学习在你的 Linux 计算机上摆弄那些软件。

如何在 Linux 上安装应用程序?因为有许多操作系统,这个问题不止有一个答案。应用程序可以可以来自许多来源 —— 几乎不可能数的清,并且每个开发团队都可以以他们认为最好的方式提供软件。知道如何安装你所得到的软件是成为操作系统高级用户的一部分。
仓库
十多年来,Linux 已经在使用软件库来分发软件。在这种情况下,“仓库”是一个托管可安装软件包的公共服务器。Linux 发行版提供了一条命令,以及该命令的图形界面,用于从服务器获取软件并将其安装到你的计算机。这是一个非常简单的概念,它已经成为所有主流手机操作系统的模式,最近,该模式也成为了两大闭源计算机操作系统的“应用商店”。

不是应用程序商店
从软件仓库安装是在 Linux 上安装应用程序的主要方法,它应该是你寻找想要安装的任何应用程序的首选地方。
从软件仓库安装,通常需要一个命令,如:
$ sudo dnf install inkscape
实际使用的命令取决于你所使用的 Linux 发行版。Fedora 使用 dnf,OpenSUSE 使用 zypper,Debian 和 Ubuntu 使用 apt,Slackware 使用 sbopkg,FreeBSD 使用 pkg_add,而基于 lllumos 的 Openlndiana 使用 pkg。无论你使用什么,该命令通常要搜索你想要安装应用程序的正确名称,因为有时候你认为的软件名称不是它官方或独有的名称:
$ sudo dnf search pyqt
PyQt.x86_64 : Python bindings for Qt3
PyQt4.x86_64 : Python bindings for Qt4
python-qt5.x86_64 : PyQt5 is Python bindings for Qt5
一旦你找到要安装的软件包的名称后,使用 install 子命令执行实际的下载和自动安装:
$ sudo dnf install python-qt5
有关从软件仓库安装的具体信息,请参阅你的 Linux 发行版的文档。
图形工具通常也是如此。搜索你认为你想要的,然后安装它。
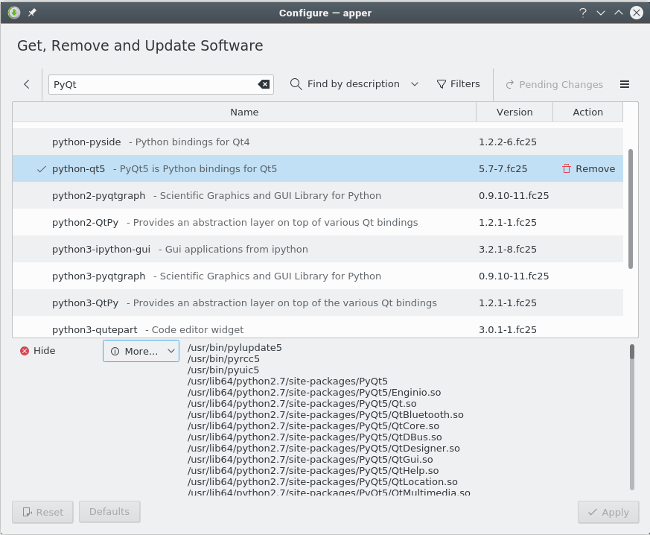
与底层命令一样,图形安装程序的名称取决于你正在运行的 Linux 发行版。相关的应用程序通常使用“软件(software)”或“包(package)”等关键字进行标记,因此请在你的启动项或菜单中搜索这些词汇,然后你将找到所需的内容。 由于开源全由用户来选择,所以如果你不喜欢你的发行版提供的图形用户界面(GUI),那么你可以选择安装替代品。 你知道该如何做到这一点。
额外仓库
你的 Linux 发行版为其打包的软件提供了标准仓库,通常也有额外的仓库。例如,EPEL 服务于 Red Hat Enterprise Linux 和 CentOS,RPMFusion 服务于 Fedora,Ubuntu 有各种级别的支持以及个人包存档(PPA),Packman 为 OpenSUSE 提供额外的软件以及 SlackBuilds.org 为 Slackware 提供社区构建脚本。
默认情况下,你的 Linux 操作系统设置为只查看其官方仓库,因此如果你想使用其他软件集合,则必须自己添加额外库。你通常可以像安装软件包一样安装仓库。实际上,当你安装例如 GNU Ring 视频聊天,Vivaldi web 浏览器,谷歌浏览器等许多软件时,你的实际安装是访问他们的私有仓库,从中将最新版本的应用程序安装到你的机器上。

