AWS 和 GCP 的 Spark 技术哪家强?
Tianhui Michael Li 和 Ariel M’ndange-Pfupfu 将在今年 10 月 10、12 和 14 号组织一个在线经验分享课程:Spark 分布式计算入门。该课程的内容包括创建端到端的运行应用程序和精通 Spark 关键工具。
毋庸置疑,云计算将会在未来数据科学领域扮演至关重要的角色。弹性,可扩展性和按需分配的计算能力作为云计算的重要资源,直接导致云服务提供商集体火拼。其中最大的两股势力正是亚马逊网络服务(AWS) 和谷歌云平台(GCP)。

本文依据构建时间和运营成本对 AWS 和 GCP 的 Spark 工作负载作一个简短比较。实验由我们的学生在 数据孵化器 进行, 数据孵化器 是一个大数据培训组织,专门为公司招聘顶尖数据科学家并为公司职员培训最新的大数据科学技能。尽管 Spark 效率惊人,分布式工作负载的时间和成本亦然可以大到不能忽略不计。因此我们一直努力寻求更高效的技术,以便我们的学生能够学习到最好和最快的工具。
提交 Spark 任务到云
Spark 是一个类 MapReduce 但是比 MapReduce 更灵活、更抽象的并行计算框架。Spark 提供 Python 和 Java 编程接口,但它更愿意用户使用原生的 Scala 语言进行应用程序开发。Scala 可以把应用程序和依赖文件打包在一个 JAR 文件从而使 Spark 任务提交变得简单。
通常情况下,Sprark 结合 HDFS 应用于分布式数据存储,而与 YARN 协同工作则应用于集群管理;这种堪称完美的配合使得 Spark 非常适用于 AWS 的弹性 MapReduce (EMR)集群和 GCP 的 Dataproc 集群。这两种集群都已有 HDFS 和 YARN 预配置,不需要额外进行配置。
配置云服务
通过命令行比通过网页界面管理数据、集群和任务具有更高的可扩展性。对 AWS 而言,这意味着客户需要安装 CLI。客户必须获得证书并为每个 EC2 实例创建独立的密钥对。除此之外,客户还需要为 EMR 用户和 EMR 本身创建角色(基本权限),主要是准入许可规则,从而使 EMR 用户获得足够多的权限(通常在 CLI 运行 aws emr create-default-roles 就可以)。
相比而言,GCP 的处理流程更加直接。如果客户选择安装 Google Cloud SDK 并且使用其 Google 账号登录,那么客户即刻可以使用 GCP 的几乎所有功能而无需其他任何配置。唯一需要提醒的是不要忘记通过 API 管理器启用计算引擎、Dataproc 和云存储 JSON 的 API。
