管理日志的一个最好做法是将你的日志集中或整合到一个地方,特别是在你有许多服务器或多层级架构时。我们将告诉你为什么这是一个好主意,然后给出如何更容易的做这件事的一些小技巧。

集中管理日志的好处
如果你有很多服务器,查看某个日志文件可能会很麻烦。现代的网站和服务经常包括许多服务器层级、分布式的负载均衡器,等等。找到正确的日志将花费很长时间,甚至要花更长时间在登录服务器的相关问题上。没什么比发现你找的信息没有被保存下来更沮丧的了,或者本该保留的日志文件正好在重启后丢失了。
集中你的日志使它们查找更快速,可以帮助你更快速的解决产品问题。你不用猜测那个服务器存在问题,因为所有的日志在同一个地方。此外,你可以使用更强大的工具去分析它们,包括日志管理解决方案。一些解决方案能转换纯文本日志为一些字段,更容易查找和分析。
集中你的日志也可以使它们更易于管理:
- 它们更安全,当它们备份归档到一个单独区域时会有意无意地丢失。如果你的服务器宕机或者无响应,你可以使用集中的日志去调试问题。
- 你不用担心ssh或者低效的grep命令在陷入困境的系统上需要更多的资源。
- 你不用担心磁盘占满,这个能让你的服务器死机。
- 你能保持你的产品服务器的安全性,只是为了查看日志无需给你所有团队登录权限。给你的团队从日志集中区域访问日志权限更安全。
随着集中日志管理,你仍需处理由于网络联通性不好或者耗尽大量网络带宽从而导致不能传输日志到中心区域的风险。在下面的章节我们将要讨论如何聪明的解决这些问题。
流行的日志归集工具
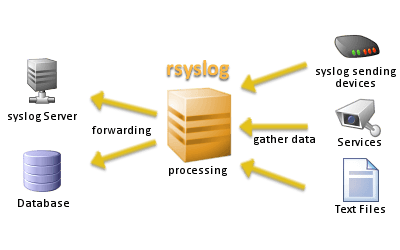
在 Linux 上最常见的日志归集是通过使用 syslog 守护进程或者日志代理。syslog 守护进程支持本地日志的采集,然后通过syslog 协议传输日志到中心服务器。你可以使用很多流行的守护进程来归集你的日志文件:
Rsyslog 是集中日志数据最流行的后台程序,因为它在大多数 Linux 分支上是被默认安装的。你不用下载或安装它,并且它是轻量的,所以不需要占用你太多的系统资源。
如果你需要更多先进的过滤或者自定义分析功能,如果你不在乎额外的系统负载,Logstash 是另一个最流行的选择。
配置 rsyslog.conf
既然 rsyslog 是最广泛使用的系统日志程序,我们将展示如何配置它为日志中心。它的全局配置文件位于 /etc/rsyslog.conf。它加载模块,设置全局指令,和包含位于目录 /etc/rsyslog.d 中的应用的特有的配置。目录中包含的 /etc/rsyslog.d/50-default.conf 指示 rsyslog 将系统日志写到文件。在 rsyslog 文档中你可以阅读更多相关配置。
rsyslog 配置语言是是RainerScript。你可以给日志指定输入,就像将它们输出到另外一个位置一样。rsyslog 已经配置标准输入默认是 syslog ,所以你通常只需增加一个输出到你的日志服务器。这里有一个 rsyslog 输出到一个外部服务器的配置例子。在本例中,BEBOP 是一个服务器的主机名,所以你应该替换为你的自己的服务器名。
action(type="omfwd" protocol="tcp" target="BEBOP" port="514")
你可以发送你的日志到一个有足够的存储容量的日志服务器来存储,提供查询,备份和分析。如果你存储日志到文件系统,那么你应该建立日志轮转来防止你的磁盘爆满。
作为一种选择,你可以发送这些日志到一个日志管理方案。如果你的解决方案是安装在本地你可以发送到系统文档中指定的本地主机和端口。如果你使用基于云提供商,你将发送它们到你的提供商特定的主机名和端口。
日志目录
你可以归集一个目录或者匹配一个通配符模式的所有文件。nxlog 和 syslog-ng 程序支持目录和通配符(*)。
常见的 rsyslog 不能直接监控目录。作为一种解决办法,你可以设置一个定时任务去监控这个目录的新文件,然后配置 rsyslog 来发送这些文件到目的地,比如你的日志管理系统。举个例子,日志管理提供商 Loggly 有一个开源版本的目录监控脚本。
哪个协议: UDP、TCP 或 RELP?
