Git 系列(五):三个 Git 图形化工具
在本文里,我们来了解几个能帮你在日常工作中舒服地用上 Git 的工具。
我是在这许多漂亮界面出来之前学习的 Git,而且我的日常工作经常是基于字符界面的,所以 Git 本身自带的大部分功能已经足够我用了。在我看来,最好能理解 Git 的工作原理。不过,能有的选也不错,下面这些就是能让你不用终端就可以开始使用 Git 的一些方式。
KDE Dolphin 里的 Git
我是一个 KDE 用户,如果不在 Plasma 桌面环境下,就是在 Fluxbox 的应用层。Dolphin 是一个非常优秀的文件管理器,有很多配置项以及大量秘密小功能。大家为它开发的插件都特别好用,其中一个几乎就是完整的 Git 界面。是的,你可以直接在自己的桌面上很方便地管理你的 Git 仓库。
但首先,你得先确认已经安装了这个插件。有些发行版带的 KDE 将各种插件都装的满满的,而有些只装了一些最基本的,所以如果你在下面的步骤里没有看到 Git 相关选项,就在你的软件仓库里找找类似 dolphin-extras 或者 dolphin-plugins 的包。
要打开 Git 集成功能,在 Dolphin 的任一窗口里点击 Settings 菜单,并选择 Configure Dolphin。
在弹出的 Configure Dolphin 窗口里,点击左边侧栏里的 Services 图标。
在 Services 面板里,滚动可用的插件列表找到 Git。
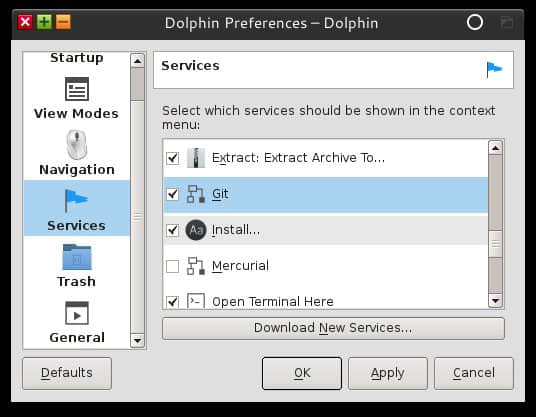
(勾选上它,)然后保存你的改动并关闭 Dolphin 窗口。重新启动 Dolphin,浏览一个 Git 仓库试试看。你会发现现在所有文件图标都带有标记:绿色方框表示已经提交的文件,绿色实心方块表示文件有改动,没加入库里的文件没有标记,等等。
之后你在 Git 仓库目录下点击鼠标右键弹出的菜单里就会有 Git 选项了。你在 Dolphin 窗口里点击鼠标就可以检出一个版本,推送或提交改动,还可以对文件进行 git add 或 git remove 操作。
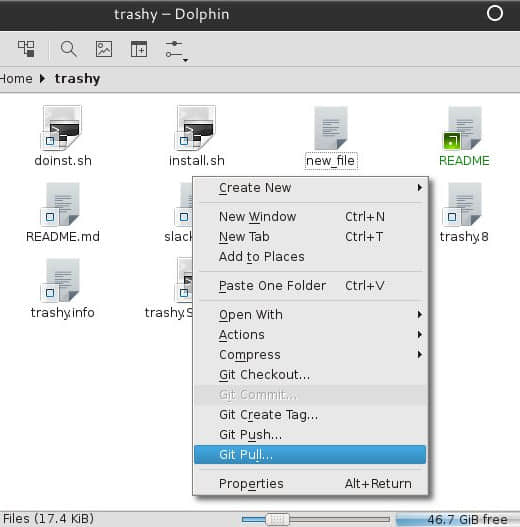
不过 Dolphin 不支持克隆仓库或是改变远端仓库路径,需要到终端窗口操作,按下 F4 就可以很方便地进行切换。
坦白地说,KDE 的这个功能太牛了,这篇文章已经可以到此为止。将 Git 集成到原生文件管理器里可以让 Git 操作非常清晰;不管你在工作流程的哪个阶段,一切都能直接地摆在面前。在终端里 Git,切换到 GUI 后也是一样 Git。完美。
不过别急,还有好多呢!
