在 本系列的第一篇文章 开始使用 Git 时,我们创建了一个简单的 Git 仓库,并用我们的计算机连接到它,向其中添加一个文件。在本文中,我们将学习一些关于 Git 的其他内容,即如何克隆(下载)、修改、添加和删除 Git 仓库中的文件。
让我们来克隆一下
假设你在 GitHub 上已经有一个 Git 仓库,并且想从它那里获取你的文件——也许你在你的计算机上丢失了本地副本,或者你正在另一台计算机上工作,但是想访问仓库中的文件,你该怎么办?从 GitHub 下载你的文件?没错!在 Git 术语中我们称之为“ 克隆 ”。(你也可以将仓库作为 ZIP 文件下载,但我们将在本文中探讨克隆方式。)
让我们克隆在上一篇文章中创建的名为 Demo 的仓库。(如果你还没有创建 Demo 仓库,请跳回到那篇文章并在继续之前执行那些步骤)要克隆文件,只需打开浏览器并导航到 https://github.com/<your_username>/Demo (其中 <your_username> 是你仓库的名称。例如,我的仓库是 https://github.com/kedark3/Demo)。一旦你导航到该 URL,点击“ 克隆或下载 ”按钮,你的浏览器看起来应该是这样的:
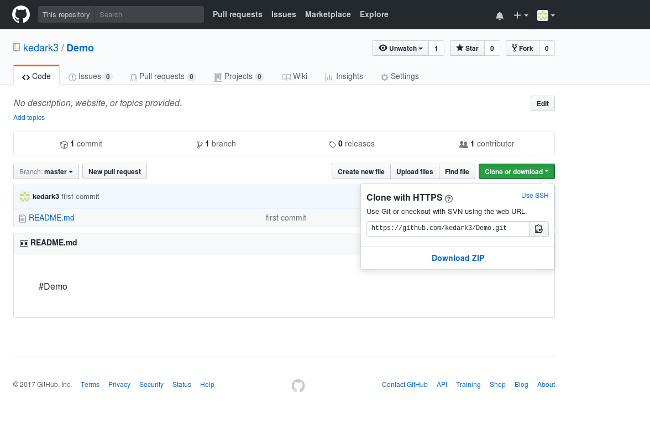
正如你在上面看到的,“ 使用 HTTPS 克隆 ”选项已打开。从该下拉框中复制你的仓库地址(https://github.com/<your_username>/Demo.git),打开终端并输入以下命令将 GitHub 仓库克隆到你的计算机:
git clone https://github.com/<your_username>/Demo.git
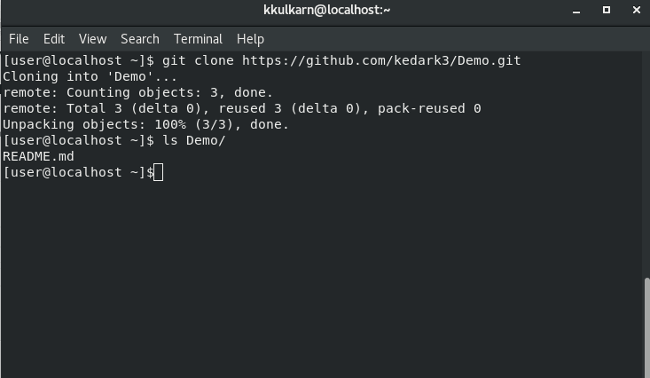
然后,要查看 Demo 目录中的文件列表,请输入以下命令:
ls Demo/
终端看起来应该是这样的:
修改文件
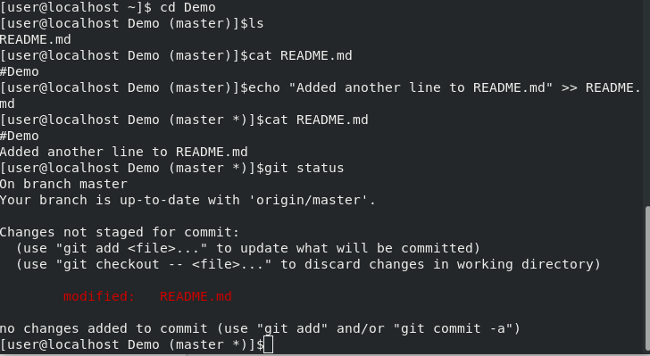
现在我们已经克隆了仓库,让我们修改文件并在 GitHub 上更新它们。首先,逐个输入下面的命令,将目录更改为 Demo/,检查 README.md 中的内容,添加新的(附加的)内容到 README.md,然后使用 git status 检查状态:
cd Demo/
ls
cat README.md
echo "Added another line to REAMD.md" >> README.md
cat README.md
git status
如果你逐一运行这些命令,终端看起开将会是这样:
让我们看一下 git status 的输出,并了解它的意思。不要担心这样的语句:
On branch master
Your branch is up-to-date with 'origin/master'.".
