怎样用 Bash 编程:语法和工具
让我们通过本系列文章来学习基本的 Bash 编程语法和工具,以及如何使用变量和控制运算符,这是三篇中的第一篇。

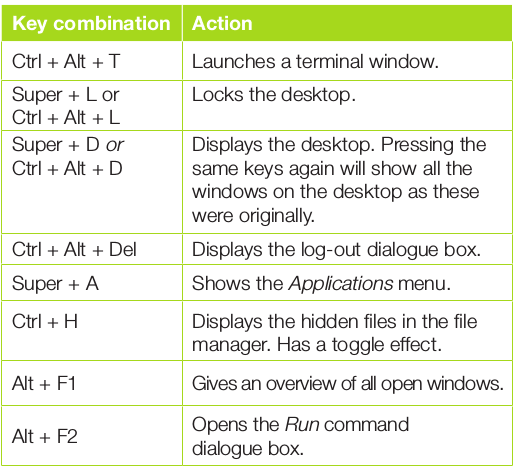
Shell 是操作系统的命令解释器,其中 Bash 是我最喜欢的。每当用户或者系统管理员将命令输入系统的时候,Linux 的 shell 解释器就会把这些命令转换成操作系统可以理解的形式。而执行结果返回 shell 程序后,它会将结果输出到 STDOUT(标准输出),默认情况下,这些结果会显示在你的终端。所有我熟悉的 shell 同时也是一门编程语言。
Bash 是个功能强大的 shell,包含众多便捷特性,比如:tab 补全、命令回溯和再编辑、别名等。它的命令行默认编辑模式是 Emacs,但是我最喜欢的 Bash 特性之一是我可以将其更改为 Vi 模式,以使用那些储存在我肌肉记忆中的的编辑命令。
然而,如果你把 Bash 当作单纯的 shell 来用,则无法体验它的真实能力。我在设计一套包含三卷的 Linux 自学课程时(这个系列的文章正是基于此课程),了解到许多 Bash 的知识,这些是我在过去 20 年的 Linux 工作经验中所没有掌握的,其中的一些知识就是关于 Bash 的编程用法。不得不说,Bash 是一门强大的编程语言,是一个能够同时用于命令行和 shell 脚本的完美设计。
本系列文章将要探讨如何使用 Bash 作为命令行界面(CLI)编程语言。第一篇文章简单介绍 Bash 命令行编程、变量以及控制运算符。其他文章会讨论诸如:Bash 文件的类型;字符串、数字和一些逻辑运算符,它们能够提供代码执行流程中的逻辑控制;不同类型的 shell 扩展;通过 for、while 和 until 来控制循环操作。
Shell
Bash 是 Bourne Again Shell 的缩写,因为 Bash shell 是 基于 更早的 Bourne shell,后者是 Steven Bourne 在 1977 年开发的。另外还有很多其他的 shell 可以使用,但下面四个是我经常见到的:
csh:C shell 适合那些习惯了 C 语言语法的开发者。ksh:Korn shell,由 David Korn 开发,在 Unix 用户中更流行。tcsh:一个 csh 的变种,增加了一些易用性。zsh:Z shell,集成了许多其他流行 shell 的特性。
所有 shell 都有内置命令,用以补充或替代核心工具集。打开 shell 的 man 说明页,找到“BUILT-INS”那一段,可以查看都有哪些内置命令。
每种 shell 都有它自己的特性和语法风格。我用过 csh、ksh 和 zsh,但我还是更喜欢 Bash。你可以多试几个,寻找更适合你的 shell,尽管这可能需要花些功夫。但幸运的是,切换不同 shell 很简单。
所有这些 shell 既是编程语言又是命令解释器。下面我们来快速浏览一下 Bash 中集成的编程结构和工具。
作为编程语言的 Bash
大多数场景下,系统管理员都会使用 Bash 来发送简单明了的命令。但 Bash 不仅可以输入单条命令,很多系统管理员可以编写简单的命令行程序来执行一系列任务,这些程序可以作为通用工具,能节省时间和精力。
编写 CLI 程序的目的是要提高效率(做一个“懒惰的”系统管理员)。在 CLI 程序中,你可以用特定顺序列出若干命令,逐条执行。这样你就不用盯着显示屏,等待一条命令执行完,再输入另一条,省下来的时间就可以去做其他事情了。
什么是“程序”?
