
inix 是一个用于获取 Linux 系统信息的终端命令。能够获取软件和硬件的详细信息,比如计算机型号、内核版本、发行版号以及桌面环境等信息,甚至可以读取主存模块占用主板的哪块 RAM 卡槽等详细信息。
inxi 还可以用于监控系统中正在消耗 CPU 或者内存资源的进程。
在本文中,我将展示使用 inxi 命令获取系统信息的常用操作。
首先,我将展示下如何安装 inxi 命令。
在 Linux 上安装 inxi
inxi 是一个非常流行的工具,所以在大多数 Linux 发行版仓库中都可以轻松获取到该工具。不过还没有流行到各大 Linux 发行版默认就安装了该软件,所以需要我们自己安装一下。
在 Ubuntu/Debian 发行版系统中,安装命令:
sudo apt install inxi
在 Fedora/RHEL8-based 等发行版中,安装命令:
sudo dnf install -y epel-release
sudo dnf install -y inxi
在 Arch Linux 以及它的派生分支版本中,安装命令:
sudo pacman -S inxi
使用 inxi 获取系统信息
你可以在终端运行 inxi 命令来总体浏览下系统信息。
inxi
如下图所示,运行 inxi 命令可以简要浏览 CPU、时钟频率(speed/min/max)、内核(Kernel)、内存(Mem)、磁盘存储空间(Storage)、运行进程数量(Procs)以及 Shell 等信息。

使用 -b 参数可以获取更为详细的系统信息。-b 参数会读取更多有关 CPU、驱动器、当前运行进程、主板 UEFI 版本、GPU、显示分辨率以及网络设备等详细信息。
inxi -b

类似 -b 参数使用方法,inxi 还有许多其他的参数可供使用。你可以综合使用这些参数来获取你关心的信息。
让我们看几个实例。
获取音频设备信息
使用 -A 参数可以获取有关音频(输出)设备信息,包括物理音频(输出)设备、声音服务器以及音频驱动等详细信息。
inxi -A

获取电池信息
使用 -B 参数,可以获取有关电池的信息(如果安装了电池)。你将读取到例如以 Wh(瓦特小时)为单位的当前电池电量和状况。
因为我使用的是台式机,所以这里仅仅作为一个示例,让我们看看使用 inxi -B 会输出什么。
Battery: ID-1: BAT0 charge: 50.0 Wh (100.0%) condition: 50.0/50.0
获取 CPU 信息
-C 参数用于获取有关 CPU 的详细信息。比如包括 CPU 缓存大小、频率(单位 MHz,如果有多核,会显示每个核心的频率)、核心数、CPU 型号以及 CPU 是 32 位还是 64 位。
inxi -C

注意,如果是在虚拟机中使用 inix -C,inxi 读取到的 CPU 的最大和最小频率可能异常。下面是一个在四核 Debian 11 虚拟机中使用 -C 参数的示例输出。

获取更多的系统信息
使用 -F 参数可以获取更详细的系统信息(类似 -b 参数,但会更为详细)。几乎囊括了所有层次的系统信息。
inxi -F
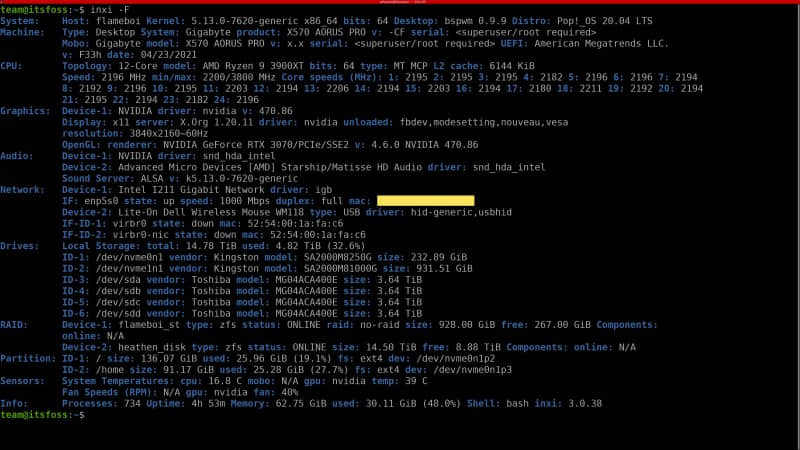
获取图形显示相关信息
-G 参数可以获取和图形相关的信息。
它会显示所有的图形设备(GPU)、正在使用的 GPU 驱动(有助于检查是否使用 Nvidia 驱动还是 nouveau 驱动)、显示输出分辨率和驱动程序版本。
inxi -G

