“如果你不知道编译器是怎么工作的,那你就不知道电脑是怎么工作的。如果你不能百分百确定,那就是不知道它们是如何工作的。” --Steve Yegge

就是这样。想一想。你是萌新还是一个资深的软件开发者实际上都无关紧要:如果你不知道 编译器 和 解释器 是怎么工作的,那么你就不知道电脑是怎么工作的。就这么简单。
所以,你知道编译器和解释器是怎么工作的吗?我是说,你百分百确定自己知道他们怎么工作吗?如果不知道。

或者如果你不知道但你非常想要了解它。

不用担心。如果你能坚持跟着这个系列做下去,和我一起构建一个解释器和编译器,最后你将会知道他们是怎么工作的。并且你会变成一个自信满满的快乐的人。至少我希望如此。

为什么要学习编译器和解释器?有三点理由。
- 要写出一个解释器或编译器,你需要有很多的专业知识,并能融会贯通。写一个解释器或编译器能帮你加强这些能力,成为一个更厉害的软件开发者。而且,你要学的技能对编写软件非常有用,而不是仅仅局限于解释器或编译器。
- 你确实想要了解电脑是怎么工作的。通常解释器和编译器看上去很魔幻。你或许不习惯这种魔力。你会想去揭开构建解释器和编译器那层神秘的面纱,了解它们的原理,把事情做好。
- 你想要创建自己的编程语言或者特定领域的语言。如果你创建了一个,你还要为它创建一个解释器或者编译器。最近,兴起了对新的编程语言的兴趣。你能看到几乎每天都有一门新的编程语言横空出世:Elixir,Go,Rust,还有很多。
好,但什么是解释器和编译器?
解释器 和 编译器 的任务是把用高级语言写的源程序翻译成其他的格式。很奇怪,是不是?忍一忍,稍后你会在这个系列学到到底把源程序翻译成什么东西。
这时你可能会奇怪解释器和编译器之间有什么区别。为了实现这个系列的目的,我们规定一下,如果有个翻译器把源程序翻译成机器语言,那它就是 编译器。如果一个翻译器可以处理并执行源程序,却不用把它翻译器机器语言,那它就是 解释器。直观上它看起来像这样:

