Linux 并不像 Windows,你经常不会有图形界面可供使用,特别是在服务器环境中。
作为一名 Linux 管理员,知道如何获取当前可用的和已经使用的资源情况,比如内存、CPU、磁盘等,是相当重要的。如果某一应用在你的系统上占用了太多的资源,导致你的系统无法达到最优状态,那么你需要找到并修正它。
如果你想找到消耗内存前十名的进程,你需要去阅读这篇文章:如何在 Linux 中找出内存消耗最大的进程。
在 Linux 中,命令能做任何事,所以使用相关命令吧。在这篇教程中,我们将会给你展示 8 个有用的命令来即查看在 Linux 系统中内存的使用情况,包括 RAM 和交换分区。
创建交换分区在 Linux 系统中是非常重要的,如果你想了解如何创建,可以去阅读这篇文章:在 Linux 系统上创建交换分区。
下面的命令可以帮助你以不同的方式查看 Linux 内存使用情况。
free 命令/proc/meminfo 文件vmstat 命令ps_mem 命令smem 命令top 命令htop 命令glances 命令
1)如何使用 free 命令查看 Linux 内存使用情况
free 命令 是被 Linux 管理员广泛使用的主要命令。但是它提供的信息比 /proc/meminfo 文件少。
free 命令会分别展示物理内存和交换分区内存中已使用的和未使用的数量,以及内核使用的缓冲区和缓存。
这些信息都是从 /proc/meminfo 文件中获取的。
# free -m
total used free shared buff/cache available
Mem: 15867 9199 1702 3315 4965 3039
Swap: 17454 666 16788
total:总的内存量used:被当前运行中的进程使用的内存量(used = total – free – buff/cache)free: 未被使用的内存量(free = total – used – buff/cache)shared: 在两个或多个进程之间共享的内存量buffers: 内存中保留用于内核记录进程队列请求的内存量cache: 在 RAM 中存储最近使用过的文件的页缓冲大小buff/cache: 缓冲区和缓存总的使用内存量available: 可用于启动新应用的可用内存量(不含交换分区)
2) 如何使用 /proc/meminfo 文件查看 Linux 内存使用情况
/proc/meminfo 文件是一个包含了多种内存使用的实时信息的虚拟文件。它展示内存状态单位使用的是 kB,其中大部分属性都难以理解。然而它也包含了内存使用情况的有用信息。
# cat /proc/meminfo
MemTotal: 16248572 kB
MemFree: 1764576 kB
MemAvailable: 3136604 kB
Buffers: 234132 kB
Cached: 4731288 kB
SwapCached: 28516 kB
Active: 9004412 kB
Inactive: 3552416 kB
Active(anon): 8094128 kB
Inactive(anon): 2896064 kB
Active(file): 910284 kB
Inactive(file): 656352 kB
Unevictable: 80 kB
Mlocked: 80 kB
SwapTotal: 17873388 kB
SwapFree: 17191328 kB
Dirty: 252 kB
Writeback: 0 kB
AnonPages: 7566736 kB
Mapped: 3692368 kB
Shmem: 3398784 kB
Slab: 278976 kB
SReclaimable: 125480 kB
SUnreclaim: 153496 kB
KernelStack: 23936 kB
PageTables: 73880 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 25997672 kB
Committed_AS: 24816804 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 0 kB
VmallocChunk: 0 kB
Percpu: 3392 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
DirectMap4k: 1059088 kB
DirectMap2M: 14493696 kB
