Linux 内核动手编译实用指南

一份让你深入体验最新 Linux 内核编译过程的实操指南。
出于各种原因,自行编译 Linux 内核可能引起你的兴趣。这些原因可能包括但不限于:
- 测试一个比你目前的 Linux 发行版更新的内核版本
- 采用一组不同的配置选项、驱动来构建内核
- 学习者的好奇心 ?
此指南将一步步指导你如何亲自编译 Linux 内核,包括你该运行哪些命令,为什么运行这些命令以及这些命令的执行效果。本文篇幅较长,所以请做好准备!
? 诸如 Ubuntu 这样的发行版提供了更简单地安装主线 Linux 内核的方式。但本教程目标是从源码手动完成所有工作。此教程需要你付出时间、耐心以及丰富的 Linux 命令行使用经验。本文更注重亲身实践的体验。不管怎么说,我仍建议你在虚拟机或备用系统中尝试此冒险,而非在你的主系统上进行。
前置准备
在软件领域,构建任何事物都有两个基本要求:
- 源代码
- 构建依赖
因此,作为预备环节,我们需要下载 Linux 内核的源码压缩包,并安装一些能让我们成功构建 Linux 内核的依赖项。
Linux 版本导览
在任何时刻,Freax Linux 内核都有四种“版本”。
Linux 的这些 “版本”,按照开发流程的顺序是:
- linux-next 树: 所有准备合并到 Linux 代码库的代码首先被合并到 linux-next 树。它代表的是 Linux 内核最新也是“最不稳定”的状态。大多数 Linux 内核开发者和测试人员使用这个来提高代码质量,为 Linus Torvalds 的后续提取做准备。请谨慎使用!
- 发布候选版(RC) / 主线版: Linus 从 linux-next 树抽取代码并创建一个初始发布版本。这个初始发布版本的测试版称为 RC( 发布候选 )版本。一旦 RC 版本发布,Linus 只会接受对它的错误修复和性能退化相关的补丁。基础这些反馈,Linus 会每周发布一个 RC 内核,直到他对代码感到满意。RC 发行版本的标识是
-rc后缀,后面跟一个数字。 - 稳定版: 当 Linus 觉得最新的 RC 版本已稳定时,他会发布最终的“公开”版本。稳定发布版将会维护几周时间。像 Arch Linux 和 Fedora Linux 这样的前沿 Linux 发行版会使用此类版本。我建议你在试用 linux-next 或任何 RC 版本之前,先试一试此版本。
- LTS 版本: 每年最后一个稳定版将会再维护 几年。这通常是一个较旧的版本,但它会 会积极地维护并提供安全修复。Debian 的稳定版本会使用 Linux 内核的 LTS 版版本。
若想了解更多此方面的知识,可参阅 官方文档。
本文将以当前可用的最新稳定版为例,编写此文时的 Linux 内核版本是 6.5.5。
系统准备
由于 Linux 内核使用 C 语言编写,编译 Linux 内核至少需要一个 C 编译器。你的计算机上可能还需要其他一些依赖项,现在是安装它们的时候了。
? 这个指南主要聚焦于使用 GNU C 编译器(GCC)来编译 Linux 内核。但在未来的文章中(可能会深入介绍 Rust 的支持),我可能会介绍使用 LLVM 的 Clang 编译器作为 GCC 的替代品。
不过,请注意,MSVC 并不适用。尽管如此,我仍期待有微软的员工为此发送修补程序集。我在瞎想啥?
对于 Arch Linux 以及其衍生版本的用户,安装命令如下:
sudo pacman -S base-devel bc coreutils cpio gettext initramfs kmod libelf ncurses pahole perl python rsync tar xz
对于 Debian 以及其衍生版本的用户,安装命令如下:
sudo apt install bc binutils bison dwarves flex gcc git gnupg2 gzip libelf-dev libncurses5-dev libssl-dev make openssl pahole perl-base rsync tar xz-utils
对于 Fedora 以及其衍生版本的用户,安装命令如下:
sudo dnf install binutils ncurses-devel \
/usr/include/{libelf.h,openssl/pkcs7.h} \
/usr/bin/{bc,bison,flex,gcc,git,gpg2,gzip,make,openssl,pahole,perl,rsync,tar,xz,zstd}
下载 Linux 内核源码
请访问 kernel.org,在页面中寻找第一个 稳定 版本。你不会找不到它,因为它是最显眼的黄色方框哦 ?
