我的一些 nix 学习经验:安装和打包

最近,我首次尝试了 Mac。直至现在,我注意到的最大缺点是其软件包管理比 Linux 差很多。一段时间以来,我对于 homebrew 感到相当不满,因为每次我安装新的软件包时,它大部分时间都花在了升级上。于是,我萌生了试试 nix 包管理器的想法!
公认的,nix 的使用存在一定困惑性(甚至它有自己单独的编程语言!),因此,我一直在努力以最简洁的方式掌握使用 nix,避开复杂的配置文件管理和新编程语言学习。以下是我至今为止学习到的内容, 敬请期待如何进行:
如同以往,由于我对 nix 的了解还停留在入门阶段,本篇文章可能存在一些表述不准确的地方。甚至我自己也对于我是否真的喜欢上 nix 感到模棱两可 —— 它的使用真的让人相当困惑!但是,它帮我成功编译了一些以前总是难以编译的软件,并且通常来说,它比 homebrew 的安装速度要快。
nix 为何引人关注?
通常,人们把 nix 定义为一种“声明式的包管理”。尽管我对此并不太感兴趣,但以下是我对 nix 的两个主要欣赏之处:
- 它提供了二进制包(托管在 https://cache.nixos.org/ 上),你可以迅速下载并安装
- 对于那些没有二进制包的软件,nix 使编译它们变得更容易
我认为 nix 之所以擅长于编译软件,主要有以下两个原因:
- 在你的系统中,可以安装同一库或程序的多个版本(例如,你可能有两个不同版本的 libc)。举个例子,我当前的计算机上就存在两个版本的 node,一个位于
/nix/store/4ykq0lpvmskdlhrvz1j3kwslgc6c7pnv-nodejs-16.17.1,另一个位于/nix/store/5y4bd2r99zhdbir95w5pf51bwfg37bwa-nodejs-18.9.1。 - 除此之外,nix 在构建包时是在隔离的环境下进行的,只使用你明确声明的依赖项的特定版本。因此,你无需担心这个包可能依赖于你的系统里的其它你并不了解的包,再也不用与
LD_LIBRARY_PATH战斗了!许多人投入了大量工作,来列出所有包的依赖项。
在本文后面,我将给出两个例子,展示 nix 如何使我在编译软件时遇到了更小的困难。
我是如何开始使用 nix 的
下面是我开始使用 nix 的步骤:
- 安装 nix。我忘记了我当时是如何做到这一点,但看起来有一个官方安装程序 和一个来自 zero-to-nix.com 的 非官方安装程序。在 MacOS 上使用标准的多用户安装卸载 nix 的 教程 有点复杂,所以选择一个卸载教程更为简单的安装方法可能值得。
- 把
~/.nix-profile/bin添加到我的PATH - 用
nix-env -iA nixpkgs.NAME命令安装包 - 就是这样。
基本上,是把 nix-env -iA 当作 brew install 或者 apt-get install。
例如,如果我想安装 fish,我可以这样做:
nix-env -iA nixpkgs.fish
这看起来就像是从 https://cache.nixos.org 下载一些二进制文件 - 非常简单。
有些人使用 nix 来安装他们的 Node 和 Python 和 Ruby 包,但我并没有那样做 —— 我仍然像我以前一样使用 npm install 和 pip install。
一些我没有使用的 nix 功能
有一些 nix 功能/工具我并没有使用,但我要提及一下。我最初认为你必须使用这些功能才能使用 nix,因为我读过的大部分 nix 教程都讨论了它们。但事实证明,你并不一定要使用它们。
- NixOS(一个 Linux 发行版)
- nix-shell
- nix flakes
- home-manager
- devenv.sh
我不去深入讨论它们,因为我并没真正使用过它们,而且网上已经有很多详解。
安装软件包
nix 包在哪里定义的?
