想象一下你正在开发一个激进的新功能。这将是很灿烂的但它需要一段时间。您这几天也许是几个星期一直在做这个。

你的功能分支已经超前master有6个提交了。你是一个优秀的开发人员并做了有意义的语义提交。但有一件事情:你开始慢慢意识到,这个疯狂的东西仍需要更多的时间才能真的做好准备被合并回主分支。
m1-m2-m3-m4 (master)
\
f1-f2-f3-f4-f5-f6(feature)
你也知道的是,一些地方实际上是交叉不大的新功能。它们可以更早地合并到主分支。不幸的是,你想将部分合并到主分支的内容存在于你六个提交中的某个地方。更糟糕的是,它也包含了依赖于你的功能分支的之前的提交。有人可能会说,你应该在第一处地方做两次提交,但没有人是完美的。
m1-m2-m3-m4 (master)
\
f1-f2-f3-f4-f5-f6(feature)
^
|
mixed commit
在你准备提交的时间,你没有预见到,你可能要逐步把该功能合并入主分支。哎呀!你不会想到这件事会有这么久。
你需要的是一种方法可以回溯历史,把它并分成两次提交,这样就可以把代码都安全地分离出来,并可以移植到master分支。
用图说话,就是我们需要这样。
m1-m2-m3-m4 (master)
\
f1-f2-f3a-f3b-f4-f5-f6(feature)
在将工作分成两个提交后,我们就可以cherry-pick出前面的部分到主分支了。
原来Git自带了一个功能强大的命令git rebase -i ,它可以让我们这样做。它可以让我们改变历史。改变历史可能会产生问题,作为一个经验,应尽快避免历史与他人共享。不过在我们的例子中,我们只是改变我们的本地功能分支的历史。没有人会受到伤害。就这么做了!
好吧,让我们来仔细看看f3提交究竟修改了什么。原来我们共修改了两个文件:userService.js和wishlistService.js。比方说,userService.js的更改可以直接合入主分支而wishlistService.js不能。因为wishlistService.js甚至不存在在主分支里面。它是f1提交中引入的。
专家提示:即使是在一个文件中更改,git也可以搞定。但这篇博客中我们先简化情况。
我们已经建立了一个公众演示仓库,我们将使用这个来练习。为了便于跟踪,每一个提交信息的前缀是在上面的图表中使用的假的SHA。以下是git在分开提交f3时的分支图。
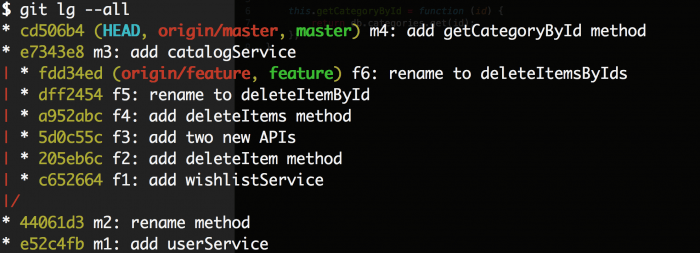
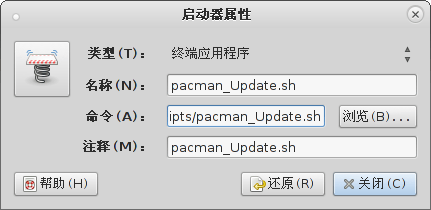
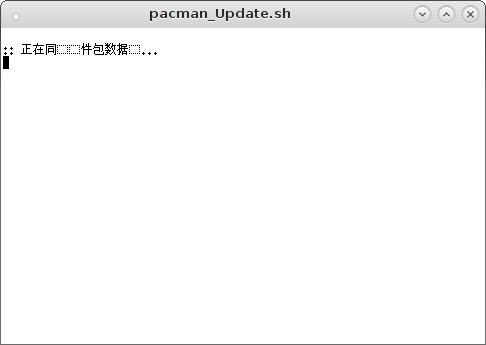
现在,我们要做的第一件事就是使用git的checkout功能checkout出我们的功能分支。用git rebase -i master开始做rebase。