点击访问 kernel.org
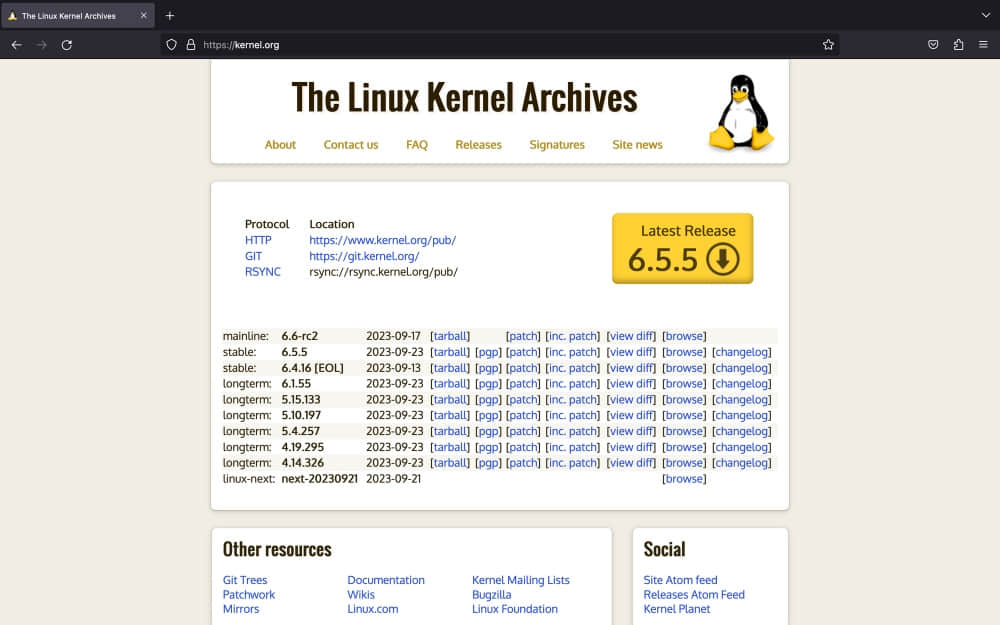
通过点击黄色的方框,你就可以下载 Tar 文件。同时,也别忘了下载相匹配的 PGP 签名文件,稍后我们需要用到它来验证 Tar 文件。它的扩展名为 .tar.sign。
校验 Tar 文件的完整性
你如何知道刚下载的 Tar 文件是否被损坏?对于个人来说,一个损坏的 Tar 文件只会浪费你的宝贵时间,如果你是在为一个组织工作,那么可能会危及到组织的安全(这时你可能还有更大的问题需要担忧,但我们并不想让所有人都产生创伤后应激障碍!)。
为了验证我们的 Tar 文件的完整性,我们需要先解压它。目前,它是使用 XZ 压缩算法压缩的。因此,我将使用 unxz 工具(其实就是 xz --decompress 的别名)来解压 .tar.xz 格式的压缩文件。
unxz --keep linux-*.tar.xz
解压完成后,我们需要获取 Linus Torvalds 和 Greg KH 使用的 GPG 公开密钥。这些密钥用于对 Tar 文件进行签名。
gpg2 --locate-keys [email protected] [email protected]
你应该可以得到一个与我在我的电脑上看到的类似的结果:
$ gpg2 --locate-keys [email protected] [email protected]
gpg: /home/pratham/.gnupg/trustdb.gpg: trustdb created
gpg: key 38DBBDC86092693E: public key "Greg Kroah-Hartman <[email protected]>" imported
gpg: Total number processed: 1
gpg: imported: 1
gpg: key 79BE3E4300411886: public key "Linus Torvalds <[email protected]>" imported
gpg: Total number processed: 1
gpg: imported: 1
pub rsa4096 2011-09-23 [SC]
647F28654894E3BD457199BE38DBBDC86092693E
uid [ unknown] Greg Kroah-Hartman <[email protected]>
sub rsa4096 2011-09-23 [E]
pub rsa2048 2011-09-20 [SC]
ABAF11C65A2970B130ABE3C479BE3E4300411886
uid [ unknown] Linus Torvalds <[email protected]>
sub rsa2048 2011-09-20 [E]
在导入 Greg 和 Linus 的密钥后,我们可以使用 --verify 标志来验证 Tar 的完整性,操作如下:
gpg2 --verify linux-*.tar.sign
如果验证成功,你应该会看到如下的输出信息:
$ gpg2 --verify linux-*.tar.sign
gpg: assuming signed data in 'linux-6.5.5.tar'
gpg: Signature made Saturday 23 September 2023 02:46:13 PM IST
gpg: using RSA key 647F28654894E3BD457199BE38DBBDC86092693E
gpg: Good signature from "Greg Kroah-Hartman <[email protected]>" [unknown]
gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Primary key fingerprint: 647F 2865 4894 E3BD 4571 99BE 38DB BDC8 6092 693E
务必查看是否存在 gpg: Good signature 的提示,然后再继续!
