构建你的数据科学作品集:用数据讲故事

这是如何建立 数据科学作品集 系列文章中的第一篇。如果你喜欢这篇文章并且想知道此系列的下一篇文章何时发表,你可以在页面底部订阅。
数据科学公司们在决定雇佣一个人时越来越看重其作品集。其中一个原因就是 作品集 是分析一个人真实技能的最好方式。好消息是,作品集是完全可以被你掌控的。如果你在其上投入了一些工作,你就能够做出一个令那些公司印象深刻的作品集结果。
建立一个高质量作品集的第一步就是知道展示什么技能。那些公司们主要希望数据科学工作者拥有的技能,或者说他们主要希望作品集所展示的技能是:
- 表达能力
- 合作能力
- 专业技能
- 解释数据的能力
- 有目标和有积极性的
任何一个好的作品集都由多个工程构成,每一个工程都会展示 1-2 个上面所说的点。这是涵盖了“如何完成一个完整的数据科学作品集”系列文章的第一篇。在这篇文章中,我们将会涵括如何完成你的第一项数据科学作品集工程,并且对此进行有效的解释。在最后,你将会得到一个帮助展示你表达能力和解释数据能力的工程。
用数据讲故事
数据科学是表达的基础。你将会在数据中发现一些观点,并且找出一个高效的方式来向他人表达这些,之后向他们展示你所开展的课题。数据科学最关键的手法之一就是能够用数据讲述一个清晰的故事。一个清晰的故事能够使你的观点更加引人注目,并且能使别人理解你的想法。
数据科学中的故事是一个讲述你发现了什么,你怎么发现它的,并且它意味着什么的故事。例如假使发现你公司的收入相对去年减少了百分之二十。这并不能够确定原因,你可能需要和其它人沟通为什么收入会减少,并且在尝试修复它。
用数据讲故事主要包含:
- 理解并确定上下文
- 从多角度发掘
- 使用有趣的表示方法
- 使用多种数据来源
- 一致的表述
用来讲述数据的故事最有效率的工具就是 Jupyter notebook。如果你不熟悉,此处有一个好的教程。Jupyter notebook 允许你交互式的发掘数据,并且将你的结果分享到多个网站,包括 Github。分享你的结果有助于合作研究和其他人拓展你的分析。
在这篇文章中,我们将使用 Jupyter notebook,以及 Pandas 和 matplotlib 这样的 Python 库。
为你的数据科学工程选择一个主题
建立一个工程的第一步就是决定你的主题。你要让你的主题是你兴趣所在,有动力去挖掘。进行数据挖掘时,为了完成而完成和有兴趣完成的区别是很明显的。这个步骤是值得花费时间的,所以确保你找到了你真正感兴趣的东西。
一个寻找主题的好方法就是浏览不同的数据集并且寻找感兴趣的部分。这里有一些作为起点的好的网站:
- Data.gov - 包含了政府数据。
- /r/datasets – 一个有着上百个有趣数据集的 reddit 板块。
- Awesome datasets – 一个数据集的列表,位于 Github 上。
- 17 个找到数据集的地方 – 这篇博文列出了 17 个数据集,每个都包含了示例数据集。
真实世界中的数据科学,你经常无法找到可以浏览的合适的单个数据集。你可能需要聚合多个独立的数据源,或者做数量庞大的数据清理。如果该主题非常吸引你,这是值得这样做的,并且也能更好的展示你的技能。
关于这篇文章的主题,我们将使用纽约市公立学校的数据,我们可以在这里找到它。
选择主题
这对于项目全程来说是十分重要的。因为主题能很好的限制项目的范围,并且它能够使我们知道它可以被完成。比起一个没有足够动力完成的工程来说,添加到一个完成的工程更加容易。
所以,我们将关注高中的学术评估测试,伴随着多种人口统计和它们的其它数据。关于学习评估测试, 或者说 SAT,是美国高中生申请大学前的测试。大学在做判定时将考虑该成绩,所以高分是十分重要的。考试分为三个阶段,每个阶段总分为 800。全部分数为 2400(即使这个前后更改了几次,在数据中总分还是 2400)。高中经常通过平均 SAT分数进行排名,并且 SAT 是评判高中有多好的标准。
因为由关于 SAT 分数对于美国中某些种族群体是不公平的,所以对纽约市这个数据做分析能够对 SAT 的公平性有些许帮助。
我们在这里有 SAT 成绩的数据集,并且在这里有包含了每所高中的信息的数据集。这些将构成我们的工程的基础,但是我们将加入更多的信息来创建有趣的分析。
补充数据
如果你已经有了一个很好的主题,拓展其它可以提升主题或者更深入挖掘数据的的数据集是一个好的选择。在前期十分适合做这些工作,你将会有尽可能多的数据来构建你的工程。数据越少意味着你会太早的放弃了你的工程。
在本项目中,在包含人口统计信息和测试成绩的网站上有一些相关的数据集。
这些是我们将会用到的所有数据集:
- 学校 SAT 成绩 – 纽约市每所高中的 SAT 成绩。
- 学校出勤情况 – 纽约市每所学校的出勤信息。
- 数学成绩 – 纽约市每所学校的数学成绩。
- 班级规模 - 纽约市每所学校课堂人数信息。
- AP 成绩 - 高阶位考试,在美国,通过 AP 测试就能获得大学学分。
- 毕业去向 – 由百分之几的学生毕业了,和其它去向信息。
- 人口统计 – 每个学校的人口统计信息。
- 学校问卷 – 学校的家长、教师,学生的问卷。
- 学校分布地图 – 包含学校的区域布局信息,因此我们能将它们在地图上标出。
(LCTT 译注:高阶位考试(AP)是美国和加拿大的一个由大学委员会创建的计划,该计划为高中学生提供大学水平的课程和考试。 美国学院和大学可以授予在考试中获得高分的学生的就学和课程学分。)
这些数据作品集之间是相互关联的,并且我们能够在开始分析之前进行合并。
获取背景信息
在开始分析数据之前,搜索一些背景信息是有必要的。我们知道这些有用的信息:
- 纽约市被分为五个不同的辖区
- 纽约市的学校被分配到几个学区,每个学区都可能包含数十所学校。
- 数据集中的学校并不全是高中,所以我们需要对数据进行一些清理工作。
- 纽约市的每所学校都有自己单独的编码,被称为‘DBN’,即区域行政编号。
- 为了通过区域进行数据聚合,我们可以使用地图区域信息来绘制逐区差异。
理解数据
为了真正的理解数据信息,你需要花费时间来挖掘和阅读数据。因此,每个数据链接都有数据的描述信息,并伴随着相关列。就像是我们拥有的高中 SAT 成绩信息,也包含图像和其它信息的数据集。
我们可以运行一些代码来读取数据。我们将使用 Jupyter notebook 来挖掘数据。下面的代码将会执行以下操作:
- 循环遍历我们下载的所有数据文件。
- 将文件读取到 Pandas DataFrame。
- 将所有数据框架导入 Python 数据库中。
In [100]:
import pandas
import numpy as np
files = ["ap_2010.csv", "class_size.csv", "demographics.csv", "graduation.csv", "hs_directory.csv", "math_test_results.csv", "sat_results.csv"]
data = {}
for f in files:
d = pandas.read_csv("schools/{0}".format(f))
data[f.replace(".csv", "")] = d
一旦我们将数据读入,我们就可以使用 DataFrames 的 head 方法打印每个 DataFrame 的前五行。
In [103]:
for k,v in data.items():
print("\n" + k + "\n")
print(v.head())
math_test_results
DBN Grade Year Category Number Tested Mean Scale Score Level 1 # \
0 01M015 3 2006 All Students 39 667 2
1 01M015 3 2007 All Students 31 672 2
2 01M015 3 2008 All Students 37 668 0
3 01M015 3 2009 All Students 33 668 0
4 01M015 3 2010 All Students 26 677 6
Level 1 % Level 2 # Level 2 % Level 3 # Level 3 % Level 4 # Level 4 % \
0 5.1% 11 28.2% 20 51.3% 6 15.4%
1 6.5% 3 9.7% 22 71% 4 12.9%
2 0% 6 16.2% 29 78.4% 2 5.4%
3 0% 4 12.1% 28 84.8% 1 3%
4 23.1% 12 46.2% 6 23.1% 2 7.7%
Level 3+4 # Level 3+4 %
0 26 66.7%
1 26 83.9%
2 31 83.8%
3 29 87.9%
4 8 30.8%
ap_2010
DBN SchoolName AP Test Takers \
0 01M448 UNIVERSITY NEIGHBORHOOD H.S. 39
1 01M450 EAST SIDE COMMUNITY HS 19
2 01M515 LOWER EASTSIDE PREP 24
3 01M539 NEW EXPLORATIONS SCI,TECH,MATH 255
4 02M296 High School of Hospitality Management s
Total Exams Taken Number of Exams with scores 3 4 or 5
0 49 10
1 21 s
2 26 24
3 377 191
4 s s
sat_results
DBN SCHOOL NAME \
0 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES
1 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL
2 01M450 EAST SIDE COMMUNITY SCHOOL
3 01M458 FORSYTH SATELLITE ACADEMY
4 01M509 MARTA VALLE HIGH SCHOOL
Num of SAT Test Takers SAT Critical Reading Avg. Score SAT Math Avg. Score \
0 29 355 404
1 91 383 423
2 70 377 402
3 7 414 401
4 44 390 433
SAT Writing Avg. Score
0 363
1 366
2 370
3 359
4 384
class_size
CSD BOROUGH SCHOOL CODE SCHOOL NAME GRADE PROGRAM TYPE \
