如何为你的平台部署一个公开的系统状态页
如果你是一个系统管理员,负责关键的 IT 基础设置或公司的服务,你将明白有效的沟通在日常任务中的重要性。假设你的线上存储服务器故障了。你希望团队所有人达成共识你好尽快的解决问题。当你忙来忙去时,你不会想一半的人问你为什么他们不能访问他们的文档。当一个维护计划快到时间了你想在计划前提醒相关人员,这样避免了不必要的开销。
这一切的要求或多或少改进了你、你的团队、和你服务的用户之间沟通渠道。一个实现它的方法是维护一个集中的系统状态页面,报告和记录故障停机详情、进度更新和维护计划等。这样,在故障期间你避免了不必要的打扰,也可以提醒一些相关方,以及加入一些可选的状态更新。
有一个不错的开源, 自承载系统状态页解决方案叫做 Cachet。在这个教程,我将要描述如何用 Cachet 部署一个自承载系统状态页面。
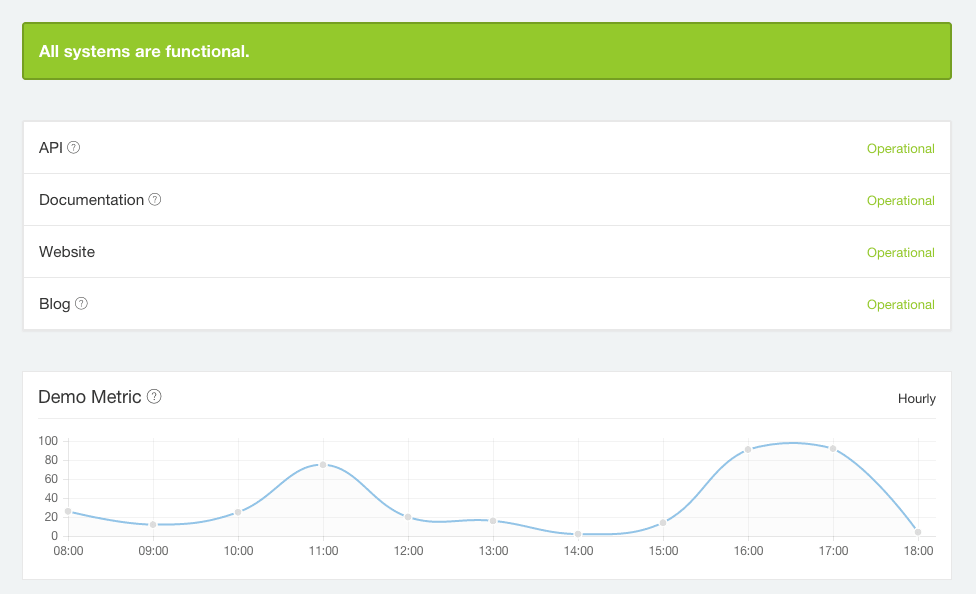
Cachet 特性
在详细的配置 Cachet 之前,让我简单的介绍一下它的主要特性。
- 全 JSON API:Cachet API 可以让你使用任意的外部程序或脚本(例如,uptime 脚本)连接到 Cachet 来自动报告突发事件或更新状态。
- 认证:Cachet 支持基础认证和 JSON API 的 API 令牌,所以只有认证用户可以更新状态页面。
- 衡量系统:这通常用来展现随着时间推移的自定义数据(例如,服务器负载或者响应时间)。
- 通知:可选地,你可以给任一注册了状态页面的人发送突发事件的提示邮件。
- 多语言:状态页被翻译为11种不同的语言。
- 双因子认证:这允许你使用 Google 的双因子认证来提升 Cachet 管理账户的安全性。
- 跨数据库支持:你可以选择 MySQL,SQLite,Redis,APC 和 PostgreSQL 作为后端存储。
剩下的教程,我会说明如何在 Linux 上安装配置 Cachet。
第一步:下载和安装 Cachet
Cachet 需要一个 web 服务器和一个后端数据库来运转。在这个教程中,我将使用 LAMP 架构。以下是一些特定发行版上安装 Cachet 和 LAMP 架构的指令。
Debian,Ubuntu 或者 Linux Mint
$ sudo apt-get install curl git apache2 mysql-server mysql-client php5 php5-mysql
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
$ cd /var/www/cachet
$ sudo git checkout v1.1.1
$ sudo chown -R www-data:www-data .
