本文介绍如何构建一个基于 Grails 的数据浏览器来可视化复杂的表格数据。

我是 Grails 的忠实粉丝。当然,我主要是热衷于利用命令行工具来探索和分析数据的数据从业人员。数据从业人员经常需要查看数据,这也意味着他们通常拥有优秀的数据浏览器。利用 Grails、jQuery,以及 DataTables jQuery 插件,我们可以制作出非常友好的表格数据浏览器。
DataTables 网站提供了许多“食谱式”的教程文档,展示了如何组合一些优秀的示例应用程序,这些程序包含了完成一些非常漂亮的东西所必要的 JavaScript、HTML,以及偶尔出现的 PHP。但对于那些宁愿使用 Grails 作为后端的人来说,有必要进行一些说明示教。此外,样本程序中使用的数据是一个虚构公司的员工的单个平面表格数据,因此处理这些复杂的表关系可以作为读者的一个练习项目。
本文中,我们将创建具有略微复杂的数据结构和 DataTables 浏览器的 Grails 应用程序。我们将介绍 Grails 标准,它是 Groovy 式的 Java Hibernate 标准。我已将代码托管在 GitHub 上方便大家访问,因此本文主要是对代码细节的解读。
首先,你需要配置 Java、Groovy、Grails 的使用环境。对于 Grails,我倾向于使用终端窗口和 Vim,本文也使用它们。为获得现代的 Java 环境,建议下载并安装 Linux 发行版提供的 Open Java Development Kit (OpenJDK)(应该是 Java 8、9、10 或 11 之一,撰写本文时,我正在使用 Java 8)。从我的角度来看,获取最新的 Groovy 和 Grails 的最佳方法是使用 SDKMAN!。
从未尝试过 Grails 的读者可能需要做一些背景资料阅读。作为初学者,推荐文章 创建你的第一个 Grails 应用程序。
获取员工信息浏览器应用程序
正如上文所提,我将本文中员工信息浏览器的源代码托管在 GitHub上。进一步讲,应用程序 embrow 是在 Linux 终端中用如下命令构建的:
cd Projects
grails create-app com.nuevaconsulting.embrow
域类和单元测试创建如下:
grails create-domain-class com.nuevaconsulting.embrow.Position
grails create-domain-class com.nuevaconsulting.embrow.Office
grails create-domain-class com.nuevaconsulting.embrow.Employeecd embrowgrails createdomaincom.grails createdomaincom.grails createdomaincom.
这种方式构建的域类没有属性,因此必须按如下方式编辑它们:
Position 域类:
package com.nuevaconsulting.embrow
class Position {
String name
int starting
static constraints = {
name nullable: false, blank: false
starting nullable: false
}
}com.Stringint startingstatic constraintsnullableblankstarting nullable
Office 域类:
package com.nuevaconsulting.embrow
class Office {
String name
String address
String city
String country
static constraints = {
name nullable: false, blank: false
address nullable: false, blank: false
city nullable: false, blank: false
country nullable: false, blank: false
}
}
Enployee 域类:
package com.nuevaconsulting.embrow
class Employee {
String surname
String givenNames
Position position
Office office
int extension
Date hired
int salary
static constraints = {
surname nullable: false, blank: false
givenNames nullable: false, blank: false
: false
office nullable: false
extension nullable: false
hired nullable: false
salary nullable: false
}
}
请注意,虽然 Position 和 Office 域类使用了预定义的 Groovy 类型 String 以及 int,但 Employee 域类定义了 Position 和 Office 字段(以及预定义的 Date)。这会导致创建数据库表,其中存储的 Employee 实例中包含了指向存储 Position 和 Office 实例表的引用或者外键。
现在你可以生成控制器,视图,以及其他各种测试组件:
-all com.nuevaconsulting.embrow.Position
grails generate-all com.nuevaconsulting.embrow.Office
grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.grails generateall com.grails generateall com.