? 你可以忽略以下警告:
WARNING: This key is not certified with a trusted signature! There is no indication that the signature belongs to the owner.。我们已根据 Linus 和 Greg 的邮件地址获取了公开密钥,并无需对此警告感到担忧。
解压 Tar 文件
如果你顺利的进行到这里,意味着你的 Tar 文件完整性检查已经成功完成。接下来,我们将从 Tar 文件中解压出 Linux 内核的源码。

这个步骤十分简单,只需对 Tar 文件执行 tar -xf 命令,如下:
tar -xf linux-*.tar
在这里,-x 选项表示解压,-f 选项则用来告诉 Tar 文件的文件名。
这个解压过程可能需要几分钟时间,你可以先放松,耐心等待一下。
配置 Linux 内核
Linux 内核的构建过程会查找 .config 文件。顾名思义,这是一个配置文件,用于指定 Linux 内核的所有可能的配置选项。这是必需的文件。
获取 Linux 内核的 .config 文件有两种方式:
- 使用你的 Linux 发行版的配置作为基础(推荐做法)
- 使用默认的,通用的配置
? 也有第三种方法,也就是从零开始,手动配置每一个选项,但注意,这需要配置超过 12,000 个选项。并不推荐这种方式,因为手动配置所有选项将花费大量的时间,并且你还需要理解每个启用和禁用选项的含义。
使用发行版提供的配置
使用你的 Linux 发行版提供的配置是一个安全的选择。 如果你只是跟随这个指南测试一个不是你的发行版提供的新内核,那么这就是推荐的方式。
你的 Linux 发行版的 Linux 内核配置文件会在以下两个位置之一:
- 大多数 Linux 发行版,如 Debian 和 Fedora 及其衍生版,将会把它存在
/boot/config-$(uname -r)。 - 一些 Linux 发行版,比如 Arch Linux 将它整合在了 Linux 内核中。所以,可以在
/proc/config.gz找到。
? 如果两者都有,建议使用 /proc/config.gz。这是因为它在只读文件系统中,所以是未被篡改的。进入含有已经解压出的 Tar 文件的目录。
cd linux-*/
接着,复制你的 Linux 发行版的配置文件:
### Debian 和 Fedora 及其衍生版:
$ cp /boot/config-"$(uname -r)" .config
### Arch Linux 及其衍生版:
$ zcat /proc/config.gz > .config
更新配置文件
一旦完成这些步骤,接下来就需要“更新”配置文件了。因为你的发行版提供的配置很可能比你正在构建的 Linux 内核版本要旧。
? 这同样适用于像 Arch Linux 和 Fedora 这样前沿的 Linux 发行版。 它们并不会因为有新版本可用就立刻发布更新。他们会进行一些质量控制工作,这必然会花费些时间。因此,即便是你的发行版提供的最新内核,相较于你在 kernel.org 上获取的版本也会滞后几个小版本。
要更新一个已有的 .config 文件,我们使用 make 命令搭配 olddefconfig 参数。简单解释一下,这个命令的意思是使用 旧的、默认的、配置。
这将使用“旧的配置文件”(当前保存为 .config,这是你发行版配置的一份直接副本),并检查从上一版本以来 Linux 代码库中新加的任何配置选项。如果找到任何新的、未配置 的选项,该选项的默认配置值会被使用,并会对 .config 文件进行更新。