因为我们还没有学习这些。(LCTT 译注:学了你就知道了)下一行说:Changes not staged for commit(变化未筹划提交);这是告诉你,它下面列出的文件没有被标记准备(“ 筹划 ”)提交。如果你运行 git add,Git 会把这些文件标记为 Ready for commit(准备提交);换句话说就是 Changes staged for commit(变化筹划提交)。在我们这样做之前,让我们用 git diff 命令来检查我们添加了什么到 Git 中,然后运行 git add。
这里是终端输出:
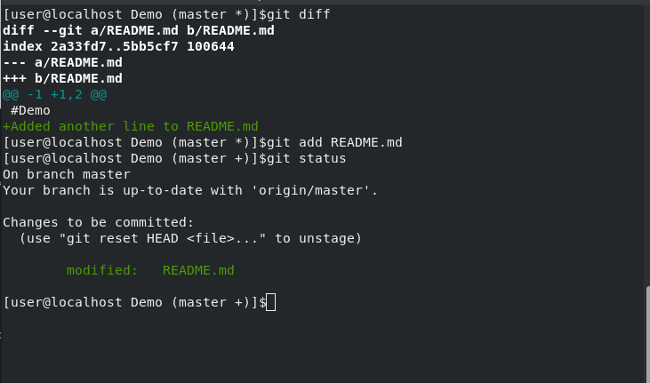
我们来分析一下:
diff --git a/README.md b/README.md 是 Git 比较的内容(在这个例子中是 README.md)。--- a/README.md 会显示从文件中删除的任何东西。+++ b/README.md 会显示从文件中添加的任何东西。- 任何添加到文件中的内容都以绿色文本打印,并在该行的开头加上
+ 号。 - 如果我们删除了任何内容,它将以红色文本打印,并在该行的开头加上
- 号。 - 现在
git status 显示 Changes to be committed:(变化将被提交),并列出文件名(即 README.md)以及该文件发生了什么(即它已经被 modified 并准备提交)。
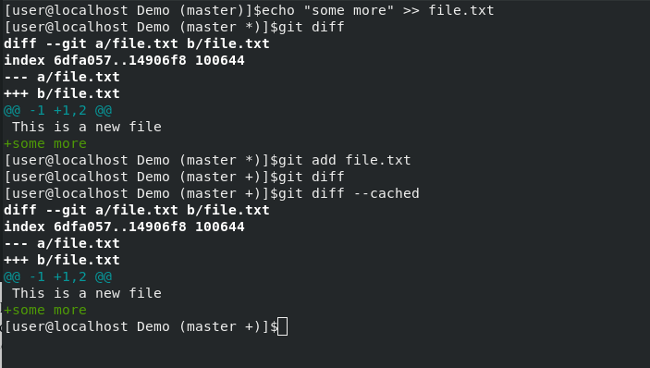
提示:如果你已经运行了 git add,现在你想看看文件有什么不同,通常 git diff 不会输出任何东西,因为你已经添加了文件。相反,你必须使用 git diff --cached。它会告诉你 Git 添加的当前版本和以前版本文件之间的差别。你的终端输出看起来会是这样:
上传文件到你的仓库
我们用一些新内容修改了 README.md 文件,现在是时候将它上传到 GitHub。
让我们提交更改并将其推送到 GitHub。运行:
git commit -m "Updated Readme file"
这告诉 Git 你正在“提交”已经“添加”的更改,你可能还记得,从本系列的第一部分中,添加一条消息来解释你在提交中所做的操作是非常重要的,以便你在稍后回顾 Git 日志时了解当时的目的。(我们将在下一篇文章中更多地关注这个话题。)Updated Readme file 是这个提交的消息——如果你认为这没有合理解释你所做的事情,那么请根据需要写下你的提交消息。