此时,你已经准备好了一个基本的增删改查(CRUD)应用程序。我在 grails-app/init/com/nuevaconsulting/BootStrap.groovy 中包含了一些基础数据来填充表格。
如果你用如下命令来启动应用程序:
grails run-app
在浏览器输入 http://localhost:8080/,你将会看到如下界面:

Embrow 应用程序主界面。
单击 “OfficeController” 链接,会跳转到如下界面:

Office 列表
注意,此表由 OfficeController 的 index 方式生成,并由视图 office/index.gsp 显示。
同样,单击 “EmployeeController” 链接 跳转到如下界面:

employee 控制器
好吧,这很丑陋: Position 和 Office 链接是什么?
上面的命令 generate-all 生成的视图创建了一个叫 index.gsp 的文件,它使用 Grails <f:table/> 标签,该标签默认会显示类名(com.nuevaconsulting.embrow.Position)和持久化示例标识符(30)。这个操作可以自定义用来产生更好看的东西,并且自动生成链接,自动生成分页以及自动生成可排序列的一些非常简洁直观的东西。
但该员工信息浏览器功能也是有限的。例如,如果想查找 “position” 信息中包含 “dev” 的员工该怎么办?如果要组合排序,以姓氏为主排序关键字,“office” 为辅助排序关键字,该怎么办?或者,你需要将已排序的数据导出到电子表格或 PDF 文档以便通过电子邮件发送给无法访问浏览器的人,该怎么办?
jQuery DataTables 插件提供了这些所需的功能。允许你创建一个完成的表格数据浏览器。
创建员工信息浏览器视图和控制器的方法
要基于 jQuery DataTables 创建员工信息浏览器,你必须先完成以下两个任务:
- 创建 Grails 视图,其中包含启用 DataTable 所需的 HTML 和 JavaScript
- 给 Grails 控制器增加一个方法来控制新视图。
员工信息浏览器视图
在目录 embrow/grails-app/views/employee 中,首先复制 index.gsp 文件,重命名为 browser.gsp:
cd Projects
cd embrow/grails-app/views/employee
cp gsp browser.gsp
此刻,你自定义新的 browser.gsp 文件来添加相关的 jQuery DataTables 代码。
通常,在可能的时候,我喜欢从内容提供商处获得 JavaScript 和 CSS;在下面这行后面:
<title><g:message code="default.list.label" args="[entityName]" /></title>
插入如下代码:
<script src="https://code.jquery.com/jquery-2.2.4.min.js" integrity="sha256-BbhdlvQf/xTY9gja0Dq3HiwQF8LaCRTXxZKRutelT44=" crossorigin="anonymous"></script>
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/1.10.16/css/jquery.dataTables.css">
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/1.10.16/js/jquery.dataTables.js"></script>
<link rel="stylesheet" type="text/css" href="https://cdn.datatables.net/scroller/1.4.4/css/scroller.dataTables.min.css">
