awk 系列:如何使用 awk 复合表达式

一直以来在查对条件是否匹配时,我们使用的都是简单的表达式。那如果你想用超过一个表达式来查对特定的条件呢?
本文中,我们将看看如何在过滤文本和字符串时,结合多个表达式,即复合表达式,用以查对条件。
awk 的复合表达式可由表示“与”的组合操作符 && 和表示“或”的 || 构成。
复合表达式的常规写法如下:
( 第一个表达式 ) && ( 第二个表达式 )
这里只有当“第一个表达式” 和“第二个表达式”都是真值时整个表达式才为真。
( 第一个表达式 ) || ( 第二个表达式)
这里只要“第一个表达式” 为真或“第二个表达式”为真,整个表达式就为真。
注意:切记要加括号。
表达式可以由比较操作符构成,具体可查看 awk 系列的第四节。
现在让我们通过一个例子来加深理解:
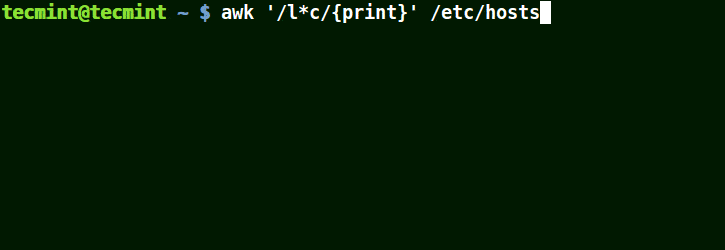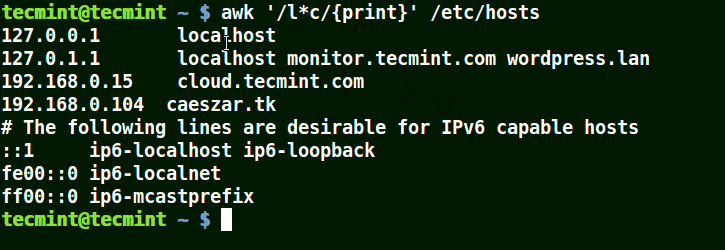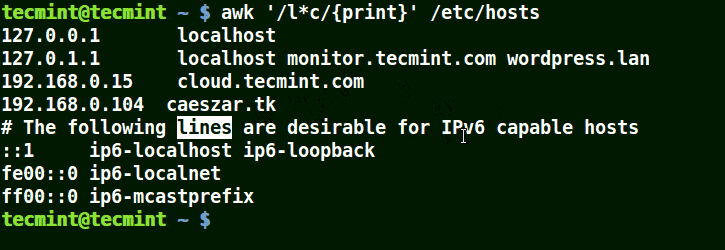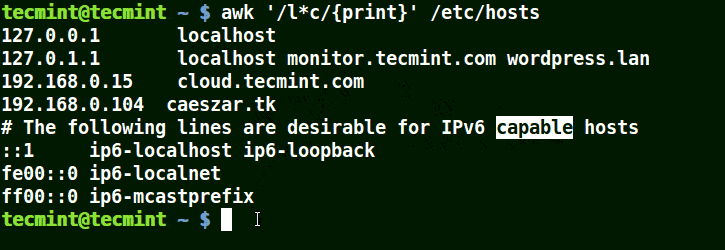
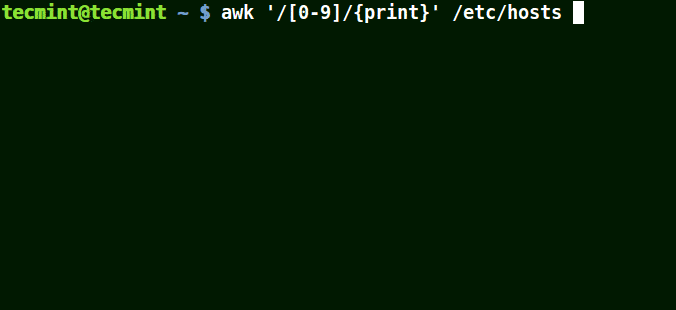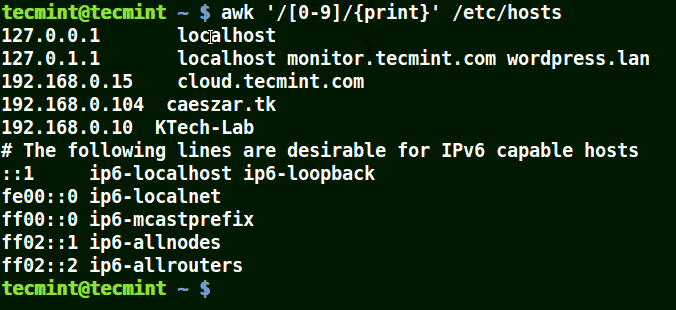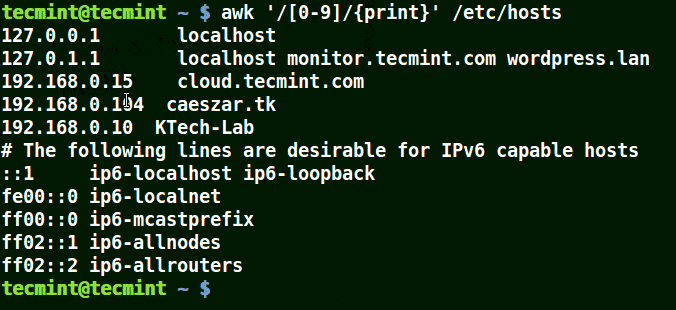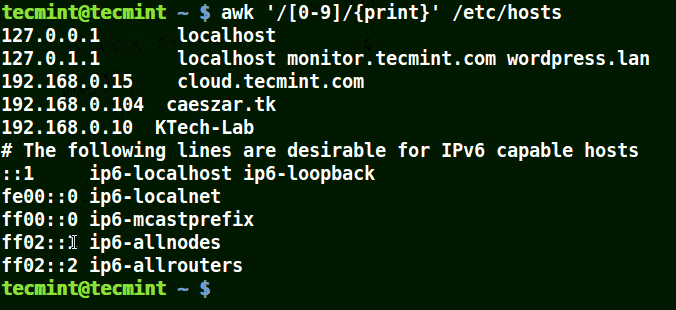
此例中,有一个文本文件 tecmint_deals.txt,文本中包含着一张随机的 Tecmint 交易清单,其中包含了名称、价格和种类。