在基于 Debian 的系统上设置 LAMP 架构的更多细节,参考这个教程。
Fedora, CentOS 或 RHEL
在基于 Red Hat 系统上,你首先需要设置 REMI 软件库(以满足 PHP 的版本需求)。然后执行下面命令。
$ sudo yum install curl git httpd mariadb-server
$ sudo yum --enablerepo=remi-php56 install php php-mysql php-mbstring
$ sudo git clone https://github.com/cachethq/Cachet.git /var/www/cachet
$ cd /var/www/cachet
$ sudo git checkout v1.1.1
$ sudo chown -R apache:apache .
$ sudo firewall-cmd --permanent --zone=public --add-service=http
$ sudo firewall-cmd --reload
$ sudo systemctl enable httpd.service; sudo systemctl start httpd.service
$ sudo systemctl enable mariadb.service; sudo systemctl start mariadb.service
在基于 Red Hat 系统上设置 LAMP 的更多细节,参考这个教程。
配置 Cachet 的后端数据库
下一步是配置后端数据库。
登录到 MySQL/MariaDB 服务,然后创建一个空的数据库称为‘cachet’。
$ sudo mysql -uroot -p
mysql> create database cachet;
mysql> quit
现在用一个示例配置文件创建一个 Cachet 配置文件。
$ cd /var/www/cachet
$ sudo mv .env.example .env
在 .env 文件里,填写你自己设置的数据库信息(例如,DB\_*)。其他的字段先不改变。
APP_ENV=production
APP_DEBUG=false
APP_URL=http://localhost
APP_KEY=SomeRandomString
DB_DRIVER=mysql
DB_HOST=localhost
DB_DATABASE=cachet
DB_USERNAME=root
DB_PASSWORD=<root-password>