原来的 .config 文件将被重命名为 .config.old 进行备份,并将新的更改写入至 .config 文件。
make olddefconfig
以下是我机器上的输出:
$ file .config
.config: Linux make config build file, ASCII text
$ make olddefconfig
HOSTCC scripts/basic/fixdep
HOSTCC scripts/kconfig/conf.o
HOSTCC scripts/kconfig/confdata.o
HOSTCC scripts/kconfig/expr.o
LEX scripts/kconfig/lexer.lex.c
YACC scripts/kconfig/parser.tab.[ch]
HOSTCC scripts/kconfig/lexer.lex.o
HOSTCC scripts/kconfig/menu.o
HOSTCC scripts/kconfig/parser.tab.o
HOSTCC scripts/kconfig/preprocess.o
HOSTCC scripts/kconfig/symbol.o
HOSTCC scripts/kconfig/util.o
HOSTLD scripts/kconfig/conf
.config:8593:warning: symbol value 'm' invalid for USB_FOTG210_HCD
.config:8859:warning: symbol value 'm' invalid for USB_FOTG210_UDC
#
# configuration written to .config
#
针对 Debian 及其衍生版用户
Debian 及其衍生版为内核模块使用一个签名证书。默认情况下,你的计算机并不包含这个证书。
我推荐关闭启用模块签名的选项。具体如下所示:
./scripts/config --file .config --set-str SYSTEM_TRUSTED_KEYS ''
./scripts/config --file .config --set-str SYSTEM_REVOCATION_KEYS ''
如果你不这么做,在后面你进行 Linux 内核构建时,可能会导致构建失败。要注意这点。
使用自定义配置
如果你出于学习内核开发的目的学习如何构建 Linux 内核,那你应该这样做。
? 请注意,偏离你的 Linux 发行版的配置可能无法在实体硬件上“正常”工作。问题可能是特定硬件无法工作、Linux 内核无法启动等。
因此,我们只建议在虚拟机中使用。
你可以通过查看 make help 的输出 来查看 所有 可用的选项,但我们主要关注三个 make 目标:
defconfig: 默认配置。allmodconfig: 根据当前系统状态,尽可能地把项目构建为可加载模块(而非内建)。tinyconfig: 极简的 Linux 内核。
由于 tinyconfig 目标只会构建少数项目,构建时间将会缩短。我个人选择它的原因主要有:
- 检查我在代码/工具链中做的修改是否正确,以及代码是否可以编译。
- 在虚拟机中只进行少数选项的测试。
? 在为 ARM 或 RISC-V 机器构建 Linux 内核时,你可能需要 DTB(设备树的二进制文件)。使用
tinyconfig目标将不会启用构建 DTB 的选项,你的内核很可能无法启动。当然,你可以用 QEMU 在没有任何 DTB 的情况下启动 Linux 内核。但这篇文章并不会聚焦在此。或许你可以通过评论,让我在之后的时间里覆盖这个话题 ?
