在 Linux 中如何以人性化的方式显示数据
许多 Linux 命令现在都有使其输出更易于理解的选项。让我们了解一些可以让我们心爱的操作系统更友好的东西。

不是每个人都以二进制方式思考,他们不想在大脑中给大数字插入逗号来了解文件的大小。因此,Linux 命令在过去的几十年里不断发展,以更人性化的方式向用户显示信息,这一点也不奇怪。在今天的文章中,我们将看一看各种命令所提供的一些选项,它们使得数据变得更容易理解。
为什么默认显示不更友好一些?
如果你想知道为什么默认不显示得更人性化,毕竟,我们人类才是计算机的默认用户啊。你可能会问自己:“为什么我们不竭尽全力输出对每个人都有意义的命令的响应?”主要的答案是:改变命令的默认输出可能会干扰许多其它进程,这些进程是在期望默认响应之上构建的。其它的工具,以及过去几十年开发的脚本,如果突然以一种完全不同的格式输出,而不是它们过去所期望的那样,可能会被一种非常丑陋的方式破坏。
说真的,也许我们中的一些人可能更愿意看文件大小中的所有数字,即 1338277310 而不是 1.3G。在任何情况下,切换默认习惯都可能造成破坏,但是为更加人性化的响应提供一些简单的选项只需要让我们学习一些命令选项而已。
可以显示人性化数据的命令
有哪些简单的选项可以使 Unix 命令的输出更容易解析呢?让我们来看一些命令。
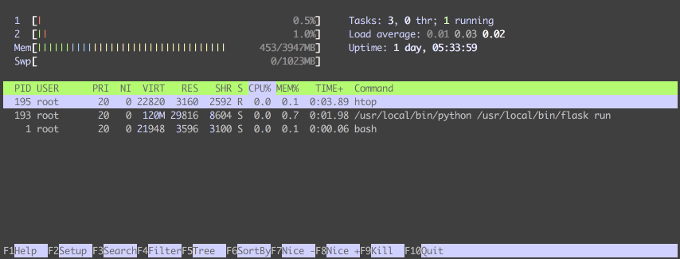
top
你可能没有注意到这个命令,但是在 top 命令中,你可以通过输入 E(大写字母 E)来更改显示全部内存使用的方式。连续按下将数字显示从 KiB 到 MiB,再到 GiB,接着是 TiB、PiB、EiB,最后回到 KiB。
认识这些单位吧?这里有一组定义:
2`10 = 1,024 = 1 KiB (kibibyte)
2`20 = 1,048,576 = 1 MiB (mebibyte)
2`30 = 1,073,741,824 = 1 GiB (gibibyte)
2`40 = 1,099,511,627,776 = 1 TiB (tebibyte)
2`50 = 1,125,899,906,842,624 = PiB (pebibyte)
2`60 = 1,152,921,504,606,846,976 = EiB (exbibyte)
2`70 = 1,180,591,620,717,411,303,424 = 1 ZiB (zebibyte)
2`80 = 1,208,925,819,614,629,174,706,176 = 1 YiB (yobibyte)这些单位与千字节(KB)、兆字节(MB)和千兆字节(GB)密切相关。虽然它们很接近,但是它们之间仍有很大的区别:一组是基于 10 的幂,另一组是基于 2 的幂。例如,比较千字节和千兆字节,我们可以看看它们不同点:
KB = 1000 = 10`3
KiB = 1024 = 2`10以下是 top 命令输出示例,使用 KiB 为单位默认显示:
top - 10:49:06 up 5 days, 35 min, 1 user, load average: 0.05, 0.04, 0.01
Tasks: 158 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 6102680 total, 4634980 free, 392244 used, 1075456 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 5407432 avail Mem在按下 E 之后,单位变成了 MiB:
top - 10:49:31 up 5 days, 36 min, 1 user, load average: 0.03, 0.04, 0.01
Tasks: 158 total, 2 running, 118 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.6 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 5959.648 total, 4526.348 free, 383.055 used, 1050.246 buff/cache
MiB Swap: 2047.996 total, 2047.996 free, 0.000 used. 5280.684 avail Mem再次按下 E,单位变为 GiB:
top - 10:49:49 up 5 days, 36 min, 1 user, load average: 0.02, 0.03, 0.01
Tasks: 158 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
GiB Mem : 5.820 total, 4.420 free, 0.374 used, 1.026 buff/cache
GiB Swap: 2.000 total, 2.000 free, 0.000 used. 5.157 avail Mem你还可以通过按字母 e 来更改为显示每个进程使用内存的数字单位。它将从默认的 KiB 到 MiB,再到 GiB、TiB,接着到 PiB(估计你能看到小数点后的很多 0),然后返回 KiB。下面是按了一下 e 之后的 top 输出:
top - 08:45:28 up 4 days, 22:32, 1 user, load average: 0.02, 0.03, 0.00
Tasks: 167 total, 1 running, 118 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.0 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 6102680 total, 4641836 free, 393348 used, 1067496 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 5406396 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
784 root 20 0 543.2m 26.8m 16.1m S 0.9 0.5 0:22.20 snapd
733 root 20 0 107.8m 2.0m 1.8m S 0.4 0.0 0:18.49 irqbalance
22574 shs 20 0 107.5m 5.5m 4.6m S 0.4 0.1 0:00.09 sshd
1 root 20 0 156.4m 9.3m 6.7m S 0.0 0.2 0:05.59 systemddu