我希望你现在确信你很想学习构建一个编译器和解释器。你期望在这个教程里学习解释器的哪些知识呢?
你看这样如何。你和我一起为 Pascal 语言的一个大子集做一个简单的解释器。在这个系列结束的时候你能做出一个可以运行的 Pascal 解释器和一个像 Python 的 pdb 那样的源代码级别的调试器。
你或许会问,为什么是 Pascal?一方面,它不是我为了这个系列而提出的一个虚构的语言:它是真实存在的一门编程语言,有很多重要的语言结构。有些陈旧但有用的计算机书籍使用 Pascal 编程语言作为示例(我知道对于选择一门语言来构建解释器,这个理由并不令人信服,但我认为学一门非主流的语言也不错 :))。
这有个 Pascal 中的阶乘函数示例,你将能用自己的解释器解释代码,还能够用可交互的源码级调试器进行调试,你可以这样创造:
program factorial;
function factorial(n: integer): longint;
begin
if n = 0 then
factorial := 1
else
factorial := n * factorial(n - 1);
end;
var
n: integer;
begin
for n := 0 to 16 do
writeln(n, '! = ', factorial(n));
end.
这个 Pascal 解释器的实现语言会使用 Python,但你也可以用其他任何语言,因为这里展示的思想不依赖任何特殊的实现语言。好,让我们开始干活。准备好了,出发!
你会从编写一个简单的算术表达式解析器,也就是常说的计算器,开始学习解释器和编译器。今天的目标非常简单:让你的计算器能处理两个个位数相加,比如 3+5。下面是你的计算器的源代码——不好意思,是解释器:
# 标记类型
#
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token 类型: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token 值: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, '+', 或 None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# 用户输入字符串, 例如 "3+5"
self.text = text
# self.pos 是 self.text 的索引
self.pos = 0
# 当前标记实例
self.current_token = None
def error(self):
raise Exception('Error parsing input')
def get_next_token(self):
"""词法分析器(也说成扫描器或者标记器)
该方法负责把一个句子分成若干个标记。每次处理一个标记
"""
text = self.text
# self.pos 索引到达了 self.text 的末尾吗?
# 如果到了,就返回 EOF 标记,因为没有更多的
# 能转换成标记的输入了
if self.pos > len(text) - 1:
return Token(EOF, None)
# 从 self.pos 位置获取当前的字符,
# 基于单个字符判断要生成哪种标记
current_char = text[self.pos]
# 如果字符是一个数字,就把他转换成一个整数,生成一个 INTEGER # 标记,累加 self.pos 索引,指向数字后面的下一个字符,
# 并返回 INTEGER 标记
if current_char.isdigit():
token = Token(INTEGER, int(current_char))
self.pos += 1
return token
if current_char == '+':
token = Token(PLUS, current_char)
self.pos += 1
return token
self.error()
def eat(self, token_type):
# 将当前的标记类型与传入的标记类型作比较,如果他们相匹配,就
# “eat” 掉当前的标记并将下一个标记赋给 self.current_token,
# 否则抛出一个异常
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""expr -> INTEGER PLUS INTEGER"""
# 将输入中的第一个标记设置成当前标记
self.current_token = self.get_next_token()
# 我们期望当前标记是个位数。
left = self.current_token
self.eat(INTEGER)
# 期望当前标记是 ‘+’ 号
op = self.current_token
self.eat(PLUS)
# 我们期望当前标记是个位数。
right = self.current_token
self.eat(INTEGER)
# 上述操作完成后,self.current_token 被设成 EOF 标记
# 这时成功找到 INTEGER PLUS INTEGER 标记序列
# 这个方法就可以返回两个整数相加的结果了,
# 即高效的解释了用户输入
result = left.value + right.value
return result
def main():
while True:
try:
# 要在 Python3 下运行,请把 ‘raw_input’ 换成 ‘input’
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
把上面的代码保存到 calc1.py 文件,或者直接从 GitHub 上下载。在你深入研究代码前,在命令行里面运行它看看效果。试一试!这是我笔记本上的示例会话(如果你想在 Python3 下运行,你要把 raw_input 换成 input):
$ python calc1.py
calc> 3+4
7
calc> 3+5
8
calc> 3+9
12
calc>
要让你的简易计算器正常工作,不抛出异常,你的输入要遵守以下几个规则:
- 只允许输入个位数
- 此时支持的唯一一个运算符是加法
- 输入中不允许有任何的空格符号
要让计算器变得简单,这些限制非常必要。不用担心,你很快就会让它变得很复杂。
好,现在让我们深入它,看看解释器是怎么工作,它是怎么评估出算术表达式的。
当你在命令行中输入一个表达式 3+5,解释器就获得了字符串 “3+5”。为了让解释器能够真正理解要用这个字符串做什么,它首先要把输入 “3+5” 分到叫做 token(标记)的容器里。 标记 是一个拥有类型和值的对象。比如说,对字符 “3” 而言,标记的类型是 INTEGER 整数,对应的值是 3。
把输入字符串分成标记的过程叫 词法分析 。因此解释器的需要做的第一步是读取输入字符,并将其转换成标记流。解释器中的这一部分叫做 词法分析器 ,或者简短点叫 lexer。你也可以给它起别的名字,诸如 扫描器 或者 标记器 。它们指的都是同一个东西:解释器或编译器中将输入字符转换成标记流的那部分。
Interpreter 类中的 get_next_token 方法就是词法分析器。每次调用它的时候,你都能从传入解释器的输入字符中获得创建的下一个标记。仔细看看这个方法,看看它是如何完成把字符转换成标记的任务的。输入被存在可变文本中,它保存了输入的字符串和关于该字符串的索引(把字符串想象成字符数组)。pos 开始时设为 0,指向字符 ‘3’。这个方法一开始检查字符是不是数字,如果是,就将 pos 加 1,并返回一个 INTEGER 类型的标记实例,并把字符 ‘3’ 的值设为整数,也就是整数 3:

现在 pos 指向文本中的 ‘+’ 号。下次调用这个方法的时候,它会测试 pos 位置的字符是不是个数字,然后检测下一个字符是不是个加号,就是这样。结果这个方法把 pos 加 1,返回一个新创建的标记,类型是 PLUS,值为 ‘+’。
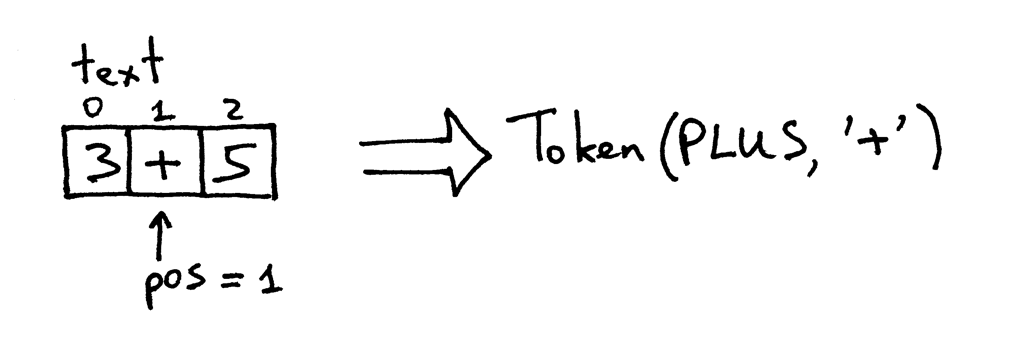
pos 现在指向字符 ‘5’。当你再调用 get_next_token 方法时,该方法会检查这是不是个数字,就是这样,然后它把 pos 加 1,返回一个新的 INTEGER 标记,该标记的值被设为整数 5:

因为 pos 索引现在到了字符串 “3+5” 的末尾,你每次调用 get_next_token 方法时,它将会返回 EOF 标记:
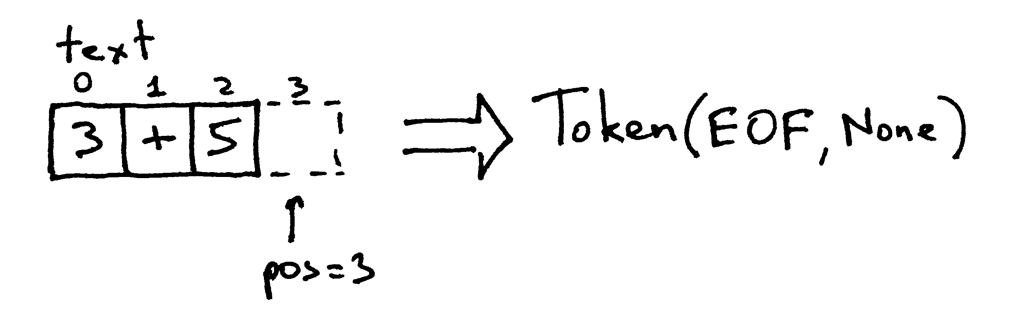
自己试一试,看看计算器里的词法分析器的运行:
>>> from calc1 import Interpreter
>>>
>>> interpreter = Interpreter('3+5')
>>> interpreter.get_next_token()
Token(INTEGER, 3)
>>>
>>> interpreter.get_next_token()
Token(PLUS, '+')
>>>
>>> interpreter.get_next_token()
Token(INTEGER, 5)
>>>
>>> interpreter.get_next_token()
Token(EOF, None)
>>>
既然你的解释器能够从输入字符中获取标记流,解释器需要对它做点什么:它需要在词法分析器 get_next_token 中获取的标记流中找出相应的结构。你的解释器应该能够找到流中的结构:INTEGER -> PLUS -> INTEGER。就是这样,它尝试找出标记的序列:整数后面要跟着加号,加号后面要跟着整数。
负责找出并解释结构的方法就是 expr。该方法检验标记序列确实与期望的标记序列是对应的,比如 INTEGER -> PLUS -> INTEGER。成功确认了这个结构后,就会生成加号左右两边的标记的值相加的结果,这样就成功解释你输入到解释器中的算术表达式了。
expr 方法用了一个助手方法 eat 来检验传入的标记类型是否与当前的标记类型相匹配。在匹配到传入的标记类型后,eat 方法会获取下一个标记,并将其赋给 current_token 变量,然后高效地 “吃掉” 当前匹配的标记,并将标记流的虚拟指针向后移动。如果标记流的结构与期望的 INTEGER -> PLUS -> INTEGER 标记序列不对应,eat 方法就抛出一个异常。
让我们回顾下解释器做了什么来对算术表达式进行评估的:
- 解释器接受输入字符串,比如说 “3+5”
- 解释器调用
expr 方法,在词法分析器 get_next_token 返回的标记流中找出结构。这个结构就是 INTEGER -> PLUS -> INTEGER 这样的格式。在确认了格式后,它就通过把两个整型标记相加来解释输入,因为此时对于解释器来说很清楚,它要做的就是把两个整数 3 和 5 进行相加。
恭喜。你刚刚学习了怎么构建自己的第一个解释器!
现在是时候做练习了。

看了这篇文章,你肯定觉得不够,是吗?好,准备好做这些练习:
- 修改代码,允许输入多位数,比如 “12+3”
- 添加一个方法忽略空格符,让你的计算器能够处理带有空白的输入,比如 “12 + 3”
- 修改代码,用 ‘-’ 号而非 ‘+’ 号去执行减法比如 “7-5”
检验你的理解
- 什么是解释器?
- 什么是编译器
- 解释器和编译器有什么差别?
- 什么是标记?
- 将输入分隔成若干个标记的过程叫什么?
- 解释器中进行词法分析的部分叫什么?
- 解释器或编译器中进行词法分析的部分有哪些其他的常见名字?
在结束本文前,我衷心希望你能留下学习解释器和编译器的承诺。并且现在就开始做。不要把它留到以后。不要拖延。如果你已经看完了本文,就开始吧。如果已经仔细看完了但是还没做什么练习 —— 现在就开始做吧。如果已经开始做练习了,那就把剩下的做完。你懂得。而且你知道吗?签下承诺书,今天就开始学习解释器和编译器!
本人, \_\_\_\_\_\_,身体健全,思想正常,在此承诺从今天开始学习解释器和编译器,直到我百分百了解它们是怎么工作的!
签字人:
日期:

签字,写上日期,把它放在你每天都能看到的地方,确保你能坚守承诺。谨记你的承诺:
“承诺就是,你说自己会去做的事,在你说完就一直陪着你的东西。” —— Darren Hardy
好,今天的就结束了。这个系列的下一篇文章里,你将会扩展自己的计算器,让它能够处理更复杂的算术表达式。敬请期待。
via: https://ruslanspivak.com/lsbasi-part1/
作者:Ruslan Spivak 译者:BriFuture 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出

