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/scroller/1.4.4/js/dataTables.scroller.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/dataTables.buttons.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.flash.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/jszip/3.1.3/jszip.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/pdfmake.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdnjs.cloudflare.com/ajax/libs/pdfmake/0.1.32/vfs_fonts.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.html5.min.js"></script>
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.print.min.js "></script>
然后删除 index.gsp 中提供数据分页的代码:
<div id="list-employee" class="content scaffold-list" role="main">
<h1><g:message code="default.list.label" args="[entityName]" /></h1>
<g:if test="${flash.message}">
<div class="message" role="status">${flash.message}</div>
</g:if>
<f:table collection="${employeeList}" />
<div class="pagination">
<g:paginate total="${employeeCount ?: 0}" />
</div>
</div>
并插入实现 jQuery DataTables 的代码。
要插入的第一部分是 HTML,它将创建浏览器的基本表格结构。DataTables 与后端通信的应用程序来说,它们只提供表格页眉和页脚;DataTables JavaScript 则负责表中内容。
<div id="employee-browser" class="content" role="main">
<h1>Employee Browser</h1>
<table id="employee_dt" class="display compact" style="width:99%;">
<thead>
<tr>
<th>Surname</th>
<th>Given name(s)</th>
<th>Position</th>
<th>Office</th>
<th>Extension</th>
<th>Hired</th>
<th>Salary</th>
</tr>
</thead>
<tfoot>
<tr>
<th>Surname</th>
<th>Given name(s)</th>
<th>Position</th>
<th>Office</th>
<th>Extension</th>
<th>Hired</th>
<th>Salary</th>
</tr>
</tfoot>
</table>
</div>
接下来,插入一个 JavaScript 块,它主要提供三个功能:它设置页脚中显示的文本框的大小,以进行列过滤,建立 DataTables 表模型,并创建一个处理程序来进行列过滤。
<g:javascript>
$('#employee_dt tfoot th').each( function() {javascript
下面的代码处理表格列底部的过滤器框的大小:
var title = $(this).text();
if (title == 'Extension' || title == 'Hired')
$(this).html('<input type="text" size="5" placeholder="' + title + '?" />');
