序言
这篇教程将会教你怎么制作你的第一个 Atom 文本编辑器的插件。我们将会制作一个山寨版的 Sourcerer,这是一个从 StackOverflow 查询并使用代码片段的插件。到教程结束时,你将会制作好一个将编程问题(用英语描述的)转换成获取自 StackOverflow 的代码片段的插件,像这样:
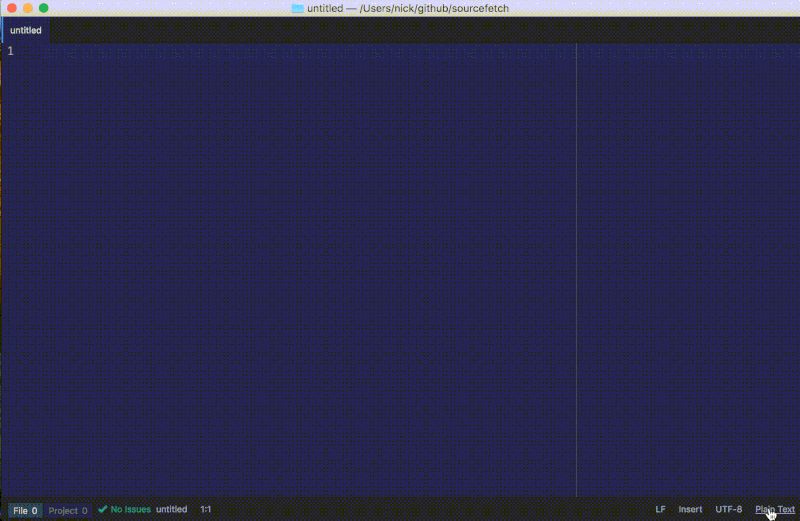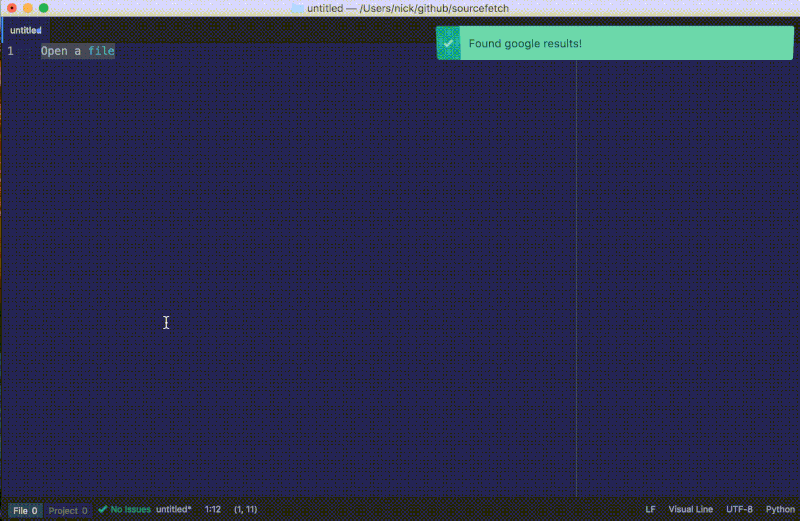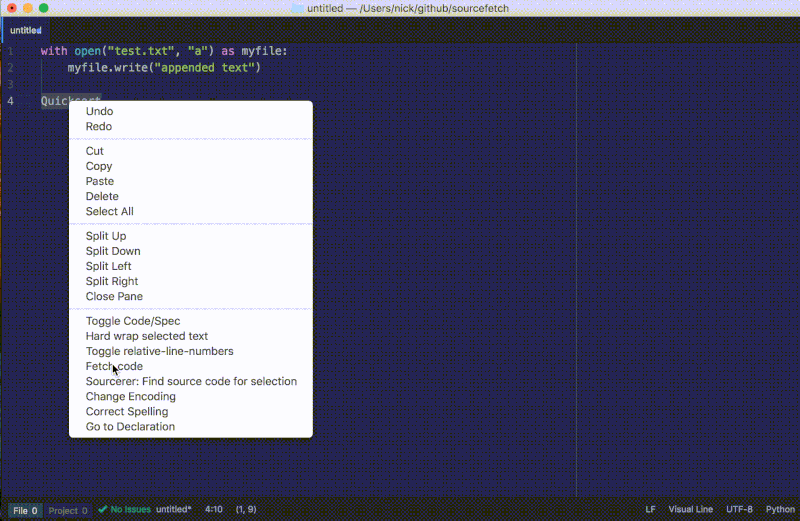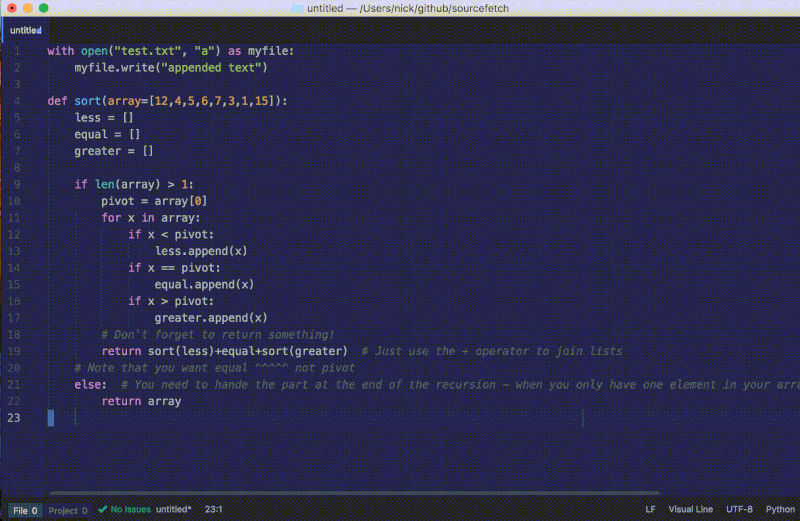
教程须知
Atom 文本编辑器是用 web 技术创造出来的。我们将完全使用 JavaScript 的 EcmaScript 6 规范来制作插件。你需要熟悉以下内容:
教程的仓库
你可以跟着教程一步一步走,或者看看 放在 GitHub 上的仓库,这里有插件的源代码。这个仓库的历史提交记录包含了这里每一个标题。
开始
安装 Atom
根据 Atom 官网 的说明来下载 Atom。我们同时还要安装上 apm(Atom 包管理器的命令行工具)。你可以打开 Atom 并在应用菜单中导航到 Atom > Install Shell Commands 来安装。打开你的命令行终端,运行 apm -v 来检查 apm 是否已经正确安装好,安装成功的话打印出来的工具版本和相关环境信息应该是像这样的:
apm -v
> apm 1.9.2
> npm 2.13.3
> node 0.10.40
> python 2.7.10
> git 2.7.4
生成骨架代码
让我们使用 Atom 提供的一个实用工具创建一个新的 package(软件包)来开始这篇教程。
- 启动编辑器,按下
Cmd+Shift+P(MacOS)或者 Ctrl+Shift+P(Windows/Linux)来打开 命令面板 。 - 搜索“Package Generator: Generate Package”并点击列表中正确的条目,你会看到一个输入提示,输入软件包的名称:“sourcefetch”。
- 按下回车键来生成这个骨架代码包,它会自动在 Atom 中打开。
如果你在侧边栏没有看到软件包的文件,依次按下 Cmd+K Cmd+B(MacOS)或者 Ctrl+K Ctrl+B(Windows/Linux)。
命令面板 可以让你通过模糊搜索来找到并运行软件包。这是一个执行命令比较方便的途径,你不用去找导航菜单,也不用刻意去记快捷键。我们将会在整篇教程中使用这个方法。
运行骨架代码包
在开始编程前让我们来试用一下这个骨架代码包。我们首先需要重启 Atom,这样它才可以识别我们新增的软件包。再次打开命令面板,执行 Window: Reload 命令。
重新加载当前窗口以确保 Atom 执行的是我们最新的源代码。每当需要测试我们对软件包的改动的时候,就需要运行这条命令。
通过导航到编辑器菜单的 Packages > sourcefetch > Toggle 或者在命令面板执行 sourcefetch:toggle 来运行软件包的 toggle 命令。你应该会看到屏幕的顶部出现了一个小黑窗。再次运行这条命令就可以隐藏它。
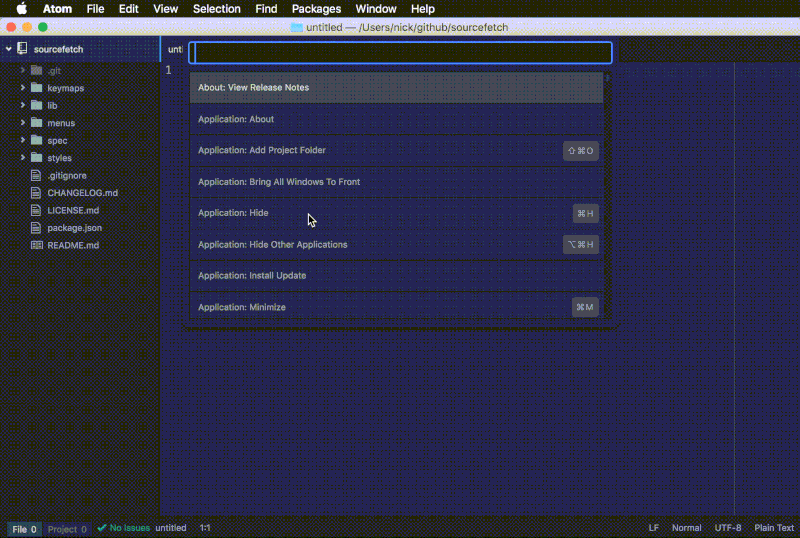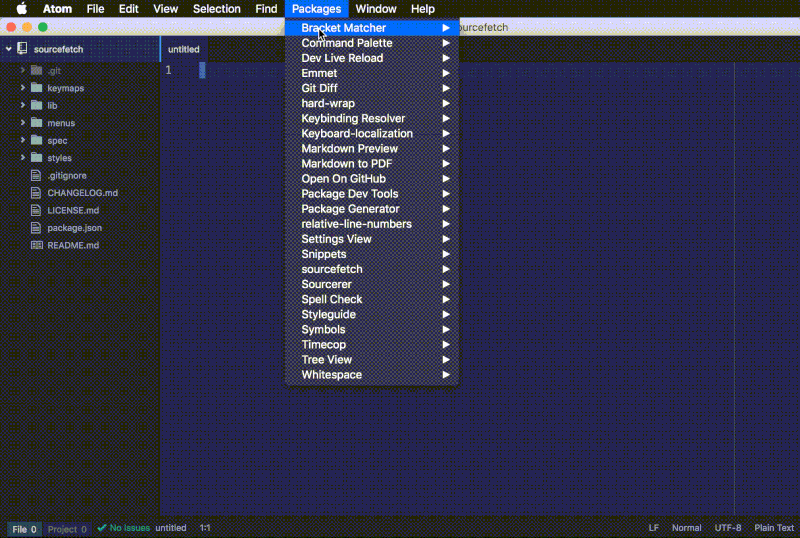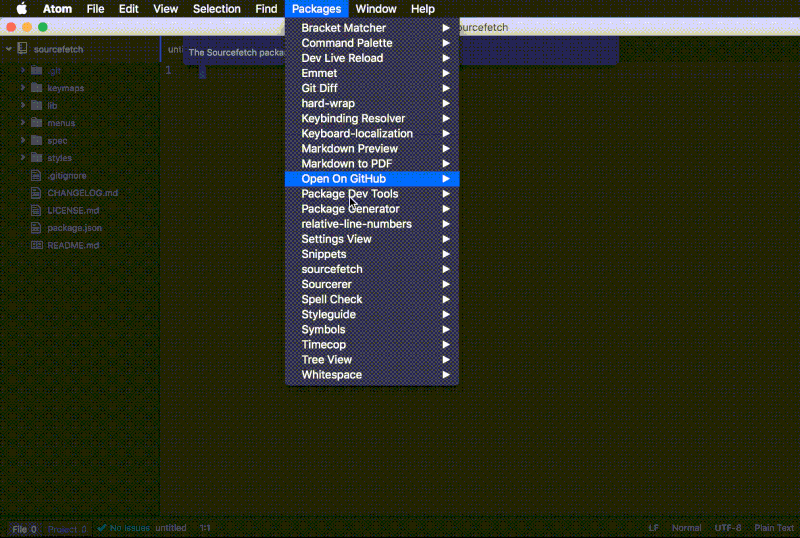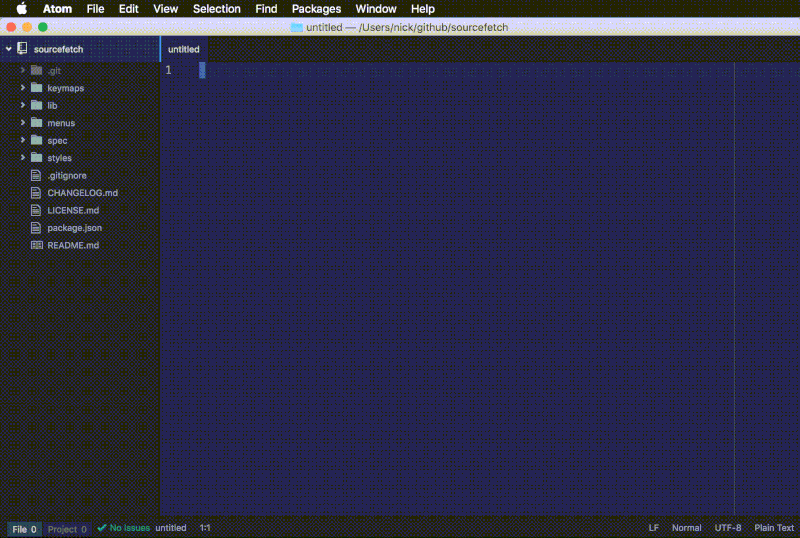
“toggle”命令
打开 lib/sourcefetch.js,这个文件包含有软件包的逻辑和 toggle 命令的定义。
toggle() {
console.log('Sourcefetch was toggled!');
return (
this.modalPanel.isVisible() ?
this.modalPanel.hide() :
this.modalPanel.show()
);
}
toggle 是这个模块导出的一个函数。根据模态面板的可见性,它通过一个三目运算符 来调用 show 和 hide 方法。modalPanel 是 Panel(一个由 Atom API 提供的 UI 元素) 的一个实例。我们需要在 export default 内部声明 modalPanel 才可以让我们通过一个实例变量 this 来访问它。
this.subscriptions.add(atom.commands.add('atom-workspace', {
'sourcefetch:toggle': () => this.toggle()
}));
上面的语句让 Atom 在用户运行 sourcefetch:toggle 的时候执行 toggle 方法。我们指定了一个 匿名函数 () => this.toggle(),每次执行这条命令的时候都会执行这个函数。这是事件驱动编程(一种常用的 JavaScript 模式)的一个范例。
