我觉得 awk 系列 将会越来越好,在本系列的前七节我们讨论了在 Linux 中处理文件和筛选字符串所需要的一些 awk 命令基础。
在这一部分,我们将会进入 awk 更高级的部分,使用 awk 处理更复杂的文本和进行字符串过滤操作。因此,我们将会讲到 Awk 的一些特性,诸如变量、数值表达式和赋值运算符。

学习 Awk 变量,数值表达式和赋值运算符
你可能已经在很多编程语言中接触过它们,比如 shell,C,Python 等;这些概念在理解上和这些语言没有什么不同,所以在这一小节中你不用担心很难理解,我们将会简短的提及常用的一些 awk 特性。
这一小节可能是 awk 命令里最容易理解的部分,所以放松点,我们开始吧。
1. Awk 变量
在很多编程语言中,变量就是一个存储了值的占位符,当你在程序中新建一个变量的时候,程序一运行就会在内存中创建一些空间,你为变量赋的值会存储在这些内存空间上。
你可以像下面这样定义 shell 变量一样定义 awk 变量:
variable_name=value
上面的语法:
variable_name: 为定义的变量的名字value: 为变量赋的值
再看下面的一些例子:
computer_name=”tecmint.com”
port_no=”22”
email=”[email protected]”
server=computer_name
观察上面的简单的例子,在定义第一个变量的时候,值 'tecmint.com' 被赋给了 'computer\_name' 变量。
此外,值 22 也被赋给了 port\_no 变量,把一个变量的值赋给另一个变量也是可以的,在最后的例子中我们把变量 computer\_name 的值赋给了变量 server。
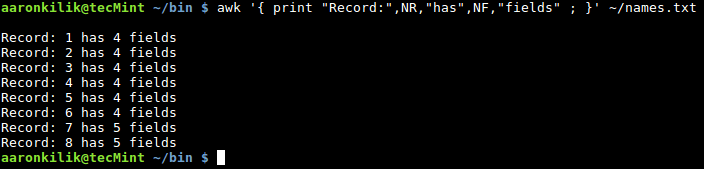
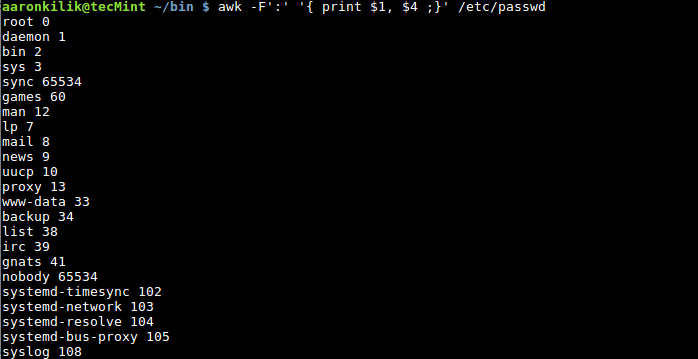
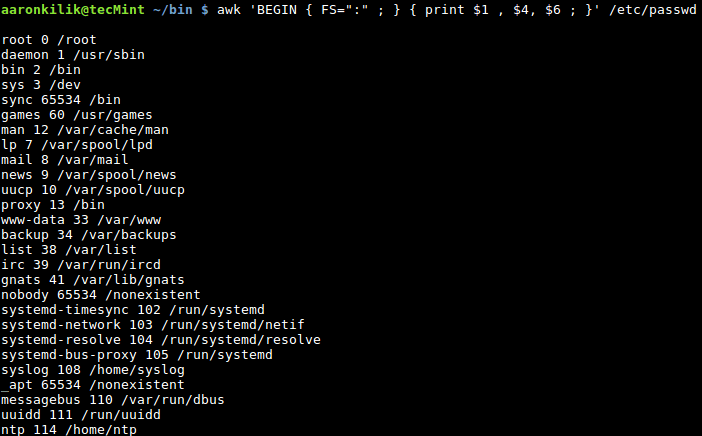
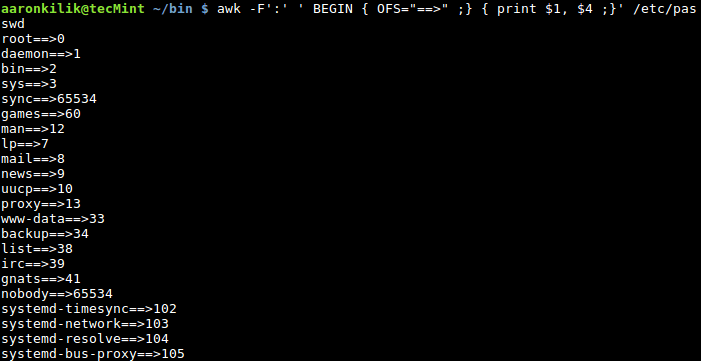
你可以看看本系列的第 2 节中提到的字段编辑,我们讨论了 awk 怎样将输入的行分隔为若干字段并且使用标准字段访问操作符 $ 来访问拆分出来的不同字段。我们也可以像下面这样使用变量为字段赋值。
first_name=$2
second_name=$3
在上面的例子中,变量 first\_name 的值设置为第二个字段,second\_name 的值设置为第三个字段。
再举个例子,有一个名为 names.txt 的文件,这个文件包含了一个应用程序的用户列表,这个用户列表包含了用户的名和姓以及性别。可以使用 cat 命令 查看文件内容:
$ cat names.txt
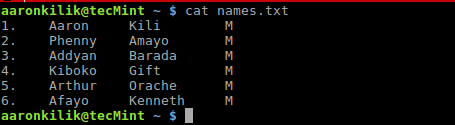
使用 cat 命令查看列表文件内容
然后,我们也可以使用下面的 awk 命令把列表中第一个用户的第一个和第二个名字分别存储到变量 first\_name 和 second\_name 上:
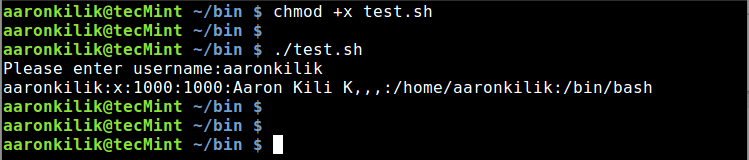
$ awk '/Aaron/{ first_name=$2 ; second_name=$3 ; print first_name, second_name ; }' names.txt