我认为 nix 包主仓库中的包是定义在 https://github.com/NixOS/nixpkgs/。
你可以在 https://search.nixos.org/packages 查找包。似乎有两种官方推荐的查找包的方式:
nix-env -qaP NAME,但这非常缓慢,并且我并没有得到期望的结果nix --extra-experimental-features 'nix-command flakes' search nixpkgs NAME,这倒是管用,但显得有点儿冗长。并且,无论何种原因,它输出的所有包都以legacyPackages开头
我找到了一种我更喜欢的从命令行搜索 nix 包的方式:
- 运行
nix-env -qa '*' > nix-packages.txt获取 Nix 仓库中所有包的列表 - 编写一个简洁的
nix-search脚本,仅在packages.txt中进行 grep 操作(cat ~/bin/nix-packages.txt | awk '{print $1}' | rg "$1")
所有的东西都是通过符号链接来安装的
nix 的一个主要设计是,没有一个单一的 bin 文件夹来存放所有的包,而是使用了符号链接。有许多层的符号链接。比如,以下就是一些符号链接的例子:
- 我机器上的
~/.nix-profile最终是一个到/nix/var/nix/profiles/per-user/bork/profile-111-link/的链接 ~/.nix-profile/bin/fish是到/nix/store/afkwn6k8p8g97jiqgx9nd26503s35mgi-fish-3.5.1/bin/fish的链接
当我安装某样东西的时候,它会创建一个新的 profile-112-link 目录并建立新的链接,并且更新我的 ~/.nix-profile 使其指向那个目录。
我认为,这意味着如果我安装了新版本的 fish 但我并不满意,我可以很容易地退回先前的版本,只需运行 nix-env --rollback,这样就可以让我回到之前的配置文件目录了。
卸载包并不意味着删除它们
如果我像这样卸载 nix 包,实际上并不会释放任何硬盘空间,而仅仅是移除了符号链接:
$ nix-env --uninstall oil
我尚不清楚如何彻底删除包 - 我试着运行了如下的垃圾收集命令,这似乎删除了一些项目:
$ nix-collect-garbage
...
85 store paths deleted, 74.90 MiB freed
然而,我系统上仍然存在 oil 包,在 /nix/store/8pjnk6jr54z77jiq5g2dbx8887dnxbda-oil-0.14.0。
nix-collect-garbage 有一个更具攻击性的版本,它也会删除你配置文件的旧版本(这样你就不能回滚了)。
$ nix-collect-garbage -d --delete-old
尽管如此,上述命令仍无法删除 /nix/store/8pjnk6jr54z77jiq5g2dbx8887dnxbda-oil-0.14.0,我不明白原因。
升级过程
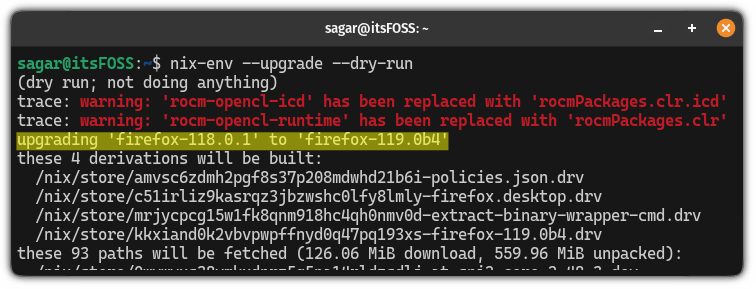
你可以通过以下的方式升级 nix 包:
nix-channel --update
nix-env --upgrade
(这与 apt-get update && apt-get upgrade 类似。)
我还没真正尝试升级任何东西。我推测,如果升级过程中出现任何问题,我可以通过以下方式轻松地回滚(因为在 nix 中,所有事物都是不可变的!):
nix-env --rollback
有人向我推荐了 Ian Henry 的 这篇文章,该文章讨论了 nix-env --upgrade 的一些令人困惑的问题 - 也许它并不总是如我们所料?因此,我会对升级保持警惕。
下一个目标:创建名为 paperjam 的自定义包
经过几个月使用现有的 nix 包后,我开始考虑制作自定义包,对象是一个名为 paperjam 的程序,它还没有被打包封装。
实际上,因为我系统上的 libiconv 版本不正确,我甚至在没有 nix 的情况下也遇到了编译 paperjam 的困难。我认为,尽管我还不懂如何制作 nix 包,但使用 nix 来编译它可能会更为简单。结果证明我的想法是对的!