Atom 命令
命令只是用户触发事件时使用的一些字符串标识符,它定义在软件包的命名空间内。我们已经用过的命令有:
package-generator:generate-packageWindow:reloadsourcefetch:toggle
软件包对应到命令,以执行代码来响应事件。
进行你的第一次代码更改
让我们来进行第一次代码更改——我们将通过改变 toggle 函数来实现逆转用户选中文本的功能。
改变 “toggle” 函数
如下更改 toggle 函数。
toggle() {
let editor
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
let reversed = selection.split('').reverse().join('')
editor.insertText(reversed)
}
}
测试你的改动
- 通过在命令面板运行
Window: Reload 来重新加载 Atom。 - 通过导航到
File > New 来创建一个新文件,随便写点什么并通过光标选中它。 - 通过命令面板、Atom 菜单或者右击文本然后选中
Toggle sourcefetch 来运行 sourcefetch:toggle 命令。
更新后的命令将会改变选中文本的顺序:
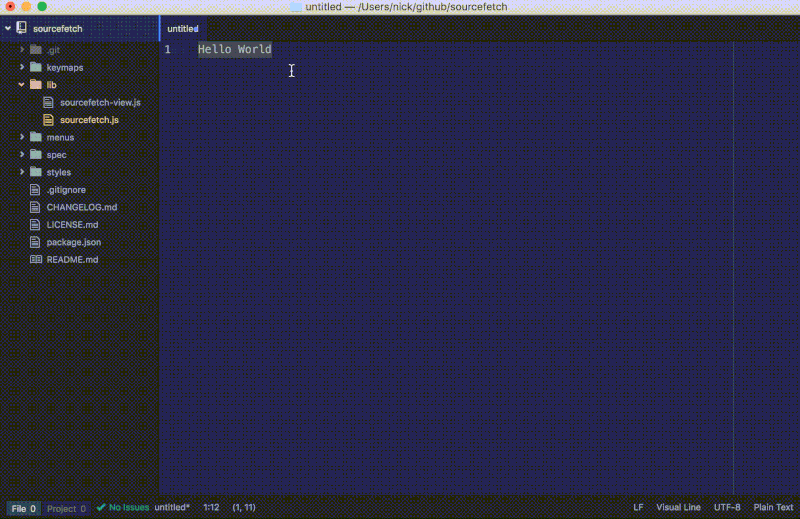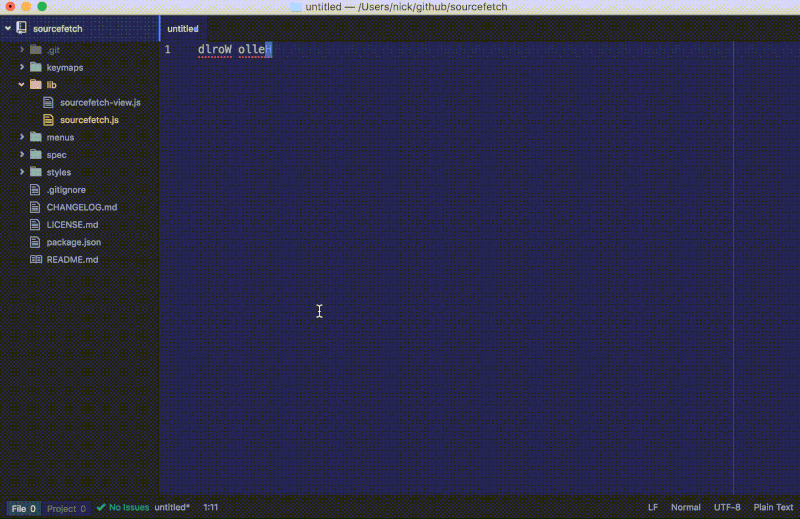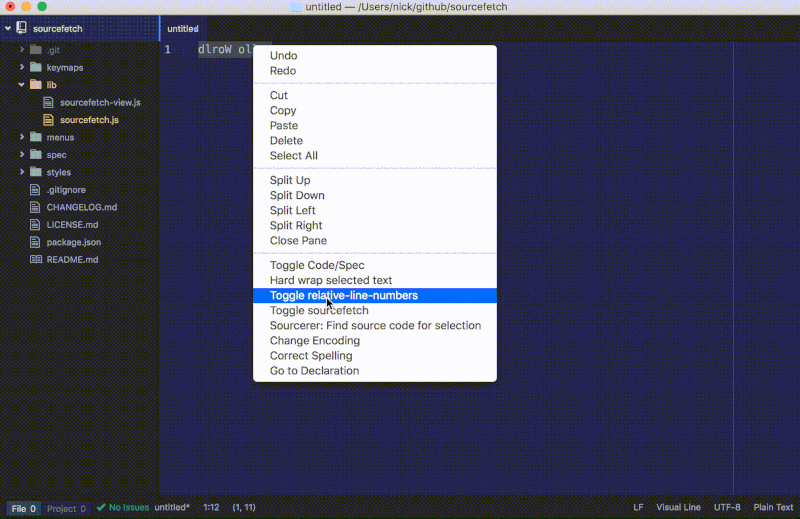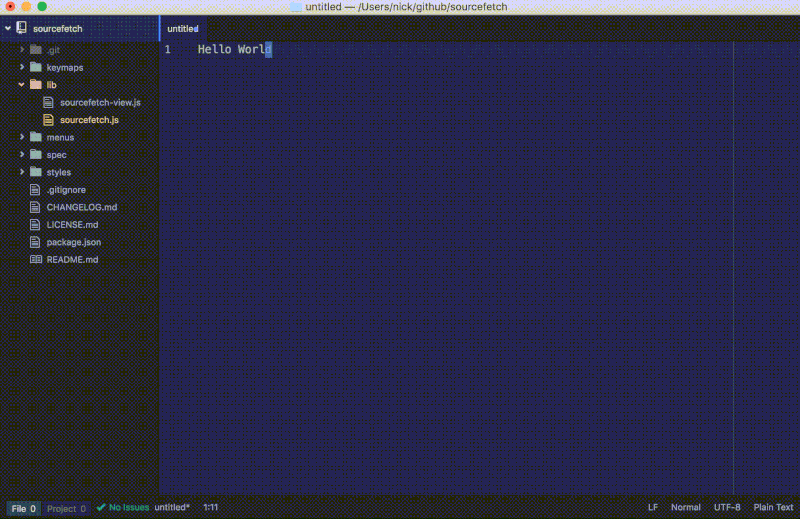
在 sourcefetch 教程仓库 查看这一步的全部代码更改。
Atom 编辑器 API
我们添加的代码通过用 TextEditor API 来访问编辑器内的文本并进行操作。让我们来仔细看看。
let editor
if (editor = atom.workspace.getActiveTextEditor()) { /* ... */ }
头两行代码获取了 TextEditor 实例的一个引用。变量的赋值和后面的代码被包在一个条件结构里,这是为了处理没有可用的编辑器实例的情况,例如,当用户在设置菜单中运行该命令时。
let selection = editor.getSelectedText()
调用 getSelectedText 方法可以让我们访问到用户选中的文本。如果当前没有文本被选中,函数将返回一个空字符串。
let reversed = selection.split('').reverse().join('')
editor.insertText(reversed)
我们选中的文本通过一个 JavaScript 字符串方法 来逆转。最后,我们调用 insertText 方法来将选中的文本替换为逆转后的文本副本。通过阅读 Atom API 文档,你可以学到更多关于 TextEditor 的不同的方法。
浏览骨架代码
现在我们已经完成第一次代码更改了,让我们浏览骨架代码包的代码来深入了解一下 Atom 的软件包是怎样构成的。
主文件
主文件是 Atom 软件包的入口文件。Atom 通过 package.json 里的条目设置来找到主文件的位置:
"main": "./lib/sourcefetch",
这个文件导出一个带有生命周期函数(Atom 在特定的事件发生时调用的处理函数)的对象。
- activate 会在 Atom 初次加载软件包的时候调用。这个函数用来初始化一些诸如软件包所需的用户界面元素的对象,以及订阅软件包命令的处理函数。
- deactivate 会在软件包停用的时候调用,例如,当用户关闭或者刷新编辑器的时候。
- serialize Atom 调用它在使用软件包的过程中保存软件包的当前状态。它的返回值会在 Atom 下一次加载软件包的时候作为一个参数传递给
activate。
我们将会重命名我们的软件包命令为 fetch,并移除一些我们不再需要的用户界面元素。按照如下更改主文件:
'use babel';
import { CompositeDisposable } from 'atom'
export default {
subscriptions: null,
activate() {
this.subscriptions = new CompositeDisposable()
this.subscriptions.add(atom.commands.add('atom-workspace', {
'sourcefetch:fetch': () => this.fetch()
}))
},
deactivate() {
this.subscriptions.dispose()
