红帽 6.28 媒体开放日手记
在一个炎热的下午我代表 Linux 中国开源社区参加了 6 月 28 日的红帽媒体开放日。以下内容摘录自该活动,有删节。

本次参加红帽开放日的主要官方人员如题图,从左到右分别是:
- Fedora 社区工程师 Adam Samalik
- 红帽资深高级云技术官 Thomas Cameron
- ManageIQ 社区负责人 Carol Chen
- 社区活动经理 Jennifer Madriaga
- Fedora 社区负责人 Brian Exelbierd
- CoreOS 及 Prometheus 社区软件工程师 Max Leonard Inden
以下是问题摘录:
问题 1
记者:我想问各位社区成员一个问题,大家本身是社区的负责人或者工程师,同时又有红帽的背景,你们怎么把技术能量转换成价值贡献给社区,又怎么将社区开源的服务能力转化给红帽?
Thomas Cameron:这个问题非常好,其实对我们来说这并不是两边。我们想的首先是这个技术先提供给社区,然后社区进一步的开发完善,最后成为供企业可以使用的技术或者软件,开源是红帽的 DNA,对我们来说最重要的一件事是使这些软件取得成功,因此在我们的工作是就某个软件进行研究,或者推动在某个软件上增加什么新的功能的时候,或者要求红帽提供更多的资源。我们想的目的都是一样的,就是先把技术放进社区,然后在这个基础上进一步的开发创新,最终拿出来供企业使用。
问题 2
记者:比较一下十年前的开源社区跟今天的开源社区的用户差别,十年前的开源社区是极客在参与这个项目,现在再去社区里看一下,有一些用户级的,他可能遇到使用上的麻烦,可能到社区找一些答案,我们这个产品可能在场景应用当中遇到一些特殊的问题和麻烦,这个时候能不能向这些应用者,向被迫进入社区的人介绍一下咱们的沟通机制和反馈机制是怎么样的?另外一个我看到咱们这个众筹项目正在进行中,不同的项目的沟通机制是什么样的,能不能给用户一个介绍?

Brian Exelbierd:这个问题,涉及到沟通的机制,对任何一个项目来说沟通发生在多个不同的层次上,以 Fedora 社区为例,我们的这些核心贡献者、开发建造软件并且把它们提供出来的开发者,他们在 IRC 里进行沟通交流,但是大量的用户沟通的地点在自己感兴趣的场景或者内容不同发生在不同的地点,有些特别专注于游戏或者某个特定场景,他们都有论坛和交流地点,我们也会提醒我们的人要去不同的地点才能了解到更多用户的反馈意见。
下个问题也是令人兴奋的问题,因为 Fedora 的发布会涉及到很多不同的技术,从最开始社区发展起来的时候,我们就在不同的技术小组间建立了很强的反馈和交流机制,我们在进行测试的时候也会对所有的要素进行测试,比如我们会和 CentOS、OpenCI 这样的项目进行联系看看在哪些点上可以实现很好的集成,在哪些点上可能存在问题,这也是不同项目组之间进行沟通的方式。
Max Leonard Inden:我也想补充一个观点,我们每个项目的沟通方式都是不一样的,但是各个项目之间仍然存在着非常密切的沟通,而且我们大家的态度是一样的:所有的沟通都是受欢迎的,没有人会因为在不合适的地点问了问题而受到责难,我们会欢迎你充分的参与进来,提出问题,这是非常重要的一点。
红帽技术人员:再补充一点,关于您提到的现在的普通用户参与社区比十年前多多了,今天的科技更复杂,解决方案也更复杂,我们上游社区的项目同样更复杂,用户也在试图参与进来,第二,对于开发者而言,他使用的最主要的沟通方式是代码和编码,因为代码是他们的共同语言,虽然有人发布了代码,那么就有人从代码的角度看一看应该怎么对他检查,漏洞怎么进行修改,所以代码对于全世界的开发者来说都是同样的语言。
问题 3
记者:红帽愿意帮助我们设立站点下载 ISO 和文件么?当我在用一个红帽的帐户登录网站的时候,我去下载镜像,点按纽会发现有一个衔接,由于我们国家到美国的网速非常慢,整个镜像下载不下来,我们的工作没法进展,我们的解决方案是租一个美国的 VPS,从 VPS 再下载到本地还是会超时,第二个解决方案是再租一个香港 VPS,把这个从美国的拉到香港 VPS,再从香港拉到本地这个时候发现中间这一块又特别慢,想知道红帽有没有相对的解决方案?
