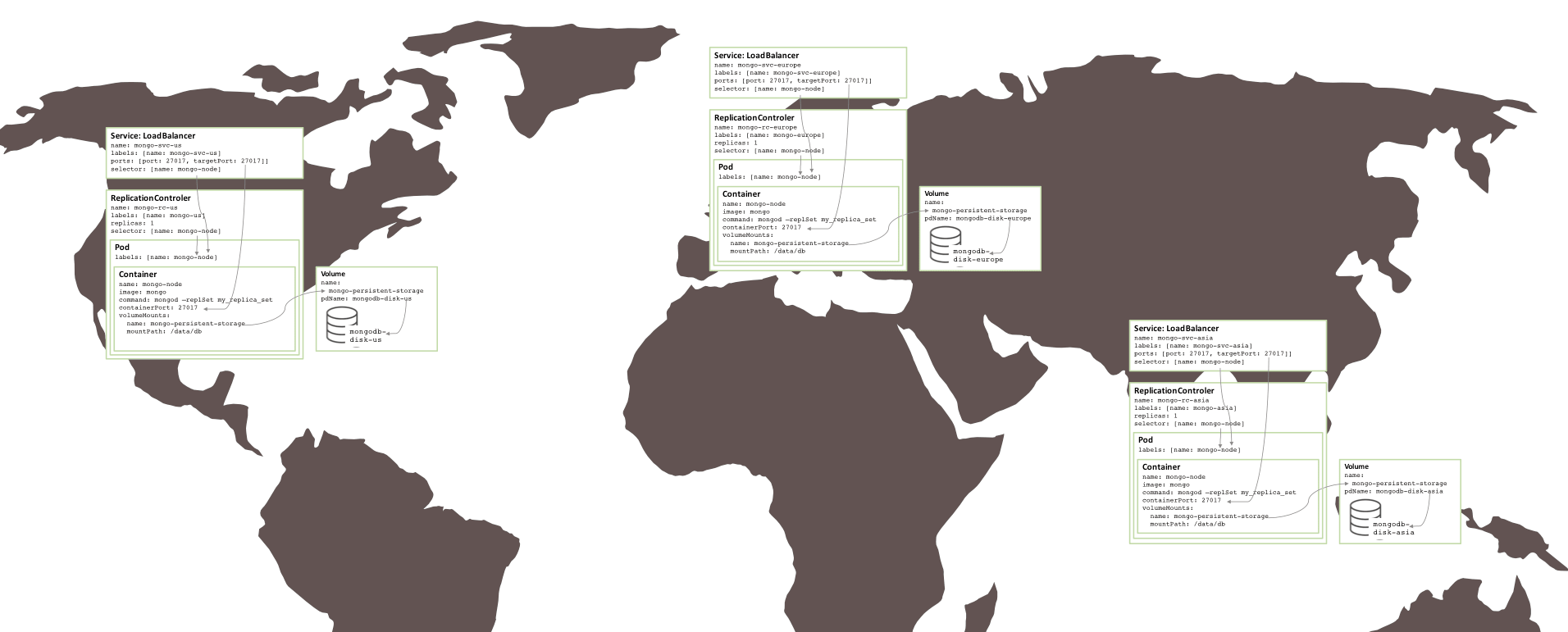
Sublime Text 3.0 正式发布!提供 Linux 软件包仓库支持
历经了 4 年半的开发,著名的 Sublime Text 编辑器的作者 Jon Skinner 宣布:Sublime Text 3.0 正式版终于发布了!
与上一个 beta 版本相比,3.0 带来了崭新的 UI 主题,新的颜色主题以及新的图标。此外,在格式高亮方面有较大改进,也支持 Windows 上的触摸板输入、支持 macOS 的 Touch Bar,以及为 Linux 提供了软件包仓库支持!