0 1 M M015 P.S. 015 Roberto Clemente 0K GEN ED
1 1 M M015 P.S. 015 Roberto Clemente 0K CTT
2 1 M M015 P.S. 015 Roberto Clemente 01 GEN ED
3 1 M M015 P.S. 015 Roberto Clemente 01 CTT
4 1 M M015 P.S. 015 Roberto Clemente 02 GEN ED
CORE SUBJECT (MS CORE and 9-12 ONLY) CORE COURSE (MS CORE and 9-12 ONLY) \
0 - -
1 - -
2 - -
3 - -
4 - -
SERVICE CATEGORY(K-9* ONLY) NUMBER OF STUDENTS / SEATS FILLED \
0 - 19.0
1 - 21.0
2 - 17.0
3 - 17.0
4 - 15.0
NUMBER OF SECTIONS AVERAGE CLASS SIZE SIZE OF SMALLEST CLASS \
0 1.0 19.0 19.0
1 1.0 21.0 21.0
2 1.0 17.0 17.0
3 1.0 17.0 17.0
4 1.0 15.0 15.0
SIZE OF LARGEST CLASS DATA SOURCE SCHOOLWIDE PUPIL-TEACHER RATIO
0 19.0 ATS NaN
1 21.0 ATS NaN
2 17.0 ATS NaN
3 17.0 ATS NaN
4 15.0 ATS NaN
demographics
DBN Name schoolyear fl_percent frl_percent \
0 01M015 P.S. 015 ROBERTO CLEMENTE 20052006 89.4 NaN
1 01M015 P.S. 015 ROBERTO CLEMENTE 20062007 89.4 NaN
2 01M015 P.S. 015 ROBERTO CLEMENTE 20072008 89.4 NaN
3 01M015 P.S. 015 ROBERTO CLEMENTE 20082009 89.4 NaN
4 01M015 P.S. 015 ROBERTO CLEMENTE 20092010 96.5
total_enrollment prek k grade1 grade2 ... black_num black_per \
0 281 15 36 40 33 ... 74 26.3
1 243 15 29 39 38 ... 68 28.0
2 261 18 43 39 36 ... 77 29.5
3 252 17 37 44 32 ... 75 29.8
4 208 16 40 28 32 ... 67 32.2
hispanic_num hispanic_per white_num white_per male_num male_per female_num \
0 189 67.3 5 1.8 158.0 56.2 123.0
1 153 63.0 4 1.6 140.0 57.6 103.0
2 157 60.2 7 2.7 143.0 54.8 118.0
3 149 59.1 7 2.8 149.0 59.1 103.0
4 118 56.7 6 2.9 124.0 59.6 84.0
female_per
0 43.8
1 42.4
2 45.2
3 40.9
4 40.4
[5 rows x 38 columns]
graduation
Demographic DBN School Name Cohort \
0 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2003
1 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2004
2 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2005
3 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2006
4 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2006 Aug
Total Cohort Total Grads - n Total Grads - % of cohort Total Regents - n \
0 5 s s s
1 55 37 67.3% 17
2 64 43 67.2% 27
3 78 43 55.1% 36
4 78 44 56.4% 37
Total Regents - % of cohort Total Regents - % of grads \
0 s s
1 30.9% 45.9%
2 42.2% 62.8%
3 46.2% 83.7%
4 47.4% 84.1%
... Regents w/o Advanced - n \
0 ... s
1 ... 17
2 ... 27
3 ... 36
4 ... 37
Regents w/o Advanced - % of cohort Regents w/o Advanced - % of grads \
0 s s
1 30.9% 45.9%
2 42.2% 62.8%
3 46.2% 83.7%
4 47.4% 84.1%
Local - n Local - % of cohort Local - % of grads Still Enrolled - n \
0 s s s s
1 20 36.4% 54.1% 15
2 16 25% 37.200000000000003% 9
3 7 9% 16.3% 16
4 7 9% 15.9% 15
Still Enrolled - % of cohort Dropped Out - n Dropped Out - % of cohort
0 s s s
1 27.3% 3 5.5%
2 14.1% 9 14.1%
3 20.5% 11 14.1%
4 19.2% 11 14.1%
[5 rows x 23 columns]
hs_directory
dbn school_name boro \
0 17K548 Brooklyn School for Music & Theatre Brooklyn
1 09X543 High School for Violin and Dance Bronx
2 09X327 Comprehensive Model School Project M.S. 327 Bronx
3 02M280 Manhattan Early College School for Advertising Manhattan
4 28Q680 Queens Gateway to Health Sciences Secondary Sc... Queens
building_code phone_number fax_number grade_span_min grade_span_max \
0 K440 718-230-6250 718-230-6262 9 12
1 X400 718-842-0687 718-589-9849 9 12
2 X240 718-294-8111 718-294-8109 6 12
3 M520 718-935-3477 NaN 9 10
4 Q695 718-969-3155 718-969-3552 6 12
expgrade_span_min expgrade_span_max \
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 9 14.0
4 NaN NaN
... \
0 ...
1 ...
2 ...
3 ...
4 ...
priority02 \
0 Then to New York City residents
1 Then to New York City residents who attend an ...
2 Then to Bronx students or residents who attend...
3 Then to New York City residents who attend an ...
4 Then to Districts 28 and 29 students or residents
priority03 \
0 NaN
1 Then to Bronx students or residents
2 Then to New York City residents who attend an ...
3 Then to Manhattan students or residents
4 Then to Queens students or residents
priority04 priority05 \
0 NaN NaN
1 Then to New York City residents NaN
2 Then to Bronx students or residents Then to New York City residents
3 Then to New York City residents NaN
4 Then to New York City residents NaN
priority06 priority07 priority08 priority09 priority10 \
0 NaN NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN
2 NaN NaN NaN NaN NaN
3 NaN NaN NaN NaN NaN
4 NaN NaN NaN NaN NaN
Location 1
0 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67...
1 1110 Boston Road\nBronx, NY 10456\n(40.8276026...
2 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241...
3 411 Pearl Street\nNew York, NY 10038\n(40.7106...
4 160-20 Goethals Avenue\nJamaica, NY 11432\n(40...