else
$(this).html('<input type="text" size="15" placeholder="' + title + '?" />');
});titletitletitletitletitle
接下来,定义表模型。这是提供所有表选项的地方,包括界面的滚动,而不是分页,根据 DOM 字符串提供的装饰,将数据导出为 CSV 和其他格式的能力,以及建立与服务器的 AJAX 连接。 请注意,使用 Groovy GString 调用 Grails createLink() 的方法创建 URL,在 EmployeeController 中指向 browserLister 操作。同样有趣的是表格列的定义。此信息将发送到后端,后端查询数据库并返回相应的记录。
var table = $('#employee_dt').DataTable( {
"scrollY": 500,
"deferRender": true,
"scroller": true,
"dom": "Brtip",
"buttons": [ 'copy', 'csv', 'excel', 'pdf', 'print' ],
"processing": true,
"serverSide": true,
"ajax": {
"url": "${createLink(controller: 'employee', action: 'browserLister')}",
"type": "POST",
},
"columns": [
{ "data": "surname" },
{ "data": "givenNames" },
{ "data": "position" },
{ "data": "office" },
{ "data": "extension" },
{ "data": "hired" },
{ "data": "salary" }
]
});
最后,监视过滤器列以进行更改,并使用它们来应用过滤器。
table.columns().every(function() {
var that = this;
$('input', this.footer()).on('keyup change', function(e) {
if (that.search() != this.value && 8 < e.keyCode && e.keyCode < 32)
that.search(this.value).draw();
});
这就是 JavaScript,这样就完成了对视图代码的更改。
});
</g:javascript>
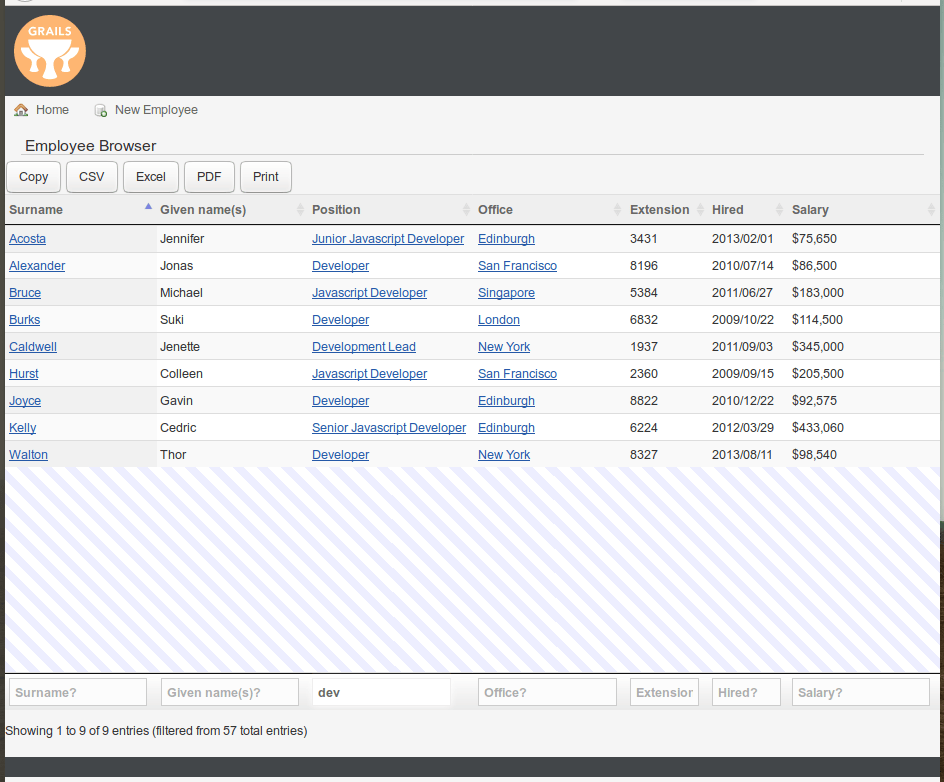
以下是此视图创建的UI的屏幕截图:
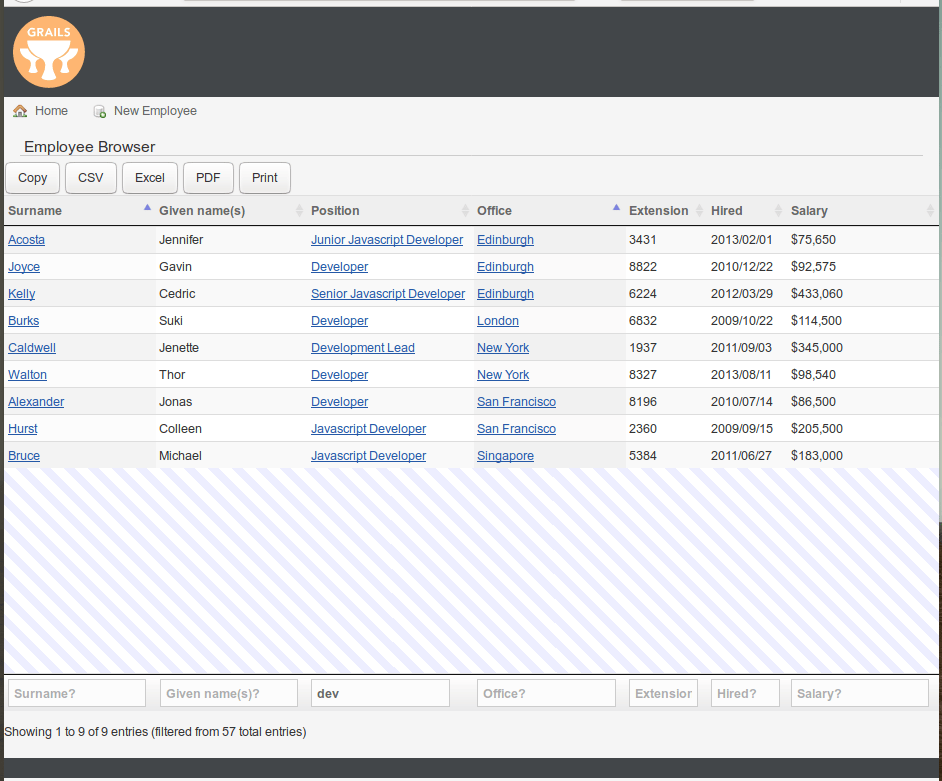
这是另一个屏幕截图,显示了过滤和多列排序(寻找 “position” 包括字符 “dev” 的员工,先按 “office” 排序,然后按姓氏排序):
这是另一个屏幕截图,显示单击 CSV 按钮时会发生什么:
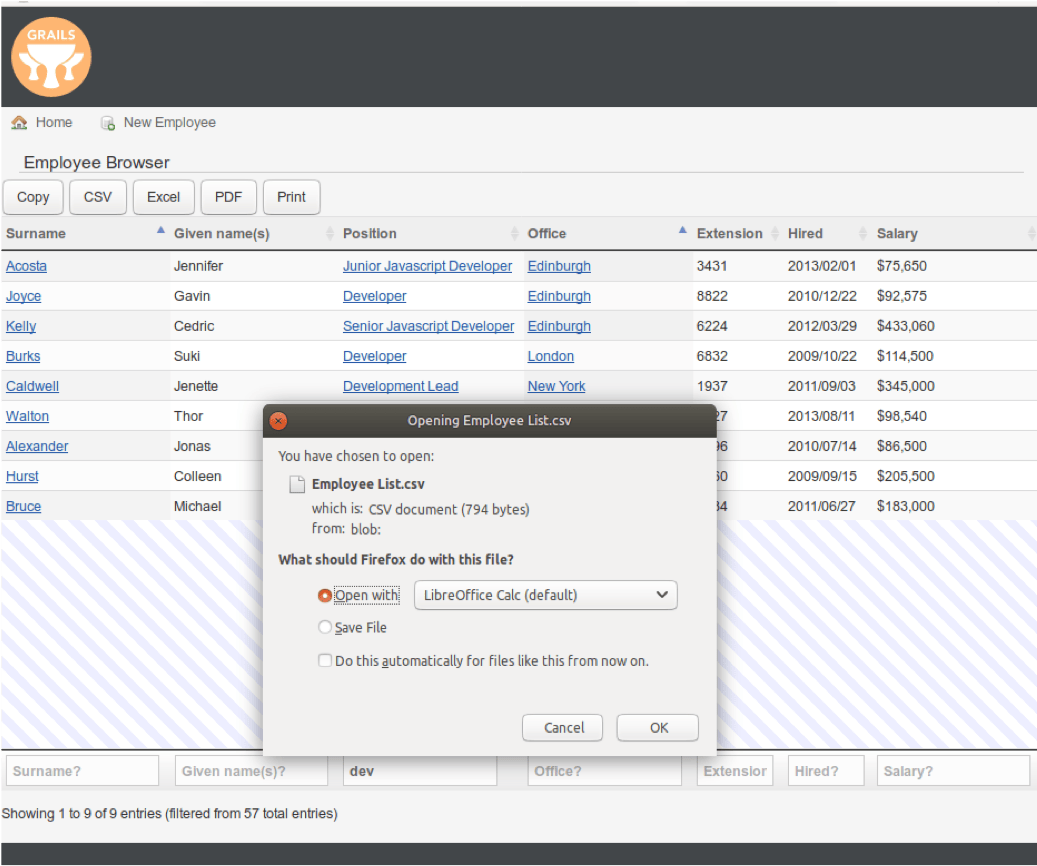
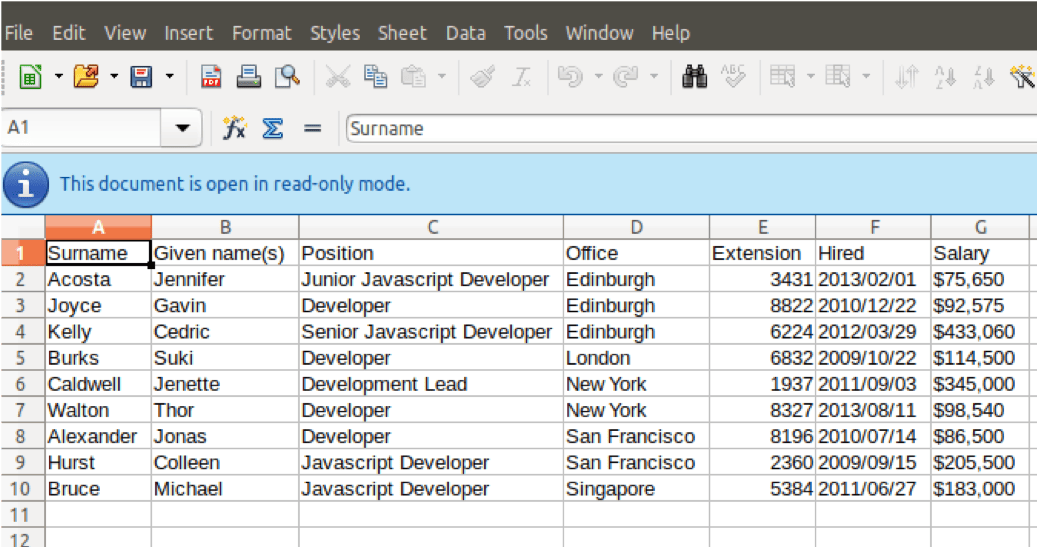
最后,这是一个截图,显示在 LibreOffice 中打开的 CSV 数据:
好的,视图部分看起来非常简单;因此,控制器必须做所有繁重的工作,对吧? 让我们来看看……
控制器 browserLister 操作
回想一下,我们看到过这个字符串:
"${createLink(controller: 'employee', action: 'browserLister')}"
对于从 DataTables 模型中调用 AJAX 的 URL,是在 Grails 服务器上动态创建 HTML 链接,其 Grails 标记背后通过调用 createLink() 的方法实现的。这会最终产生一个指向 EmployeeController 的链接,位于:
embrow/grails-app/controllers/com/nuevaconsulting/embrow/EmployeeController.groovy