现在接下来git会用所配置的编辑器打开(默认为Vim)一个临时文件。
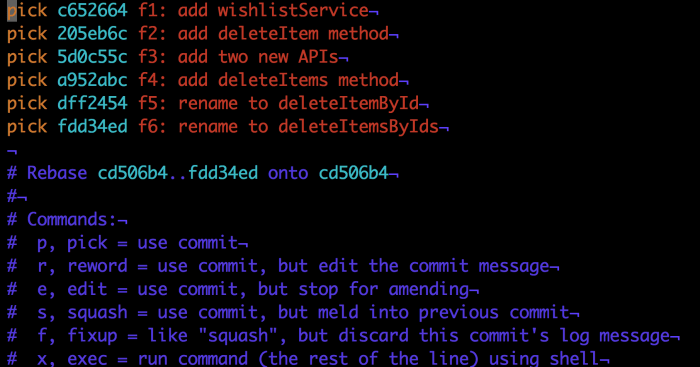
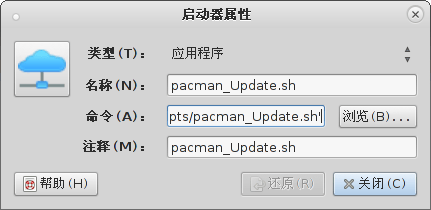
该文件为您提供一些rebase选择,它带有一个提示(蓝色文字)。对于每一个提交,我们可以选择的动作有pick、rwork、edit、squash、fixup和exec。每一个动作也可以通过它的缩写形式p、r、e、s、f和e引用。描述每一个选项超出了本文范畴,所以让我们专注于我们的具体任务。
我们要为f3提交选择edit选项,因此我们把内容改变成这样。
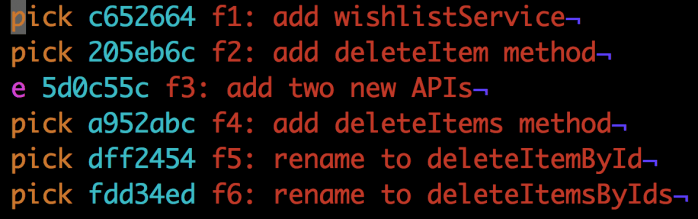
现在我们保存文件(在Vim中是按下后输入:wq,最后是按下回车)。接下来我们注意到git在编辑选项中选择的提交处停止了rebase。
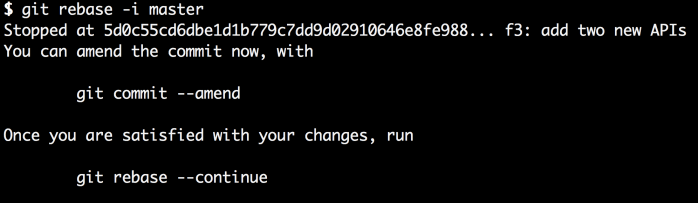
这意味这git开始将f1、f2、f3生效仿佛它就是常规的rebase,但是在f3生效之后停止。事实上,我们可以看一眼停止的地方的日志就可以证明这一点。
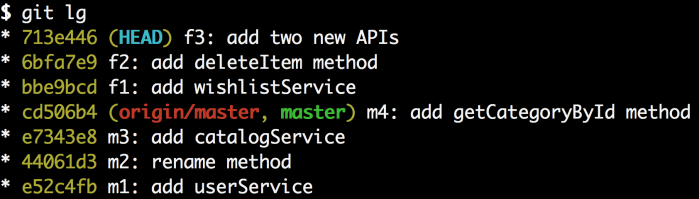
要将f3分成两个提交,我们所要做的是重置git的指针到先前的提交(f2)而保持工作目录和现在一样。这就是git reset在混合模式在做的。由于混合模式是git reset的默认模式,我们可以直接用git reset head~1。就这么做并在运行后用git status看下发生了什么。
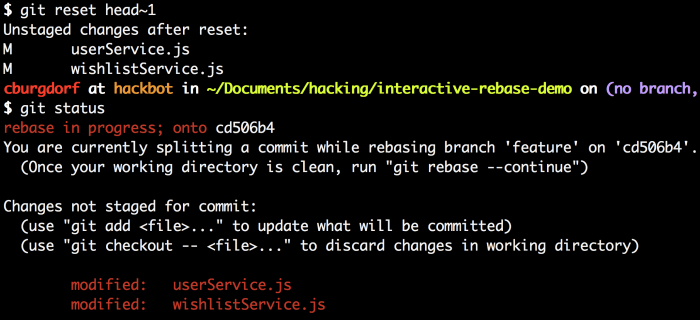
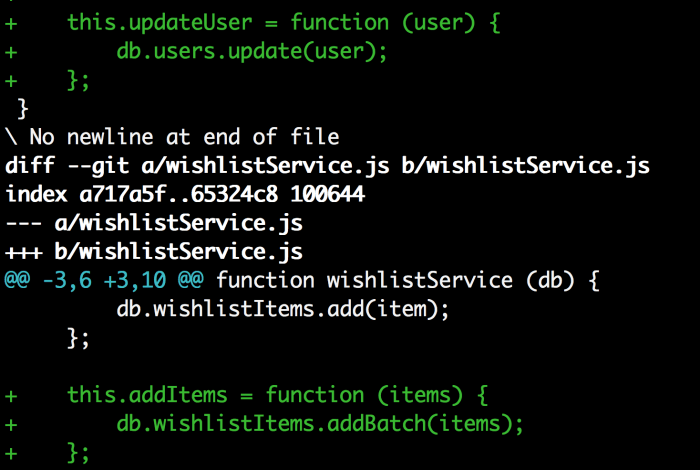
git status告诉我们userService.js和wishlistService.js被修改了。如果我们运行 git diff 我们就可以看见在f3里面确切地做了哪些更改。
如果我们看一眼日志我们会发现f3已经消失了。
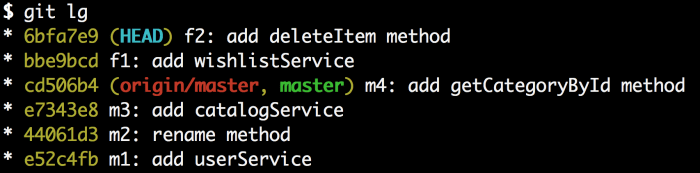
现在我们有了准备提交的先前的f3提交,而原先的f3提交已经消失了。记住虽然我们仍旧在rebase的中间过程。我们的f4、f5、f6提交还没有缺失,它们会在接下来回来。
让我们创建两个新的提交:首先让我们为可以提交到主分支的userService.js创建一个提交。运行git add userService.js 接着运行 git commit -m "f3a: add updateUser method"。
太棒了!让我们为wishlistService.js的改变创建另外一个提交。运行git add wishlistService.js,接着运行git commit -m "f3b: add addItems method".