相对于 Sublime Text 2 而言,几乎在这个编辑器的每一个方面都有所变化,所以即便是主要变更列表也显得太长了,具体你可以关注下这个页面,希望你有耐心读完。
在 3.0 当中一些大的功能有:定义跳转、新的格式高亮引擎、新的用户界面和丰富的 API。在数百个改进当中,拼写检查得到了改进,自动缩进也更完善,自动换行能也更好的处理源代码,对高分屏支持更好,任意跳转也更加智能。
在 Sublime Text 3 中最令人骄傲的一点是性能:它比历史上发布过的任何一个 Sublime Text 2 版本都要快得多,启动快、打开文件快、甚至内容滚动都快。虽然它的体积比 2 要大,但是却更轻快。
下载地址
- OS X (要求 10.7 及以上)
- Windows,也提供便携版
- Windows 64 bit,也提供便携版
- Linux 软件仓库 及 64 位 或 32 位 tarball
在 Windows 和 OS X 平台上,Sublime Text 3 提供了自动更新机制,而针对 Linux 的各个发行版,Sublime Text 3 提供了软件仓库,通过它支持自动更新。
在 Linux 上安装
apt
安装 GPG 公钥:
wget -qO - https://download.sublimetext.com/sublimehq-pub.gpg | sudo apt-key add -
选择使用的频道:
Stable
echo "deb https://download.sublimetext.com/ apt/stable/" | sudo tee /etc/apt/sources.list.d/sublime-text.list
Dev
echo "deb https://download.sublimetext.com/ apt/dev/" | sudo tee /etc/apt/sources.list.d/sublime-text.list
更新 apt 源并安装 Sublime Text:
sudo apt-get update
sudo apt-get install sublime-text
pacman
安装 GPG 公钥:
curl -O https://download.sublimetext.com/sublimehq-pub.gpg && sudo pacman-key --add sublimehq-pub.gpg && sudo pacman-key --lsign-key 8A8F901A && rm sublimehq-pub.gpg
选择要使用的频道:
Stable
echo -e "\n[sublime-text]\nServer = https://download.sublimetext.com/arch/stable/x86_64" | sudo tee -a /etc/pacman.conf
Dev
echo -e "\n[sublime-text]\nServer = https://download.sublimetext.com/arch/dev/x86_64" | sudo tee -a /etc/pacman.conf
更新 pacman 并安装 Sublime Text:
sudo pacman -Syu sublime-text
yum
安装 GPG 公钥:
sudo rpm -v --import https://download.sublimetext.com/sublimehq-rpm-pub.gpg
选择要使用的频道:
Stable
sudo yum-config-manager --add-repo https://download.sublimetext.com/rpm/stable/x86_64/sublime-text.repo
Dev
sudo yum-config-manager --add-repo https://download.sublimetext.com/rpm/dev/x86_64/sublime-text.repo
更新 yum 并安装 Sublime Text:
sudo yum install sublime-text
dnf
安装 GPG 公钥:
sudo rpm -v --import https://download.sublimetext.com/sublimehq-rpm-pub.gpg
选择要使用的频道:
Stable
sudo dnf config-manager --add-repo https://download.sublimetext.com/rpm/stable/x86_64/sublime-text.repo
Dev
sudo dnf config-manager --add-repo https://download.sublimetext.com/rpm/dev/x86_64/sublime-text.repo
更新 dnf 并安装 Sublime Text:
sudo dnf install sublime-text
zypper
安装 GPG 公钥:
sudo rpm -v --import https://download.sublimetext.com/sublimehq-rpm-pub.gpg
选择要使用的频道:
Stable
sudo zypper addrepo -g -f https://download.sublimetext.com/rpm/stable/x86_64/sublime-text.repo
Dev
sudo zypper addrepo -g -f https://download.sublimetext.com/rpm/dev/x86_64/sublime-text.repo
更新zypper 并安装 Sublime Text:
sudo zypper install sublime-text购买
需要说明的是,Sublime Text 不是自由软件,也不是免费软件,而是试用软件,虽然你可以一直试用下去,但是其是需要购买的。单个许可证的费用是 $80 美金。