安装仓库
你还可以通过编辑文本文件将仓库手动添加到你的软件包管理器的配置目录,或者运行命令来添加添加仓库。像往常一样,你使用的确切命令取决于 Linux 发行版本。例如,这是一个 dnf 命令,它将一个仓库添加到系统中:
$ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
不使用仓库来安装应用程序
仓库模型非常流行,因为它提供了用户(你)和开发人员之间的链接。重要更新发布之后,系统会提示你接受更新,并且你可以从一个集中位置接受所有更新。
然而,有时候一个软件包还没有放到仓库中时。这些安装包有几种形式。
Linux 包
有时候,开发人员会以通用的 Linux 打包格式分发软件,例如 RPM、DEB 或较新但非常流行的 FlatPak 或 Snap 格式。你不是访问仓库下载的,你只是得到了这个包。
例如,视频编辑器 Lightworks 为 APT 用户提供了一个 .deb 文件,RPM 用户提供了 .rpm 文件。当你想要更新时,可以到网站下载最新的适合的文件。
这些一次性软件包可以使用从仓库进行安装时所用的一样的工具进行安装。如果双击下载的软件包,图形安装程序将启动并逐步完成安装过程。
或者,你可以从终端进行安装。这里的区别在于你从互联网下载的独立包文件不是来自仓库。这是一个“本地”安装,这意味着你的软件安装包不需要下载来安装。大多数软件包管理器都是透明处理的:
$ sudo dnf install ~/Downloads/lwks-14.0.0-amd64.rpm
在某些情况下,你需要采取额外的步骤才能使应用程序运行,因此请仔细阅读有关你正在安装软件的文档。
通用安装脚本
一些开发人员以几种通用格式发布他们的包。常见的扩展名包括 .run 和 .sh。NVIDIA 显卡驱动程序、像 Nuke 和 Mari 这样的 Foundry visual FX 软件包以及来自 GOG 的许多非 DRM 游戏都是用这种安装程序。(LCTT 译注:DRM 是数字版权管理。)
这种安装模式依赖于开发人员提供安装“向导”。一些安装程序是图形化的,而另一些只是在终端中运行。
有两种方式来运行这些类型的安装程序。
1、 你可以直接从终端运行安装程序:
$ sh ./game/gog_warsow_x.y.z.sh
2、 另外,你可以通过标记其为可执行文件来运行它。要标记为安装程序可执行文件,右键单击它的图标并选择其属性。

给安装程序可执行权限。
一旦你允许其运行,双击图标就可以安装了。

GOG 安装程序
对于其余的安装程序,只需要按照屏幕上的说明进行操作。
AppImage 便携式应用程序
AppImage 格式对于 Linux 相对来说比较新,尽管它的概念是基于 NeXT 和 Rox 的。这个想法很简单:运行应用程序所需的一切都应该放在一个目录中,然后该目录被视为一个“应用程序”。要运行该应用程序,只需双击该图标即可运行。不需要也要不应该把应用程序安装在传统意义的地方;它从你在硬盘上的任何地方运行都行。
尽管它可以作为独立应用运行,但 AppImage 通常提供一些系统集成。

AppImage 系统集成
如果你接受此条件,则将一个本地的 .desktop 文件安装到你的主目录。.desktop 文件是 Linux 桌面的应用程序菜单和 mimetype 系统使用的一个小配置文件。实质上,只是将桌面配置文件放置在主目录的应用程序列表中“安装”应用程序,而不实际安装它。你获得了安装某些东西的所有好处,以及能够在本地运行某些东西的好处,即“便携式应用程序”。
应用程序目录
有时,开发人员只是编译一个应用程序,然后将结果发布到下载中,没有安装脚本,也没有打包。通常,这意味着你下载了一个 TAR 文件,然后 解压缩,然后双击可执行文件(通常是你下载软件的名称)。