TecMint Deal List
No Name Price Type
1 Mac_OS_X_Cleanup_Suite $9.99 Software
2 Basics_Notebook $14.99 Lifestyle
3 Tactical_Pen $25.99 Lifestyle
4 Scapple $19.00 Unknown
5 Nano_Tool_Pack $11.99 Unknown
6 Ditto_Bluetooth_Altering_Device $33.00 Tech
7 Nano_Prowler_Mini_Drone $36.99 Tech
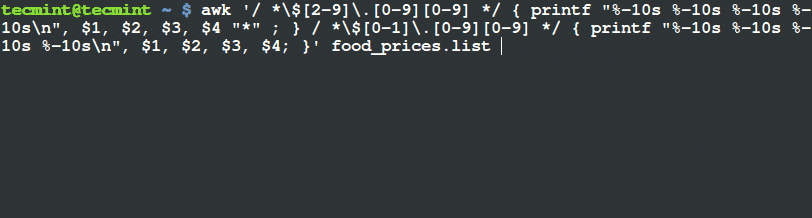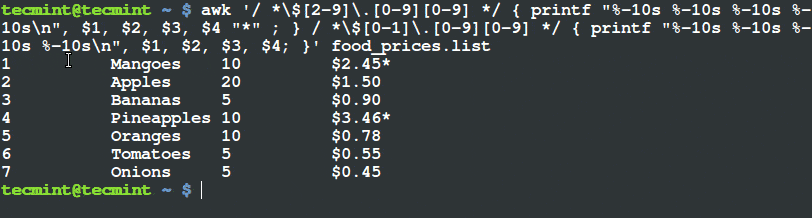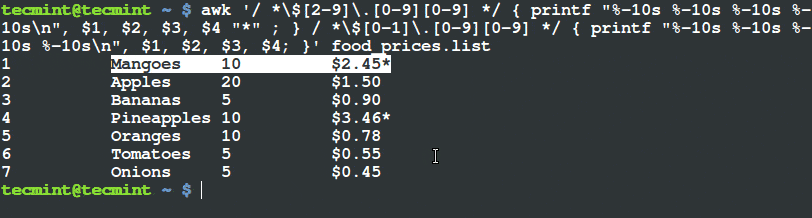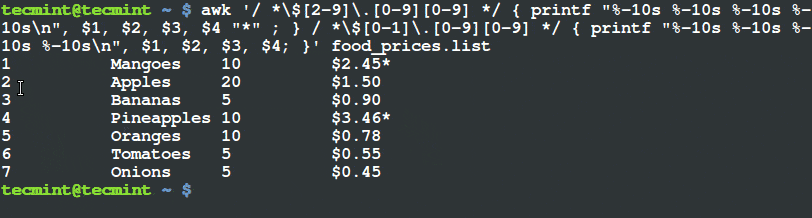
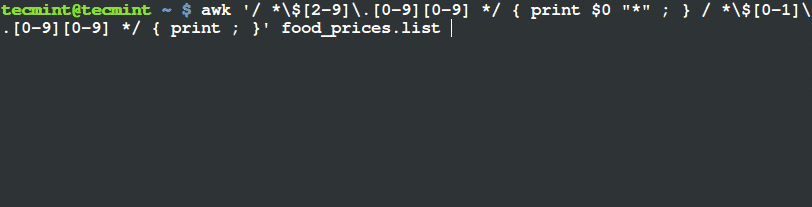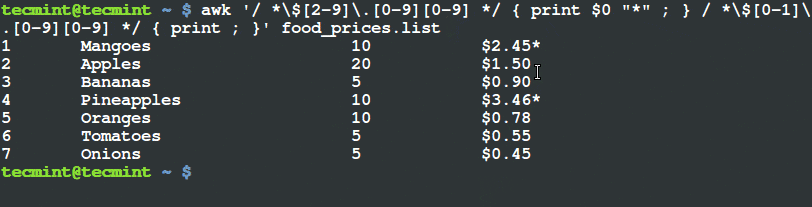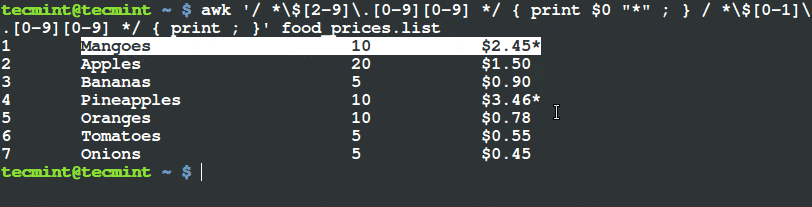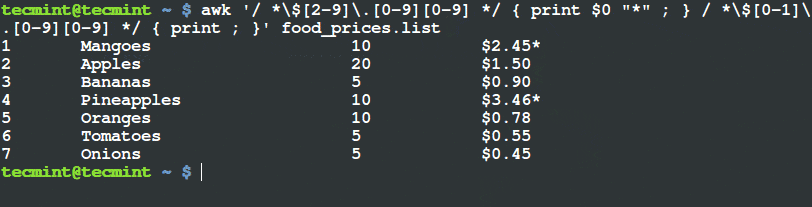
我们只想打印出价格超过 $20 且其种类为 “Tech” 的物品,在其行末用 (*) 打上标记。
我们将要执行以下命令。
