ABC 时代 GPL 许可证传染性问题探讨
2017 年 11 月 18 日至 19 日,2017 中国开源年会在上海交大召开,来自集慧智佳的高级咨询师薛亮在开源治理分论坛上发表了题为《ABC 时代 GPL 许可证传染性问题探讨》的演讲,现将演讲的内容进行整理和补充,以飨读者。

我们目前所处的时代被称为“ABC(AI、Big Data、Cloud)时代”,也是大量采用开源软件的时代。在这个过程中,不可避免地会遇到开源软件合规的问题,而其中最让人感到困惑的,可以说就是 GPL 许可证传染性问题。那么 GPL 软件是不是真的像传说中的避之唯恐不及,其传染性风险令人谈之色变呢?本次演讲和大家简要探讨一下 GPL 传染性问题。

演讲内容主要包括四个部分,第一部分为“从合规到牟利”,简要介绍目前开源软件合规环境的变化情况。第二部分为“ GPL 传染性判断”,介绍从实务角度考虑,GPL 传染性判断的流程、方法和原则。第三部分为“MongoDB 案例”,介绍了采用 AGPL 许可证的 MongoDB 案例。第四部分为“开源智慧专栏”,简单介绍集慧智佳与 Linux 中国合作开办的“开源智慧专栏”。

第一部分题目为“从合规到牟利”,介绍了近些年开源软件合规和诉讼态势发生的变化,已经从单纯的“寻求合规”转变为“追求牟利”,而这种变化使得开源软件用户的合规风险变得越来越严重。

以最为严格的 GPL 许可证来说,自由软件基金会和自由软件管理机构是全球推行 GPL 许可的主要机构,其追求的主要目标之一是实现 GPL 的合规,对于那些在无意中违反 GPL 许可证的行为,本着“惩前毖后,治病救人”的原则,大多数还是以教育和帮助为主,并不会刻意追求罚款、赔偿等。

但是,随着开源软件合规和诉讼生态的发展,涌现了更多类型的新玩家。根据国外律师的观察,除了诸如 SFLC、SFC 等传统的合规机构之外,近年来出现了比较激进的例如 McHardy 这样的 版权流氓 ,或者说是 GPL 牟利者,其主要目标已经从合规转变为牟利,要求对违规行为颁发禁令或进行赔偿。
根据“开源智慧专栏”发表的翻译文章《如何应对开源软件的版权牟利者? 开源律师说这样做!》,GPL 牟利者 McHardy 已经骚扰了 50 多个目标,据说有些国内企业也在其中。
面对越来越复杂的开源软件合规态势,作为开源软件用户来说,对于许可证合规问题,需要引起重视,而 GPL 传染性显然是其中最让人头疼的问题。