当你使用网络传输数据时,有三个主流协议可以选择。UDP 在你自己的局域网是最常用的,TCP 用在互联网。如果你不能失去(任何)日志,就要使用更高级的 RELP 协议。
UDP 发送一个数据包,那只是一个单一的信息包。它是一个只外传的协议,所以它不会发送给你回执(ACK)。它只尝试发送包。当网络拥堵时,UDP 通常会巧妙的降级或者丢弃日志。它通常使用在类似局域网的可靠网络。
TCP 通过多个包和返回确认发送流式信息。TCP 会多次尝试发送数据包,但是受限于 TCP 缓存的大小。这是在互联网上发送送日志最常用的协议。
RELP 是这三个协议中最可靠的,但是它是为 rsyslog 创建的,而且很少有行业采用。它在应用层接收数据,如果有错误就会重发。请确认你的日志接受位置也支持这个协议。
用磁盘辅助队列可靠的传送
如果 rsyslog 在存储日志时遭遇错误,例如一个不可用网络连接,它能将日志排队直到连接还原。队列日志默认被存储在内存里。无论如何,内存是有限的并且如果问题仍然存在,日志会超出内存容量。
警告:如果你只存储日志到内存,你可能会失去数据。
rsyslog 能在内存被占满时将日志队列放到磁盘。磁盘辅助队列使日志的传输更可靠。这里有一个例子如何配置rsyslog 的磁盘辅助队列:
$WorkDirectory /var/spool/rsyslog # 暂存文件(spool)放置位置
$ActionQueueFileName fwdRule1 # 暂存文件的唯一名字前缀
$ActionQueueMaxDiskSpace 1g # 1gb 空间限制(尽可能大)
$ActionQueueSaveOnShutdown on # 关机时保存日志到磁盘
$ActionQueueType LinkedList # 异步运行
$ActionResumeRetryCount -1 # 如果主机宕机,不断重试
使用 TLS 加密日志
如果你担心你的数据的安全性和隐私性,你应该考虑加密你的日志。如果你使用纯文本在互联网传输日志,嗅探器和中间人可以读到你的日志。如果日志包含私人信息、敏感的身份数据或者政府管制数据,你应该加密你的日志。rsyslog 程序能使用 TLS 协议加密你的日志保证你的数据更安全。
建立 TLS 加密,你应该做如下任务:
- 生成一个证书授权(CA)。在 /contrib/gnutls 有一些证书例子,可以用来测试,但是你需要为产品环境创建自己的证书。如果你正在使用一个日志管理服务,它会给你一个证书。
- 为你的服务器生成一个数字证书使它能启用 SSL 操作,或者使用你自己的日志管理服务提供商的一个数字证书。
- 配置你的 rsyslog 程序来发送 TLS 加密数据到你的日志管理系统。
这有一个 rsyslog 配置 TLS 加密的例子。替换 CERT 和 DOMAIN\_NAME 为你自己的服务器配置。
$DefaultNetstreamDriverCAFile /etc/rsyslog.d/keys/ca.d/CERT.crt
$ActionSendStreamDriver gtls
$ActionSendStreamDriverMode 1
$ActionSendStreamDriverAuthMode x509/name
$ActionSendStreamDriverPermittedPeer *.DOMAIN_NAME.com
应用日志的最佳管理方法
除 Linux 默认创建的日志之外,归集重要的应用日志也是一个好主意。几乎所有基于 Linux 的服务器应用都把它们的状态信息写入到独立、专门的日志文件中。这包括数据库产品,像 PostgreSQL 或者 MySQL,网站服务器,像 Nginx 或者 Apache,防火墙,打印和文件共享服务,目录和 DNS 服务等等。
