Linux系统的启动方式有点复杂,而且总是有需要优化的地方。传统的Linux系统启动过程主要由著名的init进程(也被称为SysV init启动系统)处理,而基于init的启动系统被认为有效率不足的问题,systemd是Linux系统机器的另一种启动方式,宣称弥补了以传统Linux SysV init为基础的系统的缺点。在这里我们将着重讨论systemd的特性和争议,但是为了更好地理解它,也会看一下通过传统的以SysV init为基础的系统的Linux启动过程是什么样的。友情提醒一下,systemd仍然处在测试阶段,而未来发布的Linux操作系统也正准备用systemd启动管理程序替代当前的启动过程(LCTT 译注:截止到本文发表,主流的Linux发行版已经有很多采用了 systemd)。
理解Linux启动过程
在我们打开Linux电脑的电源后第一个启动的进程就是init。分配给init进程的PID是1。它是系统其他所有进程的父进程。当一台Linux电脑启动后,处理器会先在系统存储中查找BIOS,之后BIOS会检测系统资源然后找到第一个引导设备,通常为硬盘,然后会查找硬盘的主引导记录(MBR),然后加载到内存中并把控制权交给它,以后的启动过程就由MBR控制。
主引导记录会初始化引导程序(Linux上有两个著名的引导程序,GRUB和LILO,80%的Linux系统在用GRUB引导程序),这个时候GRUB或LILO会加载内核模块。内核会马上查找/sbin下的“init”程序并执行它。从这里开始init成为了Linux系统的父进程。init读取的第一个文件是/etc/inittab,通过它init会确定我们Linux操作系统的运行级别。它会从文件/etc/fstab里查找分区表信息然后做相应的挂载。然后init会启动/etc/init.d里指定的默认启动级别的所有服务/脚本。所有服务在这里通过init一个一个被初始化。在这个过程里,init每次只启动一个服务,所有服务/守护进程都在后台执行并由init来管理。
关机过程差不多是相反的过程,首先init停止所有服务,最后阶段会卸载文件系统。
以上提到的启动过程有一些不足的地方。而用一种更好的方式来替代传统init的需求已经存在很长时间了。也产生了许多替代方案。其中比较著名的有Upstart,Epoch,Muda和Systemd。而Systemd获得最多关注并被认为是目前最佳的方案。
理解Systemd
开发Systemd的主要目的就是减少系统引导时间和计算开销。Systemd(系统管理守护进程),最开始以GNU GPL协议授权开发,现在已转为使用GNU LGPL协议,它是如今讨论最热烈的引导和服务管理程序。如果你的Linux系统配置为使用Systemd引导程序,它取替传统的SysV init,启动过程将交给systemd处理。Systemd的一个核心功能是它同时支持SysV init的后开机启动脚本。
Systemd引入了并行启动的概念,它会为每个需要启动的守护进程建立一个套接字,这些套接字对于使用它们的进程来说是抽象的,这样它们可以允许不同守护进程之间进行交互。Systemd会创建新进程并为每个进程分配一个控制组(cgroup)。处于不同控制组的进程之间可以通过内核来互相通信。systemd处理开机启动进程的方式非常漂亮,和传统基于init的系统比起来优化了太多。让我们看下Systemd的一些核心功能。
- 和init比起来引导过程简化了很多
- Systemd支持并发引导过程从而可以更快启动
- 通过控制组来追踪进程,而不是PID
- 优化了处理引导过程和服务之间依赖的方式
- 支持系统快照和恢复
- 监控已启动的服务;也支持重启已崩溃服务
- 包含了systemd-login模块用于控制用户登录
- 支持加载和卸载组件
- 低内存使用痕迹以及任务调度能力
- 记录事件的Journald模块和记录系统日志的syslogd模块
Systemd同时也清晰地处理了系统关机过程。它在/usr/lib/systemd/目录下有三个脚本,分别叫systemd-halt.service,systemd-poweroff.service,systemd-reboot.service。这几个脚本会在用户选择关机,重启或待机时执行。在接收到关机事件时,systemd首先卸载所有文件系统并停止所有内存交换设备,断开存储设备,之后停止所有剩下的进程。

Systemd结构概览
让我们看一下Linux系统在使用systemd作为引导程序时的开机启动过程的结构性细节。为了简单,我们将在下面按步骤列出来这个过程:
1. 当你打开电源后电脑所做的第一件事情就是BIOS初始化。BIOS会读取引导设备设定,定位并传递系统控制权给MBR(假设硬盘是第一引导设备)。
2. MBR从Grub或LILO引导程序读取相关信息并初始化内核。接下来将由Grub或LILO继续引导系统。如果你在grub配置文件里指定了systemd作为引导管理程序,之后的引导过程将由systemd完成。Systemd使用“target”来处理引导和服务管理过程。这些systemd里的“target”文件被用于分组不同的引导单元以及启动同步进程。
3. systemd执行的第一个目标是default.target。但实际上default.target是指向graphical.target的软链接。Linux里的软链接用起来和Windows下的快捷方式一样。文件Graphical.target的实际位置是/usr/lib/systemd/system/graphical.target。在下面的截图里显示了graphical.target文件的内容。

4. 在这个阶段,会启动multi-user.target而这个target将自己的子单元放在目录“/etc/systemd/system/multi-user.target.wants”里。这个target为多用户支持设定系统环境。非root用户会在这个阶段的引导过程中启用。防火墙相关的服务也会在这个阶段启动。

"multi-user.target"会将控制权交给另一层“basic.target”。

5. "basic.target"单元用于启动普通服务特别是图形管理服务。它通过/etc/systemd/system/basic.target.wants目录来决定哪些服务会被启动,basic.target之后将控制权交给sysinit.target.

