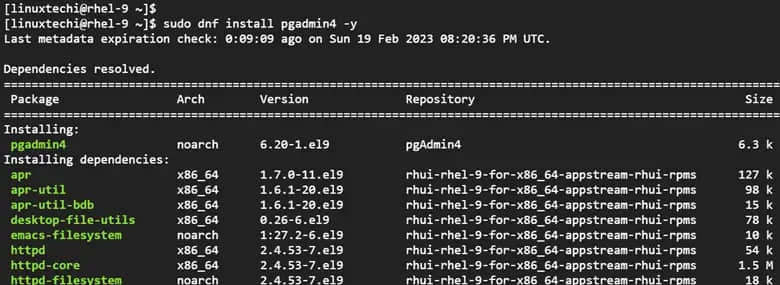
无论你需要的东西简单(如一个购物清单)亦或复杂(如色卡生成器) ,PostgreSQL 命令都能使它变得容易起来。

在 PostgreSQL 入门一文中, 我解释了如何安装、设置和开始使用这个开源数据库软件。不过,使用 PostgreSQL 中的命令可以做更多事情。
例如,我使用 Postgres 来跟踪我的杂货店购物清单。我的大多数杂货店购物是在家里进行的,而且每周进行一次大批量的采购。我去几个不同的地方购买清单上的东西,因为每家商店都提供特定的选品或质量,亦或更好的价格。最初,我制作了一个 HTML 表单页面来管理我的购物清单,但这样无法保存我的输入内容。因此,在想到要购买的物品时我必须马上列出全部清单,然后到采购时我常常会忘记一些我需要或想要的东西。
相反,使用 PostgreSQL,当我想到需要的物品时,我可以随时输入,并在购物前打印出来。你也可以这样做。
创建一个简单的购物清单
首先,输入 psql 命令进入数据库,然后用下面的命令创建一个表:
Create table groc (item varchar(20), comment varchar(10));
输入如下命令在清单中加入商品:
insert into groc values ('milk', 'K');
insert into groc values ('bananas', 'KW');
括号中有两个信息(逗号隔开):前面是你需要买的东西,后面字母代表你要购买的地点以及哪些东西是你每周通常都要买的(W)。
因为 psql 有历史记录,你可以按向上键在括号内编辑信息,而无需输入商品的整行信息。
在输入一小部分商品后,输入下面命令来检查前面的输入内容。
Select * from groc order by comment;
item | comment
----------------+---------
ground coffee | H
butter | K
chips | K
steak | K
milk | K
bananas | KW
raisin bran | KW
raclette | L
goat cheese | L
onion | P
oranges | P
potatoes | P
spinach | PW
broccoli | PW
asparagus | PW
cucumber | PW
sugarsnap peas | PW
salmon | S
(18 rows)
此命令按 comment 列对结果进行排序,以便按购买地点对商品进行分组,从而使你的购物更加方便。
使用 W 来指明你每周要买的东西,当你要清除表单为下周的列表做准备时,你可以将每周的商品保留在购物清单上。输入:
delete from groc where comment not like '%W';
注意,在 PostgreSQL 中 % 表示通配符(而非星号)。所以,要保存输入内容,需要输入:
delete from groc where item like 'goat%';
不能使用 item = 'goat%',这样没用。
在购物时,用以下命令输出清单并打印或发送到你的手机:
\o groclist.txt
select * from groc order by comment;
\o
最后一个命令 \o 后面没有任何内容,将重置输出到命令行。否则,所有的输出会继续输出到你创建的杂货店购物文件 groclist.txt 中。
分析复杂的表
这个逐项列表对于数据量小的表来说没有问题,但是对于数据量大的表呢?几年前,我帮 FreieFarbe.de 的团队从 HLC 调色板中创建一个自由色的色样册。事实上,任何能想象到的打印色都可按色调、亮度、浓度(饱和度)来规定。最终结果是 HLC Color Atlas,下面是我们如何实现的。
该团队向我发送了具有颜色规范的文件,因此我可以编写可与 Scribus 配合使用的 Python 脚本,以轻松生成色样册。一个例子像这样开始:
HLC, C, M, Y, K
H010_L15_C010, 0.5, 49.1, 0.1, 84.5
H010_L15_C020, 0.0, 79.7, 15.1, 78.9
H010_L25_C010, 6.1, 38.3, 0.0, 72.5
H010_L25_C020, 0.0, 61.8, 10.6, 67.9
H010_L25_C030, 0.0, 79.5, 18.5, 62.7
H010_L25_C040, 0.4, 94.2, 17.3, 56.5
H010_L25_C050, 0.0, 100.0, 15.1, 50.6
H010_L35_C010, 6.1, 32.1, 0.0, 61.8
H010_L35_C020, 0.0, 51.7, 8.4, 57.5
H010_L35_C030, 0.0, 68.5, 17.1, 52.5
H010_L35_C040, 0.0, 81.2, 22.0, 46.2
H010_L35_C050, 0.0, 91.9, 20.4, 39.3