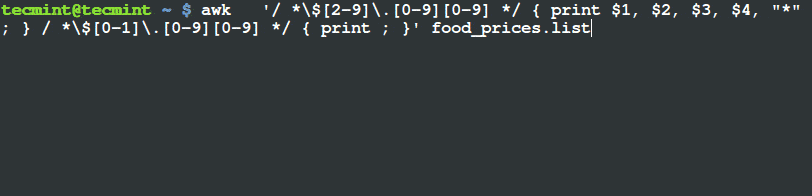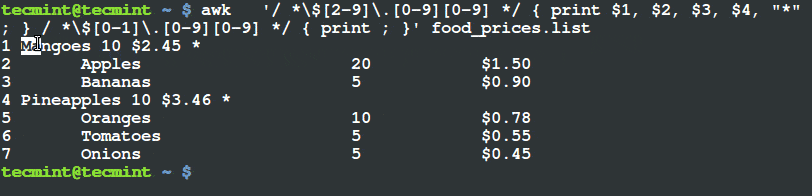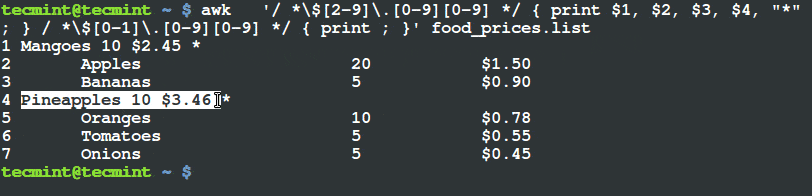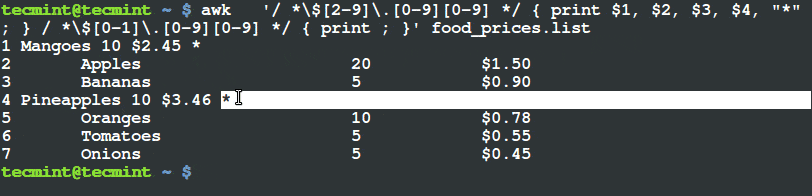
# awk '($3 ~ /^\$[2-9][0-9]*\.[0-9][0-9]$/) && ($4=="Tech") { printf "%s\t%s\n",$0,"*"; } ' tecmint_deals.txt
6 Ditto_Bluetooth_Altering_Device $33.00 Tech *
7 Nano_Prowler_Mini_Drone $36.99 Tech *
此例,在复合表达式中我们使用了两个表达式:
- 表达式 1:
($3 ~ /^\$[2-9][0-9]*\.[0-9][0-9]$/);查找交易价格超过$20的行,即只有当$3也就是价格满足/^\$[2-9][0-9]*\.[0-9][0-9]$/时值才为真值。 - 表达式 2:
($4 == “Tech”);查找是否有种类为 “Tech”的交易,即只有当$4等于 “Tech” 时值才为真值。 切记,只有当&&操作符的两端状态,也就是两个表达式都是真值的情况下,这一行才会被打上(*)标志。
总结
有些时候为了真正符合你的需求,就不得不用到复合表达式。当你掌握了比较和复合表达式操作符的用法之后,复杂的文本或字符串过滤条件也能轻松解决。
希望本向导对你有所帮助,如果你有任何问题或者补充,可以在下方发表评论,你的问题将会得到相应的解释。
via: http://www.tecmint.com/combine-multiple-expressions-in-awk/
作者:Aaron Kili 译者:martin2011qi 校对:wxy