},
fetch() {
let editor
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
selection = selection.split('').reverse().join('')
editor.insertText(selection)
}
}
};
“启用”命令
为了提升性能,Atom 软件包可以用时加载。我们可以让 Atom 在用户执行特定的命令的时候才加载我们的软件包。这些命令被称为 启用命令,它们在 package.json 中定义:
"activationCommands": {
"atom-workspace": "sourcefetch:toggle"
},
更新一下这个条目设置,让 fetch 成为一个启用命令。
"activationCommands": {
"atom-workspace": "sourcefetch:fetch"
},
有一些软件包需要在 Atom 启动的时候被加载,例如那些改变 Atom 外观的软件包。在那样的情况下,activationCommands 会被完全忽略。
“触发”命令
菜单项
menus 目录下的 JSON 文件指定了哪些菜单项是为我们的软件包而建的。让我们看看 menus/sourcefetch.json:
"context-menu": {
"atom-text-editor": [
{
"label": "Toggle sourcefetch",
"command": "sourcefetch:toggle"
}
]
},
这个 context-menu 对象可以让我们定义右击菜单的一些新条目。每一个条目都是通过一个显示在菜单的 label 属性和一个点击后执行的命令的 command 属性来定义的。
"context-menu": {
"atom-text-editor": [
{
"label": "Fetch code",
"command": "sourcefetch:fetch"
}
]
},
同一个文件中的这个 menu 对象用来定义插件的自定义应用菜单。我们如下重命名它的条目:
"menu": [
{
"label": "Packages",
"submenu": [
{
"label": "sourcefetch",
"submenu": [
{
"label": "Fetch code",
"command": "sourcefetch:fetch"
}
]
}
]
}
]
键盘快捷键
命令还可以通过键盘快捷键来触发。快捷键通过 keymaps 目录的 JSON 文件来定义:
{
"atom-workspace": {
"ctrl-alt-o": "sourcefetch:toggle"
}
}
以上代码可以让用户通过 Ctrl+Alt+O(Windows/Linux) 或 Cmd+Alt+O(MacOS) 来触发 toggle 命令。
重命名引用的命令为 fetch:
"ctrl-alt-o": "sourcefetch:fetch"
通过执行 Window: Reload 命令来重启 Atom。你应该会看到 Atom 的右击菜单更新了,并且逆转文本的功能应该还可以像之前一样使用。
在 sourcefetch 教程仓库 查看这一步所有的代码更改。
使用 NodeJS 模块
现在我们已经完成了第一次代码更改并且了解了 Atom 软件包的结构,让我们介绍一下 Node 包管理器(npm) 中的第一个依赖项模块。我们将使用 request 模块发起 HTTP 请求来下载网站的 HTML 文件。稍后将会用到这个功能来扒 StackOverflow 的页面。
安装依赖
打开你的命令行工具,切换到你的软件包的根目录并运行:
npm install --save [email protected]
apm install
这两条命令将 request 模块添加到我们软件包的依赖列表并将模块安装到 node_modules 目录。你应该会在 package.json 看到一个新条目。@ 符号的作用是让 npm 安装我们这篇教程需要用到的特定版本的模块。运行 apm install 是为了让 Atom 知道使用我们新安装的模块。
"dependencies": {
"request": "^2.73.0"
}
下载 HTML 并将记录打印在开发者控制台
通过在 lib/sourcefetch.js 的顶部添加一条引用语句引入 request 模块到我们的主文件:
import { CompositeDisposable } from 'atom'
import request from 'request'
现在,在 fetch 函数下面添加一个新函数 download 作为模块的导出项:
export default {
/* subscriptions, activate(), deactivate() */
fetch() {
...