CACHE_DRIVER=apc
SESSION_DRIVER=apc
QUEUE_DRIVER=database
MAIL_DRIVER=smtp
MAIL_HOST=mailtrap.io
MAIL_PORT=2525
MAIL_USERNAME=null
MAIL_PASSWORD=null
MAIL_ADDRESS=null
MAIL_NAME=null
REDIS_HOST=null
REDIS_DATABASE=null
REDIS_PORT=null
第三步:安装 PHP 依赖和执行数据库迁移
下面,我们将要安装必要的PHP依赖包。我们会使用 composer 来安装。如果你的系统还没有安装 composer,先安装它:
$ curl -sS https://getcomposer.org/installer | sudo php -- --install-dir=/usr/local/bin --filename=composer
现在开始用 composer 安装 PHP 依赖包。
$ cd /var/www/cachet
$ sudo composer install --no-dev -o
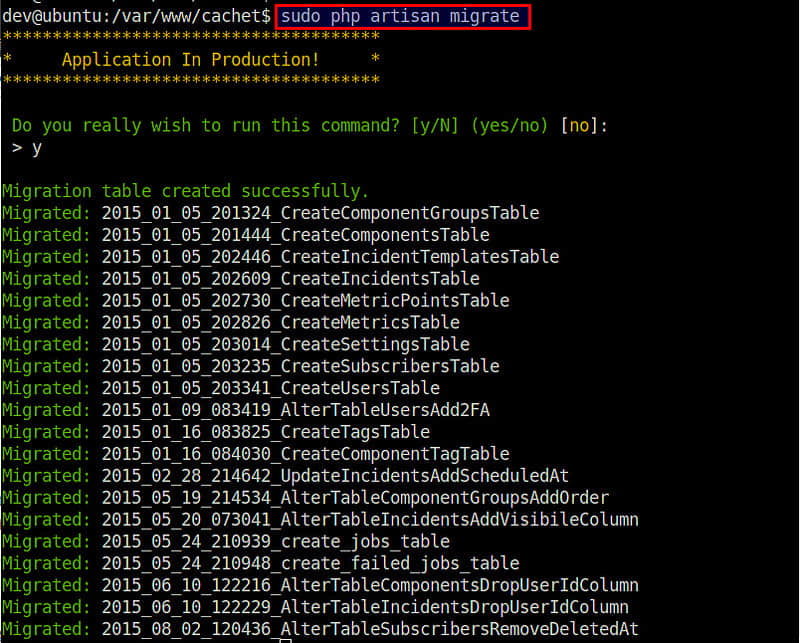
下面执行一次性的数据库迁移。这一步会在我们之前创建的数据库里面创建那些所需的表。
$ sudo php artisan migrate
假设在 /var/www/cachet/.env 的数据库配置无误,数据库迁移应该像下面显示一样成功完成。
下面,创建一个密钥,它将用来加密进入 Cachet 的数据。
$ sudo php artisan key:generate
$ sudo php artisan config:cache
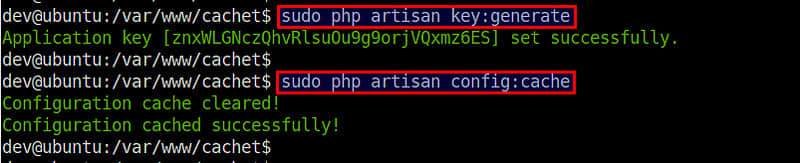
生成的应用密钥将自动添加到你的 .env 文件 APP\_KEY 变量中。你不需要自己编辑 .env。
第四步:配置 Apache HTTP 服务
现在到了配置运行 Cachet 的 web 服务的时候了。我们使用 Apache HTTP 服务器,为 Cachet 创建一个新的虚拟主机,如下:
Debian,Ubuntu 或 Linux Mint
$ sudo vi /etc/apache2/sites-available/cachet.conf
<VirtualHost *:80>
ServerName cachethost
ServerAlias cachethost
