被误用的罗伊·菲尔丁的有关描述性状态迁移(REST)的博士论文

符合 描述性状态迁移 (LCTT 译注:REST,译自审定公布名词数据库)的应用程序接口(API)无处不在。有趣的是又有多少人真正了解“符合描述性状态迁移”的应有之义呢?
大概我们中的大多数人都会跟 黑客新闻网站上的这篇公开问答 产生共鸣:
我阅读了几篇介绍描述性状态迁移(REST)的文章,甚至包括原始论文的部分章节。然而我仍然对REST 到底是什么只有一个相当模糊的想法。我开始认为没有人真的了解它,它仅仅是一个定义相当不充分的概念。
我曾经计划写一篇有关 REST 的博客,在里面探讨 REST 是如何成为这样一个在网络通信领域占主导地位的范式的。我通过阅读 2000 年发表的 罗伊·菲尔丁 的博士论文 开始我的研究,这篇博士论文向世人介绍了 REST 的概念。在读过菲尔丁的博士论文以后,我意识到,相比之下,更引人注意的是菲尔丁的理论缘何受到如此普遍的误解。
(相对公平地说,)很多人知道 REST 源自菲尔丁的博士论文,但并没有读过该论文。因此对于这篇博士论文的原始内容的误解才得以流行。
最大的误解是:这篇博士论文直接解决了构建 API(API)的问题,我此前一直认为 REST 从一开始就打算成为构建在超文本传输协议(HTTP)之上的 网络 API 的架构模型,我相信很多人也这样认为。我猜测此前可能存在一个混乱的试验时期,开发人员采用完全错误的方式在 HTTP 基础上开发 API,然后菲尔丁出现了,并提出了将 REST 做为网络应用程序开发的正确方式。但是这种想法的时间线对不上:我们今天所熟知的网络服务的 API 并非是在菲尔丁出版他的博士论文之后才出现的新生事物。
菲尔丁的博士论文《架构风格与基于网络的软件架构设计》不是讨论如何在 HTTP 的基础上构建 API,而恰恰是讨论 HTTP 本身。菲尔丁是 HTTP/1.0 版规范的贡献者,同时也是 HTTP/1.1 版的共同作者。有感于从 HTTP 的设计中获得的架构经验,他的博士论文将 REST 视为指导 HTTP/1.1 的标准化过程的架构原则的精华。举例而言,他拒绝了使用新的 MGET 和 MHEAD 方法进行批量请求的提议,因为他认为这违反了 REST 所定义的约束条件,尤其是在一个符合 REST 的系统中传递的消息应该是易于代理和缓存的约束条件。 [1] 因此,HTTP/1.1 转而围绕持久性连接设计,在此基础上可以发送多个 HTTP 请求。(菲尔丁同时认为网页保存在本地的浏览数据,即 cookie 是不符合 REST 的,因为它们在一个状态无关的系统中增加了状态描述,然而它们的应用已经根深蒂固了。 [2] )菲尔丁认为,REST 并非构建基于 HTTP 的系统的操作指南,而是扩展 HTTP 的操作指南。
这并不意味着菲尔丁认为 REST 不能用于构建其他系统。只是他假定其他系统也是 “ 分布式超媒体系统 ”。人们对 REST 还有另一个误解:认为它是一个可以用在任何网络应用中的通用架构。但是从这篇博士论文中菲尔丁介绍 REST 的部分你基本上能够得出如下的结论,“请注意,我们只设计了 HTTP,但是如果你发现你自己也在设计一个\_分布式超媒体系统\_,你也应该采用我们提出的称为 REST 的优秀架构,以让开发变得更容易”。有鉴于互联网已经存在了,我们尚不清楚为什么菲尔丁认为有人可能试图重新创建这样一个(和 HTTP 一样的)系统。或许在 2000 年的时候世界上仍然存在不只一个分布式超文本系统的空间吧。无论如何,菲尔丁已经说得很清楚了,REST 意在提供一套解决方案,来解决在试图经由网络连接超文本内容时出现的可扩展性与一致性问题,而不是 作为分布式应用的通用架构模型。
