安卓编年史(19):Android 4.0 冰淇淋三明治—摩登时代


和之前完全不同的市场设计。以上是分类,特色,热门应用以及应用详情页面。 [Ron Amadeo 供图]
这些截图给了我们冰淇淋三明治中新版操作栏的第一印象。几乎所有的应用顶部都有一条栏,带有应用图标,当前界面标题,一些功能按钮,右边还有一个菜单按钮。这个右对齐的菜单按钮被称为“更多操作”,因为里面存放着无法放置到主操作栏的项目。不过更多操作菜单并不是固定不变的,它给了操作栏节省了更多的屏幕空间——比如在横屏模式或在平板上时,更多操作菜单的项目会像通常的按钮一样显示在操作栏上。
冰淇凌三明治中新增了“滑动标签页”设计,替换掉了谷歌之前推行的 2×3 方阵导航屏幕。一个标签页栏放置在了操作栏下方,位于中间的标签显示的是当前页面,左右侧的两个标签显示的是对应的当前页面的左右侧页面。向左右滑动可以切换标签页,或者你可以点击指定页面的标签跳转过去。
应用详情页面有个很赞的设计,在应用截图后,会根据你关于那个应用的历史动态地重新布局页面。如果你从来没有安装过该应用,应用描述会优先显示。如果你曾安装过这个应用,第一部分将会是评价栏,它会邀请你评价该应用或者提醒你上次你安装该应用时的评价是什么。之前使用过的应用页面第二部分是“新特性”,因为一个老用户最关心的应该是应用有什么变化。

最近应用和浏览器和蜂巢中的类似,但是是小号的。 [Ron Amadeo 供图]
最近应用的电子风格外观被移除了。略缩图周围的蓝色的轮廓线被去除了,同时去除的还有背景怪异的、不均匀的蓝色光晕。它现在看起来是个中立型的界面,在任何时候看起来都很舒适。
浏览器尽了最大的努力把标签页体验带到手机上来。多标签浏览受到了关注,操作栏上引入的一个标签页按钮会打开一个类似最近应用的界面,显示你打开的标签页,而不是浪费宝贵的屏幕空间引入一个标签条。从功能上来说,这个和之前的浏览器中的“窗口”视图没什么差别。浏览器最佳的改进是菜单中的“请求桌面版站点”选项,这让你可以从默认的移动站点视图切换到正常站点。浏览器展示了谷歌的操作栏设计的灵活性,尽管这里没有左上角的应用图标,功能上来说和其他的顶栏设计相似。

Gmail 和 Google Talk —— 它们和蜂巢中的相似,但是更小! [Ron Amadeo 供图]
Gmail 和 Google Talk 看起来都像是之前蜂巢中的设计的缩小版,但是有些小调整让它们在小屏幕上表现更佳。Gmail 以双操作栏为特色——一个在屏幕顶部,一个在底部。顶部操作栏显示当前文件夹、账户,以及未读消息数目,点击顶栏可以打开一个导航菜单。底部操作栏有你期望出现在更多操作中的选项。使用双操作栏布局是为了在界面显示更多的按钮,但是在横屏模式下纵向空间有限,双操作栏就合并成一个顶部操作栏。
在邮件视图下,往下滚动屏幕时蓝色栏有“粘性”。它会固定在屏幕顶部,所以你一直可以看到该邮件是谁写的,回复它,或者给它加星标。一旦处于邮件消息界面,底部细长的、深灰色栏会显示你当前在收件箱(或你所在的某个列表)的位置,并且你可以向左或向右滑动来切换到其他邮件。
Google Talk 允许你像在 Gmail 中那样左右滑动来切换聊天窗口,但是这里显示栏是在顶部。