然而,理清如何实现这个目标的过程相当复杂,因此我在这里写下了一些我实现它的方式和步骤。
构建示例包的步骤
在我着手制作 paperjam 自定义包之前,我想先试手构建一个已存在的示例包,以便确保我已经理解了构建包的整个流程。这个任务曾令我头痛不已,但在我在 Discord 提问之后,有人向我阐述了如何从 https://github.com/NixOS/nixpkgs/ 获取一个可执行的包并进行构建。以下是操作步骤:
步骤 1: 从 GitHub 的 nixpkgs 下载任意一个包,以 dash 包为例:
wget https://raw.githubusercontent.com/NixOS/nixpkgs/47993510dcb7713a29591517cb6ce682cc40f0ca/pkgs/shells/dash/default.nix -O dash.nix
步骤 2: 用 with import <nixpkgs> {}; 替换开头的声明({ lib , stdenv , buildPackages , autoreconfHook , pkg-config , fetchurl , fetchpatch , libedit , runCommand , dash }:)。我不清楚为何需要这样做,但事实证明这么做是有效的。
步骤 3: 运行 nix-build dash.nix
这将开始编译该包。
步骤 4: 运行 nix-env -i -f dash.nix
这会将该包安装到我的 ~/.nix-profile 目录下。
就这么简单!一旦我完成了这些步骤,我便感觉自己能够逐步修改 dash 包,进一步创建属于我自己的包了。
制作自定义包的过程
因为 paperjam 依赖于 libpaper,而 libpaper 还没有打包,所以我首先需要构建 libpaper 包。
以下是 libpaper.nix,我基本上是从 nixpkgs 仓库中其他包的源码中复制粘贴得到的。我猜测这里的原理是,nix 对如何编译 C 包有一些默认规则,例如 “运行 make install”,所以 make install 实际上是默认执行的,并且我并不需要明确地去配置它。
with import <nixpkgs> {};
stdenv.mkDerivation rec {
pname = "libpaper";
version = "0.1";
src = fetchFromGitHub {
owner = "naota";
repo = "libpaper";
rev = "51ca11ec543f2828672d15e4e77b92619b497ccd";
hash = "sha256-S1pzVQ/ceNsx0vGmzdDWw2TjPVLiRgzR4edFblWsekY=";
};
buildInputs = [ ];
meta = with lib; {
homepage = "https://github.com/naota/libpaper";
description = "libpaper";
platforms = platforms.unix;
license = with licenses; [ bsd3 gpl2 ];
};
}
这个脚本基本上告诉 nix 如何从 GitHub 下载源代码。
我通过运行 nix-build libpaper.nix 来构建它。
接下来,我需要编译 paperjam。我制作的 nix 包 的链接在这里。除了告诉它从哪里下载源码外,我需要做的主要事情有:
- 添加一些额外的构建依赖项(像
asciidoc) - 在安装过程中设置一些环境变量(
installFlags = [ "PREFIX=$(out)" ];),这样它就会被安装在正确的目录,而不是/usr/local/bin。
我首先从散列值为空开始,然后运行 nix-build 以获取一个关于散列值不匹配的错误信息。然后我从错误信息中复制出正确的散列值。
我只是在 nixpkgs 仓库中运行 rg PREFIX 来找出如何设置 installFlags 的 —— 我认为设置 PREFIX 应该是很常见的操作,可能之前已经有人做过了,事实证明我的想法是对的。所以我只是从其他包中复制粘贴了那部分代码。
然后我执行了:
nix-build paperjam.nix
nix-env -i -f paperjam.nix
然后所有的东西都开始工作了,我成功地安装了 paperjam!耶!
下一个目标:安装一个五年前的 Hugo 版本
当前,我使用的是 2018 年的 Hugo 0.40 版本来构建我的博客。由于我并不需要任何的新功能,因此我并没有感到有升级的必要。对于在 Linux 上操作,这个过程非常简单:Hugo 的发行版本是静态二进制文件,这意味着我可以直接从 发布页面 下载五年前的二进制文件并运行。真的很方便!
但在我的 Mac 电脑上,我遇到了一些复杂的情况。过去五年中,Mac 的硬件已经发生了一些变化,因此我下载的 Mac 版 Hugo 二进制文件并不能运行。同时,我尝试使用 go build 从源代码编译,但由于在过去的五年内 Go 的构建规则也有所改变,因此没有成功。
我曾试图通过在 Linux docker 容器中运行 Hugo 来解决这个问题,但我并不太喜欢这个方法:尽管可以工作,但它运行得有些慢,而且我个人感觉这样做有些多余。毕竟,编译一个 Go 程序不应该那么麻烦!