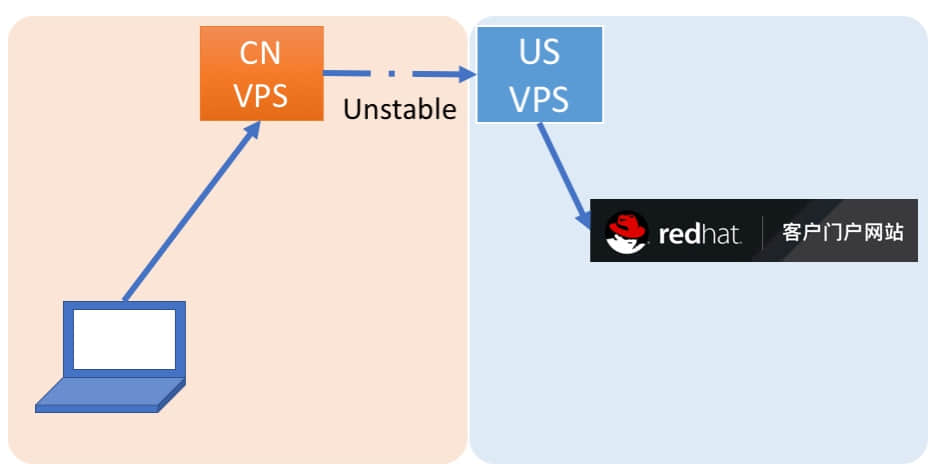
Thomas Cameron:我非常理解您的这种沮丧的情绪,而且我们也感觉这样非常麻烦。但是特别坦率的说,这个问题的解决方案涉及到方方面面,它同时是法律问题,监管问题,涉及到条约等各种各样的问题,而我们在座的人没有一个人适合回答这样的问题,因为我们不是相关问题的专家,但是鉴于您有红帽的帐户,我建议您联系一个帐户经理,他会想办法帮您找解决方案,因为我们不想使您得到非常坏的体验,也不想麻烦您建立多个 VPS 的去解决,但是这个问题的最终解决还是需要律师法律团队和网络的工程团队,我们没办法回答,谢谢。
问题 4
记者:在 Fedora 社区有不同的区域划分,相互之间的差异化红帽是怎么解决的,在中国的本地化进程是怎样落地的,人员参与和贡献分别是多少?

