简介:这篇详细的指南将向你展示如何在 Linux 和 Windows 之间共享 Steam 的游戏文件以节省下载的总用时和下载的数据量。我们将展示给你它是怎样为我们节约了 83% 的数据下载量。
假如你决心成为一名 Linux 平台上的玩家,并且在 Steam 上拥有同时支持 Linux 和 Windows 平台的游戏,或者基于同样的原因,拥有双重启动的系统,则你可以考虑看看这篇文章。
我们中的许多玩家都拥有双重启动的 Linux 和 Windows。有些人只拥有 Linux 系统,但同时拥有当前还没有被 Linux 平台上的 Steam 支持的游戏。所以我们同时保留这两个系统以便我们可以在忽略平台的前提下玩我们喜爱的游戏。
幸运的是 Linux 游戏社区应运而生,越来越多在 Windows 平台上受欢迎的 Steam 游戏也发布在 Linux 平台上的 Steam 中。
我们中的许多人喜欢备份我们的 Steam 游戏,使得我们不再苦苦等待游戏下载完成。这些游戏很大程度上是 Windows 平台下的 Steam 游戏。
现在,很多游戏也已经登陆了 Linux 平台上的 Steam,例如 奇异人生 、 古墓丽影 2013 、 中土世界:魔多阴影 、 幽浮:未知敌人 、幽浮 2、 与日赛跑 、 公路救赎 、 燥热 等等,并且这份名单一直在增长。甚至还有 杀出重围:人类分裂 和 疯狂的麦克斯 !!!在一些游戏的 Windows 版发布之后,现在我们不必再等候多年,而只需等待几月左右,便可以听到类似的消息了,这可是大新闻啊!
下面的实验性方法将向你展示如何使用你现存的任何平台上游戏文件来在 Steam 上恢复游戏的大部分数据。对于某些游戏,它们在两个平台下有很多相似的文件,利用下面例子中的方法,将减少你在享受这些游戏之前的漫长的等待时间。
在下面的方法中,我们将一步一步地尝试利用 Steam 自身的备份与恢复功能或者以手工的方式来达到我们的目的。当涉及到这些方法的时候,我们也将向你展示这两个平台上游戏文件的相同和不同之处,以便你也可以探索并做出你自己的调整。
下面的方法中,我们将使用 Ubuntu 14.04 LTS 和 Windows 10 来执行备份与恢复 Steam 的测试。
1、Steam 自身的备份与恢复
当我们尝试使用 Windows 平台上 Steam 中《 燥热 》这个游戏的备份(这些加密文件是 .csd 格式)时,Linux 平台上的 Steam 不能识别这些文件,并重新开始下载整个游戏了!甚至在做了验证性检验后,仍然有很大一部分文件不能被 Steam 识别出来。我们在 Windows 上也做了类似的操作,但结果是一样的!
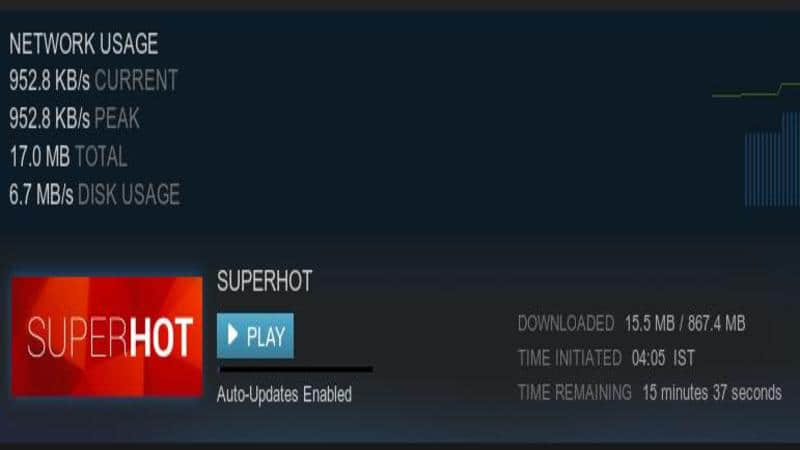
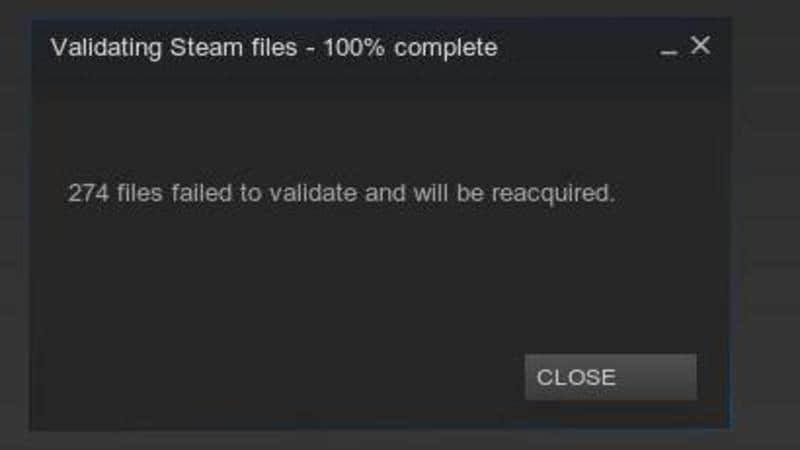
现在到了我们用某些手工的方法来共享 Windows 和 Linux 上的 Steam 游戏的时刻了!