[5 rows x 58 columns]
我们可以开始在数据作品集中观察有用的部分:
- 大部分数据集包含 DBN 列。
- 一些条目看起来在地图上标出会很有趣,特别是
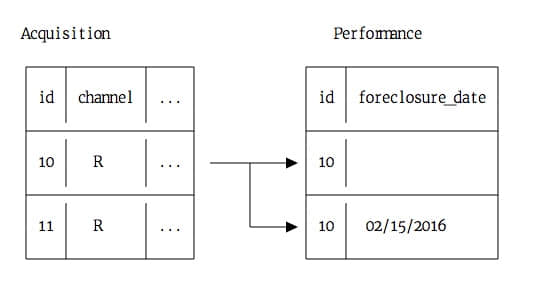
Location 1,这列在一个很长的字符串里面包含了位置信息。 - 有些数据集会出现每所学校对应多行数据(DBN 数据重复),这意味着我们要进行预处理。
统一数据
为了使工作更简单,我们将需要将全部零散的数据集统一为一个。这将使我们能够快速跨数据集对比数据列。因此,我们需要找到相同的列将它们统一起来。请查看上面的输出数据, DBN 出现在多个数据集中,它看起来可以作为共同列。
如果我们用 google 搜索 DBN New York City Schools,我们在此得到了结果。它解释了 DBN 是每个学校独特的编码。我们将挖掘数据集,特别是政府数据集。这通常需要做一些工作来找出每列的含义,或者每个数据集的意图。
现在主要的问题是这两个数据集 class_size 和 hs_directory,没有 DBN 列。在 hs_directory 数据中是 dbn,那么我们只需重命名即可,或者将它复制到新的名为 DBN 的列中。在 class_size 数据中,我们将需要尝试不同的方法。
DBN 列:
In [5]:
data["demographics"]["DBN"].head()
Out[5]:
0 01M015
1 01M015
2 01M015
3 01M015
4 01M015
Name: DBN, dtype: object
如果我们查看 class_size数据,我们将看到前五行如下:
In [4]:
data["class_size"].head()
Out[4]:
| CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | CORE COURSE (MS CORE and 9-12 ONLY) | SERVICE CATEGORY(K-9* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | - | - | 19.0 | 1.0 | 19.0 | 19.0 | 19.0 | ATS | NaN |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | - | - | 21.0 | 1.0 | 21.0 | 21.0 | 21.0 | ATS | NaN |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | - | - | 17.0 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | - | - | 17.0 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN ED | - | - | - | 15.0 | 1.0 | 15.0 | 15.0 | 15.0 | ATS | NaN |
正如上面所见,DBN 实际上是 CSD、 BOROUGH 和 SCHOOL CODE 的组合。对那些不熟悉纽约市的人来说,纽约由五个行政区组成。每个行政区是一个组织单位,并且有着相当于美国大城市一样的面积。DBN 全称为行政区域编号。看起来就像 CSD 是区域,BOROUGH 是行政区,并且当与 SCHOOL CODE 合并时就组成了 DBN。这里并没有寻找像这个数据这样的内在规律的系统方法,这需要一些探索和努力来发现。
现在我们已经知道了 DBN 的组成,那么我们就可以将它加入到 class_size 和 hs_directory 数据集中了:
In [ ]:
data["class_size"]["DBN"] = data["class_size"].apply(lambda x: "{0:02d}{1}".format(x["CSD"], x["SCHOOL CODE"]), axis=1)
data["hs_directory"]["DBN"] = data["hs_directory"]["dbn"]
加入问卷
最可能值得一看的数据集之一就是学生、家长和老师关于学校质量的问卷了。这些问卷包含了每所学校的安全程度、教学水平等。在我们合并数据集之前,让我们添加问卷数据。在真实世界的数据科学工程中,你经常会在分析过程中碰到有趣的数据,并且希望合并它。使用像 Jupyter notebook 一样灵活的工具将允许你快速添加一些新的代码,并且重新开始你的分析。
因此,我们将添加问卷数据到我们的 data 文件夹,并且合并所有之前的数据。问卷数据分为两个文件,一个包含所有的学校,一个包含 75 学区。我们将需要写一些代码来合并它们。之后的代码我们将:
- 使用 windows-1252 编码读取所有学校的问卷。
- 使用 windows-1252 编码读取所有 75 号学区的问卷。
- 添加指示每个数据集所在学区的标志。
- 使用 DataFrame 的 concat 方法将数据集合并为一个。
In [66]:
survey1 = pandas.read_csv("schools/survey_all.txt", delimiter="\t", encoding='windows-1252')
survey2 = pandas.read_csv("schools/survey_d75.txt", delimiter="\t", encoding='windows-1252')
survey1["d75"] = False
survey2["d75"] = True
survey = pandas.concat([survey1, survey2], axis=0)
一旦我们将问卷合并,这里将会有一些混乱。我们希望我们合并的数据集列数最少,那么我们将可以轻易的进行列之间的对比并找出其间的关联。不幸的是,问卷数据有很多列并不是很有用:
In [16]:
survey.head()
Out[16]:
| N\_p | N\_s | N\_t | acap11 | acas11 | acat11 | acatot11 | bn | comp11 | coms11 | ... | tq8c1 | tq8c2 | tq8c3 | tq8c4 | t\_q9 | tq91 | tq92 | tq93 | tq94 | tq95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 90.0 | NaN | 22.0 | 7.8 | NaN | 7.9 | 7.9 | M015 | 7.6 | NaN | ... | 29.0 | 67.0 | 5.0 | 0.0 | NaN | 5.0 | 14.0 | 52.0 | 24.0 | 5.0 |
| 1 | 161.0 | NaN | 34.0 | 7.8 | NaN | 9.1 | 8.4 | M019 | 7.6 | NaN | ... | 74.0 | 21.0 | 6.0 | 0.0 | NaN | 3.0 | 6.0 | 3.0 | 78.0 | 9.0 |
| 2 | 367.0 | NaN | 42.0 | 8.6 | NaN | 7.5 | 8.0 | M020 | 8.3 | NaN | ... | 33.0 | 35.0 | 20.0 | 13.0 | NaN | 3.0 | 5.0 | 16.0 | 70.0 | 5.0 |
| 3 | 151.0 | 145.0 | 29.0 | 8.5 | 7.4 | 7.8 | 7.9 | M034 | 8.2 | 5.9 | ... | 21.0 | 45.0 | 28.0 | 7.0 | NaN | 0.0 | 18.0 | 32.0 | 39.0 | 11.0 |
| 4 | 90.0 | NaN | 23.0 | 7.9 | NaN | 8.1 | 8.0 | M063 | 7.9 | NaN | ... | 59.0 | 36.0 | 5.0 | 0.0 | NaN | 10.0 | 5.0 | 10.0 | 60.0 | 15.0 |
5 rows × 2773 columns
我们可以通过查看数据文件夹中伴随问卷数据下载下来的文件来解决这个问题。它告诉我们们数据中重要的部分是哪些:
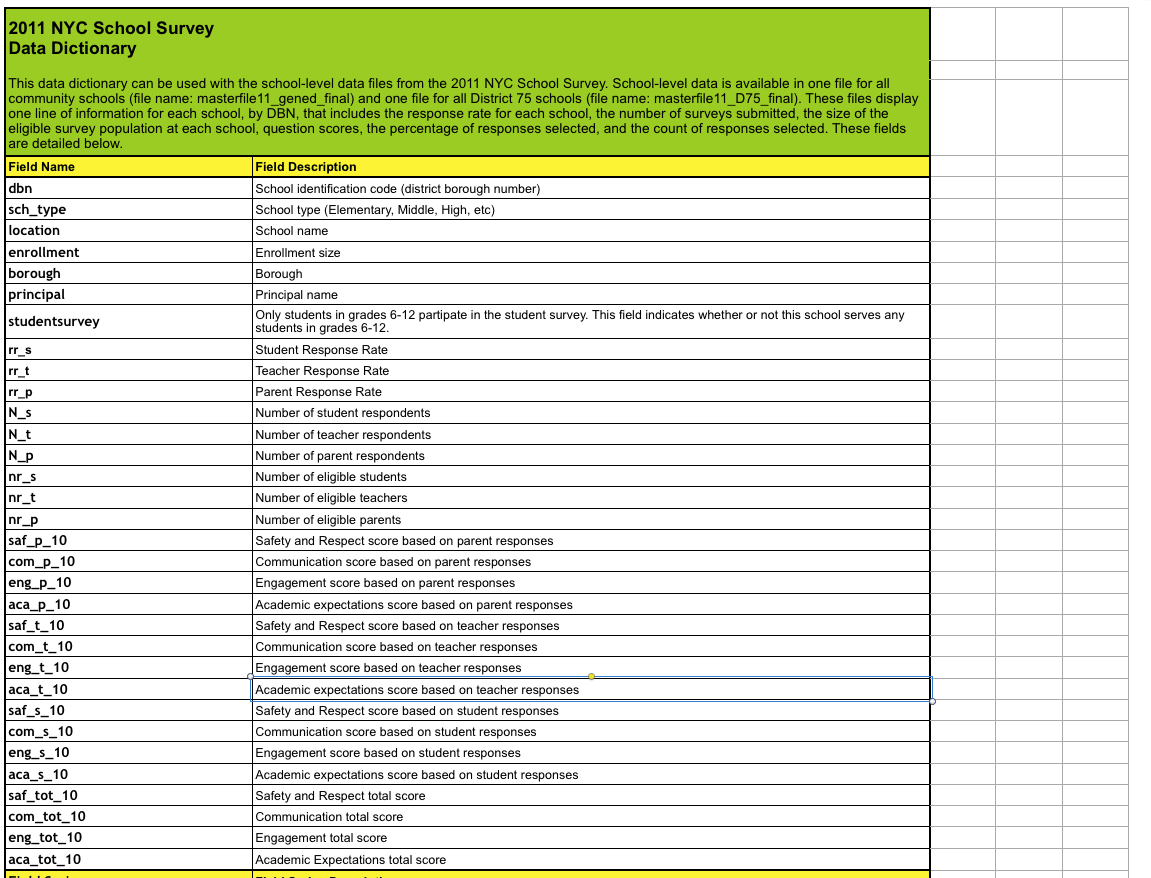
我们可以去除 survey 数据集中多余的列:
In [17]:
survey["DBN"] = survey["dbn"]
survey_fields = ["DBN", "rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_p_11", "com_p_11", "eng_p_11", "aca_p_11", "saf_t_11", "com_t_11", "eng_t_10", "aca_t_11", "saf_s_11", "com_s_11", "eng_s_11", "aca_s_11", "saf_tot_11", "com_tot_11", "eng_tot_11", "aca_tot_11",]
survey = survey.loc[:,survey_fields]
data["survey"] = survey
survey.shape
Out[17]:
(1702, 23)
请确保理你已经了解了每个数据集的内容和相关联的列,这能节约你之后大量的时间和精力:
精简数据集
如果我们查看某些数据集,包括 class_size,我们将立刻发现问题:
In [18]:
data["class_size"].head()
Out[18]:
| CSD | BOROUGH | SCHOOL CODE | SCHOOL NAME | GRADE | PROGRAM TYPE | CORE SUBJECT (MS CORE and 9-12 ONLY) | CORE COURSE (MS CORE and 9-12 ONLY) | SERVICE CATEGORY(K-9* ONLY) | NUMBER OF STUDENTS / SEATS FILLED | NUMBER OF SECTIONS | AVERAGE CLASS SIZE | SIZE OF SMALLEST CLASS | SIZE OF LARGEST CLASS | DATA SOURCE | SCHOOLWIDE PUPIL-TEACHER RATIO | DBN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | GEN ED | - | - | - | 19.0 | 1.0 | 19.0 | 19.0 | 19.0 | ATS | NaN | 01M015 |
| 1 | 1 | M | M015 | P.S. 015 Roberto Clemente | 0K | CTT | - | - | - | 21.0 | 1.0 | 21.0 | 21.0 | 21.0 | ATS | NaN | 01M015 |
| 2 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | GEN ED | - | - | - | 17.0 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN | 01M015 |
| 3 | 1 | M | M015 | P.S. 015 Roberto Clemente | 01 | CTT | - | - | - | 17.0 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | NaN | 01M015 |
| 4 | 1 | M | M015 | P.S. 015 Roberto Clemente | 02 | GEN ED | - | - | - | 15.0 | 1.0 | 15.0 | 15.0 | 15.0 | ATS | NaN | 01M015 |
每所高中都有许多行(正如你所见的重复的 DBN 和 SCHOOL NAME)。然而,如果我们看向 sat_result 数据集,每所高中只有一行:
In [21]:
data["sat_results"].head()
Out[21]:
| DBN | SCHOOL NAME | Num of SAT Test Takers | SAT Critical Reading Avg. Score | SAT Math Avg. Score | SAT Writing Avg. Score | |
|---|---|---|---|---|---|---|