DocumentRoot "/var/www/cachet/public"
<Directory "/var/www/cachet/public">
Require all granted
Options Indexes FollowSymLinks
AllowOverride All
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
启用新虚拟主机和 mod\_rewrite:
$ sudo a2ensite cachet.conf
$ sudo a2enmod rewrite
$ sudo service apache2 restart
Fedora, CentOS 或 RHEL
在基于 Red Hat 系统上,创建一个虚拟主机文件,如下:
$ sudo vi /etc/httpd/conf.d/cachet.conf
<VirtualHost *:80>
ServerName cachethost
ServerAlias cachethost
DocumentRoot "/var/www/cachet/public"
<Directory "/var/www/cachet/public">
Require all granted
Options Indexes FollowSymLinks
AllowOverride All
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
现在重载 Apache 配置:
$ sudo systemctl reload httpd.service
第五步:配置 /etc/hosts 来测试 Cachet
这时候,初始的 Cachet 状态页面应该启动运行了,现在测试一下。
由于 Cachet 被配置为Apache HTTP 服务的虚拟主机,我们需要调整你的客户机的 /etc/hosts 来访问他。你将从这个客户端电脑访问 Cachet 页面。(LCTT 译注:如果你给了这个页面一个正式的主机地址,则不需要这一步。)
打开 /etc/hosts,加入如下行:
$ sudo vi /etc/hosts
<cachet 服务器的 IP 地址> cachethost
上面名为“cachethost”必须匹配 Cachet 的 Apache 虚拟主机文件的 ServerName。
测试 Cachet 状态页面
现在你准备好访问 Cachet 状态页面。在你浏览器地址栏输入 http://cachethost。你将被转到如下的 Cachet 状态页的初始化设置页面。