自由在线计算机词典(FOLDOC)对于程序的定义是:“由计算机执行的指令,而不是运行它们的物理硬件。”普林斯顿大学的 WordNet 将程序定义为:“……计算机可以理解并执行的一系列指令……”维基百科上也有一条不错的关于计算机程序的条目。
总结下,程序由一条或多条指令组成,目的是完成一个具体的相关任务。对于系统管理员而言,一段程序通常由一系列的 shell 命令构成。Linux 下所有的 shell (至少我所熟知的)都有基本的编程功能,Bash 作为大多数 linux 发行版的默认 shell,也不例外。
本系列用 Bash 举例(因为它无处不在),假如你使用一个不同的 shell 也没关系,尽管结构和语法有所不同,但编程思想是相通的。有些 shell 支持某种特性而其他 shell 则不支持,但它们都提供编程功能。Shell 程序可以被存在一个文件中被反复使用,或者在需要的时候才创建它们。
简单 CLI 程序
最简单的命令行程序只有一或两条语句,它们可能相关,也可能无关,在按回车键之前被输入到命令行。程序中的第二条语句(如果有的话)可能取决于第一条语句的操作,但也不是必须的。
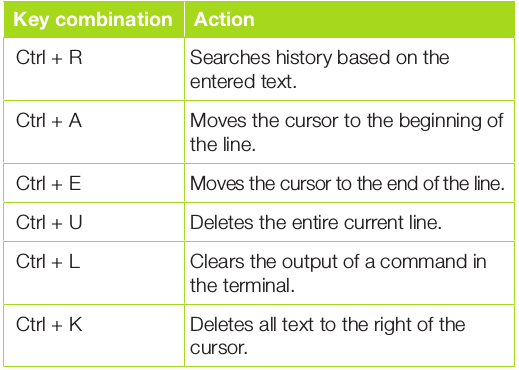
这里需要特别讲解一个标点符号。当你在命令行输入一条命令,按下回车键的时候,其实在命令的末尾有一个隐含的分号(;)。当一段 CLI shell 程序在命令行中被串起来作为单行指令使用时,必须使用分号来终结每个语句并将其与下一条语句分开。但 CLI shell 程序中的最后一条语句可以使用显式或隐式的分号。
一些基本语法
下面的例子会阐明这一语法规则。这段程序由单条命令组成,还有一个显式的终止符:
[student@studentvm1 ~]$ echo "Hello world." ;
Hello world.看起来不像一个程序,但它确是我学习每个新编程语言时写下的第一个程序。不同语言可能语法不同,但输出结果是一样的。
让我们扩展一下这段微不足道却又无所不在的代码。你的结果可能与我的有所不同,因为我的家目录有点乱,而你可能是在 GUI 桌面中第一次登录账号。
[student@studentvm1 ~]$ echo "My home directory." ; ls ;
My home directory.