| 0 | 01M292 | HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES | 29 | 355 | 404 | 363 |
| 1 | 01M448 | UNIVERSITY NEIGHBORHOOD HIGH SCHOOL | 91 | 383 | 423 | 366 |
| 2 | 01M450 | EAST SIDE COMMUNITY SCHOOL | 70 | 377 | 402 | 370 |
| 3 | 01M458 | FORSYTH SATELLITE ACADEMY | 7 | 414 | 401 | 359 |
| 4 | 01M509 | MARTA VALLE HIGH SCHOOL | 44 | 390 | 433 | 384 |
为了合并这些数据集,我们将需要找到方法将数据集精简到如 class_size 般一行对应一所高中。否则,我们将不能将 SAT 成绩与班级大小进行比较。我们通过首先更好的理解数据,然后做一些合并来完成。class_size 数据集像 GRADE 和 PROGRAM TYPE,每个学校有多个数据对应。为了将每个范围内的数据变为一个数据,我们将大部分重复行过滤掉,在下面的代码中我们将会:
- 只从
class_size中选择GRADE范围为09-12的行。 - 只从
class_size中选择PROGRAM TYPE是GEN ED的行。 - 将
class_size以DBN分组,然后取每列的平均值。重要的是,我们将找到每所学校班级大小(class_size)平均值。 - 重置索引,将
DBN重新加到列中。
In [68]:
class_size = data["class_size"]
class_size = class_size[class_size["GRADE "] == "09-12"]
class_size = class_size[class_size["PROGRAM TYPE"] == "GEN ED"]
class_size = class_size.groupby("DBN").agg(np.mean)
class_size.reset_index(inplace=True)
data["class_size"] = class_size
精简其它数据集
接下来,我们将需要精简 demographic 数据集。这里有每个学校收集多年的数据,所以这里每所学校有许多重复的行。我们将只选取 schoolyear 最近的可用行:
In [69]:
demographics = data["demographics"]
demographics = demographics[demographics["schoolyear"] == 20112012]
data["demographics"] = demographics
我们需要精简 math_test_results 数据集。这个数据集被 Grade 和 Year 划分。我们将只选取单一学年的一个年级。
In [70]:
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Year"] == 2011]
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Grade"] == '8']
最后,graduation需要被精简:
In [71]:
data["graduation"] = data["graduation"][data["graduation"]["Cohort"] == "2006"]
data["graduation"] = data["graduation"][data["graduation"]["Demographic"] == "Total Cohort"]
在完成工程的主要部分之前数据清理和挖掘是十分重要的。有一个高质量的,一致的数据集将会使你的分析更加快速。
计算变量
计算变量可以通过使我们的比较更加快速来加快分析速度,并且能使我们做到本无法做到的比较。我们能做的第一件事就是从分开的列 SAT Math Avg. Score,SAT Critical Reading Avg. Score 和 SAT Writing Avg. Score 计算 SAT 成绩:
- 将 SAT 列数值从字符转化为数字。
- 将所有列相加以得到
sat_score,即 SAT 成绩。
In [72]:
cols = ['SAT Math Avg. Score', 'SAT Critical Reading Avg. Score', 'SAT Writing Avg. Score']
for c in cols:
data["sat_results"][c] = data["sat_results"][c].convert_objects(convert_numeric=True)
data['sat_results']['sat_score'] = data['sat_results'][cols[0]] + data['sat_results'][cols[1]] + data['sat_results'][cols[2]]
接下来,我们将需要进行每所学校的坐标位置分析,以便我们制作地图。这将使我们画出每所学校的位置。在下面的代码中,我们将会:
- 从
Location 1列分析出经度和维度。 - 转化
lat(经度)和lon(维度)为数字。
In [73]:
data["hs_directory"]['lat'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[0])
data["hs_directory"]['lon'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[1])
for c in ['lat', 'lon']:
data["hs_directory"][c] = data["hs_directory"][c].convert_objects(convert_numeric=True)
现在,我们将输出每个数据集来查看我们有了什么数据:
In [74]:
for k,v in data.items():
print(k)
print(v.head())
math_test_results
DBN Grade Year Category Number Tested Mean Scale Score \
111 01M034 8 2011 All Students 48 646
280 01M140 8 2011 All Students 61 665
346 01M184 8 2011 All Students 49 727
388 01M188 8 2011 All Students 49 658
411 01M292 8 2011 All Students 49 650
Level 1 # Level 1 % Level 2 # Level 2 % Level 3 # Level 3 % Level 4 # \
111 15 31.3% 22 45.8% 11 22.9% 0
280 1 1.6% 43 70.5% 17 27.9% 0
346 0 0% 0 0% 5 10.2% 44
388 10 20.4% 26 53.1% 10 20.4% 3
411 15 30.6% 25 51% 7 14.3% 2
Level 4 % Level 3+4 # Level 3+4 %
111 0% 11 22.9%
280 0% 17 27.9%
346 89.8% 49 100%
388 6.1% 13 26.5%
411 4.1% 9 18.4%
survey
DBN rr_s rr_t rr_p N_s N_t N_p saf_p_11 com_p_11 eng_p_11 \
0 01M015 NaN 88 60 NaN 22.0 90.0 8.5 7.6 7.5
1 01M019 NaN 100 60 NaN 34.0 161.0 8.4 7.6 7.6
2 01M020 NaN 88 73 NaN 42.0 367.0 8.9 8.3 8.3
3 01M034 89.0 73 50 145.0 29.0 151.0 8.8 8.2 8.0
4 01M063 NaN 100 60 NaN 23.0 90.0 8.7 7.9 8.1
... eng_t_10 aca_t_11 saf_s_11 com_s_11 eng_s_11 aca_s_11 \
0 ... NaN 7.9 NaN NaN NaN NaN
1 ... NaN 9.1 NaN NaN NaN NaN
2 ... NaN 7.5 NaN NaN NaN NaN
3 ... NaN 7.8 6.2 5.9 6.5 7.4
4 ... NaN 8.1 NaN NaN NaN NaN
saf_tot_11 com_tot_11 eng_tot_11 aca_tot_11
0 8.0 7.7 7.5 7.9
1 8.5 8.1 8.2 8.4
2 8.2 7.3 7.5 8.0
3 7.3 6.7 7.1 7.9
4 8.5 7.6 7.9 8.0
[5 rows x 23 columns]
ap_2010
DBN SchoolName AP Test Takers \
0 01M448 UNIVERSITY NEIGHBORHOOD H.S. 39
1 01M450 EAST SIDE COMMUNITY HS 19
2 01M515 LOWER EASTSIDE PREP 24
3 01M539 NEW EXPLORATIONS SCI,TECH,MATH 255
4 02M296 High School of Hospitality Management s
Total Exams Taken Number of Exams with scores 3 4 or 5
0 49 10
1 21 s
2 26 24
3 377 191
4 s s
sat_results
DBN SCHOOL NAME \
0 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL STUDIES
1 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL
2 01M450 EAST SIDE COMMUNITY SCHOOL
3 01M458 FORSYTH SATELLITE ACADEMY
4 01M509 MARTA VALLE HIGH SCHOOL
Num of SAT Test Takers SAT Critical Reading Avg. Score \
0 29 355.0
1 91 383.0
2 70 377.0
3 7 414.0
4 44 390.0
SAT Math Avg. Score SAT Writing Avg. Score sat_score
0 404.0 363.0 1122.0
1 423.0 366.0 1172.0
2 402.0 370.0 1149.0
3 401.0 359.0 1174.0
4 433.0 384.0 1207.0
class_size
DBN CSD NUMBER OF STUDENTS / SEATS FILLED NUMBER OF SECTIONS \
0 01M292 1 88.0000 4.000000
1 01M332 1 46.0000 2.000000
2 01M378 1 33.0000 1.000000
3 01M448 1 105.6875 4.750000
4 01M450 1 57.6000 2.733333
AVERAGE CLASS SIZE SIZE OF SMALLEST CLASS SIZE OF LARGEST CLASS \
0 22.564286 18.50 26.571429
1 22.000000 21.00 23.500000
2 33.000000 33.00 33.000000
3 22.231250 18.25 27.062500
4 21.200000 19.40 22.866667
SCHOOLWIDE PUPIL-TEACHER RATIO
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
demographics
DBN Name schoolyear \
6 01M015 P.S. 015 ROBERTO CLEMENTE 20112012
13 01M019 P.S. 019 ASHER LEVY 20112012
20 01M020 PS 020 ANNA SILVER 20112012
27 01M034 PS 034 FRANKLIN D ROOSEVELT 20112012
35 01M063 PS 063 WILLIAM MCKINLEY 20112012