特别是控制器方法 browserLister()。我在代码中留了一些 print 语句,以便在运行时能够在终端看到中间结果。
def browserLister() {
// Applies filters and sorting to return a list of desired employees
首先,打印出传递给 browserLister() 的参数。我通常使用此代码开始构建控制器方法,以便我完全清楚我的控制器正在接收什么。
println "employee browserLister params $params"
println()
接下来,处理这些参数以使它们更加有用。首先,jQuery DataTables 参数,一个名为 jqdtParams 的 Groovy 映射:
def jqdtParams = [:]
params.each { key, value ->
def keyFields = key.replace(']','').split(/\[/)
def table = jqdtParams
for (int f = 0; f < keyFields.size() - 1; f++) {
def keyField = keyFields[f]
if (!table.containsKey(keyField))
table[keyField] = [:]
table = table[keyField]
}
table[keyFields[-1]] = value
}
println "employee dataTableParams $jqdtParams"
println()
接下来,列数据,一个名为 columnMap 的 Groovy 映射:
def columnMap = jqdtParams.columns.collectEntries { k, v ->
def whereTerm = null
switch (v.data) {
case 'extension':
case 'hired':
case 'salary':
if (v.search.value ==~ /\d+(,\d+)*/)
whereTerm = v.search.value.split(',').collect { it as Integer }
break
default:
if (v.search.value ==~ /[A-Za-z0-9 ]+/)
whereTerm = "%${v.search.value}%" as String
break
}
[(v.data): [where: whereTerm]]
}
println "employee columnMap $columnMap"
println()
接下来,从 columnMap 中检索的所有列表,以及在视图中应如何排序这些列表,Groovy 列表分别称为 allColumnList 和 orderList :
def allColumnList = columnMap.keySet() as List
println "employee allColumnList $allColumnList"
def orderList = jqdtParams.order.collect { k, v -> [allColumnList[v.column as Integer], v.dir] }
println "employee orderList $orderList"
我们将使用 Grails 的 Hibernate 标准实现来实际选择要显示的元素以及它们的排序和分页。标准要求过滤器关闭;在大多数示例中,这是作为标准实例本身的创建的一部分给出的,但是在这里我们预先定义过滤器闭包。请注意,在这种情况下,“date hired” 过滤器的相对复杂的解释被视为一年并应用于建立日期范围,并使用 createAlias 以允许我们进入相关类别 Position 和 Office:
def filterer = {
createAlias 'position', 'p'
createAlias 'office', 'o'