除非你确切地知道自己在做什么,否则你应当使用 defconfig 目标。 以下是我在我的电脑上运行的效果:
$ make defconfig
HOSTCC scripts/basic/fixdep
HOSTCC scripts/kconfig/conf.o
HOSTCC scripts/kconfig/confdata.o
HOSTCC scripts/kconfig/expr.o
LEX scripts/kconfig/lexer.lex.c
YACC scripts/kconfig/parser.tab.[ch]
HOSTCC scripts/kconfig/lexer.lex.o
HOSTCC scripts/kconfig/menu.o
HOSTCC scripts/kconfig/parser.tab.o
HOSTCC scripts/kconfig/preprocess.o
HOSTCC scripts/kconfig/symbol.o
HOSTCC scripts/kconfig/util.o
HOSTLD scripts/kconfig/conf
*** Default configuration is based on 'defconfig'
#
# configuration written to .config
#
修改配置
无论你是使用 Linux 发行版的配置并更新它,还是使用 defconfig 目标创建新的 .config 文件,你都可能希望熟悉如何修改这个配置文件。最可靠的修改方式是使用 menuconfig 或 nconfig 目标。
这两个目标的功能是相同的,只不过提供给你的界面有所不同。这是这两者间唯一的区别。我个人更偏向于使用 menuconfig 目标,但近来我发现 nconfig 在搜索选项时似乎更具直观性,所以我逐渐转向使用它。
首先,带着 menuconfig 目标运行 make 命令:
$ make menuconfig
HOSTCC scripts/kconfig/mconf.o
HOSTCC scripts/kconfig/lxdialog/checklist.o
HOSTCC scripts/kconfig/lxdialog/inputbox.o
HOSTCC scripts/kconfig/lxdialog/menubox.o
HOSTCC scripts/kconfig/lxdialog/textbox.o
HOSTCC scripts/kconfig/lxdialog/util.o
HOSTCC scripts/kconfig/lxdialog/yesno.o
HOSTLD scripts/kconfig/mconf
在此界面,你可以根据各选项的类型来进行切换操作。
有两类可切换选项:
- 布尔状态选项:这类选项只能关闭(
[ ])或作为内建组件开启([*])。 - 三态选项:这类选项可以关闭(
< >)、内建(<*>),或作为可加载模块(<M>)进行构建。
想要了解更多关于某个选项的信息,使用上/下箭头键导航至该选项,然后按 <TAB> 键,直至底部的 < Help > 选项被选中,然后按回车键进行选择。此时就会显示关于该配置选项的帮助信息。
在修改选项时请务必谨慎。
当你满意配置后,按 <TAB> 键直到底部的 < Save > 选项被选中。然后按回车键进行选择。然后再次按回车键(记住,此时不要更改文件名),就能将更新后的配置保存到 .config 文件中。
构建 Linux 内核
构建 Linux 内核实际上十分简单。然而,在开始构建之前,让我们为自定义内核构建添加一个标签。我将使用字符串 -pratham 作为标签,并利用 LOCALVERSION 变量来实施。你可以使用以下命令实现配置:
./scripts/config --file .config --set-str LOCALVERSION "-pratham"
这一命令将 .config 文件中的 CONFIG_LOCALVERSION 配置选项设为我在结尾指定的字符串,即 -pratham。当然,你也不必非得使用我所用的名字哦 ?
LOCALVERSION 选项可用于设置一个“本地”版本,它会被附加到通常的 x.y.z 版本方案之后,并在你运行 uname -r 命令时一并显示。
由于我正在构建的是 6.5.5 版本内核,而 LOCALVERSION 字符串被设为 -pratham,因此,对我来说,最后的版本名将会是 6.5.5-pratham。这么做的目的是确保我所构建的自定义内核不会与发行版所提供的内核产生冲突。
接下来,我们来真正地构建内核。可以用以下的命令完成此步骤:
make -j$(nproc) 2>&1 | tee log
这对大部分(99%)用户来说已经足够了。
其中的 -j 选项用于指定并行编译任务的数量。而 nproc 命令用于返回可用处理单位(包括线程)的数量。因此,-j$(nproc) 其实意味着“使用我拥有的 CPU 线程数相同数量的并行编译任务”。
2>&1 会将 STDOUT 和 STDIN 重定向到相同的文件描述符,并通过管道传输给 tee 命令,这会将输出存储在一个名为 log 的文件,并且在控制台打印出完全相同的文本。如果你在构建时遇到错误,并希望回顾日志来检查出了什么问题,这将会十分有用。遇到那种情况,你只需要简单执行 grep Error log 命令就能找到线索。
自定义 make 目标
在 Linux 内核的源文件夹中,make 命令有一些自定义的目标可供执行各种操作。这些主要作为开发者的参考。如果你的唯一目标是安装一个比你当前发行版更新的 Linux 内核,那么你完全可以跳过这部分内容 ?