fl_percent frl_percent total_enrollment prek k grade1 grade2 \
6 NaN 89.4 189 13 31 35 28
13 NaN 61.5 328 32 46 52 54
20 NaN 92.5 626 52 102 121 87
27 NaN 99.7 401 14 34 38 36
35 NaN 78.9 176 18 20 30 21
... black_num black_per hispanic_num hispanic_per white_num \
6 ... 63 33.3 109 57.7 4
13 ... 81 24.7 158 48.2 28
20 ... 55 8.8 357 57.0 16
27 ... 90 22.4 275 68.6 8
35 ... 41 23.3 110 62.5 15
white_per male_num male_per female_num female_per
6 2.1 97.0 51.3 92.0 48.7
13 8.5 147.0 44.8 181.0 55.2
20 2.6 330.0 52.7 296.0 47.3
27 2.0 204.0 50.9 197.0 49.1
35 8.5 97.0 55.1 79.0 44.9
[5 rows x 38 columns]
graduation
Demographic DBN School Name Cohort \
3 Total Cohort 01M292 HENRY STREET SCHOOL FOR INTERNATIONAL 2006
10 Total Cohort 01M448 UNIVERSITY NEIGHBORHOOD HIGH SCHOOL 2006
17 Total Cohort 01M450 EAST SIDE COMMUNITY SCHOOL 2006
24 Total Cohort 01M509 MARTA VALLE HIGH SCHOOL 2006
31 Total Cohort 01M515 LOWER EAST SIDE PREPARATORY HIGH SCHO 2006
Total Cohort Total Grads - n Total Grads - % of cohort Total Regents - n \
3 78 43 55.1% 36
10 124 53 42.7% 42
17 90 70 77.8% 67
24 84 47 56% 40
31 193 105 54.4% 91
Total Regents - % of cohort Total Regents - % of grads \
3 46.2% 83.7%
10 33.9% 79.2%
17 74.400000000000006% 95.7%
24 47.6% 85.1%
31 47.2% 86.7%
... Regents w/o Advanced - n \
3 ... 36
10 ... 34
17 ... 67
24 ... 23
31 ... 22
Regents w/o Advanced - % of cohort Regents w/o Advanced - % of grads \
3 46.2% 83.7%
10 27.4% 64.2%
17 74.400000000000006% 95.7%
24 27.4% 48.9%
31 11.4% 21%
Local - n Local - % of cohort Local - % of grads Still Enrolled - n \
3 7 9% 16.3% 16
10 11 8.9% 20.8% 46
17 3 3.3% 4.3% 15
24 7 8.300000000000001% 14.9% 25
31 14 7.3% 13.3% 53
Still Enrolled - % of cohort Dropped Out - n Dropped Out - % of cohort
3 20.5% 11 14.1%
10 37.1% 20 16.100000000000001%
17 16.7% 5 5.6%
24 29.8% 5 6%
31 27.5% 35 18.100000000000001%
[5 rows x 23 columns]
hs_directory
dbn school_name boro \
0 17K548 Brooklyn School for Music & Theatre Brooklyn
1 09X543 High School for Violin and Dance Bronx
2 09X327 Comprehensive Model School Project M.S. 327 Bronx
3 02M280 Manhattan Early College School for Advertising Manhattan
4 28Q680 Queens Gateway to Health Sciences Secondary Sc... Queens
building_code phone_number fax_number grade_span_min grade_span_max \
0 K440 718-230-6250 718-230-6262 9 12
1 X400 718-842-0687 718-589-9849 9 12
2 X240 718-294-8111 718-294-8109 6 12
3 M520 718-935-3477 NaN 9 10
4 Q695 718-969-3155 718-969-3552 6 12
expgrade_span_min expgrade_span_max ... \
0 NaN NaN ...
1 NaN NaN ...
2 NaN NaN ...
3 9 14.0 ...
4 NaN NaN ...
priority05 priority06 priority07 priority08 \
0 NaN NaN NaN NaN
1 NaN NaN NaN NaN
2 Then to New York City residents NaN NaN NaN
3 NaN NaN NaN NaN
4 NaN NaN NaN NaN
priority09 priority10 Location 1 \
0 NaN NaN 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67...
1 NaN NaN 1110 Boston Road\nBronx, NY 10456\n(40.8276026...
2 NaN NaN 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241...
3 NaN NaN 411 Pearl Street\nNew York, NY 10038\n(40.7106...
4 NaN NaN 160-20 Goethals Avenue\nJamaica, NY 11432\n(40...
DBN lat lon
0 17K548 40.670299 -73.961648
1 09X543 40.827603 -73.904475
2 09X327 40.842414 -73.916162
3 02M280 40.710679 -74.000807
4 28Q680 40.718810 -73.806500
[5 rows x 61 columns]
合并数据集
现在我们已经完成了全部准备工作,我们可以用 DBN 列将数据组合在一起了。最终,我们将会从原始数据集得到一个有着上百列的数据集。当我们合并它们,请注意有些数据集中会丢失了 sat_result 中出现的高中。为了解决这个问题,我们需要使用 outer 方法来合并缺少行的数据集,这样我们就不会丢失数据。在实际分析中,缺少数据是很常见的。能够展示解释和解决数据缺失的能力是构建一个作品集的重要部分。
你可以在此阅读关于不同类型的合并。
接下来的代码,我们将会:
- 循环遍历
data文件夹中的每一个条目。 - 输出条目中的非唯一的 DBN 码数量。
- 决定合并策略 -
inner或outer。 - 使用
DBN列将条目合并到 DataFramefull中。
In [75]:
flat_data_names = [k for k,v in data.items()]
flat_data = [data[k] for k in flat_data_names]
full = flat_data[0]
for i, f in enumerate(flat_data[1:]):
name = flat_data_names[i+1]
print(name)
print(len(f["DBN"]) - len(f["DBN"].unique()))
join_type = "inner"
if name in ["sat_results", "ap_2010", "graduation"]:
join_type = "outer"
if name not in ["math_test_results"]:
full = full.merge(f, on="DBN", how=join_type)
full.shape
survey
0
ap_2010
1
sat_results
0
class_size
0
demographics
0
graduation
0
hs_directory
0
Out[75]:
(374, 174)
添加值
现在我们有了我们的 full 数据框架,我们几乎拥有分析需要的所有数据。虽然这里有一些缺少的部分。我们可能将AP 考试结果与 SAT 成绩相关联,但是我们首先需要将这些列转化为数字,然后填充缺失的数据。
In [76]:
cols = ['AP Test Takers ', 'Total Exams Taken', 'Number of Exams with scores 3 4 or 5']
for col in cols:
full[col] = full[col].convert_objects(convert_numeric=True)
full[cols] = full[cols].fillna(value=0)
然后我们将需要计算表示学校所在学区的 school_dist列。这将是我们匹配学区并且使用我们之前下载的区域地图画出地区级别的地图。
In [77]:
full["school_dist"] = full["DBN"].apply(lambda x: x[:2])
最终,我们将需要用该列的平均值填充缺失的数据到 full 中。那么我们就可以计算关联了:
In [79]:
full = full.fillna(full.mean())
计算关联
一个挖掘数据并查看哪些列与你所关心的问题有联系的好方法来就是计算关联。这将告诉你哪列与你所关心的列更加有关联。你可以通过 Pandas DataFrames 的 corr 方法来完成。越接近 0 则关联越小。越接近 1 则正相关越强,越接近 -1 则负关联越强:
In [80]:
full.corr()['sat_score']
Out[80]:
Year NaN
Number Tested 8.127817e-02
rr_s 8.484298e-02
rr_t -6.604290e-02
rr_p 3.432778e-02
N_s 1.399443e-01
N_t 9.654314e-03
N_p 1.397405e-01
saf_p_11 1.050653e-01
com_p_11 2.107343e-02
eng_p_11 5.094925e-02
aca_p_11 5.822715e-02
saf_t_11 1.206710e-01
com_t_11 3.875666e-02
eng_t_10 NaN
aca_t_11 5.250357e-02
saf_s_11 1.054050e-01
com_s_11 4.576521e-02
eng_s_11 6.303699e-02
aca_s_11 8.015700e-02
saf_tot_11 1.266955e-01
com_tot_11 4.340710e-02
eng_tot_11 5.028588e-02
aca_tot_11 7.229584e-02
AP Test Takers 5.687940e-01
Total Exams Taken 5.585421e-01
Number of Exams with scores 3 4 or 5 5.619043e-01
SAT Critical Reading Avg. Score 9.868201e-01
SAT Math Avg. Score 9.726430e-01
SAT Writing Avg. Score 9.877708e-01
...