管理员安装一个应用后要做的第一件事是配置它。Linux 应用程序典型的有一个放在 /etc 目录里 .conf 文件。它也可能在其它地方,但是那是大家找配置文件首先会看的地方。
根据应用程序有多复杂多庞大,可配置参数的数量可能会很少或者上百行。如前所述,大多数应用程序可能会在某种日志文件写它们的状态:配置文件是定义日志设置和其它东西的地方。
如果你不确定它在哪,你可以使用locate命令去找到它:
[root@localhost ~]# locate postgresql.conf
/usr/pgsql-9.4/share/postgresql.conf.sample
/var/lib/pgsql/9.4/data/postgresql.conf
设置一个日志文件的标准位置
Linux 系统一般保存它们的日志文件在 /var/log 目录下。一般是这样,但是需要检查一下应用是否保存它们在 /var/log 下的特定目录。如果是,很好,如果不是,你也许想在 /var/log 下创建一个专用目录?为什么?因为其它程序也在 /var/log 下保存它们的日志文件,如果你的应用保存超过一个日志文件 - 也许每天一个或者每次重启一个 - 在这么大的目录也许有点难于搜索找到你想要的文件。
如果在你网络里你有运行多于一个的应用实例,这个方法依然便利。想想这样的情景,你也许有一打 web 服务器在你的网络运行。当排查任何一个机器的问题时,你就很容易知道确切的位置。
使用一个标准的文件名
给你的应用最新的日志使用一个标准的文件名。这使一些事变得容易,因为你可以监控和追踪一个单独的文件。很多应用程序在它们的日志文件上追加一种时间戳。它让 rsyslog 更难于找到最新的文件和设置文件监控。一个更好的方法是使用日志轮转给老的日志文件增加时间。这样更易去归档和历史查询。
追加日志文件
日志文件会在每个应用程序重启后被覆盖吗?如果这样,我们建议关掉它。每次重启 app 后应该去追加日志文件。这样,你就可以追溯重启前最后的日志。
日志文件追加 vs. 轮转
要是应用程序每次重启后写一个新日志文件,如何保存当前日志?追加到一个单独的、巨大的文件?Linux 系统并不以频繁重启或者崩溃而出名:应用程序可以运行很长时间甚至不间歇,但是也会使日志文件非常大。如果你查询分析上周发生连接错误的原因,你可能无疑的要在成千上万行里搜索。
我们建议你配置应用每天半晚轮转(rotate)它的日志文件。
为什么?首先它将变得可管理。找一个带有特定日期的文件名比遍历一个文件中指定日期的条目更容易。文件也小的多:你不用考虑当你打开一个日志文件时 vi 僵住。第二,如果你正发送日志到另一个位置 - 也许每晚备份任务拷贝到归集日志服务器 - 这样不会消耗你的网络带宽。最后第三点,这样帮助你做日志保留。如果你想剔除旧的日志记录,这样删除超过指定日期的文件比用一个应用解析一个大文件更容易。
日志文件的保留
你保留你的日志文件多长时间?这绝对可以归结为业务需求。你可能被要求保持一个星期的日志信息,或者管理要求保持一年的数据。无论如何,日志需要在一个时刻或其它情况下从服务器删除。
在我们看来,除非必要,只在线保持最近一个月的日志文件,并拷贝它们到第二个地方如日志服务器。任何比这更旧的日志可以被转到一个单独的介质上。例如,如果你在 AWS 上,你的旧日志可以被拷贝到 Glacier。
给日志单独的磁盘分区
更好的,Linux 通常建议挂载到 /var 目录到一个单独的文件系统。这是因为这个目录的高 I/O。我们推荐挂载 /var/log 目录到一个单独的磁盘系统下。这样可以节省与主要的应用数据的 I/O 竞争。另外,如果一些日志文件变的太多,或者一个文件变的太大,不会占满整个磁盘。
日志条目
每个日志条目中应该捕获什么信息?