下载 Twine
当使用这种软件方式交付时,你可以将它放在你下载的地方,当你需要它时,你可以手动启动它,或者你可以自己进行快速但是麻烦的安装。这包括两个简单的步骤:
- 将目录保存到一个标准位置,并在需要时手动启动它。
- 将目录保存到一个标准位置,并创建一个
.desktop 文件,将其集成到你的系统中。
如果你只是为自己安装应用程序,那么传统上会在你的主目录中放个 bin (“ 二进制文件 ” 的简称)目录作为本地安装的应用程序和脚本的存储位置。如果你的系统上有其他用户需要访问这些应用程序,传统上将二进制文件放置在 /opt 中。最后,这取决于你存储应用程序的位置。
下载通常以带版本名称的目录进行,如 twine_2.13 或者 pcgen-v6.07.04。由于假设你将在某个时候更新应用程序,因此将版本号删除或创建目录的符号链接是个不错的主意。这样,即使你更新应用程序本身,为应用程序创建的启动程序也可以保持不变。
要创建一个 .desktop 启动文件,打开一个文本编辑器并创建一个名为 twine.desktop 的文件。桌面条目规范 由 FreeDesktop.org 定义。下面是一个简单的启动器,用于一个名为 Twine 的游戏开发 IDE,安装在系统范围的 /opt 目录中:
[Desktop Entry]
Encoding=UTF-8
Name=Twine
GenericName=Twine
Comment=Twine
Exec=/opt/twine/Twine
Icon=/usr/share/icons/oxygen/64x64/categories/applications-games.png
Terminal=false
Type=Application
Categories=Development;IDE;
棘手的一行是 Exec 行。它必须包含一个有效的命令来启动应用程序。通常,它只是你下载的东西的完整路径,但在某些情况下,它更复杂一些。例如,Java 应用程序可能需要作为 Java 自身的参数启动。
Exec=java -jar /path/to/foo.jar
有时,一个项目包含一个可以运行的包装脚本,这样你就不必找出正确的命令:
Exec=/opt/foo/foo-launcher.sh
在这个 Twine 例子中,没有与该下载的软件捆绑的图标,因此示例 .desktop 文件指定了 KDE 桌面附带的通用游戏图标。你可以使用类似的解决方法,但如果你更具艺术性,可以创建自己的图标,或者可以在 Internet 上搜索一个好的图标。只要 Icon 行指向一个有效的 PNG 或 SVG 文件,你的应用程序就会以该图标为代表。
示例脚本还将应用程序类别主要设置为 Development,因此在 KDE、GNOME 和大多数其他应用程序菜单中,Twine 出现在开发类别下。
为了让这个例子出现在应用程序菜单中,把 twine.desktop 文件放这到两个地方之一:
- 如果你将应用程序存储在你自己的家目录下,那么请将其放在
~/.local/share/applications。 - 如果你将应用程序存储在
/opt 目录或者其他系统范围的位置,并希望它出现在所有用户的应用程序菜单中,请将它放在 /usr/share/applications 目录中。
现在,该应用程序已安装,因为它需要与系统的其他部分集成。
从源代码编译
最后,还有真正的通用格式安装格式:源代码。从源代码编译应用程序是学习如何构建应用程序,如何与系统交互以及如何定制应用程序的好方法。尽管如此,它绝不是一个点击按钮式过程。它需要一个构建环境,通常需要安装依赖库和头文件,有时还要进行一些调试。
要了解更多关于从源代码编译的内容,请阅读我这篇文章。
现在你明白了
有些人认为安装软件是一个神奇的过程,只有开发人员理解,或者他们认为它“激活”了应用程序,就好像二进制可执行文件在“安装”之前无效。学习许多不同的安装方法会告诉你安装实际上只是“将文件从一个地方复制到系统中适当位置”的简写。 没有什么神秘的。只要你去了解每次安装,不是期望应该如何发生,并且寻找开发者为安装过程设置了什么,那么通常很容易,即使它与你的习惯不同。
重要的是安装器要诚实于你。 如果你遇到未经你的同意尝试安装其他软件的安装程序(或者它可能会以混淆或误导的方式请求同意),或者尝试在没有明显原因的情况下对系统执行检查,则不要继续安装。
好的软件是灵活的、诚实的、开放的。 现在你知道如何在你的计算机上获得好软件了。
via: https://opensource.com/article/18/1/how-install-apps-linux
作者:Seth Kenlon 译者:MjSeven 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出