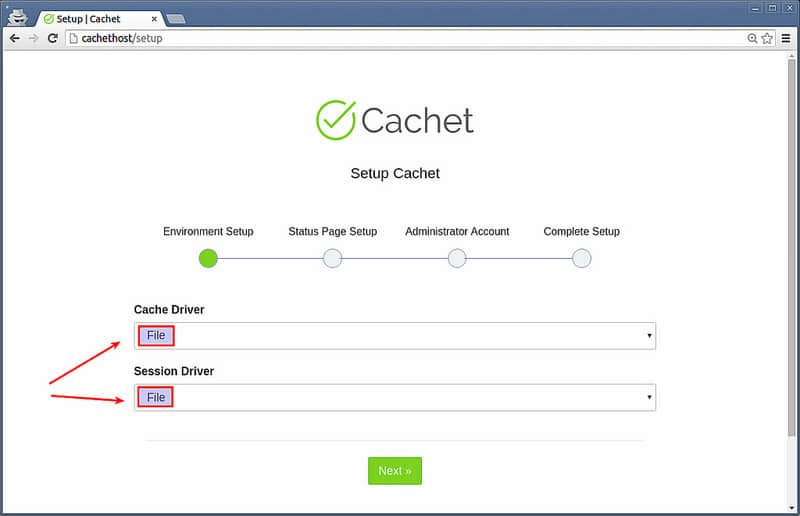
选择 cache/session 驱动。这里 cache 和 session 驱动两个都选“File”。
下一步,输入关于状态页面的基本信息(例如,站点名称、域名、时区和语言),以及管理员认证账户。
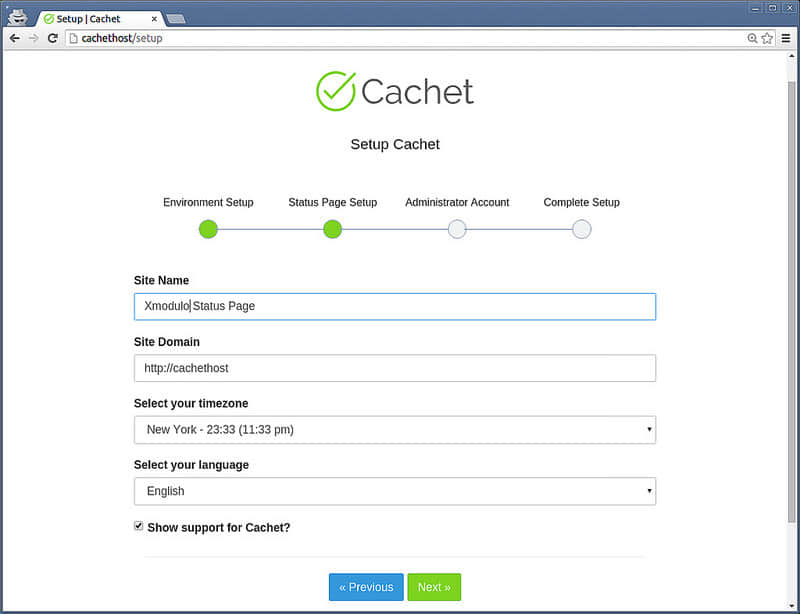
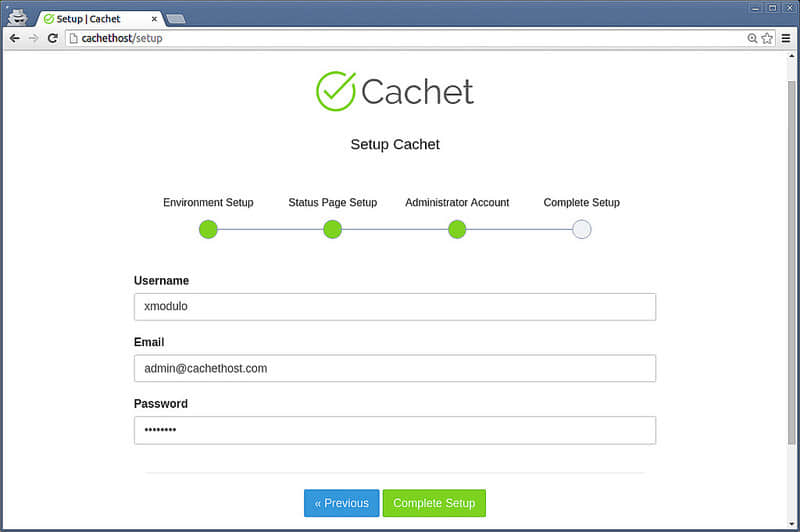
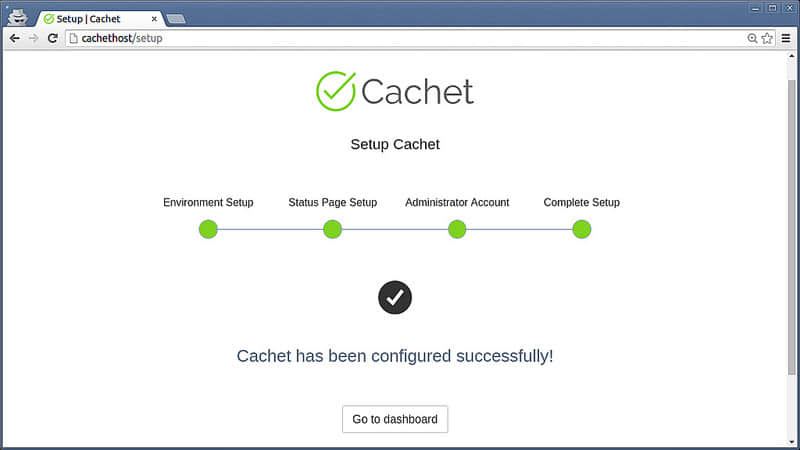
你的状态页初始化就要完成了。
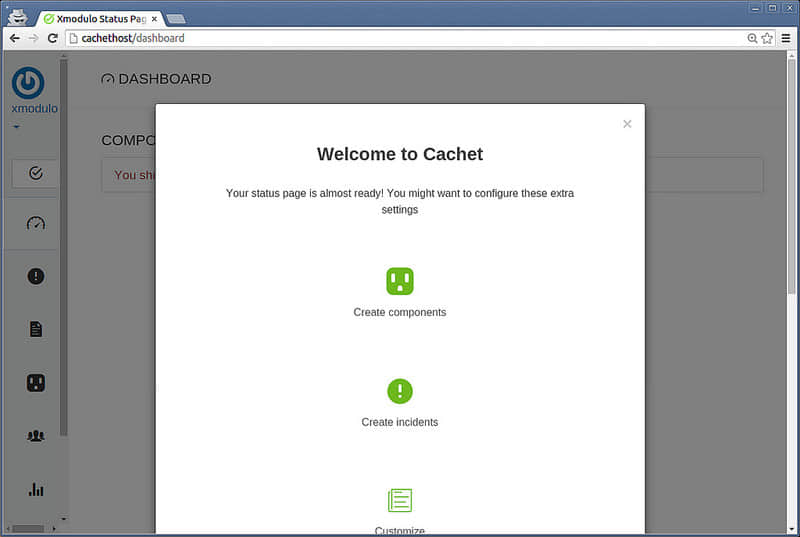
继续创建组件(你的系统单元)、事件或者任意你要做的维护计划。
例如,增加一个组件:
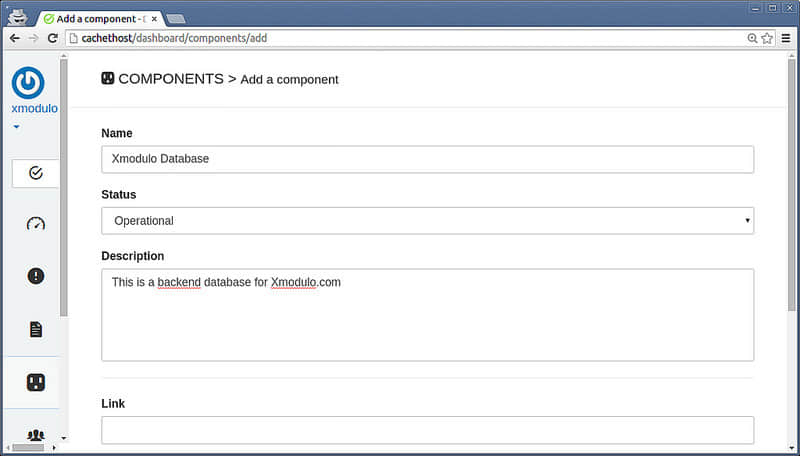
增加一个维护计划:
公共 Cachet 状态页就像这样:
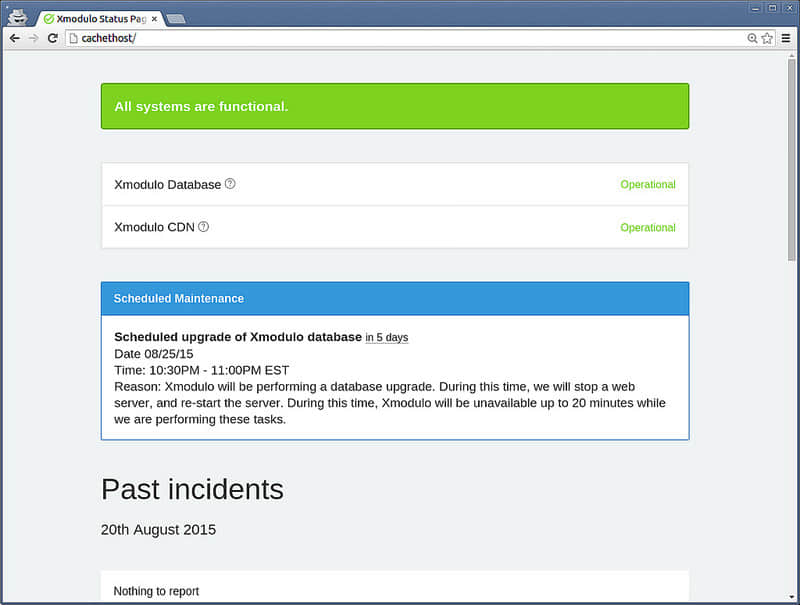
集成了 SMTP,你可以在状态更新时发送邮件给订阅者。并且你可以使用 CSS 和 markdown 格式来完全自定义布局和状态页面。
结论
Cachet 是一个相当易于使用,自托管的状态页面软件。Cachet 一个高级特性是支持全 JSON API。使用它的 RESTful API,Cachet 可以轻松连接单独的监控后端(例如,Nagios),然后回馈给 Cachet 事件报告并自动更新状态。比起手工管理一个状态页它更快和有效率。
最后一句,我喜欢提及一个事。用 Cachet 设置一个漂亮的状态页面是很简单的,但要将这个软件用好并不像安装它那么容易。你需要完全保障所有 IT 团队习惯准确及时的更新状态页,从而建立公共信息的准确性。同时,你需要教用户去查看状态页面。最后,如果没有很好的填充数据,部署状态页面就没有意义,并且/或者没有一个人查看它。记住这个,尤其是当你考虑在你的工作环境中部署 Cachet 时。
故障排查
补充,万一你安装 Cachet 时遇到问题,这有一些有用的故障排查的技巧。
- Cachet 页面没有加载任何东西,并且你看到如下报错。
production.ERROR: exception 'RuntimeException' with message 'No supported encrypter found. The cipher and / or key length are invalid.' in /var/www/cachet/bootstrap/cache/compiled.php:6695