这依赖于你想用日志来做什么。你只想用它来排除故障,或者你想捕获所有发生的事?这是一个捕获每个用户在运行什么或查看什么的规则条件吗?
如果你正用日志做错误排查的目的,那么只保存错误,报警或者致命信息。没有理由去捕获调试信息,例如,应用也许默认记录了调试信息或者另一个管理员也许为了故障排查而打开了调试信息,但是你应该关闭它,因为它肯定会很快的填满空间。在最低限度上,捕获日期、时间、客户端应用名、来源 ip 或者客户端主机名、执行的动作和信息本身。
一个 PostgreSQL 的实例
作为一个例子,让我们看看 vanilla PostgreSQL 9.4 安装的主配置文件。它叫做 postgresql.conf,与其它Linux 系统中的配置文件不同,它不保存在 /etc 目录下。下列的代码段,我们可以在我们的 Centos 7 服务器的 /var/lib/pgsql 目录下找到它:
root@localhost ~]# vi /var/lib/pgsql/9.4/data/postgresql.conf
...
#------------------------------------------------------------------------------
# ERROR REPORTING AND LOGGING
#------------------------------------------------------------------------------
# - Where to Log -
log_destination = 'stderr'
# Valid values are combinations of
# stderr, csvlog, syslog, and eventlog,
# depending on platform. csvlog
# requires logging_collector to be on.
# This is used when logging to stderr:
logging_collector = on
# Enable capturing of stderr and csvlog
# into log files. Required to be on for
# csvlogs.
# (change requires restart)
# These are only used if logging_collector is on:
log_directory = 'pg_log'
# directory where log files are written,
# can be absolute or relative to PGDATA
log_filename = 'postgresql-%a.log' # log file name pattern,
# can include strftime() escapes
# log_file_mode = 0600 .
# creation mode for log files,
# begin with 0 to use octal notation
log_truncate_on_rotation = on # If on, an existing log file with the
# same name as the new log file will be
# truncated rather than appended to.
# But such truncation only occurs on
# time-driven rotation, not on restarts
# or size-driven rotation. Default is
# off, meaning append to existing files
# in all cases.
log_rotation_age = 1d
# Automatic rotation of logfiles will happen after that time. 0 disables.
log_rotation_size = 0 # Automatic rotation of logfiles will happen after that much log output. 0 disables.
# These are relevant when logging to syslog:
#syslog_facility = 'LOCAL0'
#syslog_ident = 'postgres'
# This is only relevant when logging to eventlog (win32):
#event_source = 'PostgreSQL'
# - When to Log -
#client_min_messages = notice # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# log
# notice
# warning
# error
#log_min_messages = warning # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic
#log_min_error_statement = error # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic (effectively off)
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