我们现在只记得菲尔丁的博士论文提出了 REST 的概念,但事实上,他的博士论文是在讨论一刀切的软件架构有多么糟糕,以及如何更好地选择符合你需求的软件架构。这篇博士论文中仅用了一个章节来讨论 REST 本身,大量的文本内容都都花在了对你能够在网络应用中运用的不同的架构风格 [3] 的分类上。这些架构风格包括:受 Unix 的管道设计启发的 管道-过滤器 (PF)风格, 客户-服务器 (CS)风格的多种改进,如 分层-客户-服务器 (LCS)风格、 客户-缓存-无状态-服务器 (C$SS)风格和<ruby> 分层-客户-缓存-无状态-服务器 <rt> Layered-Client-Cache-Stateless-Server </rt></ruby>(LC$SS)。这些缩略词未必实用,但是菲尔丁认为我们可以通过混合匹配现有风格提供的约束条件来派生出新的风格。REST 就是通过这种方式产生的,它本可以称之为 一致性-分层-按需代码-客户-缓存-无状态-服务器 (ULCODC$SS)风格,显然我们并没有这样做。菲尔丁建立上述分类是为了强调(每一种风格对应的)约束适用于不同的应用,而上述最后一种风格对应的约束是他所认为的最适用于 HTTP 的。
今天,REST 的无处不在是极具讽刺意味的。REST 在各种各样的网络应用中被盲目使用,但是菲尔丁最初只是将 REST 视作一种指引,通过它指导人们裁剪一种软件架构来适应独立应用的特殊需求。
我很难弄清楚这是如何发生的,毕竟菲尔丁已经明确地指出了不能让形式服从功能的陷阱。他在论文的一开始就作出了警告:由于没有正确地理解软件架构而“使用流行的架构设计是经常发生的” [4] 。他在几页之后又重新强调了这一点:
一些架构风格经常被描述为适用于一切软件形式的“银弹”解决方案。然而,一名好的设计者应该选择能够满足解决特定问题的需要的架构风格 [5] 。
REST 本身就是一个特别糟糕的 “银弹” 解决方案。正如菲尔丁所指出的,它包含了可能不合适的利弊权衡,除非你试图构建一个分布式超媒体应用:
REST 设计用来高效地进行大粒度的超媒体数据传输,并对网络应用场景中的常用见情形做了优化,但是可能会导致其在与其他形式的软件架构相互作用时不协调。 [6]
菲尔丁提出 REST 是因为网络发展带来了“ 超越政府的可扩展性 ”这一棘手问题,菲尔丁的意思是需要以一种高性能的方式跨越组织和国家边界连接文件。REST 所施加的约束是经过精心选择的,以用来解决这一“超越政府的扩展性”问题。面向公众 的网络服务 API 同样需要解决类似的问题,因此可以理解为什么 REST 在这些应用中是适用的。然而,时至今日,如果发现一个工程团队使用 REST 构建了一个后端,即使这个后端只与工程团队完全控制的客户端通讯,也不会令人惊讶。我们都成为了 蒙蒂巨蟒 的独幕滑稽剧 中的建筑师,那位建筑师按照屠宰场的风格设计了一座公寓大楼,因为屠宰场是他唯一具有的经验的建筑。(菲尔丁使用了这部滑稽剧中的一句台词作为他的博士论文的题词:打扰一下,你说的是“刀”吗?)(LCTT 校注:顺便说一句,Python 语言的名称来自于 “Monty Python” 这个英国超现实幽默表演团体的名字。)
有鉴于菲尔丁的博士论文一直在极力避免提供一种放之四海而皆准的软件架构,REST 又怎么会成为所有网络服务的事实上的标准呢?