让我们在看一眼日志。
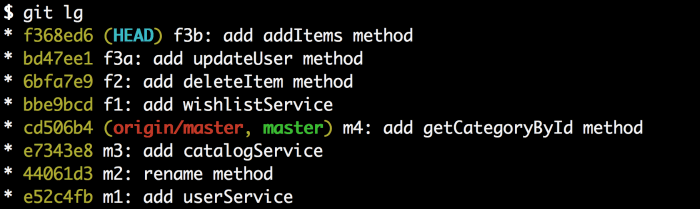
这就是我们想要的,除了f4、f5、f6仍旧缺失。这是因为我们仍在rebase交互的中间,我们需要告诉git继续rebase。用下面的命令继续:git rebase --continue。
让我们再次检查一下日志。
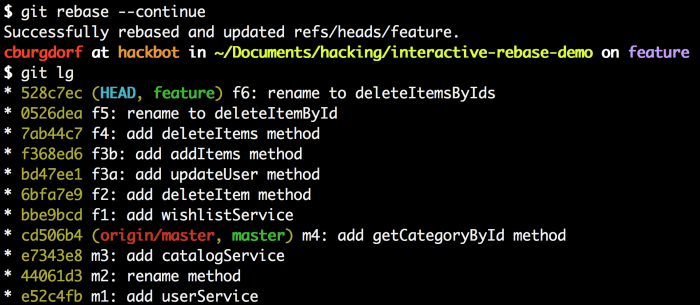
就是这样。我们现在已经得到我们想要的历史了。先前的f3提交现在已经被分割成两个提交f3a和f3b。剩下的最后一件事是cherry-pick出f3a提交到主分支上。
为了完成最后一步,我们首先切换到主分支。我们用git checkout master。现在我们就可以用cherry-pick命令来拾取f3a commit了。本例中我们可以用它的SHA值bd47ee1来引用它。
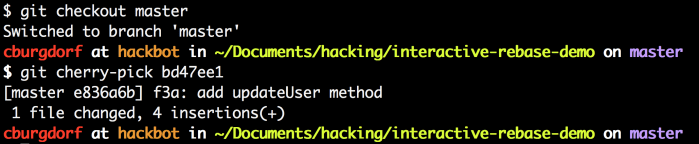
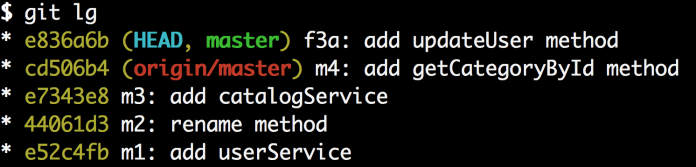
现在f3a这个提交就在主分支的最上面了。这就是我们需要的!
这篇文章的长度看起来需要花费很大的功夫,但实际上对于一个git高级用户而言这只是一会会。
注:Christoph目前正在与Pascal Precht写一本关于Git rebase的书,您可以在leanpub订阅它并在准备出版时获得通知。

本文作者 Christoph Burgdorf自10岁时就是一名程序员,他是HannoverJS Meetup网站的创始人,并且一直活跃在AngularJS社区。他也是非常了解gti的内内外外,在那里他举办一个thoughtram的工作室来帮助初学者掌握该技术。
本的教程最初发表在他的blog。
via: https://www.codementor.io/git-tutorial/git-rebase-split-old-commit-master
作者:cburgdorf 译者:geekpi 校对:wxy
本文由 LCTT 原创翻译,Linux中国 荣誉推出