},
download(url) {
request(url, (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
}
}
这个函数用 request 模块来下载一个页面的内容并将记录输出到控制台。当 HTTP 请求完成之后,我们的回调函数会将响应体作为参数来被调用。
最后一步是更新 fetch 函数以调用 download 函数:
fetch() {
let editor
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
this.download(selection)
}
},
fetch 函数现在的功能是将 selection 当作一个 URL 传递给 download 函数,而不再是逆转选中的文本了。让我们来看看这次的更改:
- 通过执行
Window: Reload 命令来重新加载 Atom。 - 打开开发者工具。为此,导航到菜单中的
View > Developer > Toggle Developer Tools。 - 新建一个文件,导航到
File > New。 - 输入一个 URL 并选中它,例如:
http://www.atom.io。 - 用上述的任意一种方法执行我们软件包的命令:
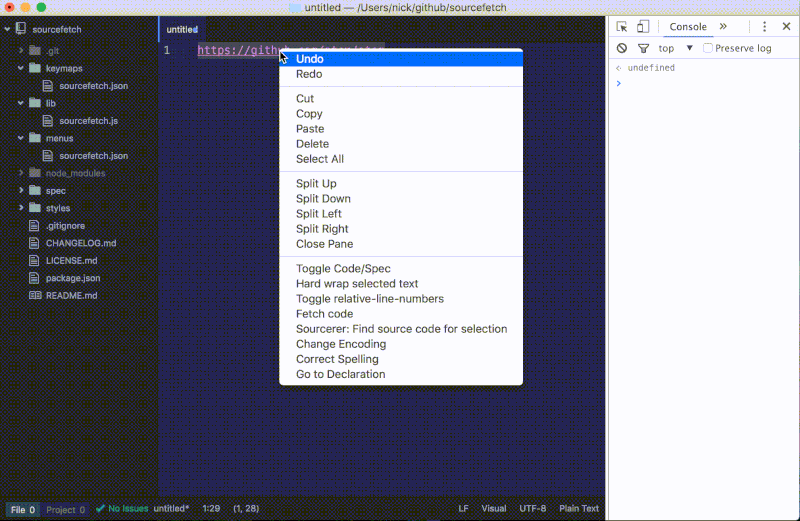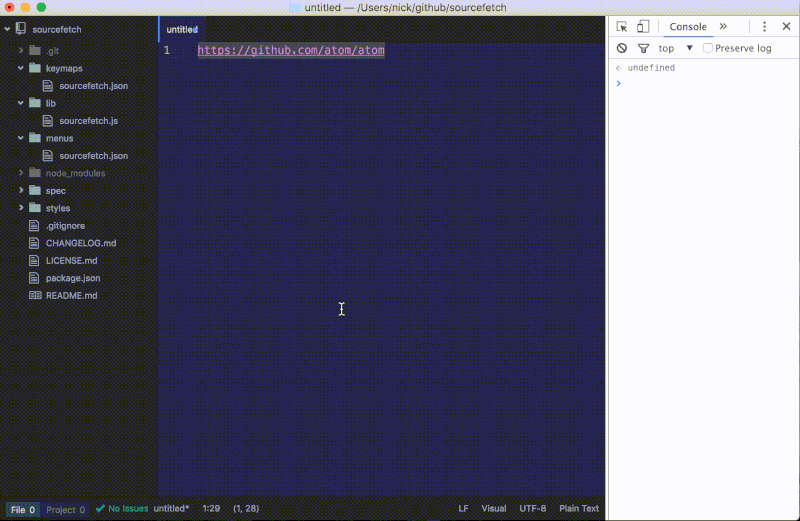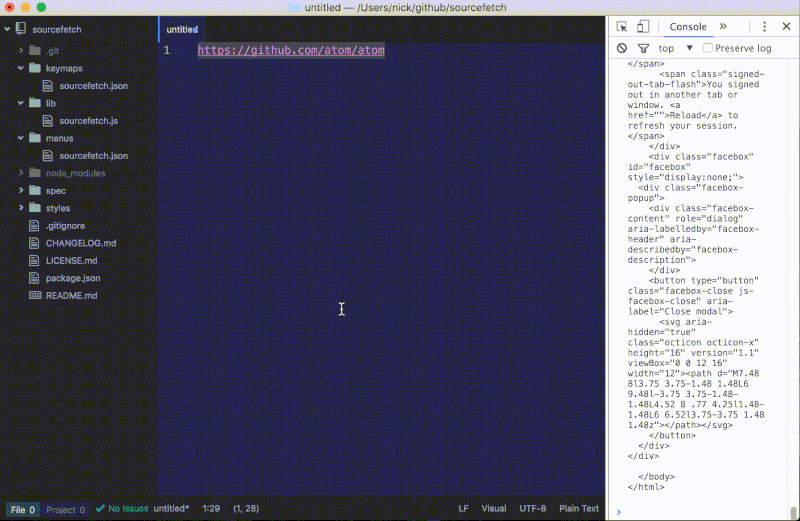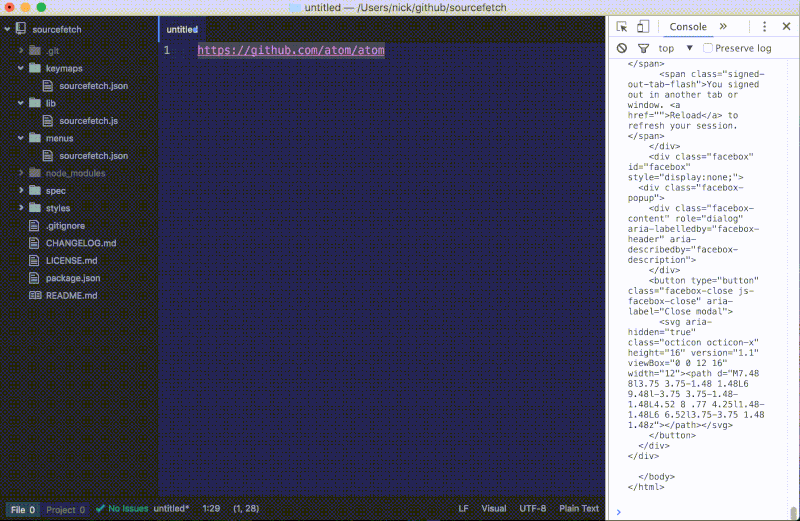
开发者工具让 Atom 软件包的调试更轻松。每个 console.log 语句都可以将信息打印到交互控制台,你还可以使用 Elements 选项卡来浏览整个应用的可视化结构——即 HTML 的文本对象模型(DOM)。
在 sourcefetch 教程仓库 查看这一步所有的代码更改。
用 Promises 来将下载好的 HTML 插入到编辑器中
理想情况下,我们希望 download 函数可以将 HTML 作为一个字符串来返回,而不仅仅是将页面的内容打印到控制台。然而,返回文本内容是无法实现的,因为我们要在回调函数里面访问内容而不是在 download 函数那里。
我们会通过返回一个 Promise 来解决这个问题,而不再是返回一个值。让我们改动 download 函数来返回一个 Promise:
download(url) {
return new Promise((resolve, reject) => {
request(url, (error, response, body) => {
if (!error && response.statusCode == 200) {
resolve(body)
} else {
reject({
reason: 'Unable to download page'
})
}
})
})
}
Promises 允许我们通过将异步逻辑封装在一个提供两个回调方法的函数里来返回获得的值(resolve 用来处理请求成功的返回值,reject 用来向使用者报错)。如果请求返回了错误我们就调用 reject,否则就用 resolve 来处理 HTML。