H010_L35_C060, 0.1, 100.0, 17.3, 31.5
H010_L45_C010, 4.3, 27.4, 0.1, 51.3
这与原始数据相比,稍有修改,原始数据用制表符分隔。我将其转换成 CSV 格式(用逗号分割值),我更喜欢其与 Python 一起使用(CSV 文也很有用,因为它可轻松导入到电子表格程序中)。
在每一行中,第一项是颜色名称,其后是其 C、M、Y 和 K 颜色值。 该文件包含 1,793 种颜色,我想要一种分析信息的方法,以了解这些值的范围。这就是 PostgreSQL 发挥作用的地方。我不想手动输入所有数据 —— 我认为输入过程中我不可能不出错,而且令人头痛。幸运的是,PostgreSQL 为此提供了一个命令。
首先用以下命令创建数据库:
Create table hlc_cmyk (color varchar(40), c decimal, m decimal, y decimal, k decimal);
然后通过以下命令引入数据:
\copy hlc_cmyk from '/home/gregp/HLC_Atlas_CMYK_SampleData.csv' with (header, format CSV);
开头有反斜杠,是因为使用纯 copy 命令的权限仅限于 root 用户和 Postgres 的超级用户。在括号中,header 表示第一行包含标题,应忽略,CSV 表示文件格式为 CSV。请注意,在此方法中,颜色名称不需要用括号括起来。
如果操作成功,会看到 COPY NNNN,其中 N 表示插入到表中的行数。
最后,可以用下列命令查询:
select * from hlc_cmyk;
color | c | m | y | k
---------------+-------+-------+-------+------
H010_L15_C010 | 0.5 | 49.1 | 0.1 | 84.5
H010_L15_C020 | 0.0 | 79.7 | 15.1 | 78.9
H010_L25_C010 | 6.1 | 38.3 | 0.0 | 72.5
H010_L25_C020 | 0.0 | 61.8 | 10.6 | 67.9
H010_L25_C030 | 0.0 | 79.5 | 18.5 | 62.7
H010_L25_C040 | 0.4 | 94.2 | 17.3 | 56.5
H010_L25_C050 | 0.0 | 100.0 | 15.1 | 50.6
H010_L35_C010 | 6.1 | 32.1 | 0.0 | 61.8
H010_L35_C020 | 0.0 | 51.7 | 8.4 | 57.5
H010_L35_C030 | 0.0 | 68.5 | 17.1 | 52.5
所有的 1,793 行数据都是这样的。回想起来,我不能说此查询对于 HLC 和 Scribus 任务是绝对必要的,但是它减轻了我对该项目的一些担忧。
为了生成 HLC 色谱,我使用 Scribus 为色板页面中的 13,000 多种颜色自动创建了颜色图表。
我可以使用 copy 命令输出数据:
\copy hlc_cmyk to '/home/gregp/hlc_cmyk_backup.csv' with (header, format CSV);
我还可以使用 where 子句根据某些值来限制输出。
例如,以下命令将仅发送以 H10 开头的色调值。
\copy hlc_cmyk to '/home/gregp/hlc_cmyk_backup.csv' with (header, format CSV) where color like 'H10%';
备份或传输数据库或表
我在此要提到的最后一个命令是 pg_dump,它用于备份 PostgreSQL 数据库,并在 psql 控制台之外运行。 例如:
pg_dump gregp -t hlc_cmyk > hlc.out
pg_dump gregp > dball.out
第一行是导出 hlc_cmyk 表及其结构。第二行将转储 gregp 数据库中的所有表。这对于备份或传输数据库或表非常有用。
要将数据库或表传输到另一台电脑(查看 PostgreSQL 入门那篇文章获取详细信息),首先在要转入的电脑上创建一个数据库,然后执行相反的操作。
psql -d gregp -f dball.out
一步创建所有表并输入数据。
总结
在本文中,我们了解了如何使用 WHERE 参数限制操作,以及如何使用 PostgreSQL 通配符 %。我们还了解了如何将大批量数据加载到表中,然后将部分或全部表数据输出到文件,甚至是将整个数据库及其所有单个表输出。
via: https://opensource.com/article/20/2/postgresql-commands
作者:Greg Pittman 选题:lujun9972 译者:Morisun029 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出