构建目标
作为一名开发者,你可能只想构建 Linux 内核,或者只想构建模块,或者只想构建设备树二进制(DTB)。在这种情况下,你可以指定一个构建目标,然后 make 命令只会构建指定的项目,而不会构建其他的。
以下是一些构建目标:
vmlinux:纯粹的 Linux 内核。modules:可加载模块。dtbs:设备树二进制文件(主要用于 ARM 和 RISC-V 架构)。all:构建所有被标记了星号*的项目(从make help的输出中可以查看)。
通常情况下,你并不需要指定构建目标,因为它们都已经在构建列表中。所列出的目标是在你只想要测试某一个构建目标,而不是其他目标时的情况。
依据你的 计算机架构,构建完成的 Linux 内核镜像(存放在 /boot 目录)的名称会有所不同。
对于 x86_64,Linux 内核的默认镜像名称是 bzImage。因此,如果你只需要构建引导所需的 Linux 内核,你可以像下面这样设定 bzImage 为目标:
### 对于 x86_64
$ make bzImage
“那么如何在我的架构上找到用来调用 make 的目标名称呢?”
有两种方法。要么你可以执行 make help 之后查找在 Architecture specific targets 下,第一个前面带有星号 * 的选项。
或者,如果你希望自动完成,你可以利用 image_name 目标得到镜像的完全路径(相对路径),选择性地添加 -s 标志来获得有用的输出。
以下是我拥有的三台电脑的输出,一台是 x86_64,另一台是 AArch64,还有一台是 riscv :
### x86_64
$ make -s image_name
arch/x86/boot/bzImage
### AArch64
$ make -s image_name
arch/arm64/boot/Image.gz
### RISC-V
$ make -s image_name
arch/riscv/boot/Image.gz
现在,要只构建 Linux 内核镜像,你可以这样进行:
make $(make -s image_name | awk -F '/' '{print $4}')
清理目标
如果你需要清理构建产生的文件,你可以用以下的目标来实现你的需求:
clean:除了.config文件外,删除几乎所有其他内容。mrproper:执行了make clean的所有操作外,还会删除.config文件。distclean:除了执行make mrproper的所有操作外,还会清理任何补丁文件。
安装
一旦成功编译了 Linux 内核,接下来就是启动安装一些东西的时候了。“一些 东西?” 没错,我们至少构建了两种不同的东西,如果你使用的是 ARM 或 RISC-V 架构,那就有三种。我会在以下内容中详细解释。
? 虽然我将告诉你不同的安装方式,尤其是关于如何改变默认安装路径的方法,但如果你不确定自己在做什么,那么我不建议你这么做! 请慎重考虑,如果你决定走自定义的路线,那你需要自己负责后果。默认设置之所以存在,是因为它们有其特殊的原因 ?
安装内核模块
Linux 内核有部分在系统启动时并非必需的。这些部分被构建为可加载模块,即在需要时才进行加载和卸载。
所以,首先需要安装这些模块。这可以通过 modules_install 目标完成。必须使用 sudo,因为模块会被安装在 /lib/modules/<kernel_release>-<localversion> 这个需要 root 权限的路径下。
这个过程不仅会安装内核模块,还会对其进行签名,所以可能需要一些时间。好消息是你可以通过之前提到的 -j$(nproc) 选项来并行执行安装任务,这样会快一些。?
sudo make modules_install -j$(nproc)
给开发者的提示: 你可以通过设定
INSTALL_MOD_PATH变量来指定一个不同的路径存放 Linux 模块,而不用默认的/lib/modules/<kernel_release>-<localversion>,具体如下:sudo make modules_install INSTALL_MOD_PATH=<path>
另一个给开发者的提示: 你可以使用INSTALL_MOD_STRIP变量来决定是否需要剥离模块的调试符号。如果未设定该变量,调试符号不会被剥离。当设为1时,符号信息将会被使用--strip-debug选项剥离,随后该选项会传递给strip(或者在使用 Clang 的时候传递给llvm-strip)工具。
(可选)安装 Linux 内核头文件
如果你打算使用这个内核来支持树外模块,比如 ZFS 或英伟达 DKMS,或者打算尝试自行编写模块,你可能会需要 Linux 内核提供的头文件。
可以通过以下方式使用 headers_install 目标来安装 Linux 内核头文件:
sudo make headers_install
应使用 sudo 命令,因为这些头文件会被安装到 /usr 目录。同时还会在 /usr 目录内创建子目录 include/linux,然后将头文件安装到 /usr/include/linux 内。
给开发者的提示: 通过设定 INSTALL_HDR_PATH 变量,你可以修改 Linux 内核头文件的安装路径。安装 DTB(只针对 ARM 和 RISC-V)
如果你使用的是 x86\_64 架构,那么你可以跳过此步骤!