让我们更改 fetch 函数来使用 download 返回的 Promise:
fetch() {
let editor
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
this.download(selection).then((html) => {
editor.insertText(html)
}).catch((error) => {
atom.notifications.addWarning(error.reason)
})
}
},
在我们新版的 fetch 函数里,我们通过在 download 返回的 Promise 调用 then 方法来对 HTML 进行操作。这会将 HTML 插入到编辑器中。我们同样会通过调用 catch 方法来接收并处理所有的错误。我们通过用 Atom Notification API 来显示警告的形式来处理错误。
看看发生了什么变化。重新加载 Atom 并在一个选中的 URL 上执行软件包命令:
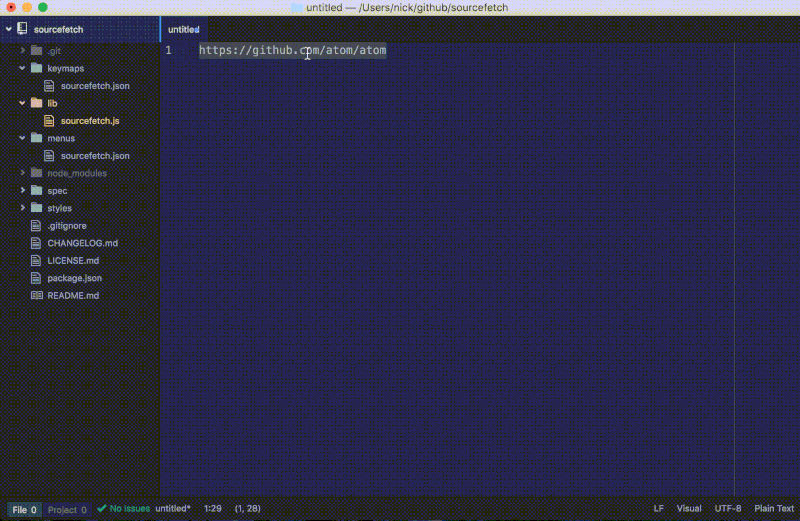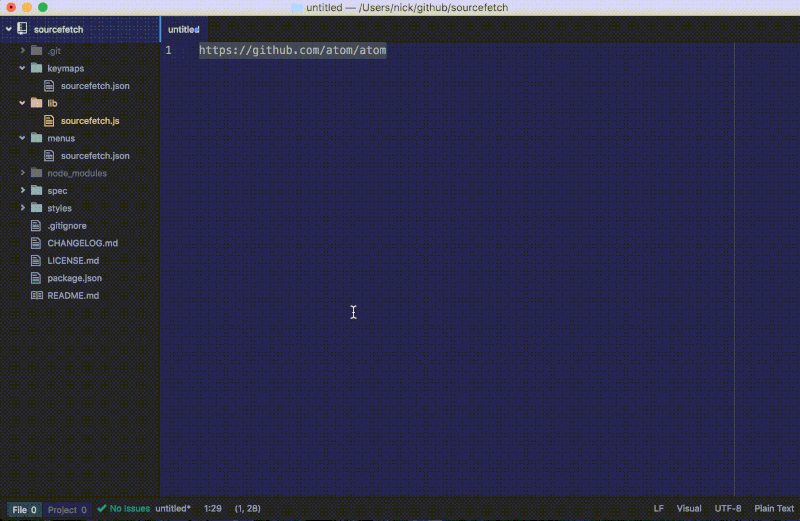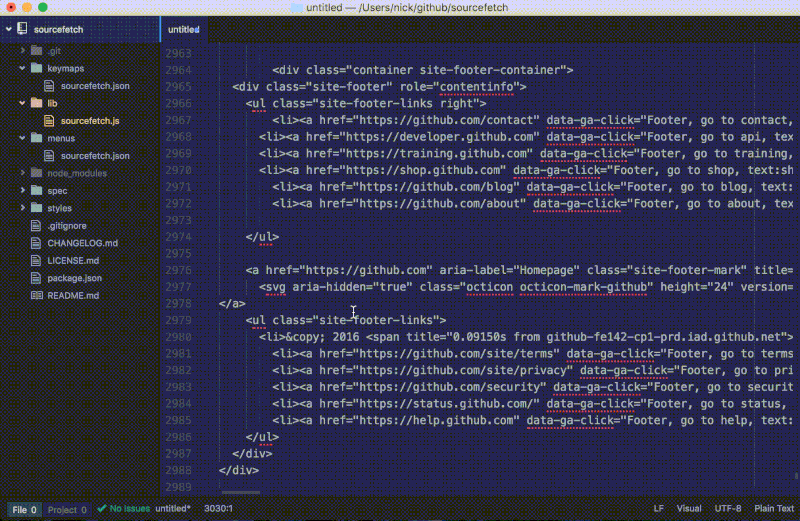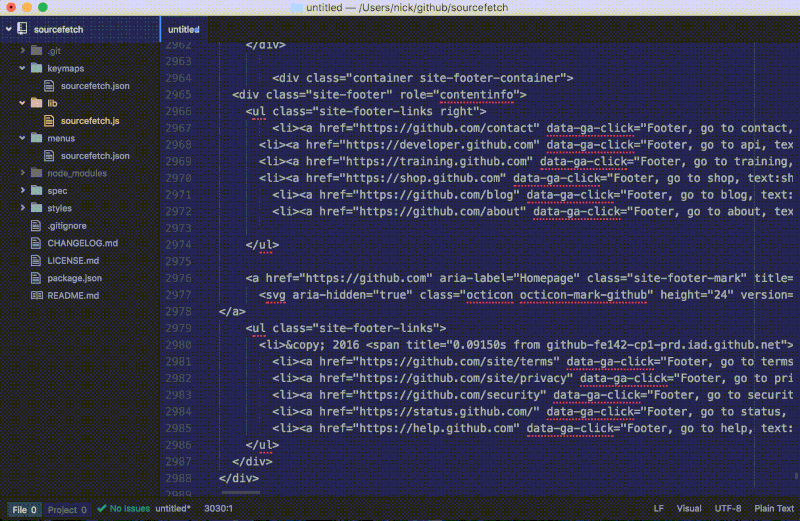
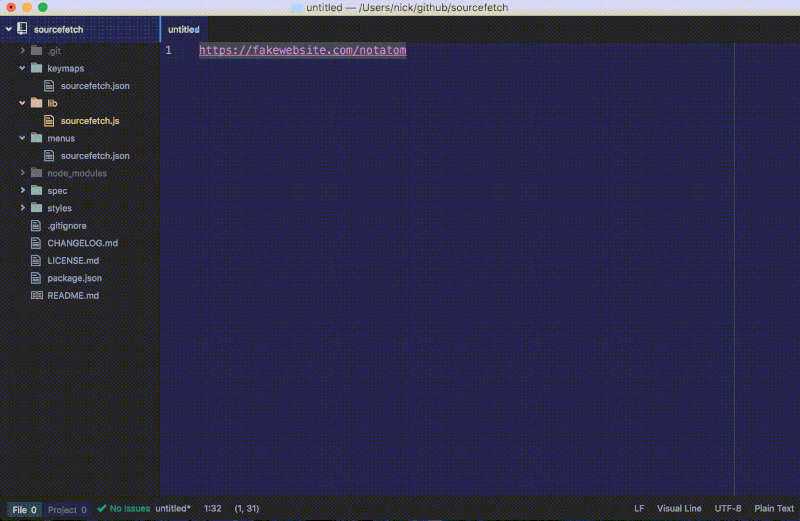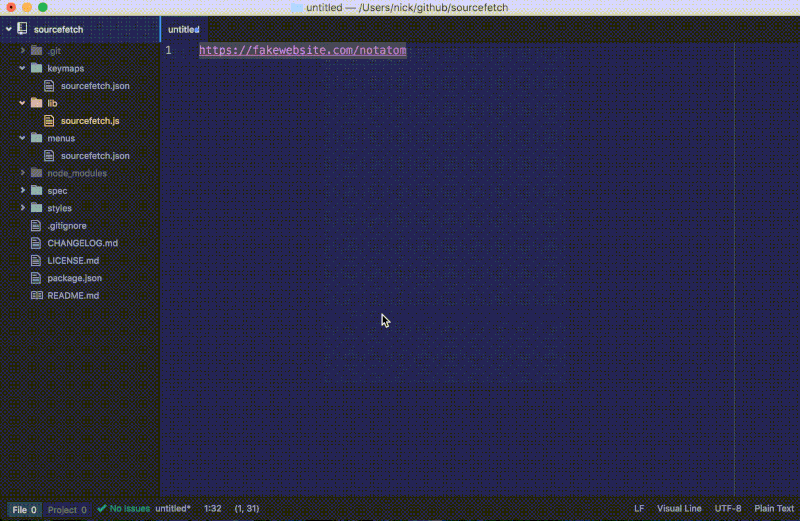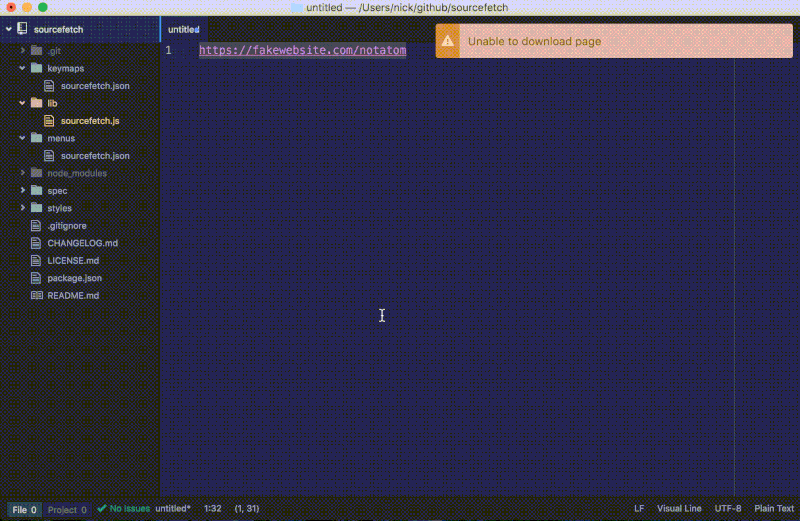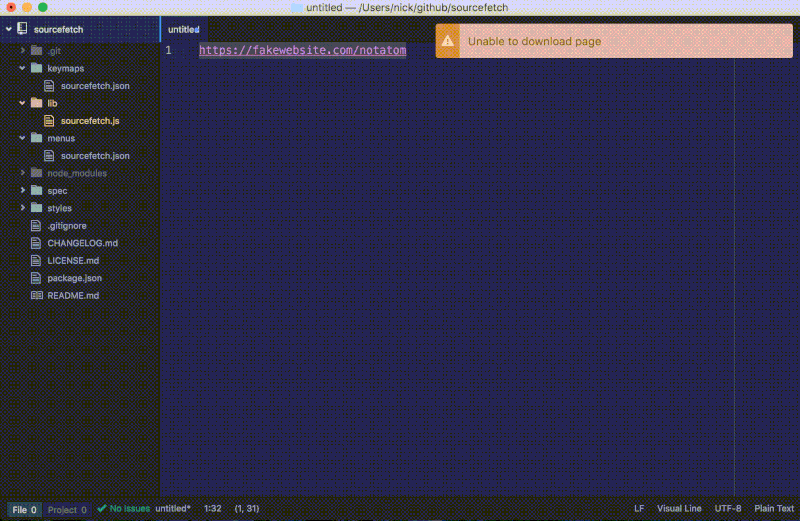
如果这个 URL 是无效的,一个警告通知将会弹出来:
在 sourcefetch 教程仓库 查看这一步所有的代码更改。
编写一个爬虫来提取 StackOverflow 页面的代码片段
下一步涉及用我们前面扒到的 StackOverflow 的页面的 HTML 来提取代码片段。我们尤其关注那些来自采纳答案(提问者选择的一个正确答案)的代码。我们可以在假设这类答案都是相关且正确的前提下大大简化我们这个软件包的实现。
使用 jQuery 和 Chrome 开发者工具来构建查询
这一部分假设你使用的是 Chrome 浏览器。你接下来可以使用其它浏览器,但是提示可能会不一样。
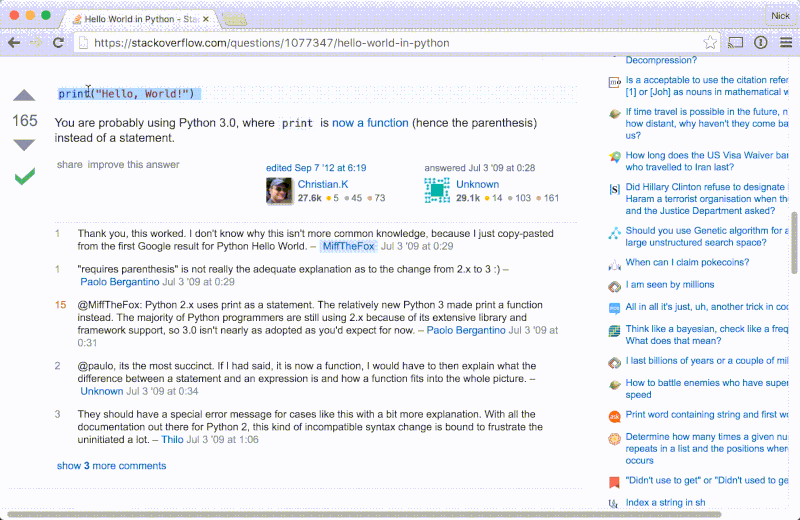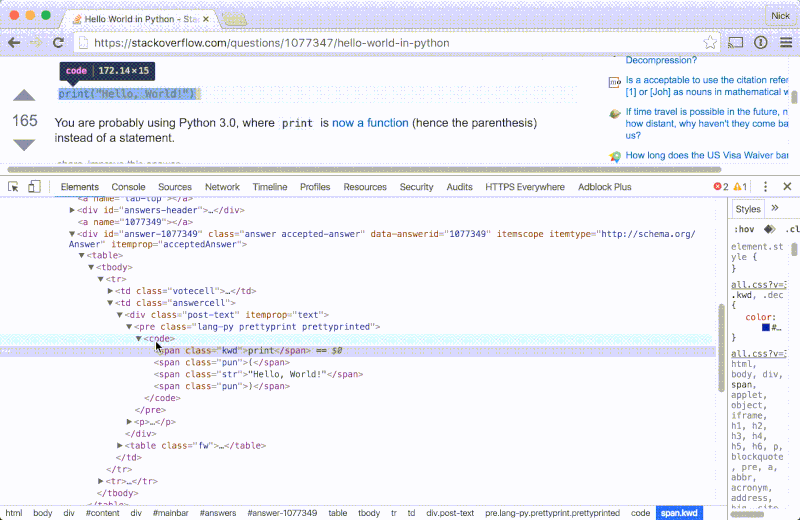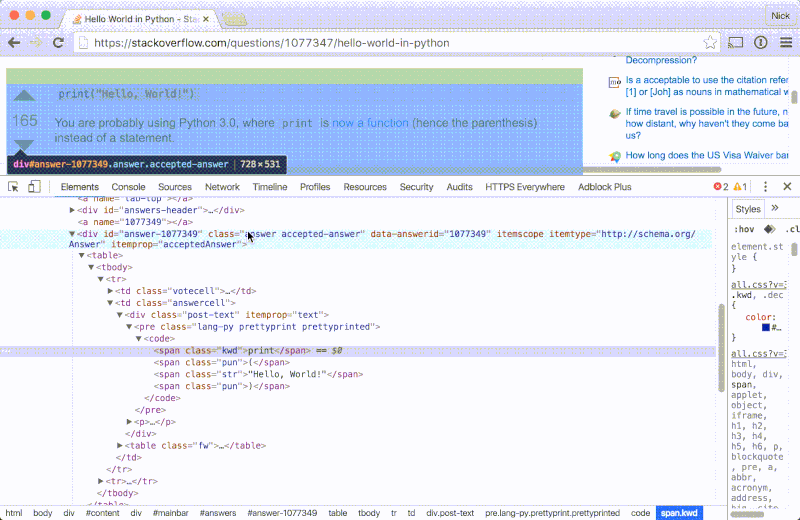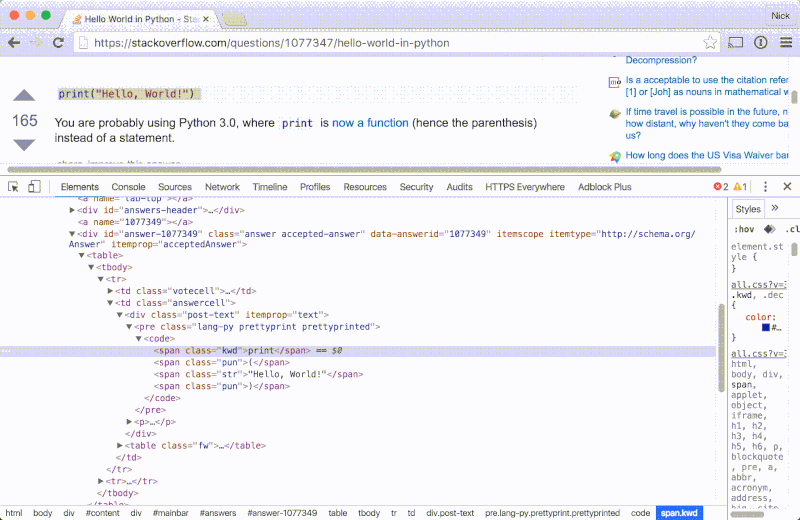
让我们先看看一张典型的包含采纳答案和代码片段的 StackOverflow 页面。我们将会使用 Chrome 开发者工具来浏览 HTML:
- 打开 Chrome 并跳到任意一个带有采纳答案和代码的 StackOverflow 页面,比如像这个用 Python 写的 hello world 的例子或者这个关于 用