新的拨号和来电界面,都是姜饼以来我们还没见过的。 [Ron Amadeo 供图]
因为蜂巢只给平板使用,所以一些界面设计直接超前于姜饼。冰淇淋三明治的新拨号界面就是如此,黑色和蓝色相间,并且使用了可滑动切换的小标签。尽管冰淇淋三明治终于做对了,将电话主体和联系人独立开来,但电话应用还是有它自己的联系人标签。现在有两个地方可以看到你的联系人列表——一个有着暗色主题,另一个有着亮色主题。由于实体搜索按钮不再是硬性要求,底部的按钮栏的语音信息快捷方式被替换为了搜索图标。
谷歌几乎就是把来电界面做成了锁屏界面的镜像,这意味着冰淇淋三明治有着一个环状解锁设计。除了通常的接受和挂断选项,圆环的顶部还添加了一个按钮,让你可以挂断来电并给对方发送一条预先定义好的信息。向上滑动并选择一条信息如“现在无法接听,一会回电”,相比于一直响个不停的手机而言这样做的信息交流更加丰富。

蜂巢没有文件夹和信息应用,所以这里是冰淇淋三明治和姜饼的对比。 [Ron Amadeo 供图]
现在创建文件夹更加方便了。在姜饼中,你得长按屏幕,选择“文件夹”选项,再点击“新文件夹”。在冰淇淋三明治中,你只要将一个图标拖拽到另一个图标上面,就会自动创建一个文件夹,并包含这两个图标。这简直不能更简单了,比寻找隐藏的长按命令容易多了。
设计上也有很大的改进。姜饼使用了一个通用的米黄色文件夹图标,但冰淇淋三明治直接显示出了文件夹中的头三个应用,把它们的图标叠在一起,在外侧画一个圆圈,并将其设置为文件夹图标。打开文件夹容器将自动调整大小以适应文件夹中的应用图标数目,而不是显示一个全屏的,大部分都是空的对话框。这看起来好得多得多。

