
在这篇文章中,我将讨论为什么你需要尝试一下 Go 语言,以及应该从哪里学起。
Go 语言是可能是最近几年里你经常听人说起的编程语言。尽管它在 2009 年已经发布了,但它最近才开始流行起来。
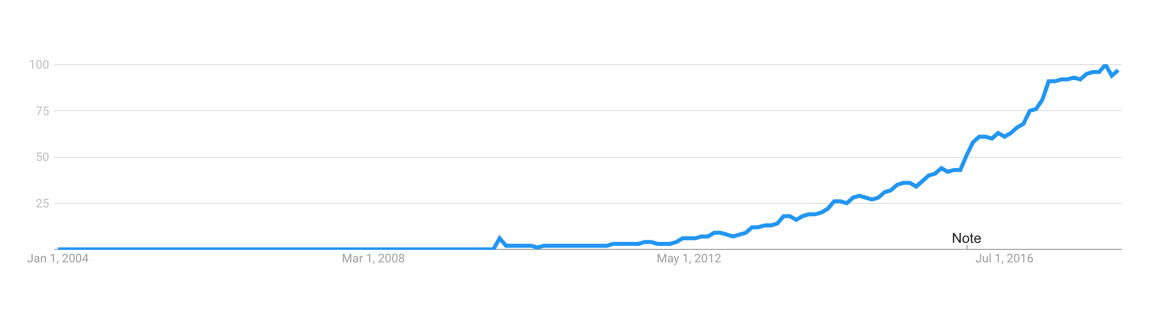
根据 Google 趋势,Go 语言非常流行。
这篇文章不会讨论一些你经常看到的 Go 语言的主要特性。
相反,我想向您介绍一些相当小众但仍然很重要的功能。只有在您决定尝试 Go 语言后,您才会知道这些功能。
这些都是表面上没有体现出来的惊人特性,但它们可以为您节省数周或数月的工作量。而且这些特性还可以使软件开发更加愉快。
阅读本文不需要任何语言经验,所以不必担心你还不了解 Go 语言。如果你想了解更多,可以看看我在底部列出的一些额外的链接。
我们将讨论以下主题:
- GoDoc
- 静态代码分析
- 内置的测试和分析框架
- 竞争条件检测
- 学习曲线
- 反射
- Opinionatedness
- 文化
请注意,这个列表不遵循任何特定顺序来讨论。
GoDoc
Go 语言非常重视代码中的文档,所以也很简洁。
GoDoc 是一个静态代码分析工具,可以直接从代码中创建漂亮的文档页面。GoDoc 的一个显著特点是它不使用任何其他的语言,如 JavaDoc、PHPDoc 或 JSDoc 来注释代码中的结构,只需要用英语。
它使用从代码中获取的尽可能多的信息来概述、构造和格式化文档。它有多而全的功能,比如:交叉引用、代码示例,并直接链接到你的版本控制系统仓库。
而你需要做的只有添加一些像 // MyFunc transforms Foo into Bar 这样子的老牌注释,而这些注释也会反映在的文档中。你甚至可以添加一些通过网络界面或者在本地可以实际运行的 代码示例。
GoDoc 是 Go 的唯一文档引擎,整个社区都在使用。这意味着用 Go 编写的每个库或应用程序都具有相同的文档格式。从长远来看,它可以帮你在浏览这些文档时节省大量时间。
例如,这是我最近一个小项目的 GoDoc 页面:pullkee — GoDoc。
静态代码分析
Go 严重依赖于静态代码分析。例如用于文档的 godoc,用于代码格式化的 gofmt,用于代码风格的 golint,等等。
它们是如此之多,甚至有一个总揽了它们的项目 gometalinter ,将它们组合成了单一的实用程序。
这些工具通常作为独立的命令行应用程序实现,并可轻松与任何编码环境集成。
静态代码分析实际上并不是现代编程的新概念,但是 Go 将其带入了绝对的范畴。我无法估量它为我节省了多少时间。此外,它给你一种安全感,就像有人在你背后支持你一样。
创建自己的分析器非常简单,因为 Go 有专门的内置包来解析和加工 Go 源码。
你可以从这个链接中了解到更多相关内容: GothamGo Kickoff Meetup: Alan Donovan 的 Go 静态分析工具。
内置的测试和分析框架
您是否曾尝试为一个从头开始的 JavaScript 项目选择测试框架?如果是这样,你或许会理解经历这种 过度分析 的痛苦。您可能也意识到您没有使用其中 80% 的框架。
一旦您需要进行一些可靠的分析,问题就会重复出现。
Go 附带内置测试工具,旨在简化和提高效率。它为您提供了最简单的 API,并做出最小的假设。您可以将它用于不同类型的测试、分析,甚至可以提供可执行代码示例。
它可以开箱即用地生成便于持续集成的输出,而且它的用法很简单,只需运行 go test。当然,它还支持高级功能,如并行运行测试,跳过标记代码,以及其他更多功能。
竞争条件检测
您可能已经听说了 Goroutine,它们在 Go 中用于实现并发代码执行。如果你未曾了解过,这里有一个非常简短的解释。
无论具体技术如何,复杂应用中的并发编程都不容易,部分原因在于竞争条件的可能性。
简单地说,当几个并发操作以不可预测的顺序完成时,竞争条件就会发生。它可能会导致大量的错误,特别难以追查。如果你曾经花了一天时间调试集成测试,该测试仅在大约 80% 的执行中起作用?这可能是竞争条件引起的。
总而言之,在 Go 中非常重视并发编程,幸运的是,我们有一个强大的工具来捕捉这些竞争条件。它完全集成到 Go 的工具链中。
您可以在这里阅读更多相关信息并了解如何使用它:介绍 Go 中的竞争条件检测 - Go Blog。
学习曲线
您可以在一个晚上学习所有的 Go 语言功能。我是认真的。当然,还有标准库,以及不同的,更具体领域的最佳实践。但是两个小时就足以让你自信地编写一个简单的 HTTP 服务器或命令行应用程序。
Go 语言拥有出色的文档,大部分高级主题已经在他们的博客上进行了介绍:Go 编程语言博客。
比起 Java(以及 Java 家族的语言)、Javascript、Ruby、Python 甚至 PHP,你可以更轻松地把 Go 语言带到你的团队中。由于环境易于设置,您的团队在完成第一个生产代码之前需要进行的投资要小得多。
反射