SIZE OF SMALLEST CLASS 2.440690e-01
SIZE OF LARGEST CLASS 3.052551e-01
SCHOOLWIDE PUPIL-TEACHER RATIO NaN
schoolyear NaN
frl_percent -7.018217e-01
total_enrollment 3.668201e-01
ell_num -1.535745e-01
ell_percent -3.981643e-01
sped_num 3.486852e-02
sped_percent -4.413665e-01
asian_num 4.748801e-01
asian_per 5.686267e-01
black_num 2.788331e-02
black_per -2.827907e-01
hispanic_num 2.568811e-02
hispanic_per -3.926373e-01
white_num 4.490835e-01
white_per 6.100860e-01
male_num 3.245320e-01
male_per -1.101484e-01
female_num 3.876979e-01
female_per 1.101928e-01
Total Cohort 3.244785e-01
grade_span_max -2.495359e-17
expgrade_span_max NaN
zip -6.312962e-02
total_students 4.066081e-01
number_programs 1.166234e-01
lat -1.198662e-01
lon -1.315241e-01
Name: sat_score, dtype: float64
这给了我们一些我们需要探索的内在规律:
total_enrollment与sat_score强相关,这是令人惊讶的,因为你曾经认为越小的学校越专注于学生就会取得更高的成绩。- 女生所占学校的比例(
female_per) 与 SAT 成绩呈正相关,而男生所占学生比例(male_per)成负相关。 - 没有问卷与 SAT 成绩成正相关。
- SAT 成绩有明显的种族不平等(
white_per、asian_per、black_per、hispanic_per)。 ell_percent与 SAT 成绩明显负相关。
每一个条目都是一个挖掘和讲述数据故事的潜在角度。
设置上下文
在我们开始数据挖掘之前,我们将希望设置上下文,不仅为了我们自己,也是为了其它阅读我们分析的人。一个好的方法就是建立挖掘图表或者地图。因此,我们将在地图标出所有学校的位置,这将有助于读者理解我们所探索的问题。
在下面的代码中,我们将会:
- 建立纽约市为中心的地图。
- 为城市里的每所高中添加一个标记。
- 显示地图。
In [82]:
import folium
from folium import plugins
schools_map = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
marker_cluster = folium.MarkerCluster().add_to(schools_map)
for name, row in full.iterrows():
folium.Marker([row["lat"], row["lon"]], popup="{0}: {1}".format(row["DBN"], row["school_name"])).add_to(marker_cluster)
schools_map.create_map('schools.html')
schools_map
Out[82]:
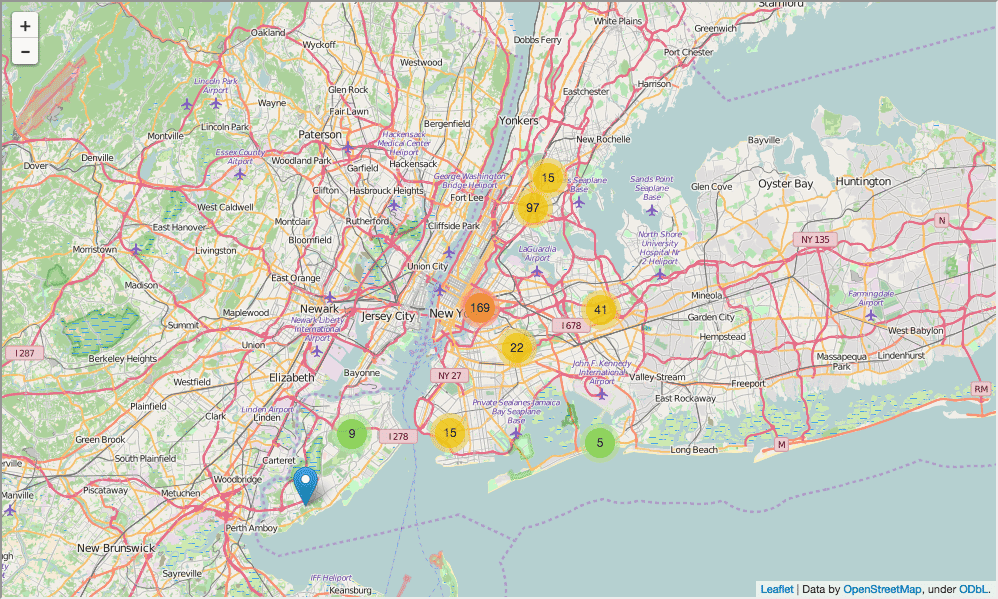
这个地图十分有用,但是不容易查看纽约哪里学校最多。因此,我们将用热力图来代替它:
In [84]:
schools_heatmap = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
schools_heatmap.add_children(plugins.HeatMap([[row["lat"], row["lon"]] for name, row in full.iterrows()]))
schools_heatmap.save("heatmap.html")
schools_heatmap
Out[84]:
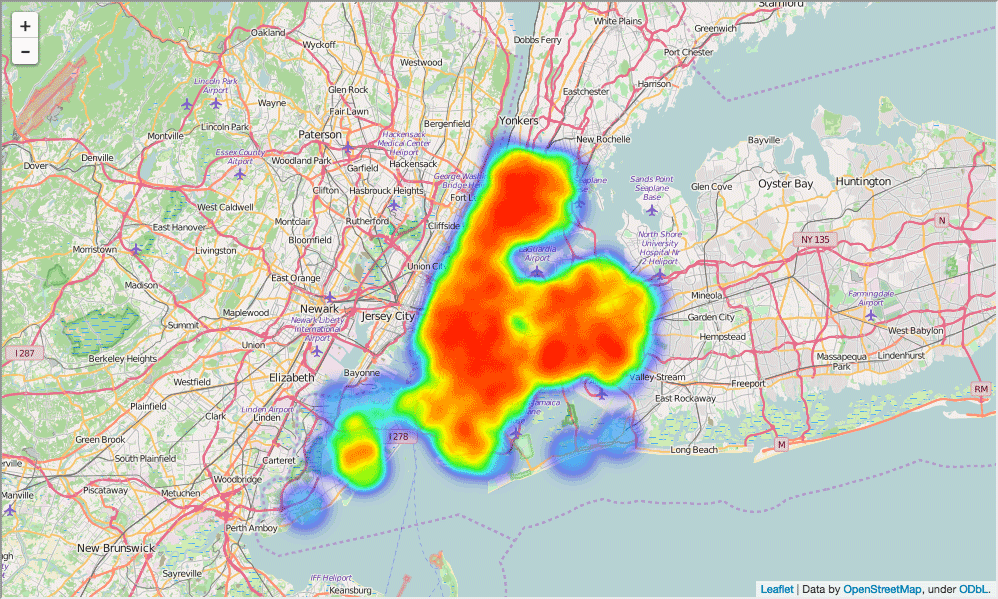
区域级别映射
热力图能够很好的标出梯度,但是我们将需要更结构化的画出不同城市之间的 SAT 分数差距。学区是一个图形化这个信息的很好的方式,就像每个区域都有自己的管理者。纽约市有数十个学区,并且每个区域都是一个小的地理区域。
我们可以通过学区来计算 SAT 分数,然后将它们画在地图上。在下面的代码中,我们将会:
- 通过学区对
full进行分组。 - 计算每个学区的每列的平均值。
- 去掉
school_dist字段头部的 0,然后我们就可以匹配地理数据了。
In [ ]:
district_data = full.groupby("school_dist").agg(np.mean)
district_data.reset_index(inplace=True)
district_data["school_dist"] = district_data["school_dist"].apply(lambda x: str(int(x)))
我们现在将可以画出 SAT 在每个学区的平均值了。因此,我们将会读取 GeoJSON 中的数据,转化为每个区域的形状,然后通过 school_dist 列对每个区域图形和 SAT 成绩进行匹配。最终我们将创建一个图形:
In [85]:
def show_district_map(col):
geo_path = 'schools/districts.geojson'
districts = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
districts.geo_json(
geo_path=geo_path,