如果你针对 ARM 或者 RISC-V 构建了内核,那么在运行 make 的过程中,设备树的二进制文件可能已经被编译出来了。你可以通过在 arch/<machine_architecture>/boot/dts 目录查找 .dtb 文件来确认这一点。
这里提供了一个快速检查的技巧:
### 对于 AArch32
$ find arch/arm/boot/dts -name "*.dtb" -type f | head -n 1 > /dev/null && echo "DTBs for ARM32 were built"
### 对于 AArch64
$ find arch/arm64/boot/dts -name "*.dtb" -type f | head -n 1 > /dev/null && echo "DTBs for ARM64 were built"
### 对于 RISC-V
$ find arch/riscv/boot/dts -name "*.dtb" -type f | head -n 1 > /dev/null && echo "DTBs for RISC-V were built"
如果你看到出现 DTBs for <arch> were built 的消息,那么你可以开始安装 DTB。这可以通过 dtbs_install 目标来实现。
需要使用 sudo,因为它们会被安装在 /boot/dtb-<kernel_release>-<localversion> 中,而这个目录是由 root 所拥有的。
sudo make dtbs_install
给开发者的提示: 就像安装模块一样,你可以使用 INSTALL_DTBS_PATH 变量指定一个自定义的路径来安装设备树二进制文件。安装 Linux 内核
最后,我们来安装 Linux 内核本身!这可以通过 install 目标来完成,就像这样:
sudo make install
在这里必须使用 sudo,因为 Linux 内核将被安装在 /boot 目录,而这个目录不允许普通用户写入。
? 一般来讲,install 目标也会更新引导加载程序,但是如果它没有成功,那可能是不支持你使用的引导加载程序。如果你没有使用 GRUB 作为你的引导加载程序,请一定要阅读你引导加载程序的使用手册 ?给开发者的提示: 并不奇怪,INSTALL_PATH变量被用来设定 Linux 内核的安装位置,而非默认的/boot目录。
针对 Arch Linux 用户的说明
如果你尝试执行了 make install 命令,可能已经注意到产生了错误。错误如下:
$ sudo make install
INSTALL /boot
Cannot find LILO.
要在 Arch Linux 上实际完成 Linux 内核的安装,我们需要手动复制 Linux 内核镜像文件。别担心,如果你使用的是 Arch Linux,手动操作应该是家常便饭了。( ͡° ͜ʖ ͡°)
可以使用以下命令完成这个步骤:
sudo install -Dm644 "$(make -s image_name)" /boot/vmlinuz-<kernel_release>-<localversion>
因为我编译的是 6.5.5 版本的内核,所以我将会执行下面这条命令,你可以根据你的实际情况进行适当调整:
sudo install -Dm644 "$(make -s image_name)" /boot/vmlinuz-6.5.5-pratham
虽然不是必须的,但最好复制一份名为 System.map 的文件。既然你已经在操作了,一并也复制了 .config 文件吧 ?
sudo cp -vf System.map /boot/System.map-<kernel_release>-<localversion>
sudo cp -vf .config /boot/config-<kernel_release>-<localversion>
生成初始 RAM 磁盘
当你安装 Arch Linux 时,可能已经了解过 mkinitcpio 这个工具。现在,我们将使用它来创建初始的 RAM 磁盘。
首先,我们需要创建一个预设文件。向 /etc/mkinitcpio.d/linux-<localversion>.preset 文件中添加以下内容,根据实际需要来替换 <kernel_release> 和 <localversion>。
ALL_config="/etc/mkinitcpio.conf"
ALL_kver="/boot/vmlinuz-<kernel_release>-<localversion>"
PRESETS=('default' 'fallback')
default_image="/boot/initramfs-<kernel_release>-<localversion>.img"
fallback_options="-S autodetect"
配置完成后,执行下面的命令来生成初始 RAM 磁盘:
sudo mkinitcpio -p linux-<localversion>
我自己的电脑上得到的输出如下,你的结果应该会类似!