# and their durations, > 0 logs only
# statements running at least this number
# of milliseconds
# - What to Log
#debug_print_parse = off
#debug_print_rewritten = off
#debug_print_plan = off
#debug_pretty_print = on
#log_checkpoints = off
#log_connections = off
#log_disconnections = off
#log_duration = off
#log_error_verbosity = default
# terse, default, or verbose messages
#log_hostname = off
log_line_prefix = '< %m >' # special values:
# %a = application name
# %u = user name
# %d = database name
# %r = remote host and port
# %h = remote host
# %p = process ID
# %t = timestamp without milliseconds
# %m = timestamp with milliseconds
# %i = command tag
# %e = SQL state
# %c = session ID
# %l = session line number
# %s = session start timestamp
# %v = virtual transaction ID
# %x = transaction ID (0 if none)
# %q = stop here in non-session
# processes
# %% = '%'
# e.g. '<%u%%%d> '
#log_lock_waits = off # log lock waits >= deadlock_timeout
#log_statement = 'none' # none, ddl, mod, all
#log_temp_files = -1 # log temporary files equal or larger
# than the specified size in kilobytes;5# -1 disables, 0 logs all temp files5
log_timezone = 'Australia/ACT'
虽然大多数参数被加上了注释,它们使用了默认值。我们可以看见日志文件目录是 pglog(logdirectory 参数,在 /var/lib/pgsql/9.4/data/ 下的子目录),文件名应该以 postgresql 开头(logfilename参数),文件每天轮转一次(logrotationage 参数)然后每行日志记录以时间戳开头(loglineprefix参数)。特别值得说明的是 logline\_prefix 参数:全部的信息你都可以包含在这。
看 /var/lib/pgsql/9.4/data/pg\_log 目录下展现给我们这些文件:
[root@localhost ~]# ls -l /var/lib/pgsql/9.4/data/pg_log
total 20
-rw-------. 1 postgres postgres 1212 May 1 20:11 postgresql-Fri.log
-rw-------. 1 postgres postgres 243 Feb 9 21:49 postgresql-Mon.log
-rw-------. 1 postgres postgres 1138 Feb 7 11:08 postgresql-Sat.log
-rw-------. 1 postgres postgres 1203 Feb 26 21:32 postgresql-Thu.log
-rw-------. 1 postgres postgres 326 Feb 10 01:20 postgresql-Tue.log
所以日志文件名只有星期命名的标签。我们可以改变它。如何做?在 postgresql.conf 配置 log\_filename 参数。
查看一个日志内容,它的条目仅以日期时间开头:
[root@localhost ~]# cat /var/lib/pgsql/9.4/data/pg_log/postgresql-Fri.log
...
< 2015-02-27 01:21:27.020 EST >LOG: received fast shutdown request
< 2015-02-27 01:21:27.025 EST >LOG: aborting any active transactions
< 2015-02-27 01:21:27.026 EST >LOG: autovacuum launcher shutting down
< 2015-02-27 01:21:27.036 EST >LOG: shutting down
< 2015-02-27 01:21:27.211 EST >LOG: database system is shut down
归集应用的日志
使用 imfile 监控日志
习惯上,应用通常记录它们数据在文件里。文件容易在一个机器上寻找,但是多台服务器上就不是很恰当了。你可以设置日志文件监控,然后当新的日志被添加到文件尾部后就发送事件到一个集中服务器。在 /etc/rsyslog.d/ 里创建一个新的配置文件然后增加一个配置文件,然后输入如下:
$ModLoad imfile