获取运行进程信息
-I 参数(大写字母 i)显示正在运行的进程、当前 shell 、内存(内存使用情况)以及 inxi 版本号等信息。

获取内存信息
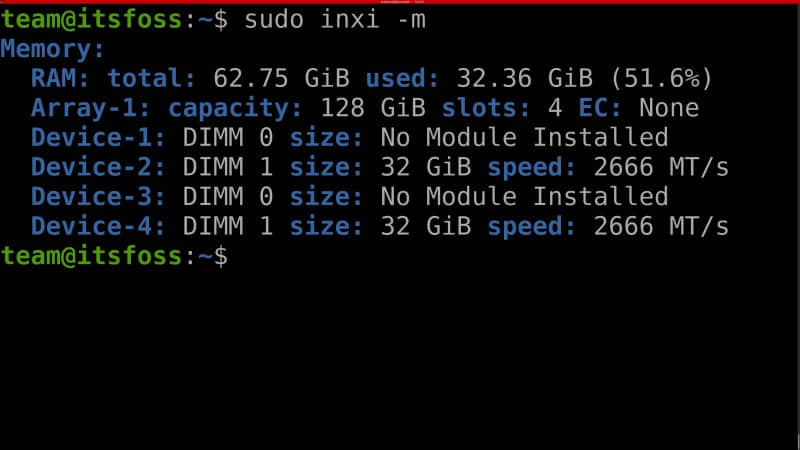
可能你已经猜到了,-m 参数可以获取与内存相关的信息。
它读取了如总可用内存、最大内存容量(硬件或 CPU 支持的)、主板物理内存插槽数、是否存在 ECC、插入的内存插槽,以及枚举每个插槽中运行的内存模块的大小和运行速度等信息。
inxi -m
要使用 -m 参数获取更详细的信息,例如最大容量、每个插槽的内存模块信息等,需要超级用户权限。
sudo inxi -m
如果只是希望简短的输出内存信息,可以使用 -memory-short 参数。
使用 -memroy-short 参数将会只显示总内存以及当前已使用的内存量。
查看正在使用的包存储库
当使用 -r 参数时,会列举当前正在使用的包管理仓库或者更新本地仓库缓存中的所有存储库列表。

获取 RAID 设备信息
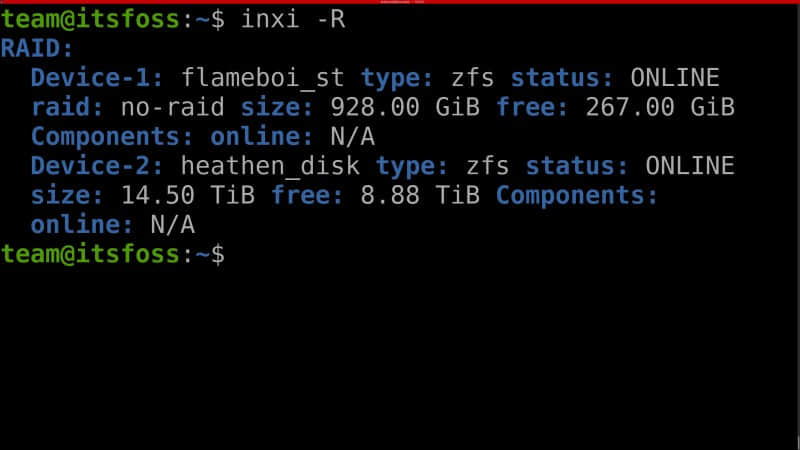
-R 参数用于获取所有 RAID 设备相关信息。
令人惊喜的是,它甚至显示了有关 ZFS RAID(默认情况下,多数 Linux 系统不包含该文件系统)的信息。它显示了 RAID 设备上文件系统的详细信息、状态(包含离线状态、总大小和可用大小等)。
inxi -R
在 Linux 终端中查询天气(对,这是可以的)
利用 -W 参数,你可以查询地球上任何地方的天气情况。
-W 参数后面,需要携带以下中的任一一个体现位置的信息
- 邮政编码
- 纬度
- 城市(及州)、国家(不能含有空格,使用 “+” 替换空格)
inxi -W Baroda,India

监控系统资源使用情况
inxi 除了提供有关已安装的硬件和驱动的信息外,还可以用于资源监控。
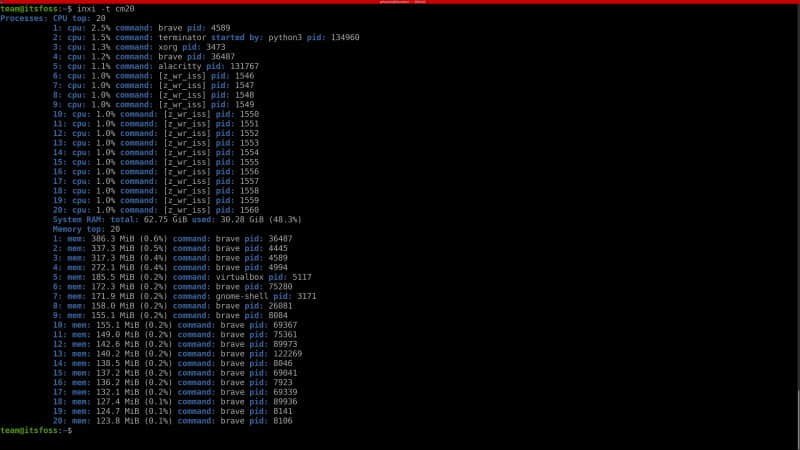
使用 -t 参数可以显示进程信息。你还可以可选项 -c (用于 CPU)和 -m(用于内存)。这些选项结合使用可以按指定数量列出进程信息。
下面是一些使用 -t 参数监控资源信息的示例。
inxi -t
命令 inxi -t 默认效果等同于 inxi -t cm5 的效果。

inxi -t cm10
偶尔需要监控资源使用情况时,该工具挺管用。如果需要更多的资源监控功能,则推荐使用 专用系统资源监控工具。
总结
对于需要诊断计算机问题以及获取那些并不熟悉的软硬件信息的人来说,inxi 工具是十分便利且有用的。它能识别那些消耗 CPU、内存的进程;可以检查是否安装了合适的图形驱动程序、主板 UEFI/BIOS 是否需要更新等等。
事实上,在 inxi 开源社区论坛上,我们要求那些寻求帮助的成员提供 inxi 命令输出内容以便判断他们当前正在使用什么样的系统环境。
我知道也有其他的工具可以读取 Linux 上的硬件信息,不过 inxi 同时能读取硬件和软件信息,这也是我喜欢它的地方所在。
你使用 inxi 或者其他工具么?欢迎在评论区留言分享交流。
via: https://itsfoss.com/inxi-system-info-linux/
作者:Pratham Patel 选题:lujun9972 译者:jrglinux 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出



















