在没有 Kotlin 的世界与 Android 共舞

开始投入一件事比远离它更容易。 — Donald Rumsfeld
没有 Kotlin 的生活就像在触摸板上玩魔兽争霸 3。购买鼠标很简单,但如果你的新雇主不想让你在生产中使用 Kotlin,你该怎么办?
下面有一些选择。
- 与你的产品负责人争取获得使用 Kotlin 的权利。
- 使用 Kotlin 并且不告诉其他人因为你知道最好的东西是只适合你的。
- 擦掉你的眼泪,自豪地使用 Java。
想象一下,你在和产品负责人的斗争中失败,作为一个专业的工程师,你不能在没有同意的情况下私自去使用那些时髦的技术。我知道这听起来非常恐怖,特别当你已经品尝到 Kotlin 的好处时,不过不要失去生活的信念。
在文章接下来的部分,我想简短地描述一些 Kotlin 的特征,使你通过一些知名的工具和库,可以应用到你的 Android 里的 Java 代码中去。对于 Kotlin 和 Java 的基本认识是需要的。
数据类
我想你肯定已经喜欢上 Kotlin 的数据类。对于你来说,得到 equals()、 hashCode()、 toString() 和 copy() 这些是很容易的。具体来说,data 关键字还可以按照声明顺序生成对应于属性的 componentN() 函数。 它们用于解构声明。
data class Person(val name: String)
val (riddle) = Person("Peter")
println(riddle)
你知道什么会被打印出来吗?确实,它不会是从 Person 类的 toString() 返回的值。这是解构声明的作用,它赋值从 name 到 riddle。使用园括号 (riddle) 编译器知道它必须使用解构声明机制。
val (riddle): String = Person("Peter").component1()
println(riddle) // prints Peter)
这个代码没编译。它就是展示了构造声明怎么工作的。
正如你可以看到 data 关键字是一个超级有用的语言特性,所以你能做什么把它带到你的 Java 世界? 使用注释处理器并修改抽象语法树(Abstract Syntax Tree)。 如果你想更深入,请阅读文章末尾列出的文章(Project Lombok— Trick Explained)。
使用项目 Lombok 你可以实现 data关键字所提供的几乎相同的功能。 不幸的是,没有办法进行解构声明。
import lombok.Data;
@Data class Person {
final String name;
}
@Data 注解生成 equals()、hashCode() 和 toString()。 此外,它为所有字段创建 getter,为所有非最终字段创建setter,并为所有必填字段(final)创建构造函数。 值得注意的是,Lombok 仅用于编译,因此库代码不会添加到您的最终的 .apk。
Lambda 表达式
Android 工程师有一个非常艰难的生活,因为 Android 中缺乏 Java 8 的特性,而且其中之一是 lambda 表达式。 Lambda 是很棒的,因为它们为你减少了成吨的样板。 你可以在回调和流中使用它们。 在 Kotlin 中,lambda 表达式是内置的,它们看起来比它们在 Java 中看起来好多了。 此外,lambda 的字节码可以直接插入到调用方法的字节码中,因此方法计数不会增加。 它可以使用内联函数。
button.setOnClickListener { println("Hello World") }
最近 Google 宣布在 Android 中支持 Java 8 的特性,由于 Jack 编译器,你可以在你的代码中使用 lambda。还要提及的是,它们在 API 23 或者更低的级别都可用。
button.setOnClickListener(view -> System.out.println("Hello World!"));
怎样使用它们?就只用添加下面几行到你的 build.gradle 文件中。
defaultConfig {
jackOptions {
enabled true
}
}
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
如果你不喜欢用 Jack 编译器,或者你由于一些原因不能使用它,这里有一个不同的解决方案提供给你。Retrolambda 项目允许你在 Java 7,6 或者 5 上运行带有 lambda 表达式的 Java 8 代码,下面是设置过程。
dependencies {
classpath 'me.tatarka:gradle-retrolambda:3.4.0'
}
apply plugin: 'me.tatarka.retrolambda'
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
正如我前面提到的,在 Kotlin 下的 lambda 内联函数不增加方法计数,但是如何在 Jack 或者 Retrolambda 下使用它们呢? 显然,它们不是没成本的,隐藏的成本如下。
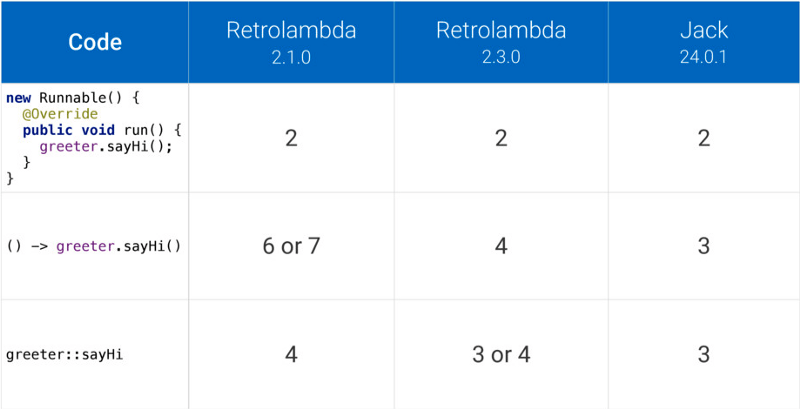
该表展示了使用不同版本的 Retrolambda 和 Jack 编译器生成的方法数量。该比较结果来自 Jake Wharton 的“探索 Java 的隐藏成本” 技术讨论之中。
数据操作