Youtube 转换到一个更加现代的白色主题,使用了列表视图替换疯狂的 3D 滚动视图。 [Ron Amadeo 供图]
Youtube 经过了完全的重新设计,看起来没那么像是来自黑客帝国的产物,更像是,嗯,Youtube。它现在就是一个简单的垂直滚动的白色视频列表,就像网站的那样。在你手机上制作视频受到了重视,操作栏的第一个按钮专用于拍摄视频。奇怪的是,不同的界面左上角使用了不同的 Youtube 标志,在水平的 Youtube 标志和方形标志之间切换。
Youtube 几乎在所有地方都使用了滑动标签页。它们被放置在主页面以在浏览和账户间切换,放置在视频页面以在评论,介绍和相关视频之间切换。4.0 版本的应用显示出 Google+ Youtube 集成的第一个信号,通常的评分按钮旁边放置了 “+1” 图标。最终 Google+ 会完全占据 Youtube,将评论和作者页面变成 Google+ 活动。
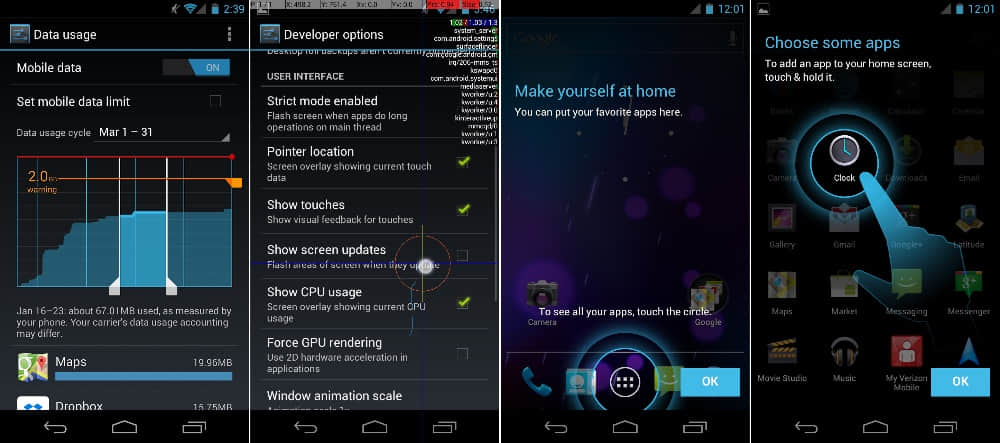
冰淇淋三明治试着让事情对所有人都更加简单。这里是数据使用量追踪,打开许多数据的新开发者选项,以及使用向导。 [Ron Amadeo 供图]
数据使用量允许用户更轻松地追踪和控制他们的数据使用。主页面显示一个月度使用量图表,用户可以设置数据使用警告值或者硬性使用限制以避免超量使用产生费用。所有的这些只需简单地拖动橙色和红色水平限制线在图表上的位置即可。纵向的白色把手允许用户选择图表上的一段指定时间段。在页面底部,选定时间段内的数据使用量又细分到每个应用,所以用户可以选择一个数据使用高峰并轻松地查看哪个应用在消耗大量流量。当流量紧张的时候,更多操作按钮中有个限制所有后台流量的选项。设置之后只用在前台运行的程序有权连接互联网。
开发者选项通常只有一点点设置选项,但是在冰淇淋三明治中,这部分有非常多选项。谷歌添加了所有类型的屏幕诊断显示浮层来帮助开发者理解他们的应用中发生了什么。你可以看到 CPU 使用率,触摸点位置,还有视图界面更新。还有些选项可以更改系统功能,比如控制动画速度,后台处理,以及 GPU 渲染。
安卓和 iOS 之间最大的区别之一就是应用抽屉界面。在冰淇淋三明治对更加用户友好的追求下,设备第一次初始化启动会启动一个小教程,向用户展示应用抽屉的位置以及如何将应用图标从应用抽屉拖拽到主屏幕。随着实体菜单按键的移除和像这样的改变,安卓 4.0 做了很大的努力变得对新智能手机用户和转换过来的用户更有吸引力。
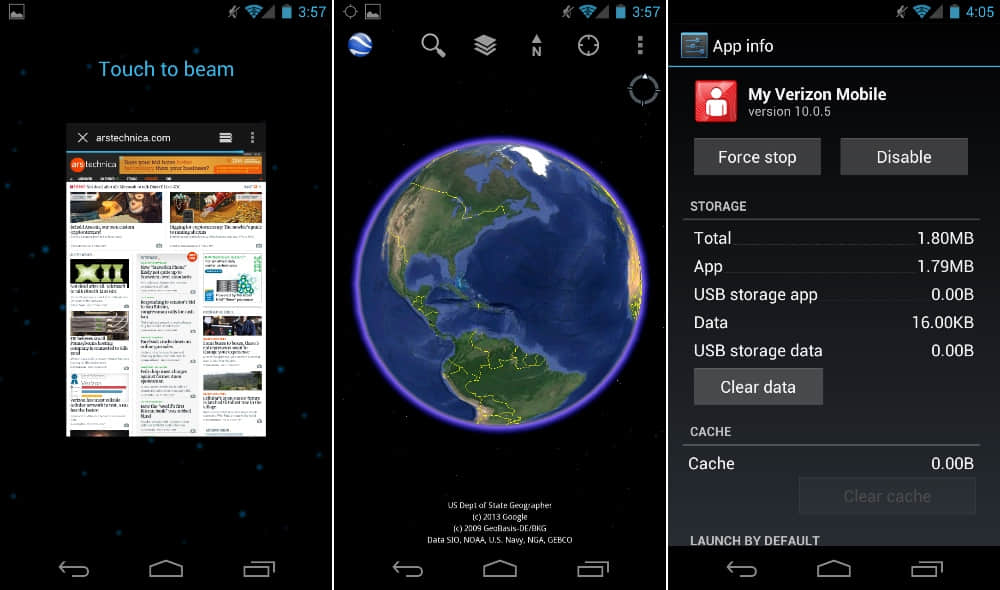
“触摸分享”NFC 支持,Google Earth,以及应用信息,让你可以禁用垃圾软件。
冰淇淋三明治内置对 NFC 的完整支持。尽管之前的设备,比如 Nexus S 也拥有 NFC,得到的支持是有限的并且系统并不能利用芯片做太多事情。4.0 添加了一个“Android Beam”功能,两台拥有 NFC 的安卓 4.0 设备可以借此在设备间来回传输数据。NFC 会传输关于此时屏幕显示的数据,因此在手机显示一个网页的时候使用该功能会将该页面传送给另一部手机。你还可以发送联系人信息、方向导航,以及 Youtube 链接。当两台手机放在一起时,屏幕显示会缩小,点击缩小的界面会发送相关信息。
在安卓中,用户不允许删除系统应用,以保证系统完整性。运营商和 OEM 利用该特性并开始将垃圾软件放入系统分区,经常有一些没用的应用存在系统中。安卓 4.0 允许用户禁用任何不能被卸载的应用,意味着该应用还存在于系统中但是不显示在应用抽屉里并且不能运行。如果用户愿意深究设置项,这给了他们一个简单的途径来拿回手机的控制权。
安卓 4.0 可以看做是现代安卓时代的开始。大部分这时发布的谷歌应用只能在安卓 4.0 及以上版本运行。4.0 还有许多谷歌想要好好利用的新 API——至少最初想要——对 4.0 以下的版本的支持就有限了。在冰淇淋三明治和蜂巢之后,谷歌真的开始认真对待软件设计。在 2012 年 1 月,谷歌最终发布了 Android Design,一个教安卓开发者如何创建符合安卓外观和感觉的应用的设计指南站点。这是 iOS 在有第三方应用支持开始就在做的事情,苹果还严肃地对待应用的设计,不符合指南的应用都被 App Store 拒之门外。安卓三年以来谷歌没有给出任何公共设计规范文档的事实,足以说明事情有多糟糕。但随着在 Duarte 掌控下的安卓设计革命,谷歌终于发布了基本设计需求。
Google Play 和直接面向消费者出售设备的回归