我认为,在 21 世纪头十年的中期人们已经厌倦了简单对象访问协议(SOAP),因此想要创造另一种属于他们自己的四字首字母缩略词。
我只是半开玩笑。 简单对象访问协议 (SOAP)是一个冗长而复杂的协议,以致于你没法在不事先理解一堆互相关联的可扩展标记语言(XML)规范的基础上使用它。早期的网络服务提供基于 SOAP 的 API。在 21 世纪头十年中期,随着越来越多的 API 开始提供,被 SOAP 的复杂性激怒的软件开发者随之集体迁移。
SOAP 遭到了这群人的蔑视,Rails 之父 戴维·海涅迈尔·汉森 (LCTT 译注:译自其所著的《重来》的中文版的作者译名)曾经评论:“我们感觉 SOAP 过于复杂了,它已经被企业人员接管。而当这一切发生的时候,通常没有什么好结果。” [7] 始于这一标志性的评论,Ruby-on-Rails 于 2007 年放弃了对 SOAP 的支持。“企业人员”总是希望所有内容都被正式指定,反对者认为这是浪费时间。
如果反对者不再继续使用 SOAP,他们仍然需要一些标准化的方式来进行工作。由于所有人都在使用 HTTP,而且代理与缓存的所有支持,每个人都至少会继续使用 HTTP 作为传输层,因此最简单的解决方案就是依赖 HTTP 的现有语义。这正是他们所做的工作。他们曾经称之为: 去它的,重载 HTTP (FIOH)。这会是一个准确的名称,任何曾经试图决定业务逻辑错误需要返回什么 HTTP 状态码的人都能证明这一点。但是在所有的 SOAP 正式规范工作的映衬下,这显得鲁莽而乏味。
幸运的是,出现了这篇由 HTTP/1.1 规范的共同作者创作的博士论文。这篇博士论文与扩展 HTTP 有某种模糊的联系,并给予了 FIOH 一个具有学术体面的外表。因此 REST 非常适合用来掩饰其实仅仅是 FIOH 的东西。
我并不是说事情就是这样发生的,也不是说在不敬业的创业者中确实存在着盗用 REST 的阴谋,但是这个故事有助于我理解,在菲尔丁的博士论文根本就不是讨论网络服务 API 的情况下,REST 是如何成为用于网络服务 API 的架构模型的。采用 REST 的约束存在一些效果,尤其是对于那些面向公众的需要跨越组织边界的 API 来说。这些 API 通常会从 REST 的“统一接口”中受益。这应该是 REST 起初在构建网络 API 时被提及的核心原因。但是,想象一下一种叫做 “FIOH” 的独立方法,它借用 “REST” 的名字只是为了营销,这有助于我解释我们今天所知道的 REST 式 API 与菲尔丁最初描述的 REST 的架构风格之间的诸多差异。
举例而言,REST 纯粹主义者经常抱怨,那些所谓 RESTful API 实际并不是 REST API,因为它们根本就没有使用 超文本作为应用程序状态引擎 (HATEOAS)。菲尔丁本人也做出过 这样的批评。根据菲尔丁的观点,一个真正的 REST API 应当允许你通过跟随链接实现从一个基础端点访问所有的端点。如果你认为这些人的确在试图构建 RESTful API,那么存在一个明显的疏漏 —— 使用超文本作为应用程序状态引擎(HATEOAS)的确是菲尔丁最初提出的 REST 概念的基础,尤其是考虑到“描述性状态迁移(REST)”中的“状态迁移(ST)”意指使用资源之间的超链接进行状态机的导航(而不是像很多人所相信的那样通过线路传输资源状态) [8] 。但是你试想一下,如果每个人都只是在构建 FIOH 的 API,并明里暗里的将之作为 REST API 宣传,或者更诚实一点说是作为 “RESTful” API 宣传,那么自然使用超文本作为应用程序状态引擎(HATEOAS)也就不重要了。
类似的,你可能会感到惊讶:尽管软件开发者喜欢不断地争论使用 PUT 方法还是使用 PATCH 方法来更新资源更加 RESTful,菲尔丁的博士论文却没有讨论哪个 HTTP 的操作方法应该映射到增删改查(CURD)操作。在 HTTP 操作与 CURD 操作之间建立一个标准的映射表是有用的,但是这一映射表是 FIOH 的一部分而不是 REST 的一部分。
这就是为什么,与其说没有人理解 REST,不如说我们应该认为 “REST” 这一术语是被误用了。REST API 这一现代概念与菲尔丁的 REST 架构之间存在历史联系,但事实上它们是两个不同的概念。历史联系适合作为确定何时构建 RESTful API 的指引而留在心底。你的 API 需要像 HTTP 那样跨越组织和政府边界吗?如果是的话,那么构建具有统一的可预测的接口的 RESTful API 可能是正确的方式。如果不是的话,你最好记住,菲尔丁更倾向于形式服从功能。或许类似 GraphQL 的方案或者仅仅 JSON-RPC 更适合你试图完成的工作。
- Roy Fielding. “Architectural Styles and the Design of Network-based Software Architectures,” 128. 2000. University of California, Irvine, PhD Dissertation, accessed June 28, 2020, https://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation_2up.pdf. ↩︎