chapter25 TestFile1.Linux dmesg2.txt Downloads newfile.txt softlink1 testdir6
chapter26 TestFile1.mac dmesg3.txt file005 Pictures Templates testdir
TestFile1 Desktop dmesg.txt link3 Public testdir Videos
TestFile1.dos dmesg1.txt Documents Music random.txt testdir1现在是不是更明显了。结果是相关的,但是两条语句彼此独立。你可能注意到我喜欢在分号前后多输入一个空格,这样会让代码的可读性更好。让我们再运行一遍这段程序,这次不要带结尾的分号:
[student@studentvm1 ~]$ echo "My home directory." ; ls输出结果没有区别。
关于变量
像所有其他编程语言一样,Bash 支持变量。变量是个象征性的名字,它指向内存中的某个位置,那里存着对应的值。变量的值是可以改变的,所以它叫“变~量”。
Bash 不像 C 之类的语言,需要强制指定变量类型,比如:整型、浮点型或字符型。在 Bash 中,所有变量都是字符串。整数型的变量可以被用于整数运算,这是 Bash 唯一能够处理的数学类型。更复杂的运算则需要借助 bc 这样的命令,可以被用在命令行编程或者脚本中。
变量的值是被预先分配好的,这些值可以用在命令行编程或者脚本中。可以通过变量名字给其赋值,但是不能使用 $ 符开头。比如,VAR=10 这样会把 VAR 的值设为 10。要打印变量的值,你可以使用语句 echo $VAR。变量名必须以文本(即非数字)开始。
Bash 会保存已经定义好的变量,直到它们被取消掉。
下面这个例子,在变量被赋值前,它的值是空(null)。然后给它赋值并打印出来,检验一下。你可以在同一行 CLI 程序里完成它:
[student@studentvm1 ~]$ echo $MyVar ; MyVar="Hello World" ; echo $MyVar ;
Hello World
[student@studentvm1 ~]$注意:变量赋值的语法非常严格,等号(=)两边不能有空格。
那个空行表明了 MyVar 的初始值为空。变量的赋值和改值方法都一样,这个例子展示了原始值和新的值。
正如之前说的,Bash 支持整数运算,当你想计算一个数组中的某个元素的位置,或者做些简单的算术运算,这还是挺有帮助的。然而,这种方法并不适合科学计算,或是某些需要小数运算的场景,比如财务统计。这些场景有其它更好的工具可以应对。
下面是个简单的算术题:
[student@studentvm1 ~]$ Var1="7" ; Var2="9" ; echo "Result = $((Var1*Var2))"
Result = 63好像没啥问题,但如果运算结果是浮点数会发生什么呢?
[student@studentvm1 ~]$ Var1="7" ; Var2="9" ; echo "Result = $((Var1/Var2))"
Result = 0
[student@studentvm1 ~]$ Var1="7" ; Var2="9" ; echo "Result = $((Var2/Var1))"
Result = 1
[student@studentvm1 ~]$结果会被取整。请注意运算被包含在 echo 语句之中,其实计算在 echo 命令结束前就已经完成了,原因是 Bash 的内部优先级。想要了解详情的话,可以在 Bash 的 man 页面中搜索 “precedence”。
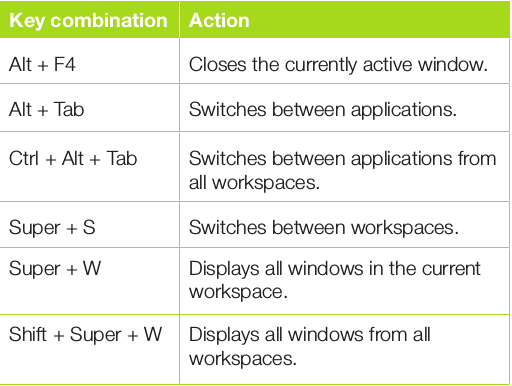
控制运算符
Shell 的控制运算符是一种语法运算符,可以轻松地创建一些有趣的命令行程序。在命令行上按顺序将几个命令串在一起,就变成了最简单的 CLI 程序:
command1 ; command2 ; command3 ; command4 ; . . . ; etc. ;只要不出错,这些命令都能顺利执行。但假如出错了怎么办?你可以预设好应对出错的办法,这就要用到 Bash 内置的控制运算符, && 和 ||。这两种运算符提供了流程控制功能,使你能改变代码执行的顺序。分号也可以被看做是一种 Bash 运算符,预示着新一行的开始。
&& 运算符提供了如下简单逻辑,“如果 command1 执行成功,那么接着执行 command2。如果 command1 失败,就跳过 command2。”语法如下:
command1 && command2现在,让我们用命令来创建一个新的目录,如果成功的话,就把它切换为当前目录。确保你的家目录(~)是当前目录,先尝试在 /root 目录下创建,你应该没有权限:
[student@studentvm1 ~]$ Dir=/root/testdir ; mkdir $Dir/ && cd $Dir
mkdir: cannot create directory '/root/testdir/': Permission denied
[student@studentvm1 ~]$上面的报错信息是由 mkdir 命令抛出的,因为创建目录失败了。&& 运算符收到了非零的返回码,所以 cd 命令就被跳过,前者阻止后者继续运行,因为创建目录失败了。这种控制流程可以阻止后面的错误累积,避免引发更严重的问题。是时候讲点更复杂的逻辑了。
当一段程序的返回码大于零时,使用 || 运算符可以让你在后面接着执行另一段程序。简单语法如下:
command1 || command2解读一下,“假如 command1 失败,执行 command2”。隐藏的逻辑是,如果 command1 成功,跳过 command2。下面实践一下,仍然是创建新目录:
[student@studentvm1 ~]$ Dir=/root/testdir ; mkdir $Dir || echo "$Dir was not created."