DirectMap1G: 2097152 kB
3) 如何使用 vmstat 命令查看 Linux 内存使用情况
vmstat 命令 是另一个报告虚拟内存统计信息的有用工具。
vmstat 报告的信息包括:进程、内存、页面映射、块 I/O、陷阱、磁盘和 CPU 特性信息。vmstat 不需要特殊的权限,并且它可以帮助诊断系统瓶颈。
# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 682060 1769324 234188 4853500 0 3 25 91 31 16 34 13 52 0 0
如果你想详细了解每一项的含义,阅读下面的描述。
procs:进程
r: 可以运行的进程数目(正在运行或等待运行)b: 处于不可中断睡眠中的进程数目
memory:内存
swpd: 使用的虚拟内存数量free: 空闲的内存数量buff: 用作缓冲区内存的数量cache: 用作缓存内存的数量inact: 不活动的内存数量(使用 -a 选项)active: 活动的内存数量(使用 -a 选项)
Swap:交换分区
si: 每秒从磁盘交换的内存数量so: 每秒交换到磁盘的内存数量
IO:输入输出
bi: 从一个块设备中收到的块(块/秒)bo: 发送到一个块设备的块(块/秒)
System:系统
in: 每秒的中断次数,包括时钟。cs: 每秒的上下文切换次数。
CPU:下面这些是在总的 CPU 时间占的百分比
us: 花费在非内核代码上的时间占比(包括用户时间,调度时间)sy: 花费在内核代码上的时间占比 (系统时间)id: 花费在闲置的时间占比。在 Linux 2.5.41 之前,包括 I/O 等待时间wa: 花费在 I/O 等待上的时间占比。在 Linux 2.5.41 之前,包括在空闲时间中st: 被虚拟机偷走的时间占比。在 Linux 2.6.11 之前,这部分称为 unknown
运行下面的命令查看详细的信息。
# vmstat -s
16248580 K total memory
2210256 K used memory
2311820 K active memory
2153352 K inactive memory
11368812 K free memory
107584 K buffer memory
2561928 K swap cache
17873388 K total swap
0 K used swap
17873388 K free swap
44309 non-nice user cpu ticks
164 nice user cpu ticks
14332 system cpu ticks
382418 idle cpu ticks
1248 IO-wait cpu ticks
1407 IRQ cpu ticks
2147 softirq cpu ticks
0 stolen cpu ticks
1022437 pages paged in
260296 pages paged out
0 pages swapped in
0 pages swapped out
1424838 interrupts
4979524 CPU context switches
1577163147 boot time
3318 forks
4) 如何使用 ps\_mem 命令查看 Linux 内存使用情况
ps\_mem 是一个用来查看当前内存使用情况的简单的 Python 脚本。该工具可以确定每个程序使用了多少内存(不是每个进程)。
该工具采用如下的方法计算每个程序使用内存:总的使用 = 程序进程私有的内存 + 程序进程共享的内存。
计算共享内存是存在不足之处的,该工具可以为运行中的内核自动选择最准确的方法。
# ps_mem
Private + Shared = RAM used Program
180.0 KiB + 30.0 KiB = 210.0 KiB xf86-video-intel-backlight-helper (2)
192.0 KiB + 66.0 KiB = 258.0 KiB cat (2)
312.0 KiB + 38.5 KiB = 350.5 KiB lvmetad
380.0 KiB + 25.5 KiB = 405.5 KiB crond
392.0 KiB + 32.5 KiB = 424.5 KiB rtkit-daemon
852.0 KiB + 117.0 KiB = 969.0 KiB gnome-session-ctl (2)