运行 git push -u origin master,这会提示你输入用户名和密码,然后将文件上传到你的 GitHub 仓库。刷新你的 GitHub 页面,你应该会看到刚刚对 README.md 所做的更改。
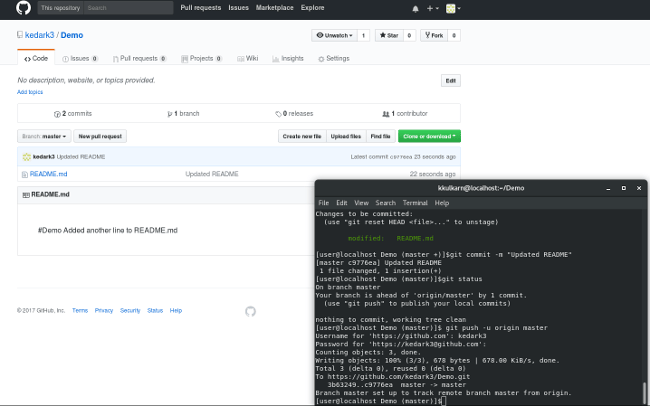
终端的右下角显示我提交了更改,检查了 Git 状态,并将更改推送到了 GitHub。git status 显示:
Your branch is ahead of 'origin/master' by 1 commit
(use "git push" to publish your local commits)
第一行表示在本地仓库中有一个提交,但不在 origin/master 中(即在 GitHub 上)。下一行指示我们将这些更改推送到 origin/master 中,这就是我们所做的。(在本例中,请参阅本系列的第一篇文章,以唤醒你对 origin 含义的记忆。我将在下一篇文章中讨论分支的时候,解释 master 的含义。)
添加新文件到 Git
现在我们修改了一个文件并在 GitHub 上更新了它,让我们创建一个新文件,将它添加到 Git,然后将其上传到 GitHub。 运行:
echo "This is a new file" >> file.txt
这将会创建一个名为 file.txt 的新文件。
如果使用 cat 查看它:
cat file.txt
你将看到文件的内容。现在继续运行:
git status
Git 报告说你的仓库中有一个未跟踪的文件(名为 file.txt)。这是 Git 告诉你说在你的计算机中的仓库目录下有一个新文件,然而你并没有告诉 Git,Git 也没有跟踪你所做的任何修改。
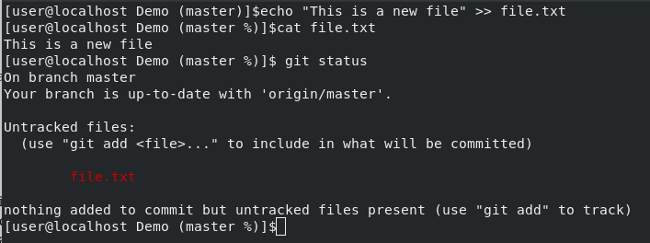
我们需要告诉 Git 跟踪这个文件,以便我们可以提交并上传文件到我们的仓库。以下是执行该操作的命令:
git add file.txt
git status
终端输出如下:
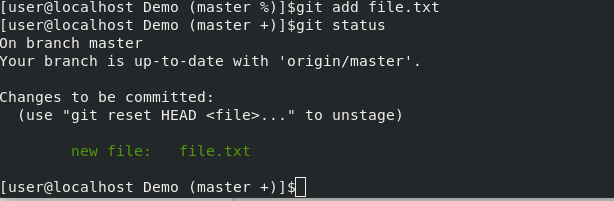
git status 告诉你有 file.txt 被修改,对于 Git 来说它是一个 new file,Git 在此之前并不知道。现在我们已经为 Git 添加了 file.txt,我们可以提交更改并将其推送到 origin/master。