data=district_data,
columns=['school_dist', col],
key_on='feature.properties.school_dist',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
)
districts.save("districts.html")
return districts
show_district_map("sat_score")
Out[85]:
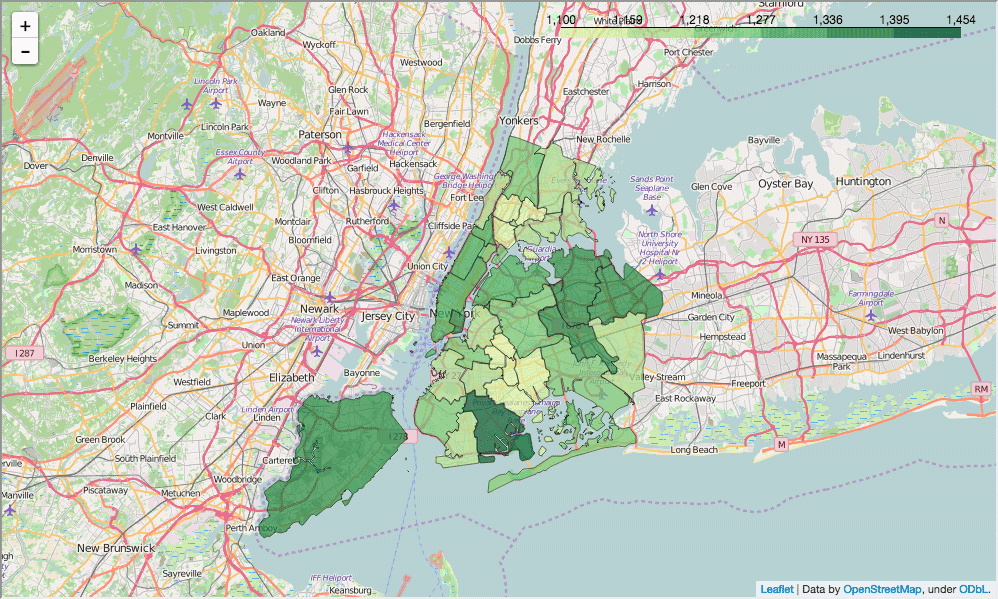
挖掘注册学生数与SAT分数
现在我们已经依地区画出学校位置和 SAT 成绩确定了上下文,浏览我们分析的人将会对数据的上下文有更好的理解。现在我们已经完成了基础工作,我们可以开始从我们上面寻找关联时所提到的角度分析了。第一个分析角度是学校注册学生人数与 SAT 成绩。
我们可以通过所有学校的注册学生与 SAT 成绩的散点图来分析。
In [87]:
%matplotlib inline
full.plot.scatter(x='total_enrollment', y='sat_score')
Out[87]:
<matplotlib.axes._subplots.AxesSubplot at 0x10fe79978>
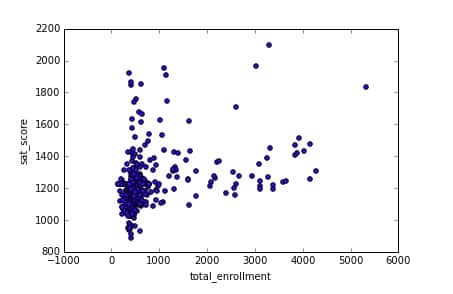
如你所见,底下角注册人数较低的部分有个较低 SAT 成绩的聚集。这个集群以外,SAT 成绩与全部注册人数只有轻微正相关。这个画出的关联显示了意想不到的图形.
我们可以通过获取低注册人数且低SAT成绩的学校的名字进行进一步的分析。
In [88]:
full[(full["total_enrollment"] < 1000) & (full["sat_score"] < 1000)]["School Name"]
Out[88]:
34 INTERNATIONAL SCHOOL FOR LIBERAL ARTS
143 NaN
148 KINGSBRIDGE INTERNATIONAL HIGH SCHOOL
203 MULTICULTURAL HIGH SCHOOL
294 INTERNATIONAL COMMUNITY HIGH SCHOOL
304 BRONX INTERNATIONAL HIGH SCHOOL
314 NaN
317 HIGH SCHOOL OF WORLD CULTURES
320 BROOKLYN INTERNATIONAL HIGH SCHOOL
329 INTERNATIONAL HIGH SCHOOL AT PROSPECT
331 IT TAKES A VILLAGE ACADEMY
351 PAN AMERICAN INTERNATIONAL HIGH SCHOO
Name: School Name, dtype: object
在 Google 上进行了一些搜索确定了这些学校大多数是为了正在学习英语而开设的,所以有这么低注册人数(规模)。这个挖掘向我们展示了并不是所有的注册人数都与 SAT 成绩有关联 - 而是与是否将英语作为第二语言学习的学生有关。
挖掘英语学习者和 SAT 成绩
现在我们知道英语学习者所占学校学生比例与低的 SAT 成绩有关联,我们可以探索其中的规律。ell_percent 列表示一个学校英语学习者所占的比例。我们可以制作关于这个关联的散点图。
In [89]:
full.plot.scatter(x='ell_percent', y='sat_score')
Out[89]:
<matplotlib.axes._subplots.AxesSubplot at 0x10fe824e0>
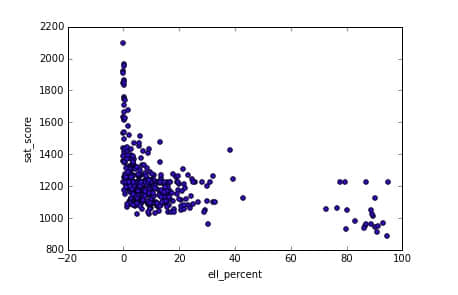
看起来这里有一组学校有着高的 ell_percentage 值并且有着低的 SAT 成绩。我们可以在学区层面调查这个关系,通过找出每个学区英语学习者所占的比例,并且查看是否与我们的学区层面的 SAT 地图所匹配:
In [90]:
show_district_map("ell_percent")
Out[90]:
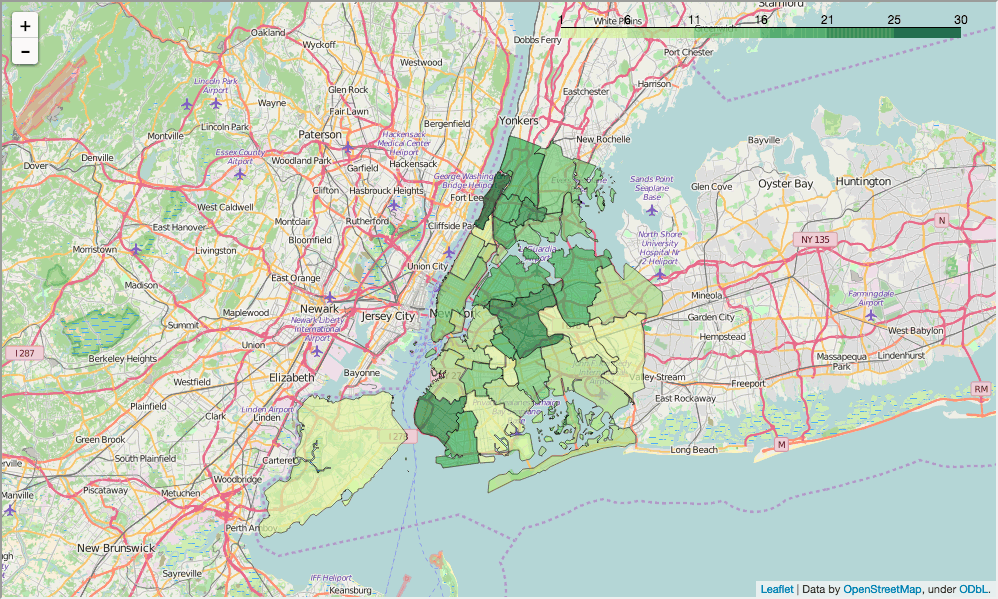
我们可通过两个区域层面地图来查看,一个低 ELL(English-language)学习者比例的地区更倾向有高 SAT 成绩,反之亦然。
关联问卷分数和 SAT 分数
学生、家长和老师的问卷结果如果与 SAT 分数有很大的关联的假设是合理的。就例如具有高学术期望的学校倾向于有着更高的 SAT 分数是合理的。为了测这个理论,让我们画出 SAT 分数和多种问卷指标:
In [91]:
full.corr()["sat_score"][["rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_tot_11", "com_tot_11", "aca_tot_11", "eng_tot_11"]].plot.bar()
Out[91]:
<matplotlib.axes._subplots.AxesSubplot at 0x114652400>
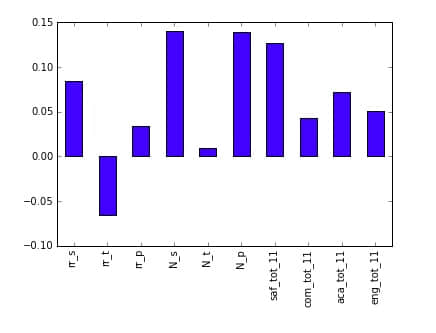
惊人的是,关联最大的两个因子是 N_p 和 N_s,它们分别是家长和学生回应的问卷。都与注册人数有着强关联,所以很可能偏离了 ell_learner。此外指标关联最强的就是 saf_t_11,这是学生、家长和老师对学校安全程度的感知。这说明了,越安全的学校,更能让学生在环境里安心学习。然而其它因子,像互动、交流和学术水平都与 SAT 分数无关,这也许表明了纽约在问卷中问了不理想的问题或者想错了因子(如果他们的目的是提高 SAT 分数的话)。
挖掘种族和 SAT 分数
其中一个角度就是调查种族和 SAT 分数的联系。这是一个大相关微分,将其画出来帮助我们理解到底发生了什么:
In [92]:
full.corr()["sat_score"][["white_per", "asian_per", "black_per", "hispanic_per"]].plot.bar()