Sparkleshare
SparkleShare 来自桌面环境的另一大阵营,由一些 GNOME 开发人员发起,一个使用文件同步模型 (“就像 Dropbox 一样!”) 的项目。不过它并没有集成任何 GNOME 特有的组件,所以你可以在任何平台使用。
如果你在用 Linux,可以从你的软件仓库直接安装 SparkleShare。如果是其它操作系统,可以去 SparkleShare 网站下载。你可以不用看 SparkleShare 网站上的指引,那个是告诉你如何架设 SparkleShare 服务器的,不是我们这里讨论的。当然你想的话也可以架设 SparkleShare 服务器,但是 SparkleShare 能兼容 Git 仓库,所以其实没必要再架一个自己的。
在安装完成后,从应用程序菜单里启动 SparkleShare。走一遍设置向导,只有两个步骤外加一个简单介绍,然后可以选择是否将 SparkleShare 设置为随桌面自动启动。
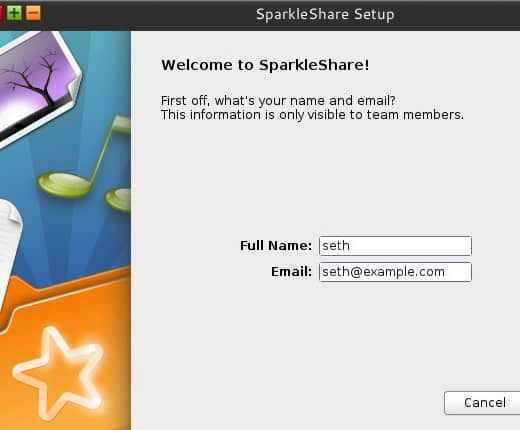
之后在你的系统托盘里会出现一个橙色的 SparkleShare 目录。目前,SparkleShare 对你电脑上的任何东西都一无所知,所以你需要添加一个项目。
要添加一个目录给 SparkleShare 追踪,可以点击系统托盘里的 SparkleShare 图标然后选择 Add Hosted Project。
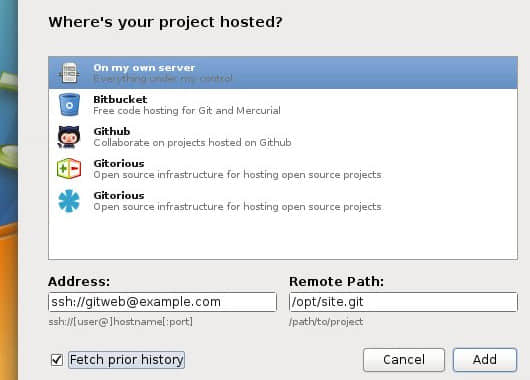
SparkleShare 支持本地 Git 项目,也可以是存放在像 GitHub 和 Bitbucket 这样的公共 Git 服务器上的项目。要获得完整访问权限,你可能会需要使用 SparkleShare 生成的客户端 ID。这是一个 SSH 密钥,作为你所用到服务的授权令牌,包括你自己的 Git 服务器,应该也使用 SSH 公钥认证而不是用户名密码。将客户端 ID 拷贝到你服务器上 Git 用户的 authorized_hosts 文件里,或者是你的 Git 主机的 SSH 密钥面板里。
在配置要你要用的主机后,SparkleShare 会下载整个 Git 项目,包括(你可以自己选择)提交历史。可以在 ~/SparkleShare 目录下找到同步完成的文件。
不像 Dolphin 那样的集成方式,SparkleShare 是不透明的,让人心里没底。在你做出改动后,它会悄悄地把改动同步到服务器远端项目中。对大部分人来说,这样做有一个很大的好处:可以用到 Git 的全部威力但是不用维护。对我来说,这样有些乱,因为我想自己管理我的提交以及要用的分支。
SparkleShare 可能不适合所有人,但是它是一个强大而且简单的 Git 解决方案,展示了不同的开源项目完美地协调整合到一起后所创造出的独特项目。
Git-cola
另一种配合 Git 仓库工作的模型,没那么原生,更多的是监视方式;不是使用一个集成的应用程序和你的 Git 项目直接交互,而是你可以使用一个桌面客户端来监视项目改动,并随意处理每一个改动。这种方式的一个优势就是专注。当你实际只用到项目里的三个文件的时候,你可能不会关心所有的 125 个文件,能将这三个文件挑出来就很方便了。
如果你觉得有好多 Git 托管网站,那只是你还不知道 Git 客户端有多少。桌面上的 Git 客户端 上有一大把。实际上,Git 默认自带一个图形客户端。它们中最跨平台、最可配置的就是开源的 Git-cola 客户端,用 Python 和 Qt 写的。
