入提交消息。提交消息基本上说明了我们所做的更改。
git commit -m "message" -a
[master (root-commit) 57331ee] message
2 files changed, 2 insertions(+)
create mode 100644 GoT.txt
create mode 100644 writing.txt
在这种情况下,我有一个名为 GoT(《权力的游戏》的点评)的文件,并且我做了一些更改,所以当我运行命令时,它指定对文件进行更改。 在上面的命令中 -a 选项意味着提交仓库中的所有文件。 如果您只更改了一个,则可以指定该文件的名称而不是使用 -a。
举一个例子:
git commit -m "message" GoT.txt
[master e517b10] message
1 file changed, 1 insertion(+)
到现在为止,我们一直在本地服务器上工作。现在我们必须将这些更改推送到远程服务器上,以便通过互联网访问,并且可以与其他团队成员进行协作。
git remote add origin ssh://git@remote-server/repo-<wbr< a="">>path-on-server..git
现在,您可以使用 pull 或 push 选项在服务器和本地计算机之间推送或拉取:
git push origin master
如果有其他团队成员想要使用该项目,则需要将远程服务器上的仓库克隆到其本地计算机上:
git clone git@remote-server:/home/swapnil/project.git
这里 /home/swapnil/project.git 是远程服务器上的项目路径,在你本机上则会改变。
然后进入本地计算机上的目录(使用服务器上的项目名称):
cd /project
现在他们可以编辑文件,写入提交更改信息,然后将它们推送到服务器:
git commit -m 'corrections in GoT.txt story' -a
然后推送改变:
git push origin master
我认为这足以让一个新用户开始在他们自己的服务器上使用 Git。 如果您正在寻找一些 GUI 工具来管理本地计算机上的更改,则可以使用 GUI 工具,例如 QGit 或 GitK for Linux。
使用 GitLab
这是项目所有者和协作者的纯命令行解决方案。这当然不像使用 GitHub 那么简单。不幸的是,尽管 GitHub 是全球最大的代码托管商,但是它自己的软件别人却无法使用。因为它不是开源的,所以你不能获取源代码并编译你自己的 GitHub。这与 WordPress 或 Drupal 不同,您无法下载 GitHub 并在您自己的服务器上运行它。
像往常一样,在开源世界中,是没有终结的尽头。GitLab 是一个非常优秀的项目。这是一个开源项目,允许用户在自己的服务器上运行类似于 GitHub 的项目管理系统。
您可以使用 GitLab 为团队成员或公司运行类似于 GitHub 的服务。您可以使用 GitLab 在公开发布之前开发私有项目。
GitLab 采用传统的开源商业模式。他们有两种产品:免费的开源软件,用户可以在自己的服务器上安装,以及类似于 GitHub 的托管服务。
可下载版本有两个版本,免费的社区版和付费企业版。企业版基于社区版,但附带针对企业客户的其他功能。它或多或少与 WordPress.org 或 Wordpress.com 提供的服务类似。
社区版具有高度可扩展性,可以在单个服务器或群集上支持 25000 个用户。GitLab 的一些功能包括:Git 仓库管理,代码评论,问题跟踪,活动源和维基。它配备了 GitLab CI,用于持续集成和交付。
Digital Ocean 等许多 VPS 提供商会为用户提供 GitLab 服务。 如果你想在你自己的服务器上运行它,你可以手动安装它。GitLab 为不同的操作系统提供了软件包。 在我们安装 GitLab 之前,您可能需要配置 SMTP 电子邮件服务器,以便 GitLab 可以在需要时随时推送电子邮件。官方推荐使用 Postfix。所以,先在你的服务器上安装 Postfix:
sudo apt-get install postfix
在安装 Postfix 期间,它会问你一些问题,不要跳过它们。 如果你一不小心跳过,你可以使用这个命令来重新配置它:
sudo dpkg-reconfigure postfix
运行此命令时,请选择 “Internet Site”并为使用 Gitlab 的域名提供电子邮件 ID。
我是这样输入的:
[email protected]
用 Tab 键并为 postfix 创建一个用户名。接下来将会要求你输入一个目标邮箱。
在剩下的步骤中,都选择默认选项。当我们安装且配置完成后,我们继续安装 GitLab。
我们使用 wget 来下载软件包(用 最新包 替换下载链接):
wget https://downloads-packages.s3.amazonaws.com/ubuntu-14.04/gitlab_7.9.4-omnibus.1-1_amd64.deb
然后安装这个包:
sudo dpkg -i gitlab_7.9.4-omnibus.1-1_amd64.deb
现在是时候配置并启动 GitLab 了。
sudo gitlab-ctl reconfigure
您现在需要在配置文件中配置域名,以便您可以访问 GitLab。打开文件。
nano /etc/gitlab/gitlab.rb
在这个文件中编辑 external_url 并输入服务器域名。保存文件,然后从 Web 浏览器中打开新建的一个 GitLab 站点。
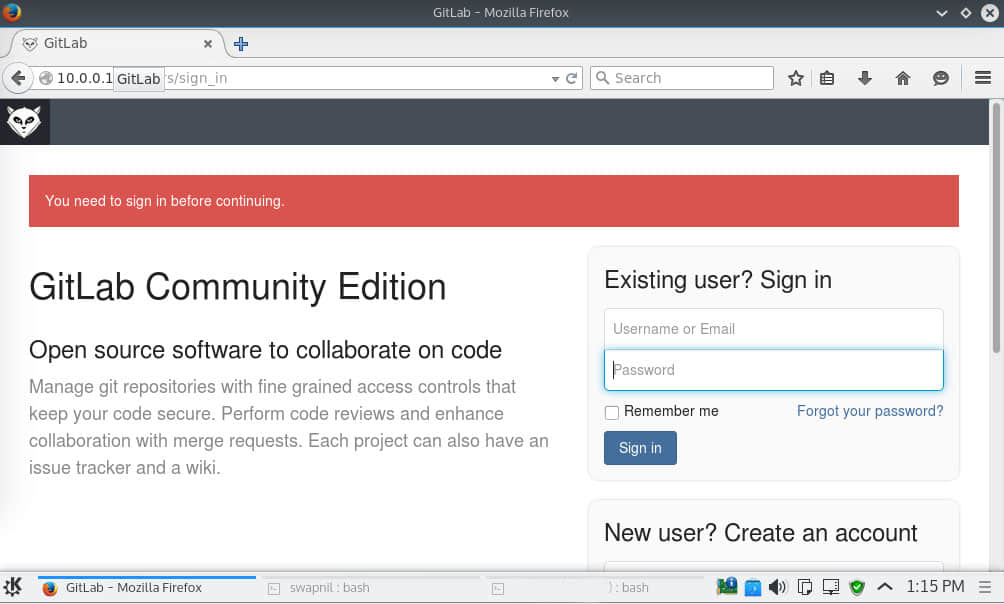
默认情况下,它会以系统管理员的身份创建 root,并使用 5iveL!fe 作为密码。 登录到 GitLab 站点,然后更改密码。
密码更改后,登录该网站并开始管理您的项目。
GitLab 有很多选项和功能。最后,我借用电影“黑客帝国”中的经典台词:“不幸的是,没有人知道 GitLab 可以做什么。你必须亲自尝试一下。”
via: https://www.linux.com/learn/how-run-your-own-git-server
作者:Swapnil Bhartiya 选题:lujun9972 译者:wyxplus 校对:wxy