if (columnMap.surname.where) ilike 'surname', columnMap.surname.where
if (columnMap.givenNames.where) ilike 'givenNames', columnMap.givenNames.where
if (columnMap.position.where) ilike 'p.name', columnMap.position.where
if (columnMap.office.where) ilike 'o.name', columnMap.office.where
if (columnMap.extension.where) inList 'extension', columnMap.extension.where
if (columnMap.salary.where) inList 'salary', columnMap.salary.where
if (columnMap.hired.where) {
if (columnMap.hired.where.size() > 1) {
or {
columnMap.hired.where.each {
between 'hired', Date.parse('yyyy/MM/dd',"${it}/01/01" as String),
Date.parse('yyyy/MM/dd',"${it}/12/31" as String)
}
}
} else {
between 'hired', Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/01/01" as String),
Date.parse('yyyy/MM/dd',"${columnMap.hired.where[0]}/12/31" as String)
}
}
}
是时候应用上述内容了。第一步是获取分页代码所需的所有 Employee 实例的总数:
def recordsTotal = Employee.count()
println "employee recordsTotal $recordsTotal"
接下来,将过滤器应用于 Employee 实例以获取过滤结果的计数,该结果将始终小于或等于总数(同样,这是针对分页代码):
def c = Employee.createCriteria()
def recordsFiltered = c.count {
filterer.delegate = delegate
filterer()
}
println "employee recordsFiltered $recordsFiltered"
获得这两个计数后,你还可以使用分页和排序信息获取实际过滤的实例。
def orderer = Employee.withCriteria {
filterer.delegate = delegate
filterer()
orderList.each { oi ->
switch (oi[0]) {
case 'surname': order 'surname', oi[1]; break
case 'givenNames': order 'givenNames', oi[1]; break
case 'position': order 'p.name', oi[1]; break
case 'office': order 'o.name', oi[1]; break
case 'extension': order 'extension', oi[1]; break
case 'hired': order 'hired', oi[1]; break
case 'salary': order 'salary', oi[1]; break
}
}
maxResults (jqdtParams.length as Integer)
firstResult (jqdtParams.start as Integer)
}
要完全清楚,JTable 中的分页代码管理三个计数:数据集中的记录总数,应用过滤器后得到的数字,以及要在页面上显示的数字(显示是滚动还是分页)。 排序应用于所有过滤的记录,并且分页应用于那些过滤的记录的块以用于显示目的。