如果你在用 Linux,Git-cola 应该在你的软件仓库里就有。不是的话,可以直接从它的网站下载并安装:
$ python setup.py install
启动 git-cola 后,会有三个按钮用来打开仓库,创建新仓库,或克隆仓库。
不管选哪个,最终都会停在一个 Git 仓库中。和大多数我用过的客户端一样,Git-cola 不会尝试成为你的仓库的接口;它们一般会让操作系统工具来做这个。换句话说,我可以通过 Git-cola 创建一个仓库,但随后我就在 Thunar 或 Emacs 里打开仓库开始工作。打开 Git-cola 来监视仓库很不错,因为当你创建新文件,或者改动文件的时候,它们都会出现在 Git-cola 的状态面板里。
Git-cola 的默认布局不是线性的。我喜欢从左向右分布,因为 Git-cola 是高度可配置的,所以你可以随便修改布局。我自己设置成最左边是状态面板,显示当前分支的任何改动,然后右边是差异面板,可以浏览当前改动,然后是动作面板,放一些常用任务的快速按钮,最后,最右边是提交面板,可以写提交信息。
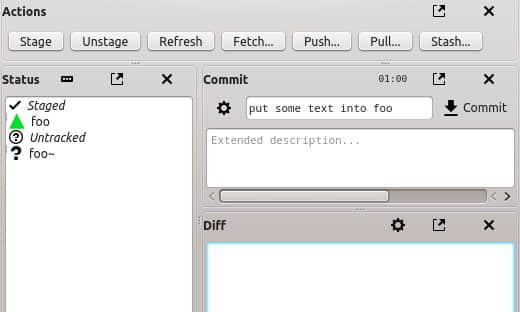
不管怎么改布局,下面是 Git-cola 的通用流程:
改动会出现在状态面板里。右键点击一个改动或选中一个文件,然后在动作面板里点击 Stage 按钮来将文件加入待提交暂存区。
待提交文件的图标会变成绿色三角形,表示该文件有改动并且正等待提交。你也可以右键点击并选择 Unstage Selected 将改动移出待提交暂存区,或者点击动作面板里的 Unstage 按钮。
在差异面板里检查你的改动。
当准备好提交后,输入提交信息并点击 Commit 按钮。
在动作面板里还有其它按钮用来处理其它普通任务,比如拉取或推送。菜单里有更多的任务列表,比如用于操作分支,改动审查,变基等等的专用操作。
我更愿意将 Git-cola 当作文件管理器的一个浮动面板(在不能用 Dolphin 的时候我只用 Git-cola)。虽然它的交互性没有完全集成 Git 的文件管理器那么强,但另一方面,它几乎提供了原始 Git 命令的所有功能,所以它实际上更为强大。
有很多 Git 图形客户端。有些是不提供源代码的付费软件,有些只是用来查看,有些尝试加入新的特定术语(用 "sync" 替代 "push" ...?) 来重造 Git,也有一些只适合特定的平台。Git-cola 一直是能在任意平台上使用的最简单的客户端,也是最贴近纯粹 Git 命令的,可以让用户在使用过程中学习 Git,即便是高手也会很满意它的界面和术语。
Git 命令还是图形界面?
我一般不用图形工具来操作 Git;一般我使用上面介绍的工具时,只是帮助其他人找出适合他们的界面。不过,最终归结于怎么适合你的工作。我喜欢基于终端的 Git 命令是因为它可以很好地集成到 Emacs 里,但如果某天我几乎都在用 Inkscape 工作时,我一般会很自然地使用 Dolphin 里带的 Git,因为我在 Dolphin 环境里。
如何使用 Git 你可以自己选择;但要记住 Git 是一种让生活更轻松的方式,也是让你在工作中更安全地尝试一些疯狂点子的方法。熟悉 Git 的工作模式,然后不管以什么方式使用 Git,只要能让你觉得最适合就可以。
在下一期文章里,我们将了解如何架设和管理 Git 服务器,包括用户权限和管理,以及运行定制脚本。
via: https://opensource.com/life/16/8/graphical-tools-git
作者:Seth Kenlon 译者:zpl1025 校对:wxy