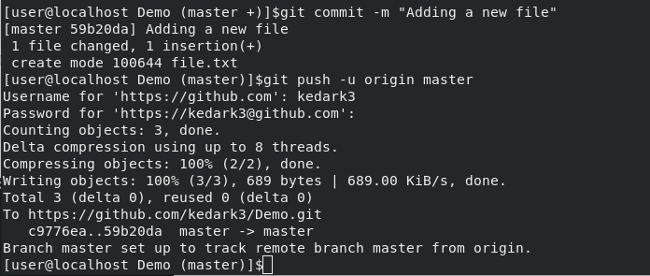
Git 现在已经将这个新文件上传到 GitHub;如果刷新 GitHub 页面,则应该在 GitHub 上的仓库中看到新文件 file.txt。
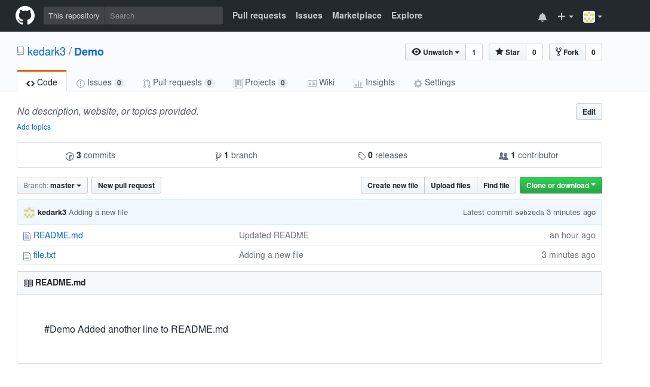
通过这些步骤,你可以创建尽可能多的文件,将它们添加到 Git 中,然后提交并将它们推送到 GitHub。
从 Git 中删除文件
如果我们发现我们犯了一个错误,并且需要从我们的仓库中删除 file.txt,该怎么办?一种方法是使用以下命令从本地副本中删除文件:
rm file.txt
如果你现在做 git status,Git 就会说有一个文件 not staged for commit(未筹划提交),并且它已经从仓库的本地拷贝中删除了。如果我们现在运行:
git add file.txt
git status
我知道我们正在删除这个文件,但是我们仍然运行 git add,因为我们需要告诉 Git 我们正在做的更改,git add 可以用于我们添加新文件、修改一个已存在文件的内容、或者从仓库中删除文件时。实际上,git add 将所有更改考虑在内,并将这些筹划提交这些更改。如果有疑问,请仔细查看下面终端屏幕截图中每个命令的输出。
Git 会告诉我们已删除的文件正在进行提交。只要你提交此更改并将其推送到 GitHub,该文件也将从 GitHub 的仓库中删除。运行以下命令:
git commit -m "Delete file.txt"
git push -u origin master
现在你的终端看起来像这样:
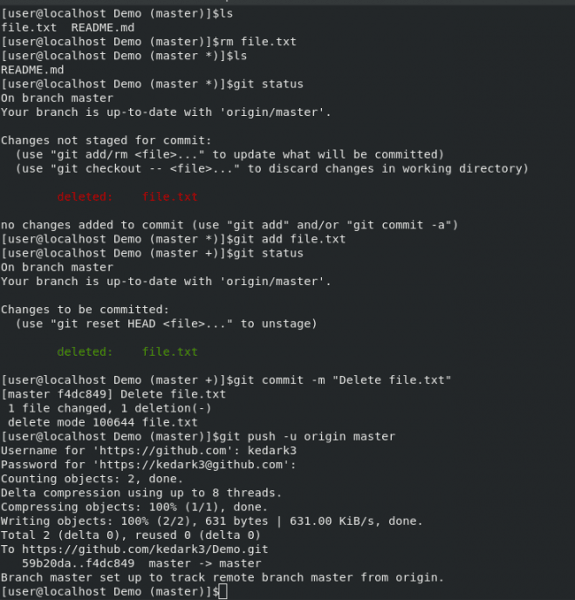
你的 GitHub 看起来像这样:
现在你知道如何从你的仓库克隆、添加、修改和删除 Git 文件。本系列的下一篇文章将检查 Git 分支。
via: https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
作者:Kedar Vijay Kulkarni 译者:MjSeven 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出