2012 年 3 月 6 日,谷歌将旗下提供的所有内容统一到 “Google Play”。安卓市场变为了 Google Play 商店,Google Books 变为 Google Play Books,Google Music 变为 Google Play Music,还有 Android Market Movies 变为 Google Play Movies & TV。尽管应用界面的变化不是很大,这四个内容应用都获得了新的名称和图标。在 Play 商店购买的内容会下载到对应的应用中,Play 商店和 Play 内容应用一道给用户提供了易管理的内容体验。
Google Play 更新是谷歌第一个大的更新周期外更新。四个自带应用都没有通过系统更新获得升级,它们都是直接通过安卓市场/ Play 商店更新的。对单独的应用启用周期外更新是谷歌的重大关注点之一,而能够实现这样的更新,是自姜饼时代开始的工程努力的顶峰。谷歌一直致力于对应用从系统“解耦”,从而让它们能够通过安卓市场/ Play 商店进行分发。
尽管一两个应用(主要是地图和 Gmail)之前就在安卓市场上,从这里开始你会看到许多更重大的更新,而其和系统发布无关。系统更新需要 OEM 厂商和运营商的合作,所以很难保证推送到每个用户手上。而 Play 商店更新则完全掌握在谷歌手上,给了谷歌一条直接到达用户设备的途径。因为 Google Play 的发布,安卓市场对自身升级到了 Google Play Store,在那之后,图书,音乐以及电影应用都下发了 Google Play 式的更新。
Google Play 系列应用的设计仍然不尽相同。每个应用的外观和功能各有差异,但暂且来说,一个统一的品牌标识是个好的开始。从品牌标识中去除“安卓”字样是很有必要的,因为很多服务是在浏览器中提供的,不需要安卓设备也能使用。
2012 年 4 月,谷歌再次开始通过 Play 商店销售设备,恢复在 Nexus One 发布时尝试的直接面向消费者销售的方式。尽管距 Nexus One 销售结束仅有两年,但网上购物现在更加寻常,在接触到物品之前就购买它并不像在 2010 年时听起来那么疯狂。
谷歌也看到了价格敏感的用户在面对 Nexus One 的 530 美元的价格时的反应。第一部销售的设备是无锁的,GSM 版本的 Galaxy Nexus,价格 399 美元。在那之后,价格变得更低。350 美元成为了最近两台 Nexus 设备的入门价,7 英寸 Nexus 平板的价格更是只有 200 美元到 220 美元。
今天,Play 商店销售八款不同的安卓设备,四款 Chromebook,一款自动调温器,以及许多配件,设备商店已经是谷歌新产品发布的实际地点了。新产品发布总是如此受欢迎,站点往往无法承载如此大的流量,新 Nexus 手机也在几小时内售空。

Ron Amadeo / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。@RonAmadeo