2、手工方法
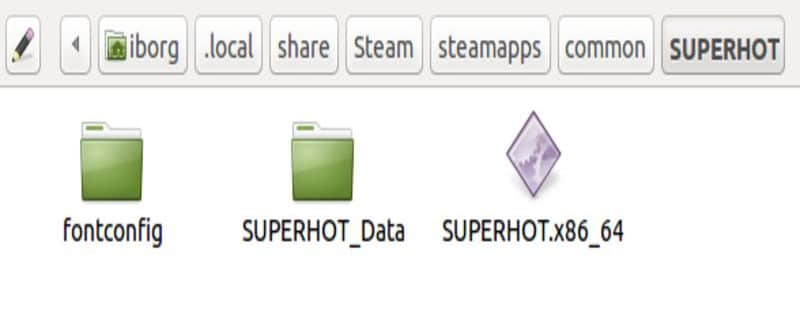
首先,让我们先看看 Linux 下这些游戏文件所处的位置(用户目录在 /home 中):
这是 Linux 平台上 Steam 游戏的默认安装位置。 .local 和 .steam 目录默认情况下是不可见的,你必须将它们显现出来。我们将推荐使用一个自定义的 Steam 安装位置以便更容易地处理这些文件。这里 SUPERHOT.x86_64 是 Linux 下原生的可执行文件,与 Windows 中的 .exe 文件类似。
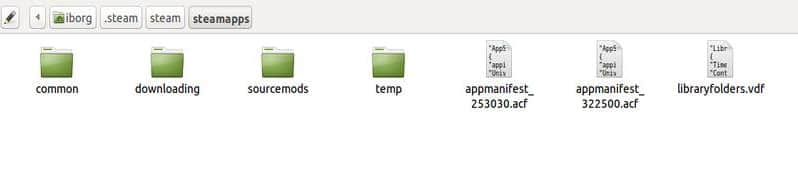
下图展示的位置包含我们需要的大部分文件(在 Windows 和 Linux 平台上相同):
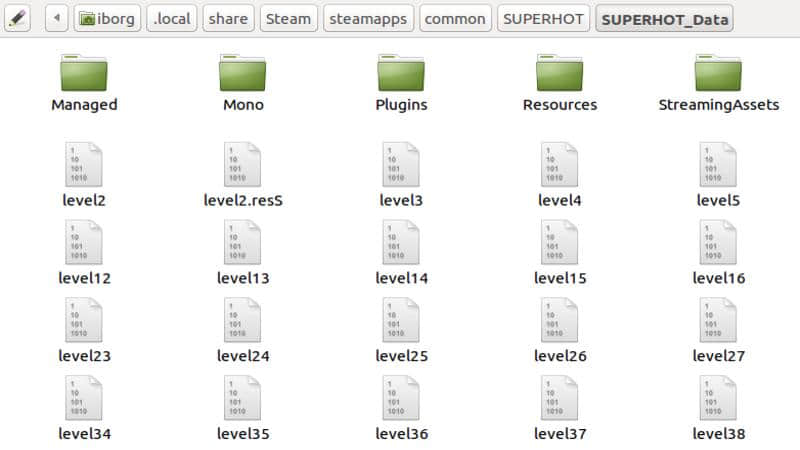
下面我们来看看这些 .acf 格式的文件。appmanifest_322500.acf 便是那个我们需要的文件。编辑并调整这个文件有助于 Steam 识别在 common 这个目录下现存的非加密的原始文件备份:
为了确认这个文件是一样的,用编辑器打开这个文件并检查它。我们越多地了解这个文件越好。这个链接是来自 Steam 论坛上的一个帖子,它展示了这个文件的主要意义。它类似于下面这样:
“AppState”
{
“appid” “322500”
“Universe” “1”
“name” “SUPERHOT”
“StateFlags” “4”
“installdir” “SUPERHOT”
“LastUpdated” “1474466631”
“UpdateResult” “0”
“SizeOnDisk” “4156100762”
“buildid” “1234395”
“LastOwner” “<SteamID>”
“BytesToDownload” “909578688”
“BytesDownloaded” “909578688”
“AutoUpdateBehavior” “0”
“UserConfig”
{
“Language” “english”
}
“MountedDepots”
{
“322503” “1943012315434556837”
}