幸好,Nix 来救援!接下来,我将介绍我是如何使用 nix 来安装旧版本的 Hugo。
使用 nix 安装 Hugo 0.40 版本
我的目标是安装 Hugo 0.40,并将其添加到我的 PATH 中,以 hugo-0.40 作为命名。以下是我实现此目标的步骤。尽管我采取了一种相对特殊的方式进行操作,但是效果不错(可以参考 搜索和安装旧版本的 Nix 包 来找到可能更常规的方法)。
步骤 1: 在 nixpkgs 仓库中搜索找到 Hugo 0.40。
我在此链接中找到了相应的 .nix 文件 https://github.com/NixOS/nixpkgs/blob/17b2ef2/pkgs/applications/misc/hugo/default.nix。
步骤 2: 下载该文件并进行构建。
我下载了带有 .nix 扩展名的文件(以及同一目录下的另一个名为 deps.nix 的文件),将文件的首行替换为 with import <nixpkgs> {};,然后使用 nix-build hugo.nix 进行构建。
虽然这个过程几乎无需进行修改就能成功运行,但我仍然做了两处小调整:
- 把
with stdenv.lib替换为with lib。 - 为避免与我已安装的其他版本的
hugo冲突,我把包名改为了hugo040。
步骤 3: 将 hugo 重命名为 hugo-0.40。
我编写了一个简短的后安装脚本,用以重命名 Hugo 二进制文件。
postInstall = ''
mv $out/bin/hugo $out/bin/hugo-0.40
'';
我是通过在 nixpkgs 仓库中运行 rg 'mv ' 命令,然后复制和修改一条看似相关的代码片段来找到如何实施此步骤。
步骤 4: 安装。
我通过运行 nix-env -i -f hugo.nix 命令,将 Hugo 安装到了 ~/.nix-profile/bin 目录中。
所有的步骤都顺利运行了!我把最终的 .nix 文件存放到了我自己的 nixpkgs 仓库 中,这样我以后如果需要,就能再次使用它了。
可重复的构建过程并非神秘,其实它们极其复杂
我觉得值得一提的是,这个 hugo.nix 文件并不是什么魔法——我之所以能在今天轻易地编译 Hugo 0.40,完全归功于许多人长期以来的付出,他们让 Hugo 的这个版本得以以可重复的方式打包。
总结
安装 paperjam 和这个五年前的 Hugo 版本过程惊人地顺利,实际上比没有 nix 来编译它们更简单。这是因为 nix 极大地方便了我使用正确的 libiconv 版本来编译 paperjam 包,而且五年前就已经有人辛苦地列出了 Hugo 的确切依赖关系。
我并无计划详细深入地使用 nix(真的,我很可能对它感到困扰,然后最后选择回归使用 homebrew!),但我们将拭目以待!我发现,简单入手然后按需逐步掌握更多功能,远比一开始就全面接触一堆复杂功能更容易掌握。
我可能不会在 Linux 上使用 nix —— 我一直都对 Debian 基础发行版的 apt 和 Arch 基础发行版的 pacman 感到满意,它们策略明晰且少有混淆。而在 Mac 上,使用 nix 似乎会有所得。不过,谁知道呢!也许三个月后,我可能会对 nix 感到不满然后再次选择回归使用 homebrew。
(题图:MJ/f68aaf37-4a34-4643-b3a1-8728d49cf887)
via: https://jvns.ca/blog/2023/02/28/some-notes-on-using-nix/
作者:Julia Evans 选题:lkxed 译者:ChatGPT 校对:wxy


 就是一个行向量。
就是一个行向量。
 。人工智能和机器学习的第一个挑战来了:如果医疗记录有十亿条怎么办?即使动用成千上万的专业人员从中手动提取数据,这项任务也是无法完成的。因此,人工智能和机器学习利用程序来提取数据。
。人工智能和机器学习的第一个挑战来了:如果医疗记录有十亿条怎么办?即使动用成千上万的专业人员从中手动提取数据,这项任务也是无法完成的。因此,人工智能和机器学习利用程序来提取数据。
 、
、  、
、  等。如果你完全没有 Python 编程经验,请自行了解 Python 变量的相关知识。
等。如果你完全没有 Python 编程经验,请自行了解 Python 变量的相关知识。