928.0 KiB + 56.5 KiB = 984.5 KiB gvfs-mtp-volume-monitor
1.0 MiB + 42.5 KiB = 1.0 MiB dconf-service
1.0 MiB + 106.5 KiB = 1.1 MiB gvfs-goa-volume-monitor
1.0 MiB + 180.5 KiB = 1.2 MiB gvfsd
.
.
5.3 MiB + 3.0 MiB = 8.3 MiB evolution-addressbook-factory
8.5 MiB + 1.2 MiB = 9.7 MiB gnome-session-binary (4)
7.5 MiB + 3.1 MiB = 10.5 MiB polkitd
7.4 MiB + 3.3 MiB = 10.7 MiB pulseaudio (2)
7.0 MiB + 7.0 MiB = 14.0 MiB msm_notifier
12.7 MiB + 2.3 MiB = 15.0 MiB evolution-source-registry
13.3 MiB + 2.5 MiB = 15.8 MiB gnome-terminal-server
15.8 MiB + 1.0 MiB = 16.8 MiB tracker-miner-fs
18.7 MiB + 1.8 MiB = 20.5 MiB python3.7
16.6 MiB + 4.0 MiB = 20.5 MiB evolution-calendar-factory
22.3 MiB + 753.0 KiB = 23.0 MiB gsd-keyboard (2)
22.4 MiB + 832.0 KiB = 23.2 MiB gsd-wacom (2)
20.8 MiB + 2.5 MiB = 23.3 MiB blueman-tray
22.0 MiB + 1.8 MiB = 23.8 MiB blueman-applet
23.1 MiB + 934.0 KiB = 24.0 MiB gsd-xsettings (2)
23.7 MiB + 1.2 MiB = 24.9 MiB gsd-media-keys (2)
23.4 MiB + 1.6 MiB = 25.0 MiB gsd-color (2)
23.9 MiB + 1.2 MiB = 25.1 MiB gsd-power (2)
16.5 MiB + 8.9 MiB = 25.4 MiB evolution-alarm-notify
27.2 MiB + 2.0 MiB = 29.2 MiB systemd-journald
28.7 MiB + 2.8 MiB = 31.5 MiB c
29.6 MiB + 2.2 MiB = 31.8 MiB chrome-gnome-sh (2)
43.9 MiB + 6.8 MiB = 50.7 MiB WebExtensions
46.7 MiB + 6.7 MiB = 53.5 MiB goa-daemon
86.5 MiB + 55.2 MiB = 141.7 MiB Xorg (2)
191.4 MiB + 24.1 MiB = 215.4 MiB notepadqq-bin
306.7 MiB + 29.0 MiB = 335.7 MiB gnome-shell (2)
601.6 MiB + 77.7 MiB = 679.2 MiB firefox
1.0 GiB + 109.7 MiB = 1.1 GiB chrome (15)
2.3 GiB + 123.1 MiB = 2.5 GiB Web Content (8)
----------------------------------
5.6 GiB
==================================
5)如何使用 smem 命令查看 Linux 内存使用情况
smem 是一个可以为 Linux 系统提供多种内存使用情况报告的工具。不同于现有的工具,smem 可以报告 比例集大小 (PSS)、 唯一集大小 (USS)和 驻留集大小 (RSS)。
- 比例集大小(PSS):库和应用在虚拟内存系统中的使用量。
- 唯一集大小(USS):其报告的是非共享内存。
- 驻留集大小(RSS):物理内存(通常多进程共享)使用情况,其通常高于内存使用量。
# smem -tk
PID User Command Swap USS PSS RSS
3383 daygeek cat 0 92.0K 123.0K 1.7M