6. "sysinit.target"会启动重要的系统服务例如系统挂载,内存交换空间和设备,内核补充选项等等。sysinit.target在启动过程中会传递给local-fs.target。这个target单元的内容如下面截图里所展示。
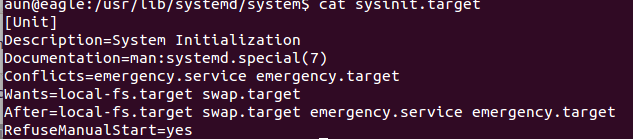
7. local-fs.target,这个target单元不会启动用户相关的服务,它只处理底层核心服务。这个target会根据/etc/fstab和/etc/inittab来执行相关操作。
系统引导性能分析
Systemd提供了工具用于识别和定位引导相关的问题或性能影响。Systemd-analyze是一个内建的命令,可以用来检测引导过程。你可以找出在启动过程中出错的单元,然后跟踪并改正引导组件的问题。在下面列出一些常用的systemd-analyze命令。
systemd-analyze time 用于显示内核和普通用户空间启动时所花的时间。
$ systemd-analyze time
Startup finished in 1440ms (kernel) + 3444ms (userspace)
systemd-analyze blame 会列出所有正在运行的单元,按从初始化开始到当前所花的时间排序,通过这种方式你就知道哪些服务在引导过程中要花较长时间来启动。
$ systemd-analyze blame
2001ms mysqld.service
234ms httpd.service
191ms vmms.service
systemd-analyze verify 显示在所有系统单元中是否有语法错误。
systemd-analyze plot 可以用来把整个引导过程写入一个SVG格式文件里。整个引导过程非常长不方便阅读,所以通过这个命令我们可以把输出写入一个文件,之后再查看和分析。下面这个命令就是做这个。
systemd-analyze plot > boot.svg
Systemd的争议
Systemd并没有幸运地获得所有人的青睐,一些专家和管理员对于它的工作方式和开发有不同意见。根据对于Systemd的批评,它不是“类Unix”方式因为它试着替换一些系统服务。一些专家也不喜欢使用二进制配置文件的想法。据说编辑systemd配置非常困难而且没有一个可用的图形工具。
如何在Ubuntu 14.04和12.04上测试Systemd
本来,Ubuntu决定从Ubuntu 16.04 LTS开始使用Systemd来替换当前的引导过程。Ubuntu 16.04预计在2016年4月发布,但是考虑到Systemd的流行和需求,刚刚发布的Ubuntu 15.04采用它作为默认引导程序。另外,Ubuntu 14.04 Trusty Tahr和Ubuntu 12.04 Precise Pangolin的用户可以在他们的机器上测试Systemd。测试过程并不复杂,你所要做的只是把相关的PPA包含到系统中,更新仓库并升级系统。
声明:请注意它仍然处于Ubuntu的测试和开发阶段。升级测试包可能会带来一些未知错误,最坏的情况下有可能损坏你的系统配置。请确保在尝试升级前已经备份好重要数据。
在终端里运行下面的命令来添加PPA到你的Ubuntu系统里:
sudo add-apt-repository ppa:pitti/systemd
你将会看到警告信息因为我们尝试使用临时/测试PPA,而它们是不建议用于实际工作机器上的。
然后运行下面的命令更新APT包管理仓库。
sudo apt-get update
运行下面的命令升级系统。
sudo apt-get dist-upgrade
就这些,你应该已经可以在你的Ubuntu系统里看到Systemd配置文件了,打开/lib/systemd/目录可以看到这些文件。
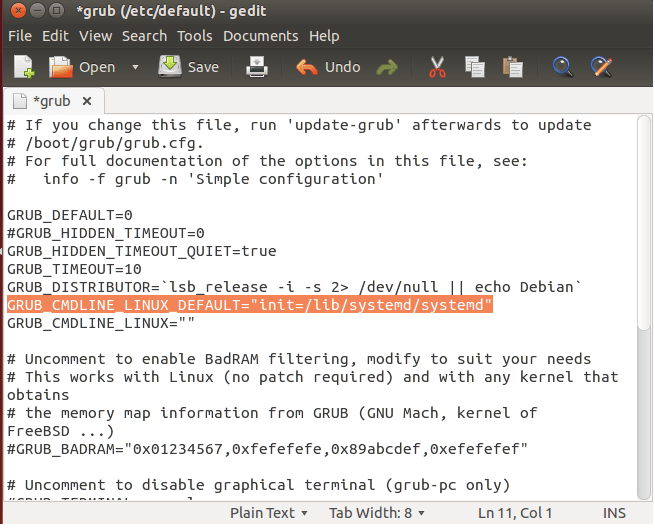
好吧,现在让我们编辑一下grub配置文件指定systemd作为默认引导程序。可以使用Gedit文字编辑器编辑grub配置文件。
sudo gedit /etc/default/grub

在文件里修改GRUBCMDLINELINUX\_DEFAULT项,设定它的参数为:“init=/lib/systemd/systemd”
就这样,你的Ubuntu系统已经不再使用传统的引导程序了,改为使用Systemd管理器。重启你的机器然后查看systemd引导过程吧。
结论
Systemd毫无疑问为改进Linux引导过程前进了一大步;它包含了一套漂亮的库和守护进程配合工作来优化系统引导和关闭过程。许多Linux发行版正准备将它作为自己的正式引导程序。在以后的Linux发行版中,我们将有望看到systemd开机。但是另一方面,为了获得成功并广泛应用,systemd仍需要认真处理批评意见。
via: http://linoxide.com/linux-how-to/systemd-boot-process/
作者:Aun Raza 译者:zpl1025 校对:wxy
本文由 LCTT 原创翻译,Linux中国 荣誉推出