du 命令显示磁盘空间文件或目录使用了多少,如果使用 -h 选项,则将输出大小调整为最合适的单位。默认情况下,它以千字节(KB)为单位。
$ du camper*
360 camper_10.jpg
5684 camper.jpg
240 camper_small.jpg
$ du -h camper*
360K camper_10.jpg
5.6M camper.jpg
240K camper_small.jpgdf
df 命令也提供了一个 -h 选项。请注意在下面的示例中是如何以千兆字节(GB)和兆字节(MB)输出的:
$ df -h | grep -v loop
Filesystem Size Used Avail Use% Mounted on
udev 2.9G 0 2.9G 0% /dev
tmpfs 596M 1.7M 595M 1% /run
/dev/sda1 110G 9.0G 95G 9% /
tmpfs 3.0G 0 3.0G 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 3.0G 0 3.0G 0% /sys/fs/cgroup
tmpfs 596M 16K 596M 1% /run/user/121
/dev/sdb2 457G 73M 434G 1% /apps
tmpfs 596M 0 596M 0% /run/user/1000下面的命令使用了 -h 选项,同时使用 -T 选项来显示我们正在查看的文件系统的类型。
$ df -hT /mnt2
Filesystem Type Size Used Avail Use% Mounted on
/dev/sdb2 ext4 457G 73M 434G 1% /appsls
即使是 ls,它也为我们提供了调整大小显示的选项,保证是最合理的单位。
$ ls -l camper*
-rw-rw-r-- 1 shs shs 365091 Jul 14 19:42 camper_10.jpg
-rw-rw-r-- 1 shs shs 5818597 Jul 14 19:41 camper.jpg
-rw-rw-r-- 1 shs shs 241844 Jul 14 19:45 camper_small.jpg
$ ls -lh camper*
-rw-rw-r-- 1 shs shs 357K Jul 14 19:42 camper_10.jpg
-rw-rw-r-- 1 shs shs 5.6M Jul 14 19:41 camper.jpg
-rw-rw-r-- 1 shs shs 237K Jul 14 19:45 camper_small.jpgfree
free 命令允许你以字节(B),千字节(KB),兆字节(MB)和千兆字节(GB)为单位查看内存使用情况。
$ free -b
total used free shared buff/cache available
Mem: 6249144320 393076736 4851625984 1654784 1004441600 5561253888
Swap: 2147479552 0 2147479552
$ free -k
total used free shared buff/cache available
Mem: 6102680 383836 4737924 1616 980920 5430932
Swap: 2097148 0 2097148
$ free -m
total used free shared buff/cache available
Mem: 5959 374 4627 1 957 5303
Swap: 2047 0 2047
$ free -g
total used free shared buff/cache available
Mem: 5 0 4 0 0 5
Swap: 1 0 1tree
虽然 tree 命令与文件或内存计算无关,但它也提供了非常人性化的文件视图,它分层显示文件以说明文件是如何组织的。当你试图了解如何安排目录内容时,这种显示方式非常有用。(LCTT 译注:也可以看看 pstree,它以树状结构显示进程树。)
$ tree
.g to
├── 123
├── appended.png
├── appts
├── arrow.jpg
├── arrow.png
├── bin
│ ├── append
│ ├── cpuhog1
│ ├── cpuhog2
│ ├── loop
│ ├── mkhome
│ ├── runmestat
stat 命令是另一个以非常人性化的格式显示信息的命令。它提供了更多关于文件的元数据,包括文件大小(以字节和块为单位)、文件类型、设备和 inode(索引节点)、文件所有者和组(名称和数字 ID)、以数字和 rwx 格式显示的文件权限以及文件的最后访问和修改日期。在某些情况下,它也可能显示最初创建文件的时间。
$ stat camper*
File: camper_10.jpg
Size: 365091 Blocks: 720 IO Block: 4096 regular file
Device: 801h/2049d Inode: 796059 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
Access: 2018-07-19 18:56:31.841013385 -0400
Modify: 2018-07-14 19:42:25.230519509 -0400
Change: 2018-07-14 19:42:25.230519509 -0400
Birth: -
File: camper.jpg
Size: 5818597 Blocks: 11368 IO Block: 4096 regular file
Device: 801h/2049d Inode: 796058 Links: 1
Access: (0664/-rw-rw-r--) Uid: ( 1000/ shs) Gid: ( 1000/ shs)
Access: 2018-07-19 18:56:31.845013872 -0400
Modify: 2018-07-14 19:41:46.882024039 -0400
Change: 2018-07-14 19:41:46.882024039 -0400
Birth: -总结
Linux 命令提供了许多选项,可以让用户更容易理解或比较它们的输出。对于许多命令,-h 选项会显示更友好的输出格式。对于其它的,你可能必须通过使用某些特定选项或者按下某个键来查看你希望的输出。我希望这其中一些选项会让你的 Linux 系统看起来更友好一点。
作者:Sandra Henry-Stocker 选题:lujun9972 译者:MjSeven 校对:wxy





{kind=link}