mkdir: cannot create directory '/root/testdir': Permission denied
/root/testdir was not created.
[student@studentvm1 ~]$正如预期,因为目录无法创建,第一条命令失败了,于是第二条命令被执行。
把 && 和 || 两种运算符结合起来才能发挥它们的最大功效。请看下面例子中的流程控制方法:
前置 commands ; command1 && command2 || command3 ; 跟随 commands语法解释:“假如 command1 退出时返回码为零,就执行 command2,否则执行 command3。”用具体代码试试:
[student@studentvm1 ~]$ Dir=/root/testdir ; mkdir $Dir && cd $Dir || echo "$Dir was not created."
mkdir: cannot create directory '/root/testdir': Permission denied
/root/testdir was not created.
[student@studentvm1 ~]$现在我们再试一次,用你的家目录替换 /root 目录,你将会有权限创建这个目录了:
[student@studentvm1 ~]$ Dir=~/testdir ; mkdir $Dir && cd $Dir || echo "$Dir was not created."
[student@studentvm1 testdir]$像 command1 && command2 这样的控制语句能够运行的原因是,每条命令执行完毕时都会给 shell 发送一个返回码,用来表示它执行成功与否。默认情况下,返回码为 0 表示成功,其他任何正值表示失败。一些系统管理员使用的工具用值为 1 的返回码来表示失败,但其他很多程序使用别的数字来表示失败。
Bash 的内置变量 $? 可以显示上一条命令的返回码,可以在脚本或者命令行中非常方便地检查它。要查看返回码,让我们从运行一条简单的命令开始,返回码的结果总是上一条命令给出的。
[student@studentvm1 testdir]$ ll ; echo "RC = $?"
total 1264
drwxrwxr-x 2 student student 4096 Mar 2 08:21 chapter25
drwxrwxr-x 2 student student 4096 Mar 21 15:27 chapter26
-rwxr-xr-x 1 student student 92 Mar 20 15:53 TestFile1
drwxrwxr-x. 2 student student 663552 Feb 21 14:12 testdir
drwxr-xr-x. 2 student student 4096 Dec 22 13:15 Videos
RC = 0
[student@studentvm1 testdir]$在这个例子中,返回码为零,意味着命令执行成功了。现在对 root 的家目录测试一下,你应该没有权限:
[student@studentvm1 testdir]$ ll /root ; echo "RC = $?"
ls: cannot open directory '/root': Permission denied
RC = 2
[student@studentvm1 testdir]$本例中返回码是 2,表明非 root 用户没有权限进入这个目录。你可以利用这些返回码,用控制运算符来改变程序执行的顺序。
总结
本文将 Bash 看作一门编程语言,并从这个视角介绍了它的简单语法和基础工具。我们学习了如何将数据输出到 STDOUT,怎样使用变量和控制运算符。在本系列的下一篇文章中,将会重点介绍能够控制指令执行流程的逻辑运算符。
via: https://opensource.com/article/19/10/programming-bash-part-1
作者:David Both 选题:lujun9972 译者:jdh8383 校对:wxy