Brian Exelbierd:我非得站起来回答您的第二个问题不可,因为要给您看一下我穿的体恤,这个体恤是 Fedora 本地化的主题,这是我们第 26 次发布 Fedora 版本的时候做的,主要目的是为了感谢全世界各地为 Fedora 本地化做出贡献的人们,因为确实有很多人都参与进来了,里面有一个泡泡写的是汉语。
我现在回答您问题的第一部分,您讲的非常对,我们 Fedora 是分区域的这个主要是有两个原因,首先是过去为了行政管理的便利做出的安排,因为这样分成不同的区域之后就可以更为容易的,相当于在本地做决定,而且资金的流动也更便利一些,随着全球化的发展,这个重要性降低了。还有第二个原因,您刚才提到差异化,差异性是无处不在的,我们希望在对话的时候,彼此的对话能在一个更适合的地方发生,因而在不同的国家和社区进行对话时所产生的决议有效,毕竟不同区域在文化上是有敏感性的。
回答您的第二个问题,您问到中国有多少贡献者,和他们在在这个社区中多活跃,对这样的问题,我们的回答永远是不够多,因为我们希望任何地方的贡献者都能够更多一些,希望他们更活跃的参与社区的活动。在中国我们也面临这样的挑战,因为中国的这些软件工程师或者相关可能的爱好者,他们本身的工作时间是非常长的,会加很长的班,通勤时间也非常长。这样他们就没有太多的精力投入开源社区的活动,此外中国社会不太重视让学生参与开源活动,大部分学生更专注于把考分弄的更高一点。我们在中国一直希望寻找对开源感兴趣的人,鼓励他们参与进来。不管你面临什么样的用户和场景,我们希望都是有人能够和你进行交流提供帮助的,所以我们非常鼓励大家的参与。
再补充一点,我们的开源社区是非常具有全球性的社区,因此绝不会在中国天然的有哪些情况就使得中国人为社区做贡献特别难,不会有这些情况,比如我本人经常在晚上九点和社区的成员进行交流,因为这个对大部分社区成员来说是最合适的时间。对不少中国人来讲,中国的时区和美国时区差异特别大,但是这一点不会阻止开源社区的交流。
问题 5
记者:我想问一个跟开源和闭源有关的问题,从软件开发的角度来讲,开源比闭源好,因为闭源一年更新的速度比较慢,而开源的广泛性和活跃性远远大于闭源,但是从商业角度来讲,开源还是不太成功的,以红帽为例,现在红帽每年的营收跟微软和闭源的软件厂商来讲远远不在一个级别上,从商业的角度讲,开源不那么成熟,作为开源社区的大拿来讲,吸引你们进入开源的热情是你们对技术的偏好,还是你们坚信开源技术未来在商业上有很大的潜质,什么支撑你们在开源领域里努力?
Thomas Cameron:在商业上我们已经比那些闭源的软件厂商要成功了。如果仔细的看一下红帽的财报跟他每年的增长,我们每年平均增长都在 20% 以上,所以从增速的角度来看,我们比所有的闭源软件开发公司做的都要好,所以从商业模式上已经证明了开源可以做的很好。关于为什么我个人会在开源中,这个回答非常简单,因为在这个世界上没有任何其他一个我所知道的行业能够让一个国家、或者一个村子里的人看到代码,并且利用手上的电脑开展相关的工作,没有任何一个其他的行业像开源社区一样把自己知道的一切都告诉别人,而在这个过程中我还拿到一份薪酬,当然我不能代表别人说话,我自己而言我觉得我是全世界最幸运的人,一方面我能够每天都在玩这些最酷的技术,同时还把我所知道的一切告诉任何感兴趣想学习的人,在这个过程中还能拿到工资。

给大家看一下大臂上的刺青,我觉得几乎没有那个闭源公司的员工会把自己公司的logo刻到自己的身上,但是我这样做了。大概五年前,闭源和开源软件公司之间的冲突还是非常显著的,但是今天我们可以看到所有的闭源软件公司都在采用开源的方法,他们也在发布大量的开源的代码,也就是说他们都看到了开源的模式,协作,为他人提供服务,以及做一切人人们生活变的更好的事情,这个模式是被大家认可的,这个时代是非常不可思议的,著名厂商包括IBM,微软,甲骨文等等,他们都在做开源的事情。