使用 Awk 命令为变量赋值
再看一个例子,当你在终端运行 'uname -a' 时,它可以打印出所有的系统信息。
第二个字段包含了你的主机名,因此,我们可以像下面这样把它赋给一个叫做 hostname 的变量并且用 awk 打印出来。
$ uname -a
$ uname -a | awk '{hostname=$2 ; print hostname ; }'

使用 Awk 把命令的输出赋给变量
2. 数值表达式
在 Awk 中,数值表达式使用下面的数值运算符组成:
* : 乘法运算符+ : 加法运算符/ : 除法运算符- : 减法运算符% : 取模运算符^ : 指数运算符
数值表达式的语法是:
$ operand1 operator operand2
上面的 operand1 和 operand2 可以是数值和变量,运算符可以是上面列出的任意一种。
下面是一些展示怎样使用数值表达式的例子:
counter=0
num1=5
num2=10
num3=num2-num1
counter=counter+1
要理解 Awk 中数值表达式的用法,我们可以看看下面的例子,文件 domians.txt 里包括了所有属于 Tecmint 的域名。
news.tecmint.com
tecmint.com
linuxsay.com
windows.tecmint.com
tecmint.com
news.tecmint.com
tecmint.com
linuxsay.com
tecmint.com
news.tecmint.com
tecmint.com
linuxsay.com
windows.tecmint.com
tecmint.com
可以使用下面的命令查看文件的内容:
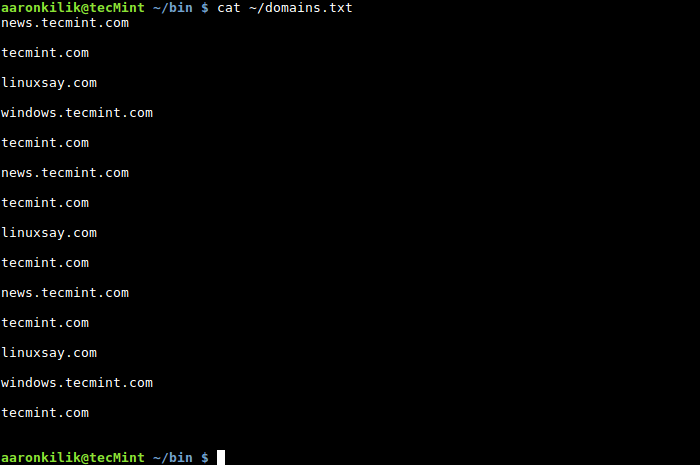
$ cat domains.txt
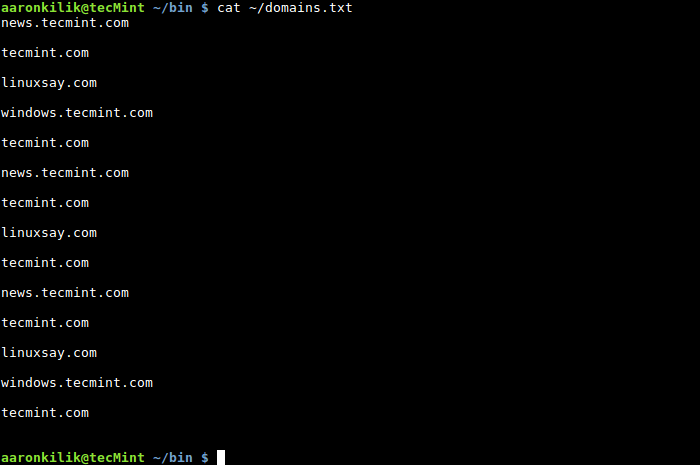
查看文件内容
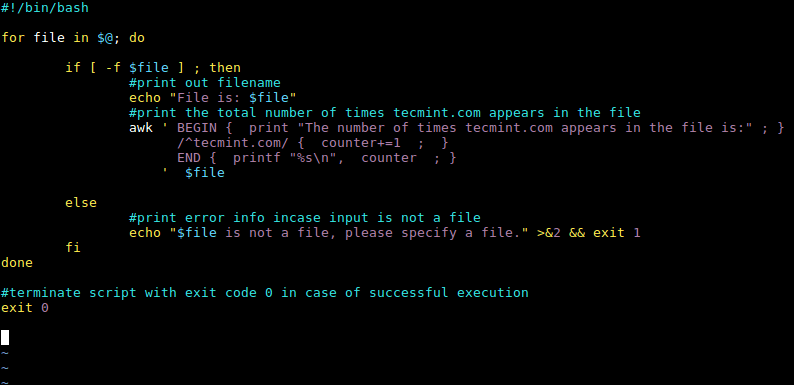
如果想要计算出域名 tecmint.com 在文件中出现的次数,我们就可以通过写一个简单的脚本实现这个功能:
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
#print out filename
echo "File is: $file"
#print a number incrementally for every line containing tecmint.com
awk '/^tecmint.com/ { counter=counter+1 ; printf "%s\n", counter ; }' $file
else
#print error info incase input is not a file
echo "$file is not a file, please specify a file." >&2 && exit 1
fi
done
#terminate script with exit code 0 in case of successful execution
exit 0
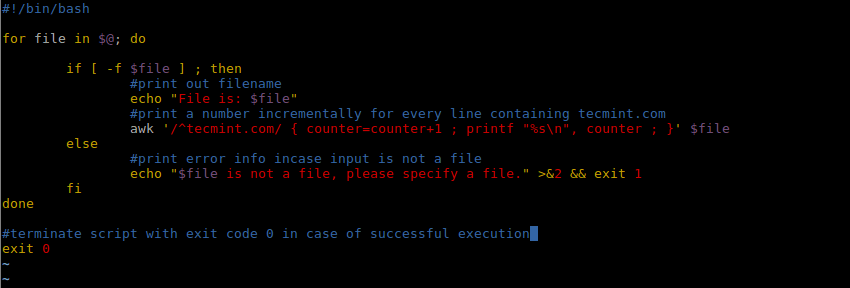
