使用 R 语言构建一个可交互的 Web 应用

数据分析已成为企业的当务之急,并且对具有用户友好界面的数据驱动应用程序有巨大的需求。本文介绍如何使用 R 语言中的 Shiny 包开发交互式 Web 应用程序,R 语言是一种流行的数据科学编程语言。
如今,世界各地几乎所有企业都以某种形式依赖于数据。数据科学通过使用数据驱动的应用程序帮助许多企业实现转型,无论是在金融、银行、零售、物流、电子商务、运输、航空还是任何其他领域。
高性能计算机和低成本存储使我们现在能够在几分钟内预测结果,而不是像以前一样以前需要花费很多时间。数据科学家着眼于未来,正在开发具有高性能和多维可视化的便捷应用。这一切都始于大数据,它由三个组成部分组成:数量、多样性和速度。算法和模型都是根据这些数据提供的。机器学习和人工智能领域最前沿的数据科学家正在创建能够自我改进、检测错误并从中学习的模型。
在数据科学领域,统计和计算用于将数据转化为有用的信息,通常称为数据驱动科学。数据科学是来自各个领域的方法的综合,用于收集、分析和解释数据,以形成新的见解并做出选择。构成数据科学的技术学科包括统计学、概率、数学、机器学习、商业智能和一些编程。
数据科学可以应用于各个领域(图 1)。对大型、复杂数据集的分析是数据科学的重点。它帮助我们创建了一个以全新方式看待数据的新宇宙。亚马逊、谷歌和 Facebook 等科技巨头利用数据科学原理进行商业智能和商业决策。

R 语言:为数据科学量身打造的语言
由于海量的可用信息,我们迫切需要数据分析以得到新的见解,在多种技术的帮助下,原始数据转化为成品数据产品。在数据研究、处理、转换和可视化方面,没有比 R 语言更好的工具了。
R 语言用于数据科学的主要功能包括:
- 数据预处理
- 社交媒体数据获取和分析
- 对数据结构的各种操作
- 提取、转换、加载(ETL)
- 连接到各种数据库,包括 SQL 和电子表格
- 与 NoSQL 数据库交互
- 使用模型进行训练和预测
- 机器学习模型
- 聚类
- 傅里叶变换
- 网页抓取
R 语言是一种强大的编程语言,常用于统计计算和数据分析。有关优化 R 语言用户界面的努力由来已久。从简单的文本编辑器到更现代的交互式 R Studio 和 Jupyter Notebooks,世界各地的多个数据科学小组都在关注 R 语言的发展。
只有全世界 R 用户的贡献才使这一切成为可能。R 语言中包含的强大软件包使其日益强大。许多开源软件包使处理大型数据集和可视化数据变得更加容易和高效。
使用 Shiny 在 R 语言中开发交互式 Web 应用
你可以使用 Shiny 包在 R 语言中构建交互式 Web 应用程序。应用程序可以托管在网站上、嵌入 R Markdown 文档中,或用于开发控制面板板和可视化。CSS 主题、HTML 小部件和 JavaScript 操作都可以用于进一步自定义你的 Shiny 应用程序。
Shiny 是一款 R 语言工具,它可以轻松创建交互式的 Web 应用程序。它允许你将你的 R 代码扩展到 Web 上,从而使更多的人能够使用它,从中获益。
除了 Shiny 内置的功能外,还有许多第三方扩展包可用,例如 shinythemes、shinydashboard 和 shinyjs。
使用 Shiny 可以开发各种应用程序。以下是其中一些:
- 基于 Web 应用的机器学习
- 具有动态控件的 Web 应用程序
- 数据驱动的仪表盘
- 多重数据集的交互式应用
- 实时数据可视化面板
- 数据收集表单
Shiny Web 应用程序可以分为以下几类:
- 用户接口
- 服务功能逻辑
- Shiny 应用逻辑
获取更深理解,请访问以下网站 https://shiny.rstudio.com/gallery/ 。
其中某个用 Shiny 开发的应用如图 2(https://shiny.rstudio.com/gallery/radiant.html )。

销售仪表盘的生成
下面是一个与销售仪表盘相关的 Web 应用程序的代码片段。该仪表板具有多个控件和用户界面模块,用于查看数据。
首先,安装 Shiny 包,然后在代码中调用它,以便将输出呈现为 Web 页面的形式。
library(shiny)
library(dplyr)
sales <- vroom::vroom(“salesdata.csv”, na = “”)
ui <- fluidPage(
titlePanel(“Dashboard for Sales Data”),
sidebarLayout(
sidebarPanel(
selectInput(“territories”, “territories”, choices = unique(sales$territories)),
selectInput(“Customers”, “Customer”, choices = NULL),
selectInput(“orders”, “Order number”, choices = NULL, size = 5, selectize = FALSE),
),
mainPanel(
uiOutput(“customer”),
tableOutput(“data”)
)
)
)
server <- function(input, output, session) {
territories <- reactive({
req(input$territories)
filter(sales, territories == input$territories)
})
customer <- reactive({
req(input$Customers)
filter(territories(), Customers == input$Customers)
})
output$customer <- renderUI({
row <- customer()[1, ]
tags$div(
class = “well”,
tags$p(tags$strong(“Name: “), row$customers),
tags$p(tags$strong(“Phone: “), row$contact),
tags$p(tags$strong(“Contact: “), row$fname, “ “, row$lname)
)
})
order <- reactive({
req(input$order)
customer() %>%
filter(ORDER == input$order) %>%
arrange(OLNUMBER) %>%
select(pline, qty, price, sales, status)
})
output$data <- renderTable(order())
observeEvent(territories(), {
updateSelectInput(session, “Customers”, choices = unique(territories()$Customers), selected = character())
})
observeEvent(customer(), {
updateSelectInput(session, “order”, choices = unique(customer()$order))
})
}
shinyApp(ui, server)
运行 Shiny 应用程序的代码后,生成了图 3 所示的输出,可以在任何 Web 浏览器上查看。销售仪表盘具有多个控件,并且具有不同的用户界面模块,非常互动。

通过使用 Shiny Cloud,可以将这个应用程序部署和托管在云上,以便随时随地在互联网上使用。

Shiny Cloud 的免费版本允许在 25 个活动小时内部署五个应用程序。研究人员和数据科学家可以使用 R 的 Shiny 库开发基于实时数据驱动的用户友好应用程序。这个库也可以用于在 Web 平台上部署他们的机器学习应用程序。
(题图:MJ/1a76ad20-e56d-480b-b28b-8cf74d2230a1)
via: https://www.opensourceforu.com/2022/10/using-r-for-building-an-interactive-web-app/
作者:Dr Kumar Gaurav 选题:lkxed 译者:Charonxin 校对:wxy

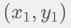 和 B 点
和 B 点 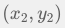 的欧式距离是
的欧式距离是 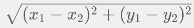 ;
; ,等于 2;
,等于 2;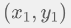 和 B 点
和 B 点  之间的曼哈顿距离是
之间的曼哈顿距离是  ;
;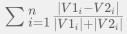 ;
; ,当 p = 1 时相当于曼哈顿距离,当 p = 2 时相当于欧式距离。
,当 p = 1 时相当于曼哈顿距离,当 p = 2 时相当于欧式距离。