第二部分我们具体探讨一下“GPL 传染性判断”,主要是根据我们的研究和实务经验,对于如何评估和判断GPL软件的传染性进行梳理和总结。
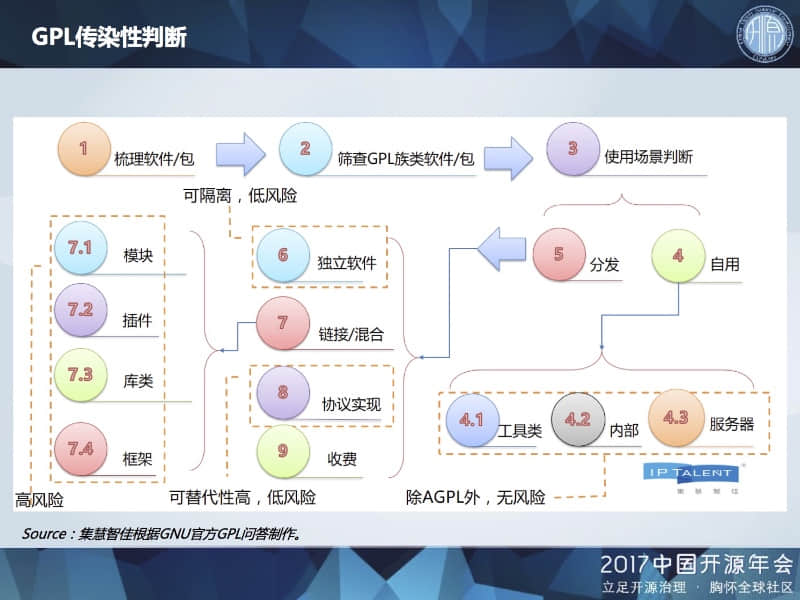
对于软件企业的技术人员来说,开源代码是否好用,是他们选用开源代码的重要标准之一,而不会过多考虑许可证问题。但对于企业的合规和法律部门来说,自己企业的技术人员使用了哪些开源软件,这些开源软件采用哪些许可证,则是需要进行排查和梳理,做到心中有数。而对于采用 GPL 许可证的软件,为了避免传染性,是不是必须简单地“一刀切”,绝对禁止使用呢?
我们认为,根据 GPL 软件类型和使用场景的不同,其传染性风险也存在不同。其中一个关键的分界点,在于自用与分发。
自用的范畴比较广泛,在公司个人、部门使用,甚至在公司内部分发,都可以自由使用。
对于编译器、解释器等工具类软件,其主要作用是对代码进行加工,可以归为自用的范畴,但也要区分 GPL 工具类软件是否将自身代码混进其所加工的代码。例如 GCC 是 GPL 编译器,但使用 GCC 不会感染被编译的源文件。
对于采用 GPL、LGPL 许可证的软件,如果放在服务器/云上以 SaaS 方式对外提供服务,也可以算作自用的范畴。但是,采用 AGPL 许可证的软件除外,AGPL 专门针对 SaaS 方式进行约束。
我们接着再来看分发,对于一些必须分发出去的 GPL 软件,其类型也有多种。对于一些相对独立的软件,需要注意与自有代码是各自独立还是复杂的糅合,是否构成了结合作品。对于诸如 MQTT 等协议实现类的软件,其实现方式有多种,可以选择采用宽松许可证的开源软件。许多开源软件也采用双重授权,如果担心开源版本的风险问题,可以选择花钱购买其商业授权版本。
对于自有代码与 GPL 软件的链接/混合,也分几种情况。例如对于自有模块 A 和 GPL 模块 B,需要根据两者之间的通信亲密程度以及传输数据的复杂程度,判断两者是否构成了结合作品。对于 GPL 插件,需要分析自有代码主程序对其调用的方式,判断是否造成传染。
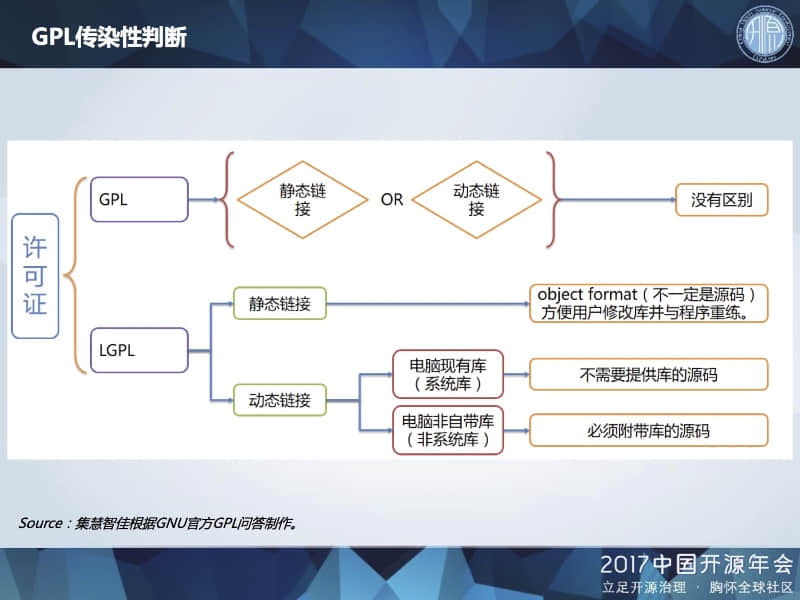
对于自有代码与 GPL 库的链接,根据 GPL 许可证,无论是采用静态链接或动态链接方式,都会造成自有代码被传染,必须进行公开。而之后发表的 LGPL 许可证,则对 GPL 库的链接稍微放松了限制。由于 LGPL 专门针对库而制定,采用 LGPL 的库相对来说应该已经考虑了对调用程序的影响,更容易避免被“传染”。
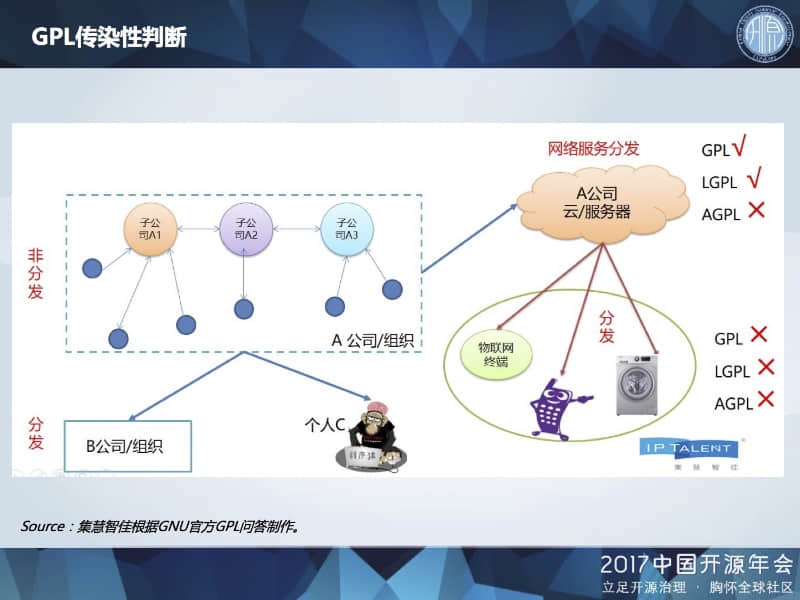
我们再来看一下“自用”,GNU 官方问答对于自用的解释非常宽泛,在一个企业集团的总公司、分公司、子公司等使用,都可以算作自用的范畴,不构成分发。
对于采用 GPL、LGPL 许可证的软件,如果放在服务器/云上以 SaaS 方式对外提供服务,不构成分发,但如果将其部署在用户终端上,则构成分发,带来传染性问题。
对于采用 AGPL 许可证的软件,即便是运行在服务器/云上,如果后续用户对其源代码进行了修改,也必须将修改版本发布出来。
需要注意的是,某个GPL软件的使用场景如果发生变化,之前对其传染性风险的判断也有可能变化,需要根据新的使用场景重新评估。