3384 daygeek cat 0 100.0K 129.0K 1.7M
1177 daygeek /usr/lib/gnome-session-ctl 0 436.0K 476.0K 4.6M
1171 daygeek /usr/bin/dbus-daemon --conf 0 524.0K 629.0K 3.8M
1238 daygeek /usr/lib/xdg-permission-sto 0 592.0K 681.0K 5.9M
1350 daygeek /usr/lib/gsd-screensaver-pr 0 652.0K 701.0K 5.8M
1135 daygeek /usr/lib/gdm-x-session --ru 0 648.0K 723.0K 6.0M
.
.
1391 daygeek /usr/lib/evolution-data-ser 0 16.5M 25.2M 63.3M
1416 daygeek caffeine-ng 0 28.7M 31.4M 66.2M
4855 daygeek /opt/google/chrome/chrome - 0 38.3M 46.3M 120.6M
2174 daygeek /usr/lib/firefox/firefox -c 0 44.0M 50.7M 120.3M
1254 daygeek /usr/lib/goa-daemon 0 46.7M 53.3M 80.4M
3416 daygeek /opt/google/chrome/chrome - 0 44.7M 54.2M 103.3M
4782 daygeek /opt/google/chrome/chrome - 0 57.2M 65.8M 142.3M
1137 daygeek /usr/lib/Xorg vt2 -displayf 0 77.2M 129.6M 192.3M
3376 daygeek /opt/google/chrome/chrome 0 117.8M 131.0M 210.9M
4448 daygeek /usr/lib/firefox/firefox -c 0 124.4M 133.8M 224.1M
3558 daygeek /opt/google/chrome/chrome - 0 157.3M 165.7M 242.2M
2310 daygeek /usr/lib/firefox/firefox -c 0 159.6M 169.4M 259.6M
4331 daygeek /usr/lib/firefox/firefox -c 0 176.8M 186.2M 276.8M
4034 daygeek /opt/google/chrome/chrome - 0 179.3M 187.9M 264.6M
3911 daygeek /opt/google/chrome/chrome - 0 183.1M 191.8M 269.4M
3861 daygeek /opt/google/chrome/chrome - 0 199.8M 208.2M 285.2M
2746 daygeek /usr/bin/../lib/notepadqq/n 0 193.5M 217.5M 261.5M
1194 daygeek /usr/bin/gnome-shell 0 203.7M 219.0M 285.1M
2945 daygeek /usr/lib/firefox/firefox -c 0 294.5M 308.0M 410.2M
2786 daygeek /usr/lib/firefox/firefox -c 0 341.2M 354.3M 459.1M
4193 daygeek /usr/lib/firefox/firefox -c 0 417.4M 427.6M 519.3M
2651 daygeek /usr/lib/firefox/firefox -c 0 417.0M 430.1M 535.6M
2114 daygeek /usr/lib/firefox/firefox -c 0 430.6M 473.9M 610.9M
2039 daygeek /usr/lib/firefox/firefox -- 0 601.3M 677.5M 840.6M
-------------------------------------------------------------------------------
90 1 0 4.8G 5.2G 8.0G
6) 如何使用 top 命令查看 Linux 内存使用情况