当你安装你的喜好设置好之后,有趣的事情就发生了!比如可以通过aws s3 cp或者gsutil cp命令拷贝客户的数据到云端。再比如客户可以创建自己的输入、输出或者任何其他需要的 bucket,如此,运行一个应用就像创建一个集群或者提交 JAR 文件一样简单。请确定日志存放的地方,毕竟在云环境下跟踪问题或者调试 bug 有点诡异。
一分钱一分货
谈及成本,Google 的服务在以下几个方面更有优势。首先,购买计算能力的原始成本更低。4 个 vCPU 和 15G RAM 的 Google 计算引擎服务(GCE)每小时只需 0.20 美元,如果运行 Dataproc,每小时也只需区区 0.24 美元。相比之下,同等的云配置,AWS EMR 则需要每小时 0.336 美元。
其次,计费方式。AWS 按小时计费,即使客户只使用 15 分钟也要付足 1 小时的费用。GCP 按分钟计费,最低计费 10 分钟。在诸多用户案例中,资费方式的不同直接导致成本的巨大差异。
两种云服务都有其他多种定价机制。客户可以使用 AWS 的 Sport Instance 或 GCP 的 Preemptible Instance 来竞价它们的空闲云计算能力。这些服务比专有的、按需服务便宜,缺点是不能保证随时有可用的云资源提供服务。在 GCP 上,如果客户长时间(每月的 25% 至 100%)使用服务,可以获取更多折扣。在 AWS 上预付费或者一次购买大批量服务可以节省不少费用。底线是,如果你是一个超级用户,并且使用云计算已经成为一种常态,那么最好深入研究云计算,自己算计好成本。
最后,新手在 GCP 上体验云服务的费用较低。新手只需 300 美元信用担保,就可以免费试用 60 天 GCP 提供的全部云服务。AWS 只免费提供特定服务的特定试用层级,如果运行 Spark 任务,需要付费。这意味着初次体验 Spark,GCP 具有更多选择,也少了精打细算和讨价还价的烦恼。
性能比拼
我们通过实验检测一个典型 Spark 工作负载的性能与开销。实验分别选择 AWS 的 m3.xlarg 和 GCP 的 n1-standard-4,它们都是由一个 Master 和 5 个核心实例组成的集群。除了规格略有差别,虚拟核心和费用都相同。实际上它们在 Spark 任务的执行时间上也表现的惊人相似。
测试 Spark 任务包括对数据的解析、过滤、合并和聚合,这些数据来自公开的 堆栈交换数据转储 。通过运行相同的 JAR,我们首先对大约 50M 的数据子集进行交叉验证,然后将验证扩大到大约 9.5G 的数据集。
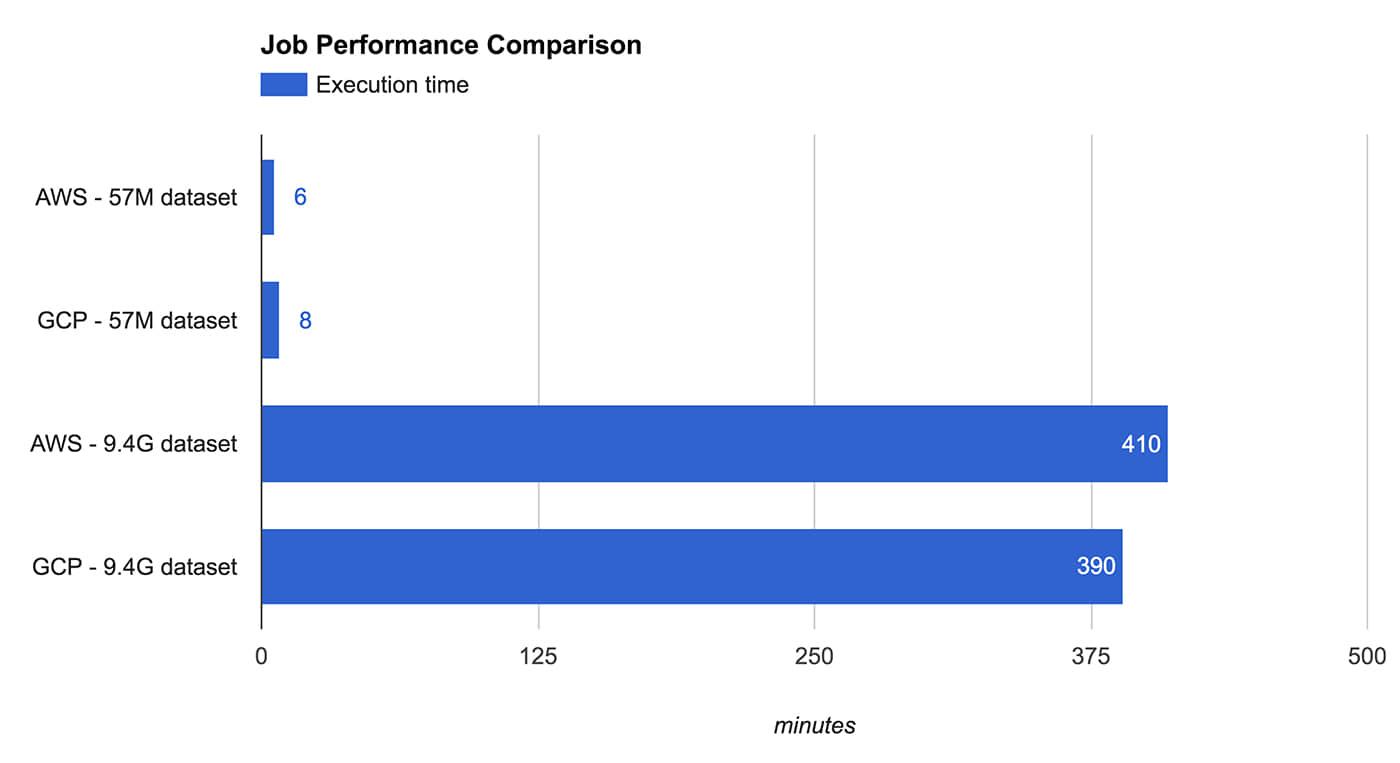
Figure 1. Credit: Michael Li and Ariel M'ndange-Pfupfu.