计算一个字符串或文本在文件中出现次数的 shell 脚本
写完脚本后保存并赋予执行权限,当我们使用文件运行脚本的时候,文件 domains.txt 作为脚本的输入,我们会得到下面的输出:
$ ./script.sh ~/domains.txt

计算字符串或文本出现次数的脚本
从脚本执行后的输出中,可以看到在文件 domains.txt 中包含域名 tecmint.com 的地方有 6 行,你可以自己计算进行验证。
3. 赋值操作符
我们要说的最后的 Awk 特性是赋值操作符,下面列出的只是 awk 中的部分赋值运算符:
*= : 乘法赋值操作符+= : 加法赋值操作符/= : 除法赋值操作符-= : 减法赋值操作符%= : 取模赋值操作符^= : 指数赋值操作符
下面是 Awk 中最简单的一个赋值操作的语法:
$ variable_name=variable_name operator operand
例子:
counter=0
counter=counter+1
num=20
num=num-1
你可以使用在 awk 中使用上面的赋值操作符使命令更简短,从先前的例子中,我们可以使用下面这种格式进行赋值操作:
variable_name operator=operand
counter=0
counter+=1
num=20
num-=1
因此,我们可以在 shell 脚本中改变 awk 命令,使用上面提到的 += 操作符:
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
#print out filename
echo "File is: $file"
#print a number incrementally for every line containing tecmint.com
awk '/^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; }' $file
else
#print error info incase input is not a file
echo "$file is not a file, please specify a file." >&2 && exit 1
fi
done
#terminate script with exit code 0 in case of successful execution
exit 0
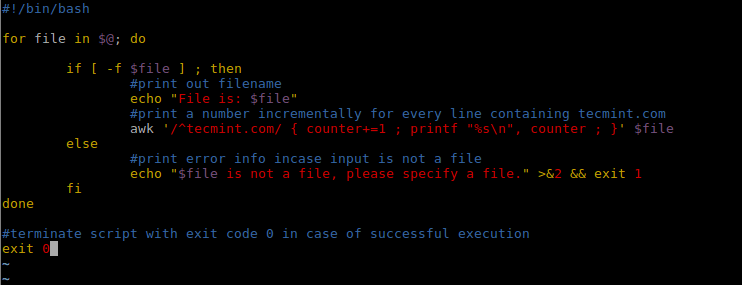
修改了的 shell 脚本
在 awk 系列 的这一部分,我们讨论了一些有用的 awk 特性,有变量,使用数值表达式和赋值运算符,还有一些使用它们的实例。
这些概念和其他的编程语言没有任何不同,但是可能在 awk 中有一些意义上的区别。
在本系列的第 9 节,我们会学习更多的 awk 特性,比如特殊格式: BEGIN 和 END。请继续关注。
via: http://www.tecmint.com/learn-awk-variables-numeric-expressions-and-assignment-operators/
作者:Aaron Kili 译者:vim-kakali 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出