代码反射本质上是一种隐藏在编译器下并访问有关语言结构的各种元信息的能力,例如变量或函数。
鉴于 Go 是一种静态类型语言,当涉及更松散类型的抽象编程时,它会受到许多各种限制。特别是与 Javascript 或 Python 等语言相比。
此外,Go 没有实现一个名为泛型的概念,这使得以抽象方式处理多种类型更具挑战性。然而,由于泛型带来的复杂程度,许多人认为不实现泛型对语言实际上是有益的。我完全同意。
根据 Go 的理念(这是一个单独的主题),您应该努力不要过度设计您的解决方案。这也适用于动态类型编程。尽可能坚持使用静态类型,并在确切知道要处理的类型时使用 接口 。接口在 Go 中非常强大且无处不在。
但是,仍然存在一些情况,你无法知道你处理的数据类型。一个很好的例子是 JSON。您可以在应用程序中来回转换所有类型的数据。字符串、缓冲区、各种数字、嵌套结构等。
为了解决这个问题,您需要一个工具来检查运行时的数据并根据其类型和结构采取不同行为。 反射 可以帮到你。Go 拥有一流的反射包,使您的代码能够像 Javascript 这样的语言一样动态。
一个重要的警告是知道你使用它所带来的代价 —— 并且只有知道在没有更简单的方法时才使用它。
你可以在这里阅读更多相关信息: 反射的法则 — Go 博客.
您还可以在此处阅读 JSON 包源码中的一些实际代码: src/encoding/json/encode.go — Source Code
Opinionatedness(专制独裁的 Go)
顺便问一下,有这样一个单词吗?
来自 Javascript 世界,我面临的最艰巨的困难之一是决定我需要使用哪些约定和工具。我应该如何设计代码?我应该使用什么测试库?我该怎么设计结构?我应该依赖哪些编程范例和方法?
这有时候基本上让我卡住了。我需要花时间思考这些事情而不是编写代码并满足用户。
首先,我应该注意到我完全知道这些惯例的来源,它总是来源于你或者你的团队。无论如何,即使是一群经验丰富的 Javascript 开发人员也很容易发现他们在实现相同的结果时,而大部分的经验却是在完全不同的工具和范例上。
这导致整个团队中出现过度分析,并且使得个体之间更难以相互协作。
嗯,Go 是不同的。即使您对如何构建和维护代码有很多强烈的意见,例如:如何命名,要遵循哪些结构模式,如何更好地实现并发。但你只有一个每个人都遵循的风格指南。你只有一个内置在基本工具链中的测试框架。
虽然这似乎过于严格,但它为您和您的团队节省了大量时间。当你写代码时,受一点限制实际上是一件好事。在构建新代码时,它为您提供了一种更直接的方法,并且可以更容易地调试现有代码。
因此,大多数 Go 项目在代码方面看起来非常相似。
文化
人们说,每当你学习一门新的口语时,你也会沉浸在说这种语言的人的某些文化中。因此,您学习的语言越多,您可能会有更多的变化。
编程语言也是如此。无论您将来如何应用新的编程语言,它总能给你带来新的编程视角或某些特别的技术。
无论是函数式编程, 模式匹配 还是 原型继承 。一旦你学会了它们,你就可以随身携带这些编程思想,这扩展了你作为软件开发人员所拥有的问题解决工具集。它们也改变了你阅读高质量代码的方式。
而 Go 在这方面有一项了不起的财富。Go 文化的主要支柱是保持简单,脚踏实地的代码,而不会产生许多冗余的抽象概念,并将可维护性放在首位。大部分时间花费在代码的编写工作上,而不是在修补工具和环境或者选择不同的实现方式上,这也是 Go 文化的一部分。
Go 文化也可以总结为:“应当只用一种方法去做一件事”。
一点注意事项。当你需要构建相对复杂的抽象代码时,Go 通常会妨碍你。好吧,我会说这是简单的权衡。
如果你真的需要编写大量具有复杂关系的抽象代码,那么最好使用 Java 或 Python 等语言。然而,这种情况却很少。
在工作时始终使用最好的工具!
总结
你或许之前听说过 Go,或者它暂时在你圈子以外的地方。但无论怎样,在开始新项目或改进现有项目时,Go 可能是您或您团队的一个非常不错的选择。
这不是 Go 的所有惊人的优点的完整列表,只是一些被人低估的特性。
请尝试一下从 Go 之旅 来开始学习 Go,这将是一个令人惊叹的开始。
如果您想了解有关 Go 的优点的更多信息,可以查看以下链接:
并在评论中分享您的阅读感悟!
即使您不是为了专门寻找新的编程语言语言,也值得花一两个小时来感受它。也许它对你来说可能会变得非常有用。
不断为您的工作寻找最好的工具!
题图来自 https://github.com/ashleymcnamara/gophers 的图稿
via: https://medium.freecodecamp.org/here-are-some-amazing-advantages-of-go-that-you-dont-hear-much-about-1af99de3b23a
作者:Kirill Rogovoy 译者:imquanquan 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出