解决方案:确保你创建了一个应用密钥,以及明确配置缓存如下所述。
$ cd /path/to/cachet
$ sudo php artisan key:generate
$ sudo php artisan config:cache
- 调用 composer 命令时有如下报错。
- danielstjules/stringy 1.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
- laravel/framework v5.1.8 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
- league/commonmark 0.10.0 requires ext-mbstring * -the requested PHP extension mbstring is missing from your system.
解决方案:确保在你的系统上安装了必要的 PHP 扩展 mbstring ,并且兼容你的 PHP 版本。在基于 Red Hat 的系统上,由于我们从 REMI-56 库安装PHP,所以要从同一个库安装扩展。
$ sudo yum --enablerepo=remi-php56 install php-mbstring
- 你访问 Cachet 状态页面时得到一个白屏。HTTP 日志显示如下错误。
PHP Fatal error: Uncaught exception 'UnexpectedValueException' with message 'The stream or file "/var/www/cachet/storage/logs/laravel-2015-08-21.log" could not be opened: failed to open stream: Permission denied' in /var/www/cachet/bootstrap/cache/compiled.php:12851
解决方案:尝试如下命令。
$ cd /var/www/cachet
$ sudo php artisan cache:clear
$ sudo chmod -R 777 storage
$ sudo composer dump-autoload
如果上面的方法不起作用,试试禁止 SELinux:
$ sudo setenforce 0
via: http://xmodulo.com/setup-system-status-page.html