接下来,处理命令返回的结果,在每行中创建指向 Employee、Position 和 Office 实例的链接,以便用户可以单击这些链接以获取相关实例的所有详细信息:
def dollarFormatter = new DecimalFormat('$##,###.##')
def employees = orderer.collect { employee ->
['surname': "<a href='${createLink(controller: 'employee', action: 'show', id: employee.id)}'>${employee.surname}</a>",
'givenNames': employee.givenNames,
'position': "<a href='${createLink(controller: 'position', action: 'show', id: employee.position?.id)}'>${employee.position?.name}</a>",
'office': "<a href='${createLink(controller: 'office', action: 'show', id: employee.office?.id)}'>${employee.office?.name}</a>",
'extension': employee.extension,
'hired': employee.hired.format('yyyy/MM/dd'),
'salary': dollarFormatter.format(employee.salary)]
}
最后,创建要返回的结果并将其作为 JSON 返回,这是 jQuery DataTables 所需要的。
def result = [draw: jqdtParams.draw, recordsTotal: recordsTotal, recordsFiltered: recordsFiltered, data: employees]
render(result as JSON)
}
大功告成。
如果你熟悉 Grails,这可能看起来比你原先想象的要多,但这里没有火箭式的一步到位方法,只是很多分散的操作步骤。但是,如果你没有太多接触 Grails(或 Groovy),那么需要了解很多新东西 - 闭包,代理和构建器等等。
在那种情况下,从哪里开始? 最好的地方是了解 Groovy 本身,尤其是 Groovy closures 和 Groovy delegates and builders。然后再去阅读上面关于 Grails 和 Hibernate 条件查询的建议阅读文章。
结语
jQuery DataTables 为 Grails 制作了很棒的表格数据浏览器。对视图进行编码并不是太棘手,但 DataTables 文档中提供的 PHP 示例提供的功能仅到此位置。特别是,它们不是用 Grails 程序员编写的,也不包含探索使用引用其他类(实质上是查找表)的元素的更精细的细节。
我使用这种方法制作了几个数据浏览器,允许用户选择要查看和累积记录计数的列,或者只是浏览数据。即使在相对适度的 VPS 上的百万行表中,性能也很好。
一个警告:我偶然发现了 Grails 中暴露的各种 Hibernate 标准机制的一些问题(请参阅我的其他 GitHub 代码库),因此需要谨慎和实验。如果所有其他方法都失败了,另一种方法是动态构建 SQL 字符串并执行它们。在撰写本文时,我更喜欢使用 Grails 标准,除非我遇到杂乱的子查询,但这可能只反映了我在 Hibernate 中对子查询的相对缺乏经验。
我希望 Grails 程序员发现本文的有趣性。请随时在下面留下评论或建议。
via: https://opensource.com/article/18/9/using-grails-jquery-and-datatables
作者:Chris Hermansen 选题:lujun9972 译者:jrg 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出