Jennifer Madriaga:我也补充一下,强调一下我们开源的核心是协作,在开源的社区里面,你会发现很多竞争对手同时也是合作的伙伴,我们和 IBM 是很好的伙伴,和微软是很好的伙伴,是 AWS、谷歌都是非常好的伙伴。重要的是没有他们的参与,没有我们的参与,这个行业就不可能取得这么大的成功。我经常到各个社区去,在这个过程中会和其他的组织进行交流,其中不少会被媒体描述为我们的竞争对手。我们也不仅仅和这些公司打交道,我们还和很多大学,非盈利机构进行沟通,这个社区是多样的,而且有大量的互动。开源社区伟大的一点是他特别促进创新,有这样的一个机构,CERN,欧洲原子能组织,他们的每一个软件都是开源的,他们在用 CoreOS、Fedora、Ceph 等,还有 NASA,也使用了大量的开源软件,其实他们是最早发明了 OpenStack,之后在社区得以进一步开发。行业的未来是开源,很多公司为什么用开源,因为他们知道只有用了开源才能保持自己的敏捷性,而且他们也知道自己是没有办法预测未来的,但是如果他们不与时俱进,那么这个公司可能将来就死路一条。
Adam Samalik:假如你是一个喜欢编代码的人,或者公司让程序员编写代码,如果你在社区里发布过你的代码,并且让其他人为这个代码做出贡献,你立刻会意识到开源的重要性或者价值。拿 Kubernetes 举个例子,它最早是谷歌拿出来的,一开始非常简单,但是大家都看到它的前景,现在有好多公司在为 Kubernetes 做出贡献,Kubernetes 本身也变的更为庞大,而且是非常棒的,但是在开源社区会发生这些事情,你把代码拿出来不是损失了自己的代码,有更多人会对你帮助,会有更多的贡献。
Carol Chen:谈到关系,在去年我们与阿里巴巴建立了伙伴关系,我希望并且认为肯定有更多的中国本地的伙伴关系发展起来。其实看一看 LC3 大会就知道了,有那么多大大小小的本地公司他们都在做开源,而且非常愿意分享自己用开源的经验,所以我想在这方面我们可以真实的看到这个趋势。关于个人的动机,我非常喜欢技术,我喜欢和别人分享东西,我也喜欢给别人参与这些非常酷的项目的机会,我也希望生活能够过的好,而参与开源给了我这一切。
某男:我补充一句关于创新和开源的关系,我们的 CEO 发布了一本新书《开放式创新》,现在我们看到在当今世界上人们面临的问题越来越复杂,对于这些复杂的问题一个公司单独没有办法解决,我们需要很多公司很多人合作,所以开源的平台会是非常重要的,这么多人和企业都可以一起寻找解决方案,所以开源在将来肯定会非常重要的推动创新。
Brian Exelbierd:我要讲的故事跟他们都不一样,我不知道一开始加入开源社区的动机是不是像我的同事那么纯净。 我就记得当时在大学里的朋友来找我,他当时拿着最初的 Linux 的某个版本,我们当时用软盘的复制工具复制了 64 个软盘,当时是希望能用这个东西让我非常糟糕的电脑转的更快一点。
当时我这个同学就说,欧洲有这么一个人在干这个事情,你知道我们都是美国人,住在美国也不太关心,不知道他在欧洲哪儿,但是现在我住在欧洲,知道那些地方在哪儿。当时有一个特别自私的想法,就是想让我的电脑快一点,我也做出了我的第一个贡献,因为我想让这个程序运行得有点差别,想改一下。所以最初这个动机帮助我逐步进入开源社区,当时我还是一个大学生,所以写的代码不太好,当时有代码的审阅人员,他们会看代码给你各种建议帮助你改进,这样逐步的参与动机,自私程度降低了,而更多的希望我能够也做出点贡献,也给其他人提供一些帮助。我们最早的时候有 GRP 系统,厂商根本不问我们用的怎么样,但是在开源社区情况完全不一样,我们跟企业用户沟通,他们会直接说出这个软件存在什么问题,并且他会告诉你我们应该怎么改进。
Max Leonard Inden:我为什么我参加了开源社区,我的同事们讲的非常好,从我的角度来讲是开源让我能够到这儿,让我在大会上发言,并且公开谈论我自己感兴趣的东西,而且能听别人谈。

听了大家的提问和回答,本人有如下感受:
- 开源在中国需要更多的非程序员的贡献者,来在艺术、营销、文档三个方面做出更多的贡献。
- 文化始终是大于代码的(Culture is bigger than code)。
- 开源本身是跨越了国界、地域、文化,让我们把资源更高效的利用起来让人们的生活更美好(OpenSource making people's life better)。