$ sudo mkinitcpio -p linux-pratham
==> Building image from preset: /etc/mkinitcpio.d/linux-pratham.preset: 'default'
==> Using configuration file: '/etc/mkinitcpio.conf'
-> -k /boot/vmlinuz-6.5.5-pratham -c /etc/mkinitcpio.conf -g /boot/initramfs-6.5.5-pratham.img
==> Starting build: '6.5.5-pratham'
-> Running build hook: [base]
-> Running build hook: [udev]
-> Running build hook: [autodetect]
-> Running build hook: [modconf]
-> Running build hook: [kms]
-> Running build hook: [keyboard]
==> WARNING: Possibly missing firmware for module: 'xhci_pci'
-> Running build hook: [keymap]
-> Running build hook: [consolefont]
==> WARNING: consolefont: no font found in configuration
-> Running build hook: [block]
-> Running build hook: [filesystems]
-> Running build hook: [fsck]
==> Generating module dependencies
==> Creating zstd-compressed initcpio image: '/boot/initramfs-6.5.5-pratham.img'
==> Image generation successful
==> Building image from preset: /etc/mkinitcpio.d/linux-pratham.preset: 'fallback'
==> Using configuration file: '/etc/mkinitcpio.conf'
==> WARNING: No image or UKI specified. Skipping image 'fallback'
初始 RAM 磁盘已成功生成,现在我们可以进入下一步,更新引导加载器!
更新 GRUB
一旦所有必要的文件已成功复制到其对应的位置,接下来,我们将进行 GRUB 的更新。
使用以下命令对 GRUB 引导加载器进行更新:
sudo grub-mkconfig -o /boot/grub/grub.cfg
? 如果你使用的引导加载器不是 GRUB,请参看 Arch Wiki 中相关的引导加载器文档。
注意,更新 GRUB 并不会直接使新的内核版本设为默认启动选项。在引导时,请在启动菜单中手动选择新的内核版本。
你可以通过选择 Advanced options for Arch Linux 菜单,并在随后的菜单中选择 Arch Linux, with Linux <kernel_release>-<localversion> 来启用新版的 Linux 内核。
重启电脑
恭喜你!你已经完成了获取 Linux 内核源代码、进行配置、构建以及安装等所有步骤。现在只需要通过重启电脑并进入新构建和安装的 Linux 内核,就可以开始享受你的努力成果了。
启动时,请确保从引导加载器中选择正确的 Linux 内核版本。系统启动后,运行 uname -r 命令来确认你正在使用预期的 Linux 内核。
以下是我自己的电脑输出的内容:
$ uname -r
6.5.5-pratham
是时候开始庆祝了! ?
卸载操作
? 提示:在删除当前正在使用的内核版本之前,你应该首先切换至较旧的内核版本。
可能你的 Linux 发行版所使用的 Linux 内核版本就是你手动编译的版本,或者你自行编译了新的内核并注意到应卸载旧的内核以节省空间,于是你开始想如何才能卸载。当然,虽然我们无法简单地运行 make uninstall 命令,但这并不代表没有其他的方法!
我们清楚各个文件的安装位置,因此删除它们相对简单。
### 删除内核模块
$ rm -rf /lib/modules/<kernel_release>-<localversion>
### 删除设备树二进制文件
$ rm -rf /boot/dtb-<kernel_release>-<localversion>
### 删除 Linux 内核本身
$ rm -vf /boot/{config,System,vmlinuz}-<kernel_release>-<localversion>
总结
这个过程不是一次简单的旅程,是吧?但是现在,我们终于抵达了终点。我们一起学习了手动编译 Linux 内核的全过程,包括安装依赖、获取和验证源码、解压源码、配置 Linux 内核、构建内核以及安装内核。
如果你喜欢这个详细的步骤指南,请给我留言反馈。如果在操作过程中遇到问题,也欢迎提出,让我知道!
(题图:MJ/853481c5-87e3-42aa-8ace-e9ddfa232f75)
via: https://itsfoss.com/compile-linux-kernel/
作者:Pratham Patel 选题:lujun9972 译者:ChatGPT 校对:wxy