top 命令 是一个 Linux 系统的管理员最常使用的用于查看进程的资源使用情况的命令。
该命令会展示了系统总的内存量、当前内存使用量、空闲内存量和缓冲区使用的内存总量。此外,该命令还会展示总的交换空间内存量、当前交换空间的内存使用量、空闲的交换空间内存量和缓存使用的内存总量。
# top -b | head -10
top - 11:04:39 up 40 min, 1 user, load average: 1.59, 1.42, 1.28
Tasks: 288 total, 2 running, 286 sleeping, 0 stopped, 0 zombie
%Cpu(s): 13.3 us, 1.5 sy, 0.0 ni, 84.4 id, 0.0 wa, 0.3 hi, 0.5 si, 0.0 st
KiB Mem : 16248572 total, 7755928 free, 4657736 used, 3834908 buff/cache
KiB Swap: 17873388 total, 17873388 free, 0 used. 9179772 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2114 daygeek 20 3182736 616624 328228 R 83.3 3.8 7:09.72 Web Content
2039 daygeek 20 4437952 849616 261364 S 13.3 5.2 7:58.54 firefox
1194 daygeek 20 4046856 291288 165460 S 4.2 1.8 1:57.68 gnome-shell
4034 daygeek 20 808556 273244 88676 S 4.2 1.7 1:44.72 chrome
2945 daygeek 20 3309832 416572 150112 S 3.3 2.6 4:04.60 Web Content
1137 daygeek 20 564316 197292 183380 S 2.5 1.2 2:55.76 Xorg
2651 daygeek 20 3098420 547260 275700 S 1.7 3.4 2:15.96 Web Content
2786 daygeek 20 2957112 463912 240744 S 1.7 2.9 3:22.29 Web Content
1 root 20 182756 10208 7760 S 0.8 0.1 0:04.51 systemd
442 root -51 S 0.8 0:05.02 irq/141-iw+
1426 daygeek 20 373660 48948 29820 S 0.8 0.3 0:03.55 python3
2174 daygeek 20 2466680 122196 78604 S 0.8 0.8 0:17.75 WebExtensi+
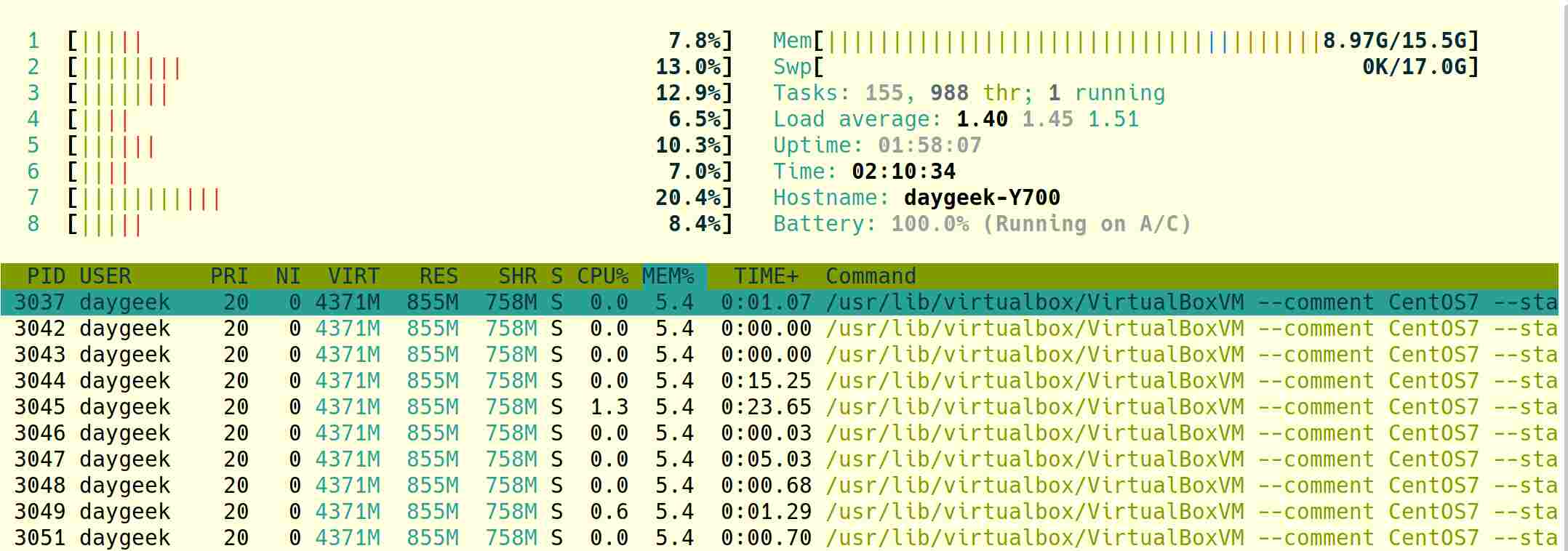
7) 如何使用 htop 命令查看 Linux 内存使用情况
htop 命令 是一个可交互的 Linux/Unix 系统进程查看器。它是一个文本模式应用,且使用它需要 Hisham 开发的 ncurses 库。
该名令的设计目的使用来代替 top 命令。该命令与 top 命令很相似,但是其允许你可以垂直地或者水平地的滚动以便可以查看系统中所有的进程情况。
htop 命令拥有不同的颜色,这个额外的优点当你在追踪系统性能情况时十分有用。
此外,你可以自由地执行与进程相关的任务,比如杀死进程或者改变进程的优先级而不需要其进程号(PID)。
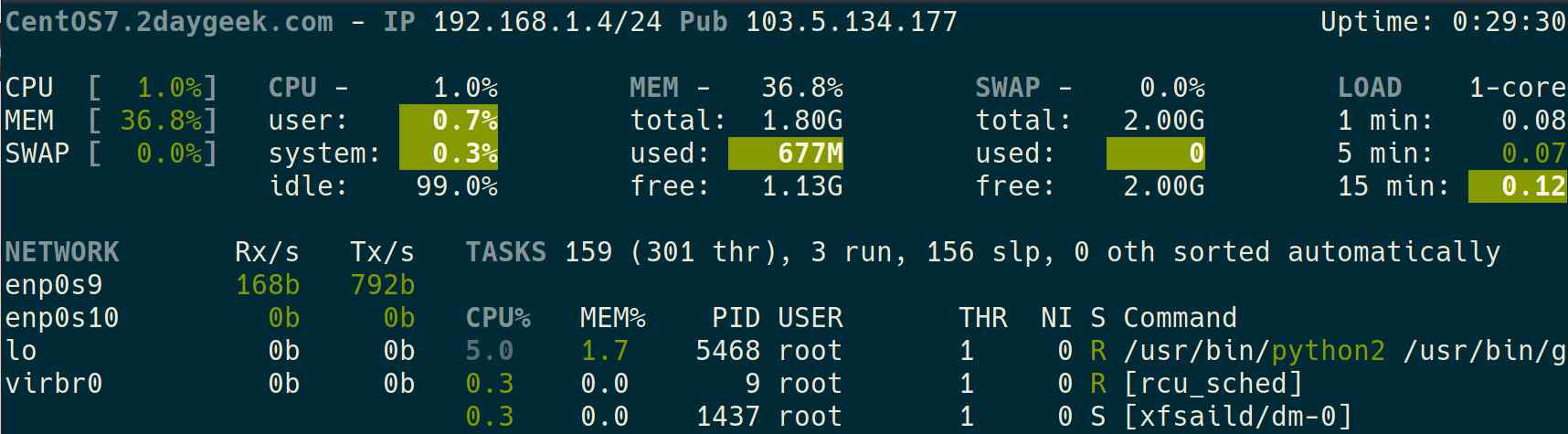
8)如何使用 glances 命令查看 Linux 内存使用情况
Glances 是一个 Python 编写的跨平台的系统监视工具。
你可以在一个地方查看所有信息,比如:CPU 使用情况、内存使用情况、正在运行的进程、网络接口、磁盘 I/O、RAID、传感器、文件系统信息、Docker、系统信息、运行时间等等。
via: https://www.2daygeek.com/linux-commands-check-memory-usage/
作者:Magesh Maruthamuthu 选题:lujun9972 译者:萌新阿岩 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出