Kotlin 引入了高阶函数作为流的替代。 当您必须将一组数据转换为另一组数据或过滤集合时,它们非常有用。
fun foo(persons: MutableList<Person>) {
persons.filter { it.age >= 21 }
.filter { it.name.startsWith("P") }
.map { it.name }
.sorted()
.forEach(::println)
}
data class Person(val name: String, val age: Int)
流也由 Google 通过 Jack 编译器提供。 不幸的是,Jack 不使用 Lombok,因为它在编译代码时跳过生成中间的 .class 文件,而 Lombok 却依赖于这些文件。
void foo(List<Person> persons) {
persons.stream()
.filter(it -> it.getAge() >= 21)
.filter(it -> it.getName().startsWith("P"))
.map(Person::getName)
.sorted()
.forEach(System.out::println);
}
class Person {
final private String name;
final private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
String getName() { return name; }
int getAge() { return age; }
}
这简直太好了,所以 catch 在哪里? 令人悲伤的是,流从 API 24 才可用。谷歌做了好事,但哪个应用程序有用 minSdkVersion = 24?
幸运的是,Android 平台有一个很好的提供许多很棒的库的开源社区。Lightweight-Stream-API 就是其中的一个,它包含了 Java 7 及以下版本的基于迭代器的流实现。
import lombok.Data;
import com.annimon.stream.Stream;
void foo(List<Person> persons) {
Stream.of(persons)
.filter(it -> it.getAge() >= 21)
.filter(it -> it.getName().startsWith("P"))
.map(Person::getName)
.sorted()
.forEach(System.out::println);
}
@Data class Person {
final String name;
final int age;
}
上面的例子结合了 Lombok、Retrolambda 和 Lightweight-Stream-API,它看起来几乎和 Kotlin 一样棒。使用静态工厂方法允许您将任何 Iterable 转换为流,并对其应用 lambda,就像 Java 8 流一样。 将静态调用 Stream.of(persons) 包装为 Iterable 类型的扩展函数是完美的,但是 Java 不支持它。
扩展函数
扩展机制提供了向类添加功能而无需继承它的能力。 这个众所周知的概念非常适合 Android 世界,这就是 Kotlin 在该社区很受欢迎的原因。
有没有技术或魔术将扩展功能添加到你的 Java 工具箱? 因 Lombok,你可以使用它们作为一个实验功能。 根据 Lombok 文档的说明,他们想把它从实验状态移出,基本上没有什么变化的话很快。 让我们重构最后一个例子,并将 Stream.of(persons) 包装成扩展函数。
import lombok.Data;
import lombok.experimental.ExtensionMethod;
@ExtensionMethod(Streams.class)
public class Foo {
void foo(List<Person> persons) {
persons.toStream()
.filter(it -> it.getAge() >= 21)
.filter(it -> it.getName().startsWith("P"))
.map(Person::getName)
.sorted()
.forEach(System.out::println);
}
}
@Data class Person {
final String name;
final int age;
}
class Streams {
static <T> Stream<T> toStream(List<T> list) {
return Stream.of(list);
}
}
所有的方法是 public、static 的,并且至少有一个参数的类型不是原始的,因而是扩展方法。 @ExtensionMethod 注解允许你指定一个包含你的扩展函数的类。 你也可以传递数组,而不是使用一个 .class 对象。
我完全知道我的一些想法是非常有争议的,特别是 Lombok,我也知道,有很多的库,可以使你的生活更轻松。请不要犹豫在评论里分享你的经验。干杯!

作者简介:
Coder and professional dreamer @ Grid Dynamics
via: https://medium.com/proandroiddev/living-android-without-kotlin-db7391a2b170
作者:Piotr Ślesarew 译者:DockerChen 校对:wxy