C 来读取文本内容的问题。 - 滚动窗口到采纳答案的位置并选中一部分代码。
- 右击选中文本并选择
检查。 - 使用元素侦察器来检查代码片段在 HTML 中的位置。
注意文本结构应该是这样的:
<div class="accepted-answer">
...
...
<pre>
<code>
...snippet elements...
</code>
</pre>
...
...
</div>
- 采纳的答案通过一个 class 为
accepted-answer 的 div 来表示 - 代码块位于
pre 元素的内部 - 呈现代码片段的元素就是里面那一对
code 标签
现在让我们写一些 jQuery 代码来提取代码片段:
- 在开发者工具那里点击 Console 选项卡来访问 Javascript 控制台。
- 在控制台中输入
$('div.accepted-answer pre code').text() 并按下回车键。
你应该会看到控制台中打印出采纳答案的代码片段。我们刚刚运行的代码使用了一个 jQuery 提供的特别的 $ 函数。$ 接收要选择的查询字符串并返回网站中的某些 HTML 元素。让我们通过思考几个查询案例看看这段代码的工作原理:
$('div.accepted-answer')
> [<div id="answer-1077349" class="answer accepted-answer" ... ></div>]
上面的查询会匹配所有 class 为 accepted-answer 的 <div> 元素,在我们的案例中只有一个 div。
$('div.accepted-answer pre code')
> [<code>...</code>]
在前面的基础上改造了一下,这个查询会匹配所有在之前匹配的 <div> 内部的 <pre> 元素内部的 <code> 元素。
$('div.accepted-answer pre code').text()
> "print("Hello World!")"
text 函数提取并连接原本将由上一个查询返回的元素列表中的所有文本。这也从代码中去除了用来使语法高亮的元素。
介绍 Cheerio
我们的下一步涉及使用我们创建好的查询结合 Cheerio(一个服务器端实现的 jQuery)来实现扒页面的功能。
安装 Cheerio
打开你的命令行工具,切换到你的软件包的根目录并执行:
npm install --save [email protected]
apm install
实现扒页面的功能
在 lib/sourcefetch.js 为 cheerio 添加一条引用语句:
import { CompositeDisposable } from 'atom'
import request from 'request'
import cheerio from 'cheerio'
现在创建一个新函数 scrape,它用来提取 StackOverflow HTML 里面的代码片段:
fetch() {
...
},
scrape(html) {
$ = cheerio.load(html)
return $('div.accepted-answer pre code').text()
},
download(url) {
...