第三部分我们来看一个案例,MongoDB 是一个非常典型的使用 AGPL 许可证的开源软件。国外有文章甚至开玩笑说,正是因为有了 MongoDB,人们对 AGPL 许可证的看法有了明显改变,从 “never use AGPL” 转变成 “never use AGPL except for Mongo DB”。

具体看一下 MongoDB 的许可政策。MongoDB 的数据库部分采用严格的 AGPL v3.0 许可证,并且是双重许可,用户既可以选择开源版本,也可以选择商业授权版本。MongoDB 的驱动部分则采用宽松的 Apache v2.0 许可证。

通过对数据库和驱动分别适用不同的许可证,MongoDB 在坚守其自由软件本质的同时,也为用户大开方便之门。
其中需要注意,如果用户修改了 MongoDB 核心数据库的源代码,则必须将修改版本发布出来,回馈给社区。
反之,如果用户的程序仅是使用 MongoDB 数据库,没有对数据库源代码进行修改,则不必发布该用户程序。Copyleft 仅适用于 mongod 和 mongos 数据库,而驱动则采用 Apache 许可证,所以用户的程序如果通过 MongoDB 官方推荐的驱动与数据库进行交互,也不被视为 AGPL 范畴下的结合作品,而是单独的程序或作品,无需担心被传染。
从 MongoDB 这个案例可以看出,一些开源软件的著作权人为了保护和推广自己的开源项目,可以说是“煞费苦心”,绞尽脑汁地在许可证方面进行精巧的设计,给出一些“例外声明”,为用户“开后门”,让用户可以相对比较放心地使用,推动了这些开源软件的迅速普及。

“开源智慧专栏”由集慧智佳与国内领先的开源社区 Linux 中国合作创办,聚焦开源软件的知识产权问题,旨在传播域外动态,梳理经典判例,翻译重要文本,关注行业热点,分享实务经验。
在第三部分简要介绍了 GPL 传染性判断的方法和原则,其主要依据是自由软件基金会发布的 GPL 许可证官方问答。我们也对这个问题进行了翻译,陆续发表在本专栏中。此外,对于此前闹得沸沸扬扬的 Facebook 公司 react 许可证事件,我们也进行了实时的跟踪和解读。

以上所列为本专栏从创办至今所发表的文章列表,大家可以登录 Linux 中国的“开源智慧专栏”查看,或者扫描关注微信公众号,接收实时推送的相关文章。

最后,简单介绍一下我本人。我所供职的单位——集慧智佳是中国第一家在新三板挂牌(838286)的知识产权咨询公司,对开源知识产权问题一直进行持续的跟踪和研究,曾承担国家级的开源知识产权研究课题,并为国内知名的互联网软件企业提供开源知识产权风险排查服务。
我在集慧智佳互联网事业部担任高级咨询师,擅长专利检索、专利分析、专利布局、竞争对手跟踪、FTO 调查、开源软件知识产权风险分析;长期为联想、中国移动、海尔、东软等互联网企业、高科技公司提供知识产权咨询服务;担任“开源智慧专栏”主要撰稿人。
- 2017 年 10 月 14 日,在 GNOME 2017 亚洲峰会上发表题为《开源软件的知识产权风险》演讲。
- 2017 年 11 月 18 日,在 2017 中国开源年会上发表题为《ABC 时代 GPL 许可证传染性问题探讨》演讲(PDF)。
欢迎大家围绕开源软件知识产权问题与我进行交流!