}
在 Linux 平台上卸载游戏后我们再进行测试。现在让我们看看在 Windows 10 上相同的游戏安装目录里包含哪些内容:
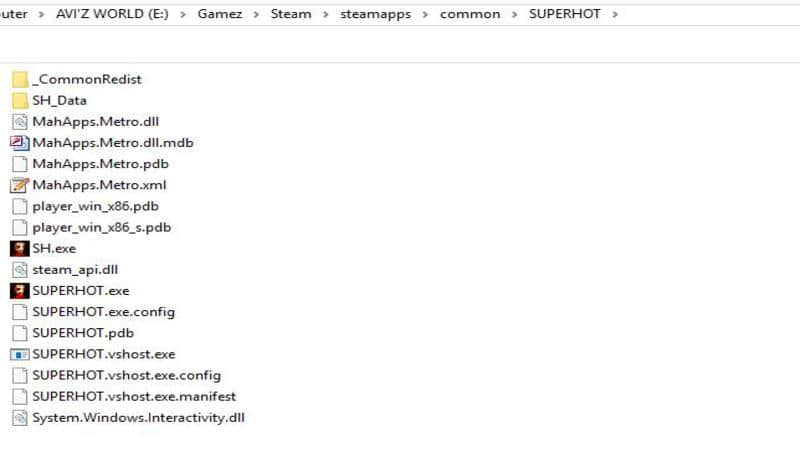
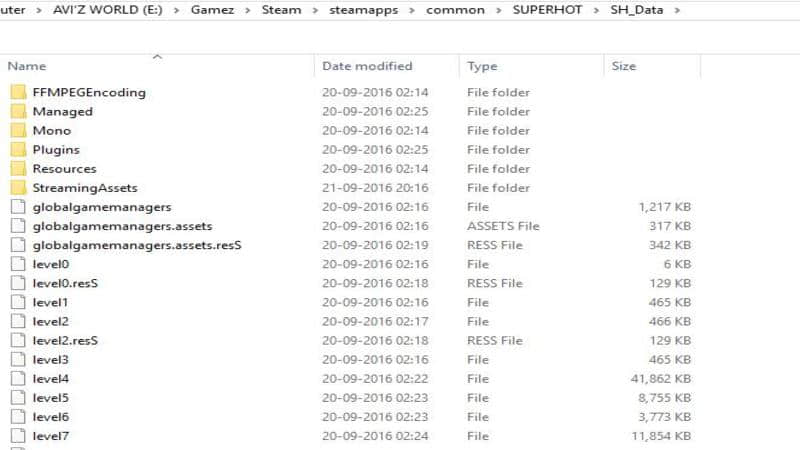
我们复制了 SUPERHOT 目录和 .acf 格式的清单文件(这个文件在 Windows 的 Steam 上格式是一样的)。在复制 .acf 文件和游戏目录到 Linux 中 Steam 它们对应的位置时,我们需要确保 Steam 没有在后台运行。
在转移完成之后,我们运行 Steam 并看到了这个:
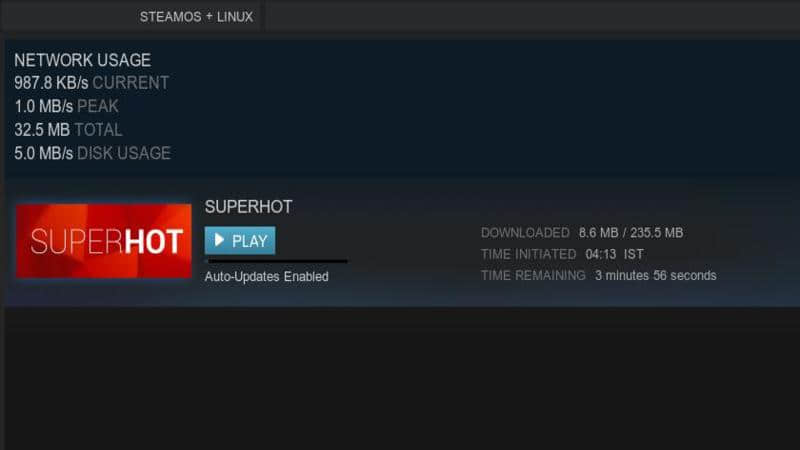
所以下图显示只需要有 235.5 MB 的文件需要下载,而不是整个 867.4 MB,这意味着超过 70% 的文件已经被 Steam 识别了:) !相对来说,节省了一笔大量的时间开销。当然不同的游戏可能有所不同,但对于那些网速居于平均水平或以下的玩家来说,这种方法绝对值得一试,尤其是考虑到当前那些 40-50 GB 大小的重量级游戏。
我们还进行了其他几种尝试:
- 我们尝试使用 Linux 下原有的清单文件(
.acf)和来自 Windows 的手工备份文件,但结果是 Steam 重新开始下载游戏。 - 我们看到当我们将
SUPERHOT_Data 这个目录中的 SH_Data 更换为 Windows 中的对应目录时,同上面的一样,也重新开始下载整个游戏。
理解清单目录的一个尝试
清单目录绝对可以被进一步地被编辑和修改以此来改善上面的结果,使得 Steam 检测出尽可能多的文件。
在 Github 上有一个项目,包含一个可以生成这些清单文件的 python 脚本。任何 Steam 游戏的 AppID 可以从SteamDB 上获取到。知晓了游戏的 ID 号后,你便可以用你喜爱的编辑器以下面的格式创建你自己的清单文件 appmanifest_<AppID>.acf。在上面手工方法中,我们可以看到 SUPERHOT 这个游戏的 AppID 是 322500,所以对应的清单文件名应该是 appmanifest_322500.acf。
下面以我们知晓的信息来尝试对该文件进行一些解释:
“AppState” // 应用(游戏)的状态
“appid” “322500” // 游戏的 AppID
“Universe” “1”
“name” “SUPERHOT” // 游戏的名称
“StateFlags” “4”
“installdir” “SUPERHOT” // 安装目录的名称
“LastUpdated” “1474466631”
“UpdateResult” “0”
“SizeOnDisk” “4156100762”
“buildid” “1234395”
“LastOwner” “<SteamID>” // 唯一的帐号拥有者的 <SteamID>
“BytesToDownload” “909578688” // 将这个数字除以 1073741824(1024 x 1024 x 1024) 便可以计算出还需要下载的数据大小,以 GB 记。
“BytesDownloaded” “909578688” // 已下载数据的大小, 以 Bytes 记。
“AutoUpdateBehavior” “0” // 当这个设为 0 时,该游戏将自动升级。
“UserConfig” // 用户的配置信息
{
“Language” “english”
}
“MountedDepots” // 这个部分大多与游戏的 DLC 相关。
{
“322503” “1943012315434556837”
}
}
通过计算下载的数据的大小,你可以将它与 Steam 展现的信息进行比较并进行更多的调整。
假如你知道更多关于清单文件或者手工方式中另外可以改进的方法,请在评论中分享给大家。我们打算去发现更多的关于这些文件格式的信息,当前在官方的 Valve 开发者社区 或者 Steam 论坛 上我们还没有发现完整的文档。
至少现在为止,这些便是我们知道的在 Linux 和 Windows 之间分享 Steam 游戏的最好方法了。
via: https://itsfoss.com/share-steam-files-linux-windows/
作者:Avimanyu Bandyopadhyay 译者:FSSlc 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出