今天早上,我为未来潜在容器杂志画了一幅 OverlayFS 的漫画,我对这个主题感到兴奋,想写一篇关于它的博客来提供更多详细信息。
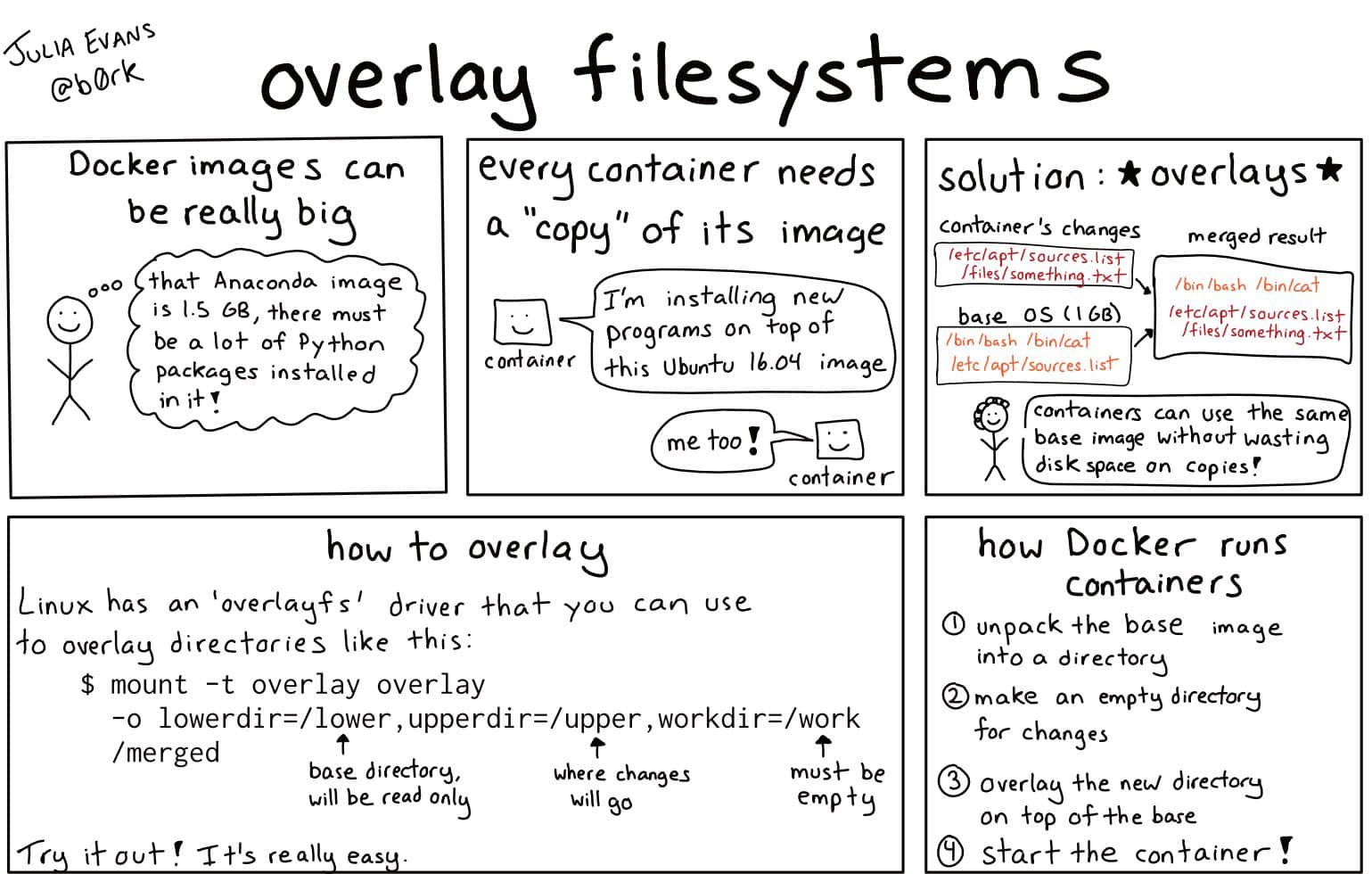
容器镜像很大
容器镜像可能会很大(尽管有些很小,例如 alpine linux 才 2.5MB)。Ubuntu 16.04 约为 27 MB,Anaconda Python 发行版为 800MB 至 1.5GB。
你以镜像启动的每个容器都是原始空白状态,仿佛它只是为使用容器而复制的一份镜像拷贝一样。但是对于大的容器镜像,像 800MB 的 Anaconda 镜像,复制一份拷贝既浪费磁盘空间也很慢。因此 Docker 不会复制,而是采用叠加。
叠加如何工作
OverlayFS,也被称为 联合文件系统或 联合挂载,它可让你使用 2 个目录挂载文件系统:“下层”目录和“上层”目录。
基本上:
- 文件系统的下层目录是只读的
- 文件系统的上层目录可以读写
当进程“读取”文件时,OverlayFS 文件系统驱动将在上层目录中查找并从该目录中读取文件(如果存在)。否则,它将在下层目录中查找。
当进程“写入”文件时,OverlayFS 会将其写入上层目录。
让我们使用 mount 制造一个叠加层!