}
最后,让我们更改 fetch 函数以传递下载好的 HTML 给 scrape 而不是将其插入到编辑器:
fetch() {
let editor
let self = this
if (editor = atom.workspace.getActiveTextEditor()) {
let selection = editor.getSelectedText()
this.download(selection).then((html) => {
let answer = self.scrape(html)
if (answer === '') {
atom.notifications.addWarning('No answer found :(')
} else {
editor.insertText(answer)
}
}).catch((error) => {
console.log(error)
atom.notifications.addWarning(error.reason)
})
}
},
我们扒取页面的功能仅仅用两行代码就实现了,因为 cheerio 已经替我们做好了所有的工作!我们通过调用 load 方法加载 HTML 字符串来创建一个 $ 函数,然后用这个函数来执行 jQuery 语句并返回结果。你可以在官方 开发者文档 查看完整的 Cheerio API。
测试更新后的软件包
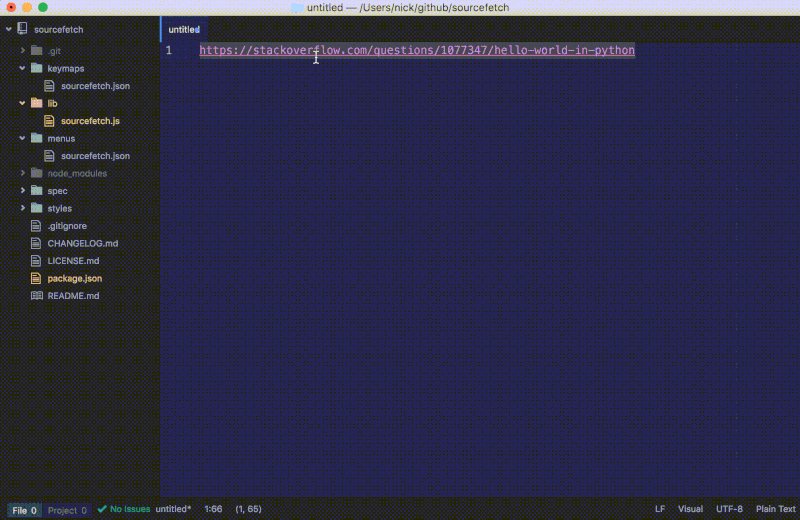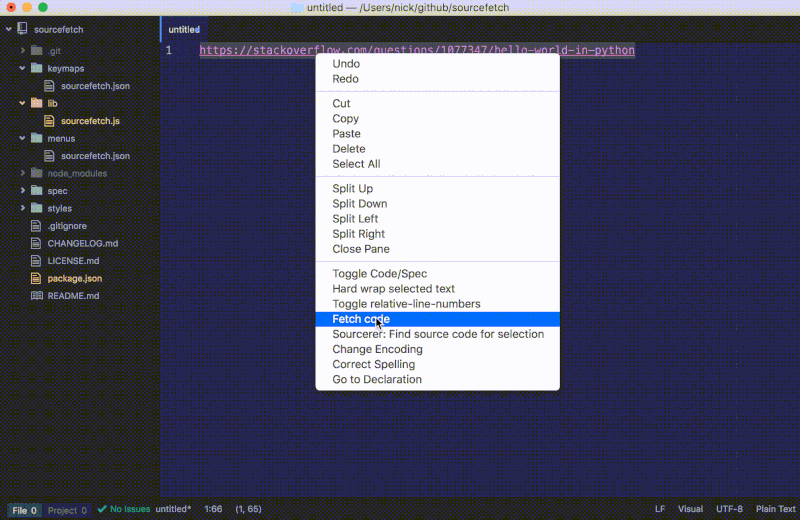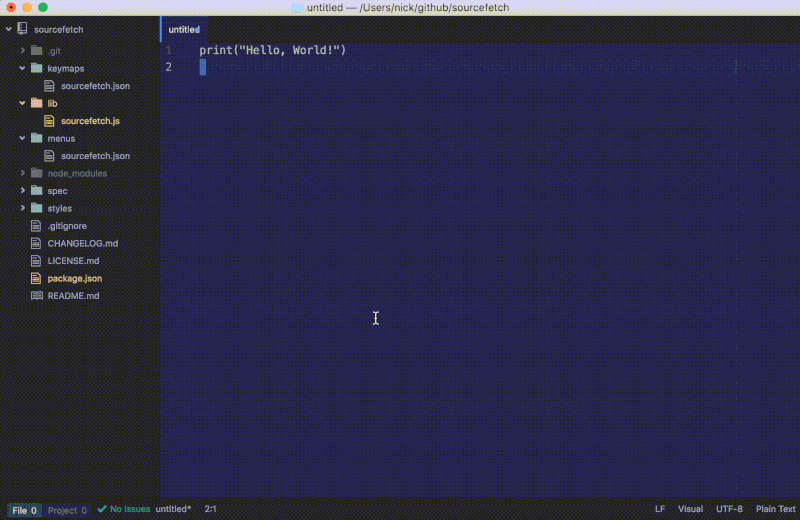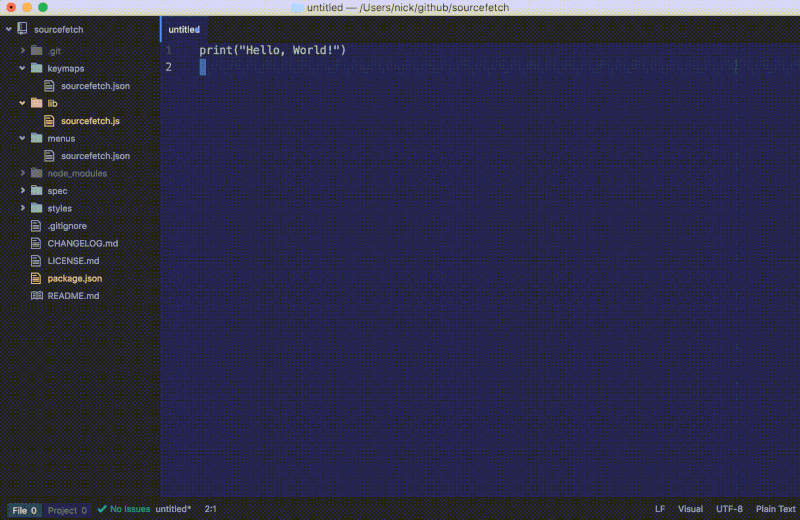
重新加载 Atom 并在一个选中的 StackOverflow URL 上运行 soucefetch:fetch 以查看到目前为止的进度。
如果我们在一个有采纳答案的页面上运行这条命令,代码片段将会被插入到编辑器中:
如果我们在一个没有采纳答案的页面上运行这条命令,将会弹出一个警告通知:
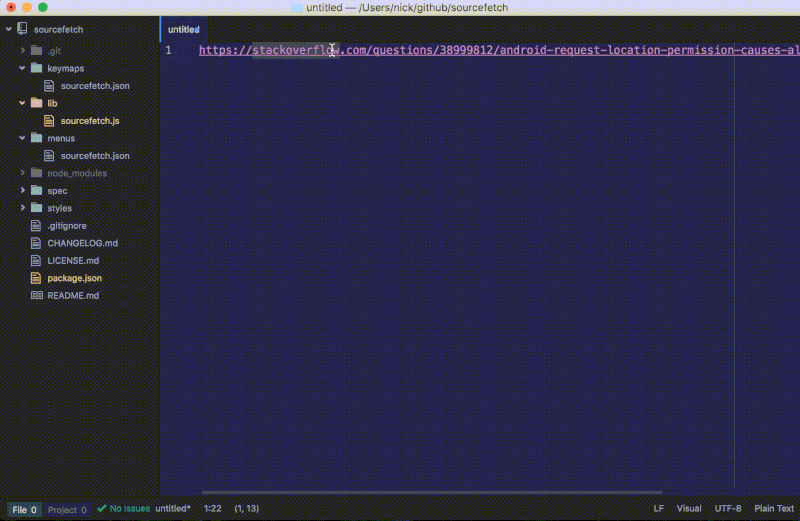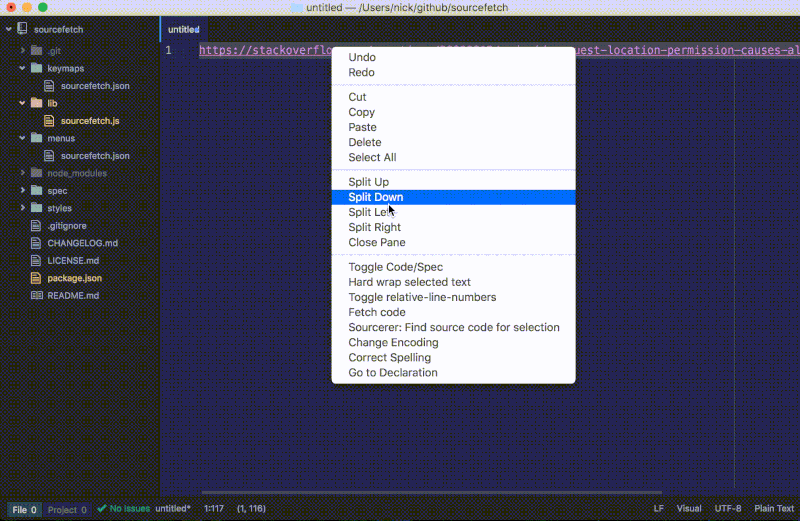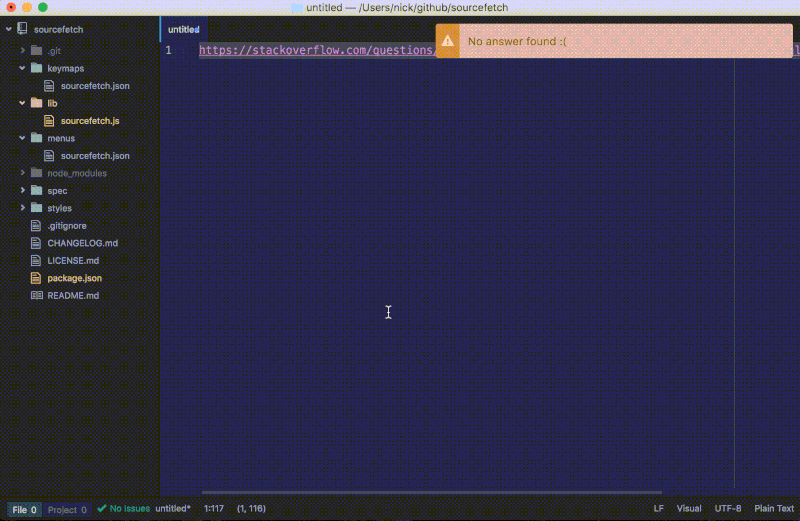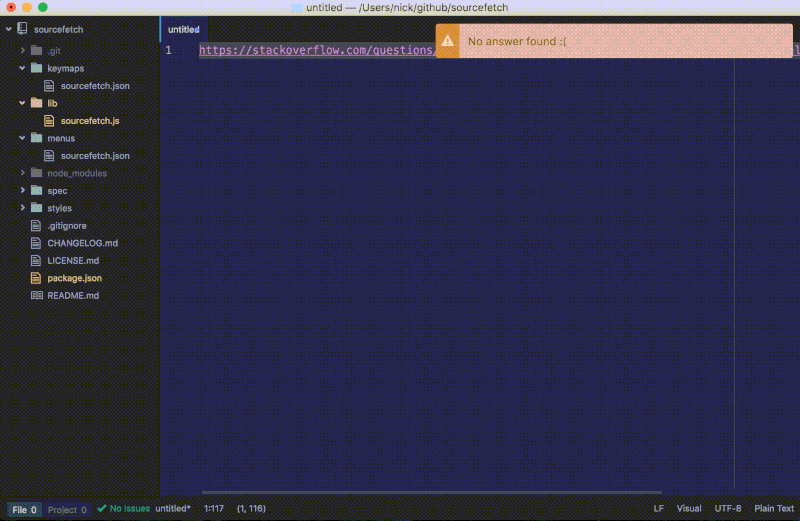
我们最新的 fetch 函数给我们提供了一个 StackOverflow 页面的代码片段而不再是整个 HTML 内容。要注意我们更新的 fetch 函数会检查有没有答案并显示通知以提醒用户。
在 sourcefetch 教程仓库 查看这一步所有的代码更改。
实现用来查找相关的 StackOverflow URL 的谷歌搜索功能
现在我们已经将 StackOverflow 的 URL 转化为代码片段了,让我们来实现最后一个函数——search,它应该要返回一个相关的 URL 并附加一些像“hello world”或者“快速排序”这样的描述。我们会通过一个非官方的 google npm 模块来使用谷歌搜索功能,这样可以让我们以编程的方式来搜索。
安装这个 Google npm 模块
通过在软件包的根目录打开命令行工具并执行命令来安装 google 模块:
npm install --save [email protected]
apm install
引入并配置模块
在 lib/sourcefetch.js 的顶部为 google 模块添加一条引用语句:
import google from "google"
我们将配置一下 google 以限制搜索期间返回的结果数。将下面这行代码添加到引用语句下面以限制搜索返回最热门的那个结果。
google.resultsPerPage = 1
实现 search 函数
接下来让我们来实现我们的 search 函数:
fetch() {
...