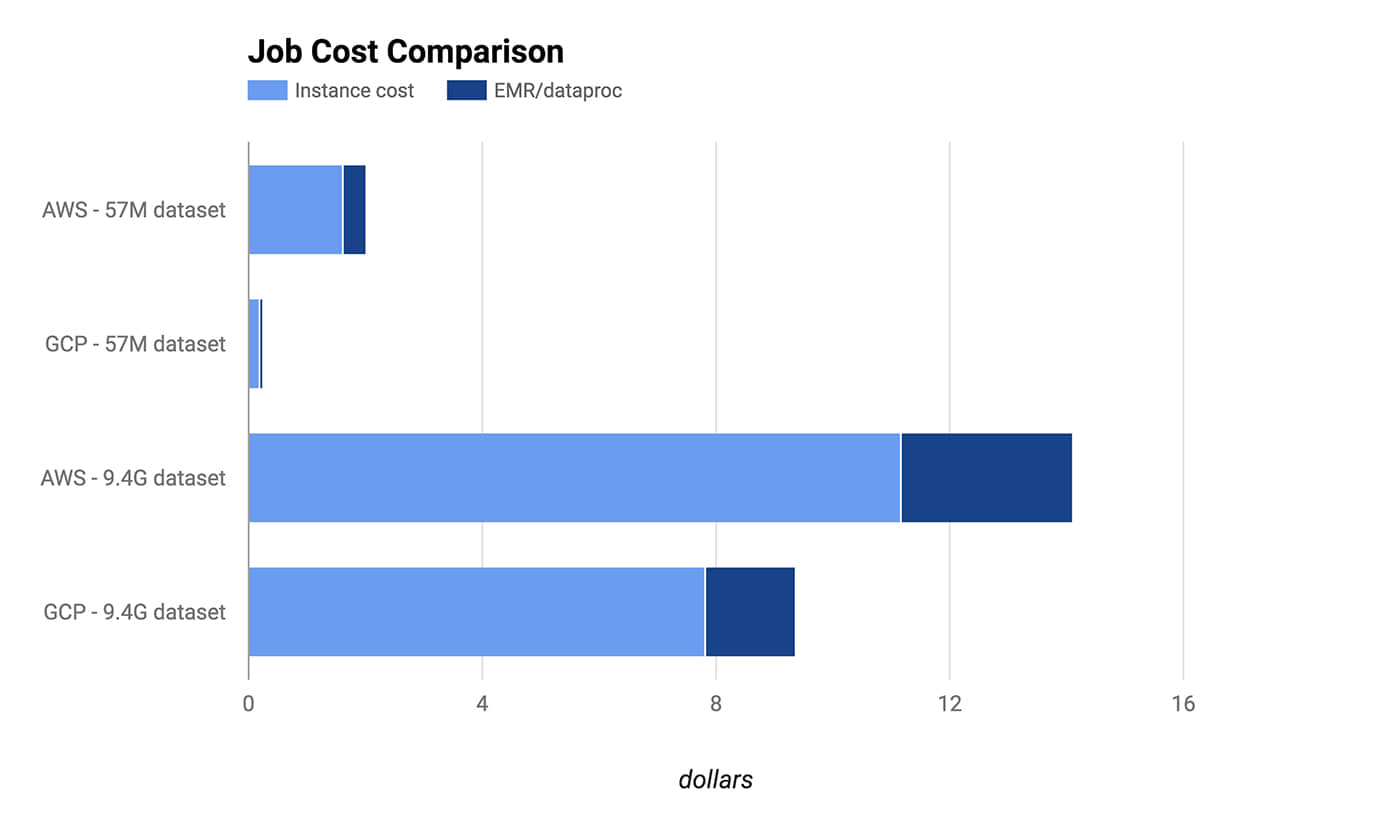
Figure 2. Credit: Michael Li and Ariel M'ndange-Pfupfu.
结果表明,短任务在 GCP 上具有明显的成本优势,这是因为 GCP 以分钟计费,并最终扣除了 10 分钟的费用,而 AWS 则收取了 1 小时的费用。但是即使长任务,因为计费方式占优,GPS 仍然具有相当优势。同样值得注意的是存储成本并不包括在此次比较当中。
结论
AWS 是云计算的先驱,这甚至体现在 API 中。AWS 拥有巨大的生态系统,但其许可模型已略显陈旧,配置管理也有些晦涩难解。相比之下,Google 是云计算领域的新星并且将云计算服务打造得更加圆润自如。但是 GCP 缺少一些便捷的功能,比如通过简单方法自动结束集群和详细的任务计费信息分解。另外,其 Python 编程接口也不像 AWS 的 Boto 那么全面。
如果你初次使用云计算,GCP 因其简单易用,别具魅力。即使你已在使用 AWS,你也许会发现迁移到 GCP 可能更划算,尽管真正从 AWS 迁移到 GCP 的代价可能得不偿失。
当然,现在对两种云服务作一个全面的总结还非常困难,因为它们都不是单一的实体,而是由多个实体整合而成的完整生态系统,并且各有利弊。真正的赢家是用户。一个例证就是在 数据孵化器 ,我们的博士数据科学研究员在学习分布式负载的过程中真正体会到成本的下降。虽然我们的大数据企业培训客户可能对价格不那么敏感,他们更在意能够更快速地处理企业数据,同时保持价格不增加。数据科学家现在可以享受大量的可选服务,这些都是从竞争激烈的云计算市场得到的实惠。
via: https://www.oreilly.com/ideas/spark-comparison-aws-vs-gcp
作者:Michael Li Ariel M'Ndange-Pfupfu 译者:firstadream 校对:wxy