- Fielding, 130. ↩︎
- Fielding distinguishes between software architectures and software architecture “styles.” REST is an architectural style that has an instantiation in the architecture of HTTP. ↩︎
- Fielding, 2. ↩︎
- Fielding, 15. ↩︎
- Fielding, 82 ↩︎
- Paul Krill. “Ruby on Rails 2.0 released for Web Apps,” InfoWorld. Dec 7, 2007, accessed June 28, 2020, https://www.infoworld.com/article/2648925/ruby-on-rails-2-0-released-for-web-apps.html ↩︎
- Fielding, 109. ↩︎
via: https://twobithistory.org/2020/06/28/rest.html
作者:Two-Bit History 选题:lujun9972 译者:CanYellow 校对:wxy

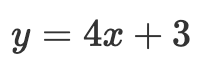 的常见代数式表示变量 y 与 变量 x 之间的关系。形如
的常见代数式表示变量 y 与 变量 x 之间的关系。形如 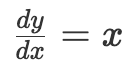 或
或 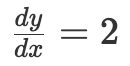 的微分方程表示变化率与其它变量间的关系。本质上微分方程就是用纯数学方式来描述变化率。前面第一个方程表示 “变量 y 相对于变量 x 的变化率刚好等于 x 。”第二个方程表示“无论 x 的值是多少, y 相对于 x 的变化率总是 2。”
的微分方程表示变化率与其它变量间的关系。本质上微分方程就是用纯数学方式来描述变化率。前面第一个方程表示 “变量 y 相对于变量 x 的变化率刚好等于 x 。”第二个方程表示“无论 x 的值是多少, y 相对于 x 的变化率总是 2。”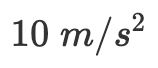 )向地球加速运动。那么如何用微分方程来解决这个问题呢?
)向地球加速运动。那么如何用微分方程来解决这个问题呢?


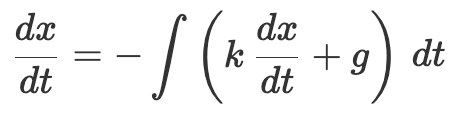

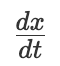 。积分器在左下方,由于这是二阶微分方程,所以我们需要两个积分器。电机驱动顶部标注为 t 的传动轴。(有趣的是,布什将这些水平传动轴称为“总线”。)
。积分器在左下方,由于这是二阶微分方程,所以我们需要两个积分器。电机驱动顶部标注为 t 的传动轴。(有趣的是,布什将这些水平传动轴称为“总线”。) 标记的传动轴的转动量,并通过齿轮组进行放缩。用 ∑ 标记的方框是 加法器 。它通过巧妙的齿轮组合将两个传动轴的的转动叠加起来驱动第三个传动轴。我们的方程中涉及了求两项之和,所以需要引入加法器。这些额外组件的引入确保了微分分析仪有足够的灵活性来模拟由各种各样的项和系数组成的方程。
标记的传动轴的转动量,并通过齿轮组进行放缩。用 ∑ 标记的方框是 加法器 。它通过巧妙的齿轮组合将两个传动轴的的转动叠加起来驱动第三个传动轴。我们的方程中涉及了求两项之和,所以需要引入加法器。这些额外组件的引入确保了微分分析仪有足够的灵活性来模拟由各种各样的项和系数组成的方程。 。速度又反过来作为积分器 I 的输入,推动它的转盘让输出转轮以速率
。速度又反过来作为积分器 I 的输入,推动它的转盘让输出转轮以速率 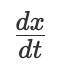 转动。积分器 I 的输出作为最终结果将会被直接导向到输出面板上。
转动。积分器 I 的输出作为最终结果将会被直接导向到输出面板上。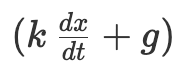 为输入,但是该传动轴的转动又部分决定于积分器 II 的输出本身。这可能快把你绕吐了,但在物理上这并没有任何问题——因为所有部部件都是一同转动的。出现这种怪圈并没什么奇怪的,因为在用微分方程在描述某函数的变化率时,也经常会用该函数的函数的形式。(在这个例子中,加速度,即速度的变化率,取决于于速度。)
为输入,但是该传动轴的转动又部分决定于积分器 II 的输出本身。这可能快把你绕吐了,但在物理上这并没有任何问题——因为所有部部件都是一同转动的。出现这种怪圈并没什么奇怪的,因为在用微分方程在描述某函数的变化率时,也经常会用该函数的函数的形式。(在这个例子中,加速度,即速度的变化率,取决于于速度。)