},
search(query, language) {
return new Promise((resolve, reject) => {
let searchString = `${query} in ${language} site:stackoverflow.com`
google(searchString, (err, res) => {
if (err) {
reject({
reason: 'A search error has occured :('
})
} else if (res.links.length === 0) {
reject({
reason: 'No results found :('
})
} else {
resolve(res.links[0].href)
}
})
})
},
scrape() {
...
}
以上代码通过谷歌来搜索一个和指定的关键词以及编程语言相关的 StackOverflow 页面,并返回一个最热门的 URL。让我们看看这是怎样来实现的:
let searchString = `${query} in ${language} site:stackoverflow.com`
我们使用用户输入的查询和当前所选的语言来构造搜索字符串。比方说,当用户在写 Python 的时候输入“hello world”,查询语句就会变成 hello world in python site:stackoverflow.com。字符串的最后一部分是谷歌搜索提供的一个过滤器,它让我们可以将搜索结果的来源限制为 StackOverflow。
google(searchString, (err, res) => {
if (err) {
reject({
reason: 'A search error has occured :('
})
} else if (res.links.length === 0) {
reject({
reason: 'No results found :('
})
} else {
resolve(res.links[0].href)
}
})
我们将 google 方法放在一个 Promise 里面,这样我们可以异步地返回我们的 URL。我们会传递由 google 返回的所有错误并且会在没有可用的搜索结果的时候返回一个错误。否则我们将通过 resolve 来解析最热门结果的 URL。
更新 fetch 来使用 search
我们的最后一步是更新 fetch 函数来使用 search 函数:
fetch() {
let editor
let self = this
if (editor = atom.workspace.getActiveTextEditor()) {
let query = editor.getSelectedText()
let language = editor.getGrammar().name
self.search(query, language).then((url) => {
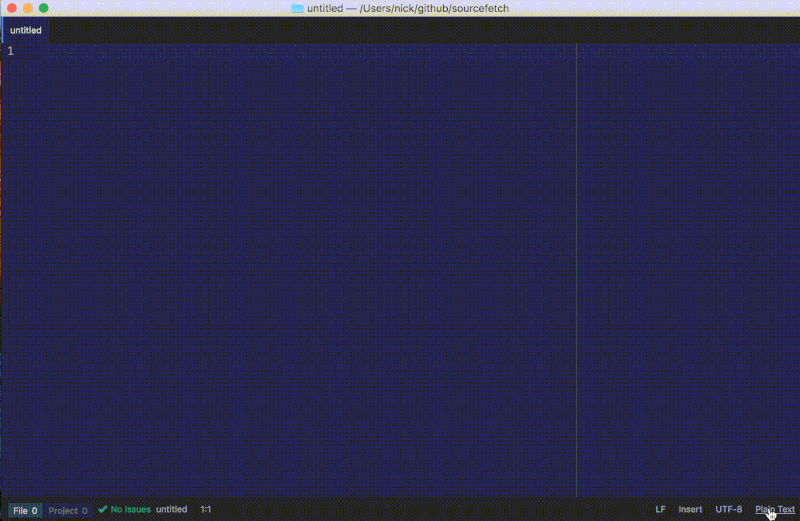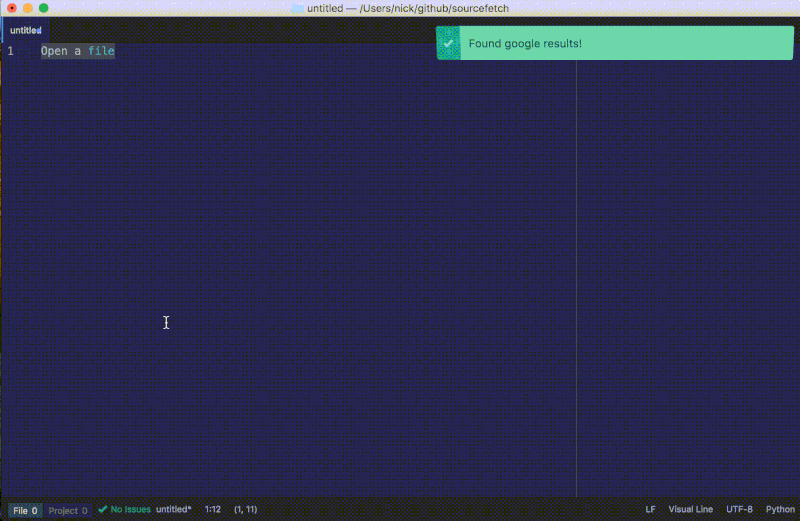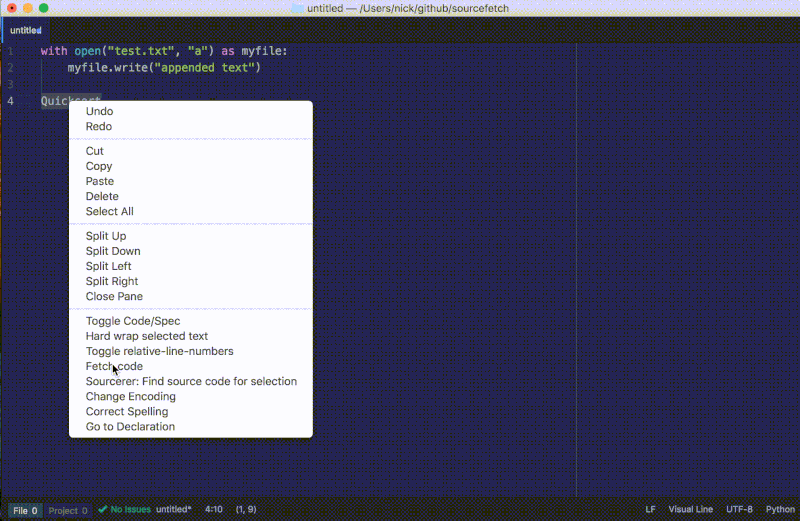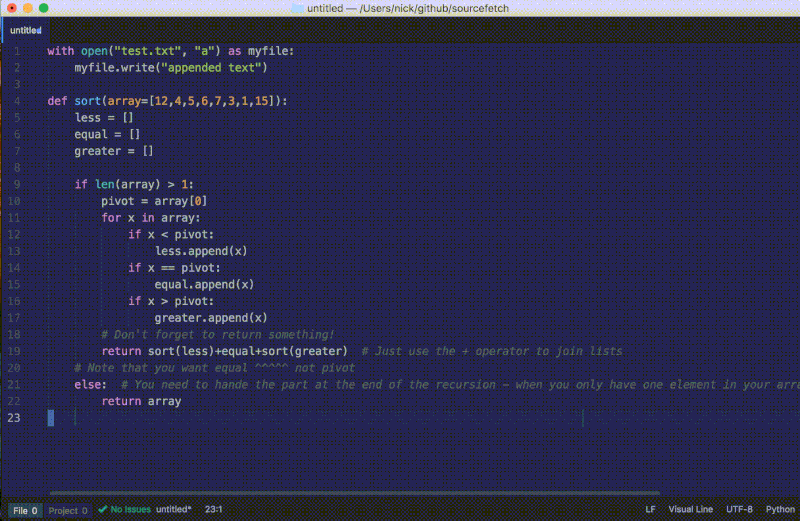
atom.notifications.addSuccess('Found google results!')
return self.download(url)
}).then((html) => {
let answer = self.scrape(html)
if (answer === '') {
atom.notifications.addWarning('No answer found :(')
} else {
atom.notifications.addSuccess('Found snippet!')
editor.insertText(answer)
}
}).catch((error) => {
atom.notifications.addWarning(error.reason)
})
}
}
让我们看看发生了什么变化:
- 我们选中的文本现在变成了用户输入的
query - 我们使用 TextEditor API 来获取当前编辑器选项卡使用的
language - 我们调用
search 方法来获取一个 URL,然后通过在得到的 Promise 上调用 then 方法来访问这个 URL
我们不在 download 返回的 Promise 上调用 then 方法,而是在前面 search 方法本身链式调用的另一个 then 方法返回的 Promise 上面接着调用 then 方法。这样可以帮助我们避免回调地狱
在 sourcefetch 教程仓库 查看这一步所有的代码更改。
测试最终的插件
大功告成了!重新加载 Atom,对一个“问题描述”运行软件包的命令来看看我们最终的插件是否工作,不要忘了在编辑器右下角选择一种语言。
下一步
现在你知道怎么去 “hack” Atom 的基本原理了,通过 分叉 sourcefetch 这个仓库并添加你的特性 来随心所欲地实践你所学到的知识。
via: https://github.com/blog/2231-building-your-first-atom-plugin
作者:NickTikhonov 译者:OneNewLife 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出