这有点抽象,所以让我们制作一个 OverlayFS 并尝试一下!这将只包含一些文件:我将创建上、下层目录,以及用来挂载合并的文件系统的 merged 目录:
$ mkdir upper lower merged work
$ echo "I'm from lower!" > lower/in_lower.txt
$ echo "I'm from upper!" > upper/in_upper.txt
$ # `in_both` is in both directories
$ echo "I'm from lower!" > lower/in_both.txt
$ echo "I'm from upper!" > upper/in_both.txt
合并上层目录和下层目录非常容易:我们可以通过 mount 来完成!
$ sudo mount -t overlay overlay
-o lowerdir=/home/bork/test/lower,upperdir=/home/bork/test/upper,workdir=/home/bork/test/work
/home/bork/test/merged
在执行此操作时,我不断收到一条非常烦人的错误消息,内容为:mount: /home/bork/test/merged: special device overlay does not exist.。这条消息是错误的,实际上只是意味着我指定的一个目录缺失(我写成了 ~/test/merged,但它没有被展开)。
让我们尝试从 OverlayFS 中读取其中一个文件!文件 in_both.txt 同时存在于 lower/ 和 upper/ 中,因此应从 upper/ 目录中读取该文件。
$ cat merged/in_both.txt
"I'm from upper!
可以成功!
目录的内容就是我们所期望的:
find lower/ upper/ merged/
lower/
lower/in_lower.txt
lower/in_both.txt
upper/
upper/in_upper.txt
upper/in_both.txt
merged/
merged/in_lower.txt
merged/in_both.txt
merged/in_upper.txt
创建新文件时会发生什么?
$ echo 'new file' > merged/new_file
$ ls -l */new_file
-rw-r--r-- 1 bork bork 9 Nov 18 14:24 merged/new_file
-rw-r--r-- 1 bork bork 9 Nov 18 14:24 upper/new_file
这是有作用的,新文件会在 upper 目录创建。
删除文件时会发生什么?
读写似乎很简单。但是删除会发生什么?开始试试!
$ rm merged/in_both.txt
发生了什么?让我们用 ls 看下:
ls -l upper/in_both.txt lower/lower1.txt merged/lower1.txt
ls: cannot access 'merged/in_both.txt': No such file or directory
-rw-r--r-- 1 bork bork 6 Nov 18 14:09 lower/in_both.txt
c--------- 1 root root 0, 0 Nov 18 14:19 upper/in_both.txt
所以:
in_both.txt 仍在 lower 目录中,并且保持不变- 它不在
merged 目录中。到目前为止,这就是我们所期望的。 - 但是在
upper 中发生的事情有点奇怪:有一个名为 upper/in_both.txt 的文件,但是它是字符设备?我想这就是 overlayfs 驱动表示删除的文件的方式。
如果我们尝试复制这个奇怪的字符设备文件,会发生什么?
$ sudo cp upper/in_both.txt upper/in_lower.txt
cp: cannot open 'upper/in_both.txt' for reading: No such device or address
好吧,这似乎很合理,复制这个奇怪的删除信号文件并没有任何意义。
你可以挂载多个“下层”目录
Docker 镜像通常由 25 个“层”组成。OverlayFS 支持具有多个下层目录,因此你可以运行:
mount -t overlay overlay
-o lowerdir:/dir1:/dir2:/dir3:...:/dir25,upperdir=...
因此,我假设这是有多个 Docker 层的容器的工作方式,它只是将每个层解压缩到一个单独的目录中,然后要求 OverlayFS 将它们全部合并在一起,并使用一个空的上层目录,容器将对其进行更改。
Docker 也可以使用 btrfs 快照
现在,我使用的是 ext4,而 Docker 使用 OverlayFS 快照来运行容器。但是我曾经用过 btrfs,接着 Docker 将改为使用 btrfs 的写时复制快照。(这是 Docker 何时使用哪种存储驱动的列表)
以这种方式使用 btrfs 快照会产生一些有趣的结果:去年某个时候,我在笔记本上运行了数百个临时的 Docker 容器,这导致我用尽了 btrfs 元数据空间(像这个人一样)。这真的很令人困惑,因为我以前从未听说过 btrfs 元数据,而且弄清楚如何清理文件系统以便再次运行 Docker 容器非常棘手。(这个 docker github 上的提案描述了 Docker 和 btrfs 的类似问题)
以简单的方式尝试容器功能很有趣!
我认为容器通常看起来像是在做“复杂的”事情,我认为将它们分解成这样很有趣。你可以运行一条 mount 咒语,而实际上并没有做任何与容器相关的其他事情,看看叠加层是如何工作的!
via: https://jvns.ca/blog/2019/11/18/how-containers-work–overlayfs/
作者:Julia Evans 选题:lujun9972 译者:geekpi 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出









{kind=link}
{kind=link}