$InputFilePollInterval 10
$PrivDropToGroup adm
# Input for FILE1
$InputFileName /FILE1
$InputFileTag APPNAME1
$InputFileStateFile stat-APPNAME1 #this must be unique for each file being polled
$InputFileSeverity info
$InputFilePersistStateInterval 20000
$InputRunFileMonitor
替换 FILE1 和 APPNAME1 为你自己的文件名和应用名称。rsyslog 将发送它到你配置的输出目标中。
本地套接字日志与 imuxsock
套接字类似 UNIX 文件句柄,所不同的是套接字内容是由 syslog 守护进程读取到内存中,然后发送到目的地。不需要写入文件。作为一个例子,logger 命令发送它的日志到这个 UNIX 套接字。
如果你的服务器 I/O 有限或者你不需要本地文件日志,这个方法可以使系统资源有效利用。这个方法缺点是套接字有队列大小的限制。如果你的 syslog 守护进程宕掉或者不能保持运行,然后你可能会丢失日志数据。
rsyslog 程序将默认从 /dev/log 套接字中读取,但是你需要使用如下命令来让 imuxsock 输入模块 启用它:
$ModLoad imuxsock
UDP 日志与 imupd
一些应用程序使用 UDP 格式输出日志数据,这是在网络上或者本地传输日志文件的标准 syslog 协议。你的 syslog 守护进程接受这些日志,然后处理它们或者用不同的格式传输它们。备选的,你可以发送日志到你的日志服务器或者到一个日志管理方案中。
使用如下命令配置 rsyslog 通过 UDP 来接收标准端口 514 的 syslog 数据:
$ModLoad imudp
$UDPServerRun 514
用 logrotate 管理日志
日志轮转是当日志到达指定的时期时自动归档日志文件的方法。如果不介入,日志文件一直增长,会用尽磁盘空间。最后它们将破坏你的机器。
logrotate 工具能随着日志的日期截取你的日志,腾出空间。你的新日志文件保持该文件名。你的旧日志文件被重命名加上后缀数字。每次 logrotate 工具运行,就会创建一个新文件,然后现存的文件被逐一重命名。你来决定何时旧文件被删除或归档的阈值。
当 logrotate 拷贝一个文件,新的文件会有一个新的 inode,这会妨碍 rsyslog 监控新文件。你可以通过增加copytruncate 参数到你的 logrotate 定时任务来缓解这个问题。这个参数会拷贝现有的日志文件内容到新文件然后从现有文件截短这些内容。因为日志文件还是同一个,所以 inode 不会改变;但它的内容是一个新文件。
logrotate 工具使用的主配置文件是 /etc/logrotate.conf,应用特有设置在 /etc/logrotate.d/ 目录下。DigitalOcean 有一个详细的 logrotate 教程
管理很多服务器的配置
当你只有很少的服务器,你可以登录上去手动配置。一旦你有几打或者更多服务器,你可以利用工具的优势使这变得更容易和更可扩展。基本上,所有的事情就是拷贝你的 rsyslog 配置到每个服务器,然后重启 rsyslog 使更改生效。
pssh
这个工具可以让你在很多服务器上并行的运行一个 ssh 命令。使用 pssh 部署仅用于少量服务器。如果你其中一个服务器失败,然后你必须 ssh 到失败的服务器,然后手动部署。如果你有很多服务器失败,那么手动部署它们会话费很长时间。
Puppet/Chef
Puppet 和 Chef 是两个不同的工具,它们能在你的网络按你规定的标准自动的配置所有服务器。它们的报表工具可以使你了解错误情况,然后定期重新同步。Puppet 和 Chef 都有一些狂热的支持者。如果你不确定那个更适合你的部署配置管理,你可以拜读一下 InfoWorld 上这两个工具的对比
一些厂商也提供一些配置 rsyslog 的模块或者方法。这有一个 Loggly 上 Puppet 模块的例子。它提供给 rsyslog 一个类,你可以添加一个标识令牌:
node 'my_server_node.example.net' {
# Send syslog events to Loggly
class { 'loggly::rsyslog':
customer_token => 'de7b5ccd-04de-4dc4-fbc9-501393600000',
}
}
Docker
Docker 使用容器去运行应用,不依赖于底层服务。所有东西都运行在内部的容器,你可以把它想象为一个功能单元。ZDNet 有一篇关于在你的数据中心使用 Docker 的深入文章。
这里有很多方式从 Docker 容器记录日志,包括链接到一个日志容器,记录到一个共享卷,或者直接在容器里添加一个 sysllog 代理。其中最流行的日志容器叫做 logspout。
供应商的脚本或代理
大多数日志管理方案提供一些脚本或者代理,可以从一个或更多服务器相对容易地发送数据。重量级代理会耗尽额外的系统资源。一些供应商像 Loggly 提供配置脚本,来使用现存的 syslog 守护进程更轻松。这有一个 Loggly 上的例子脚本,它能运行在任意数量的服务器上。
via: http://www.loggly.com/ultimate-guide/logging/managing-linux-logs/
作者:Jason Skowronski 作者:Amy Echeverri 作者:Sadequl Hussain 译者:wyangsun 校对:wxy
本文由 LCTT 原创翻译,Linux中国 荣誉推出