Out[92]:
<matplotlib.axes._subplots.AxesSubplot at 0x108166ba8>
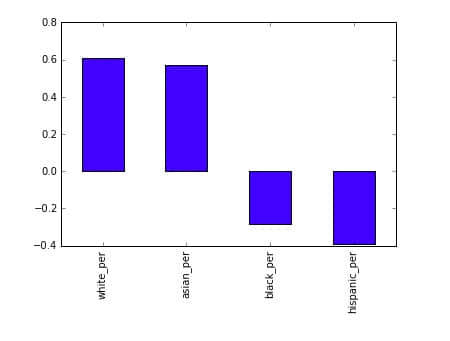
看起来更高比例的白种和亚洲学生与更高的 SAT 分数有关联,而更高比例的黑人和西班牙裔与更低的 SAT 分数有关联。对于西班牙学生,这可能因为近年的移民还是英语学习者的事实。我们可以标出学区层面的西班牙裔的比例并观察联系。
In [93]:
show_district_map("hispanic_per")
Out[93]:
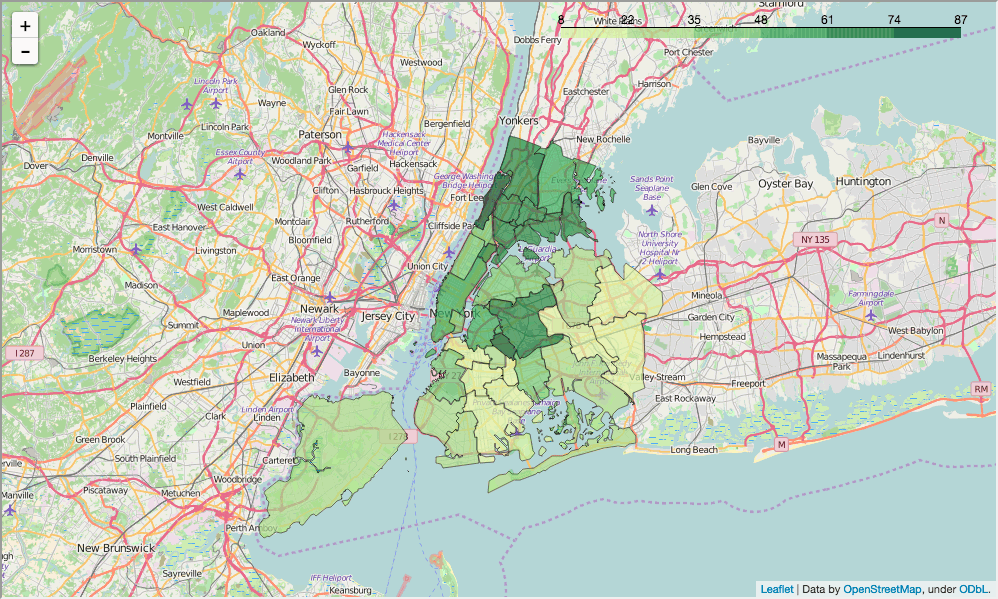
看起来这里与英语学习者比例有关联,但是有必要对这种和其它种族在 SAT 分数上的差异进行挖掘。
SAT 分数上的性别差异
挖掘性别与 SAT 分数之间的关系是最后一个角度。我们注意更高的女生比例的学校倾向于与更高的 SAT 分数有关联。我们可以可视化为一个条形图:
In [94]:
full.corr()["sat_score"][["male_per", "female_per"]].plot.bar()
Out[94]:
<matplotlib.axes._subplots.AxesSubplot at 0x10774d0f0>
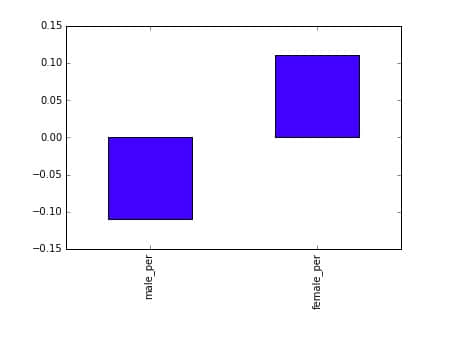
为了挖掘更多的关联性,我们可以制作一个 female_per 和 sat_score 的散点图:
In [95]:
full.plot.scatter(x='female_per', y='sat_score')
Out[95]:
<matplotlib.axes._subplots.AxesSubplot at 0x104715160>
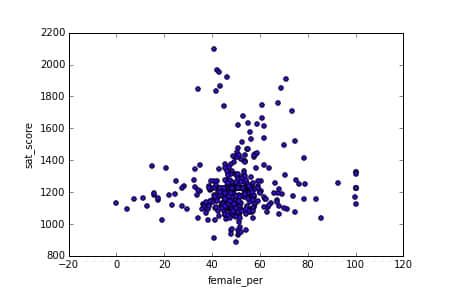
看起来这里有一个高女生比例、高 SAT 成绩的簇(右上角)(LCTT 译注:此处散点图并未有如此迹象,可能数据图有误)。我们可以获取簇中学校的名字:
In [96]:
full[(full["female_per"] > 65) & (full["sat_score"] > 1400)]["School Name"]
Out[96]:
3 PROFESSIONAL PERFORMING ARTS HIGH SCH
92 ELEANOR ROOSEVELT HIGH SCHOOL
100 TALENT UNLIMITED HIGH SCHOOL
111 FIORELLO H. LAGUARDIA HIGH SCHOOL OF
229 TOWNSEND HARRIS HIGH SCHOOL
250 FRANK SINATRA SCHOOL OF THE ARTS HIGH SCHOOL
265 BARD HIGH SCHOOL EARLY COLLEGE
Name: School Name, dtype: object
使用 Google 进行搜索可以知道这些是专注于表演艺术的精英学校。这些学校有着更高比例的女生和更高的 SAT 分数。这可能解释了更高的女生比例和 SAT 分数的关联,并且相反的更高的男生比例与更低的 SAT 分数。
AP 成绩
至今,我们关注的是人口统计角度。还有一个角度是我们通过数据来看参加高阶测试(AP)的学生和 SAT 分数。因为高学术成绩获得者倾向于有着高的 SAT 分数说明了它们是有关联的。
In [98]:
full["ap_avg"] = full["AP Test Takers "] / full["total_enrollment"]
full.plot.scatter(x='ap_avg', y='sat_score')
Out[98]:
<matplotlib.axes._subplots.AxesSubplot at 0x11463a908>
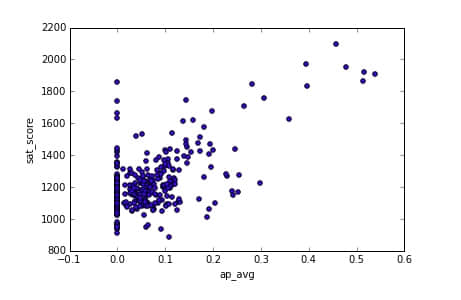
看起来它们之间确实有着很强的关联。有趣的是右上角高 SAT 分数的学校有着高的 AP 测试通过比例:
In [99]:
full[(full["ap_avg"] > .3) & (full["sat_score"] > 1700)]["School Name"]
Out[99]:
92 ELEANOR ROOSEVELT HIGH SCHOOL
98 STUYVESANT HIGH SCHOOL
157 BRONX HIGH SCHOOL OF SCIENCE
161 HIGH SCHOOL OF AMERICAN STUDIES AT LE
176 BROOKLYN TECHNICAL HIGH SCHOOL
229 TOWNSEND HARRIS HIGH SCHOOL
243 QUEENS HIGH SCHOOL FOR THE SCIENCES A
260 STATEN ISLAND TECHNICAL HIGH SCHOOL
Name: School Name, dtype: object
通过 google 搜索解释了那些大多是高选择性的学校,你需要经过测试才能进入。这就说明了为什么这些学校会有高的 AP 通过人数。
包装故事
在数据科学中,故事不可能真正完结。通过向其他人发布分析,你可以让他们拓展并且运用你的分析到他们所感兴趣的方向。比如在本文中,这里有一些角度我们没有完成,并且可以探索更加深入。
一个开始讲述故事的最好方式就是尝试拓展或者复制别人已经完成的分析。如果你觉得采取这个方式,欢迎你拓展这篇文章的分析,并看看你能发现什么。如果你确实这么做了,请在下面评论,那么我就可以看到了。
下一步
如果你做的足够多,你看起来已经对用数据讲故事和构建你的第一个数据科学作品集有了很好的理解。一旦你完成了你的数据科学工程,发表在 Github 上是一个好的想法,这样别人就能够与你一起合作。
如果你喜欢这篇文章,你可能希望阅读我们‘Build a Data Science Portfolio’系列文章的其它部分:
via: https://www.dataquest.io/blog/data-science-portfolio-project/
作者:Vik Paruchuri 译者:[Yoo-4x] 校对:wxy