12 件可以用 GitHub 完成的很酷的事情

我不能为我的人生想出一个引子来,所以……
1 在 GitHub.com 上编辑代码
我想我要开始介绍的第一件事是多数人都已经知道的(尽管我一周之前还不知道)。
当你登录到 GitHub ,查看一个文件时(任何文本文件,任何版本库),右上方会有一只小铅笔。点击它,你就可以编辑文件了。 当你编辑完成后,GitHub 会给出文件变更的建议,然后为你 复刻 该仓库并创建一个 拉取请求 (PR)。
是不是很疯狂?它为你创建了一个复刻!
你不需要自己去复刻、拉取,然后本地修改,再推送,然后创建一个 PR。
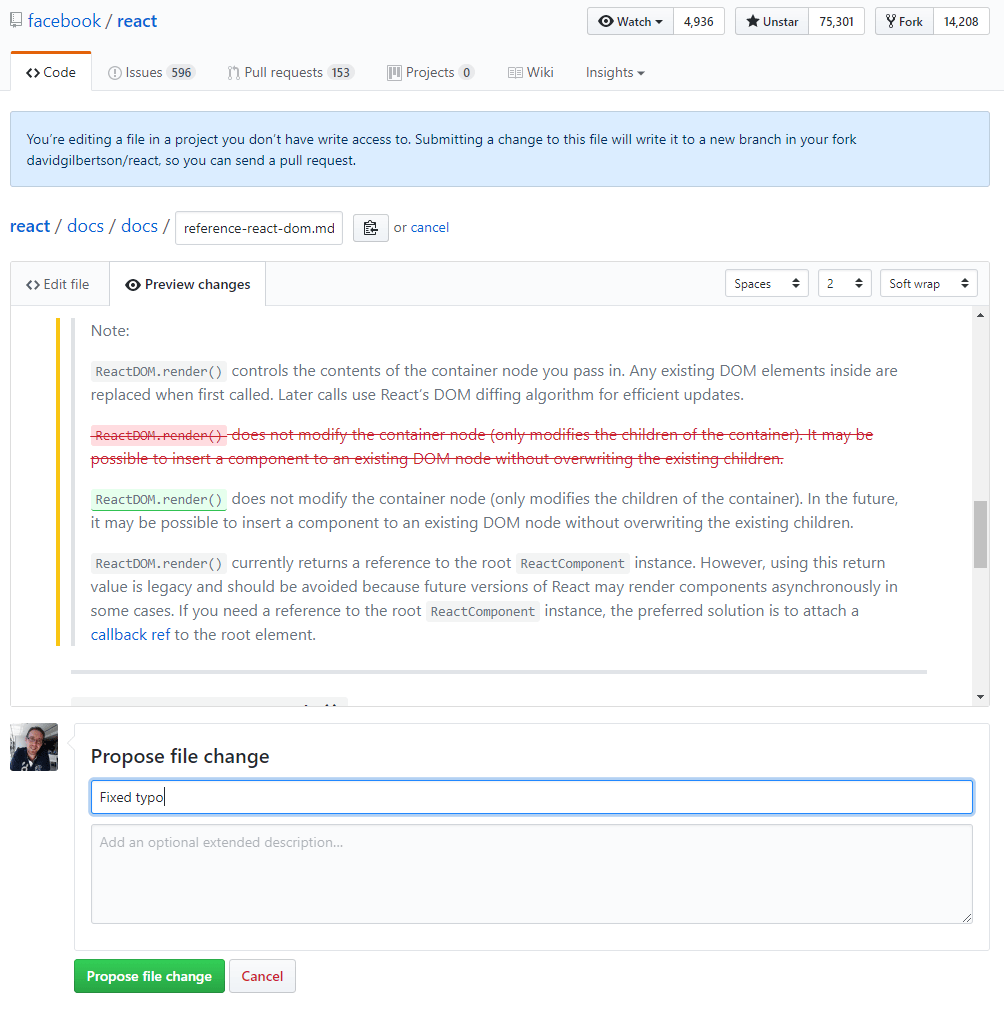
不是一个真正的 PR
这对于修改错误拼写以及编辑代码时的一些糟糕的想法是很有用的。
2 粘贴图像
在评论和 工单 的描述中并不仅限于使用文字。你知道你可以直接从剪切板粘贴图像吗? 在你粘贴的时候,你会看到图片被上传 (到云端,这毫无疑问),并转换成 markdown 显示的图片格式。
棒极了。
3 格式化代码
如果你想写一个代码块的话,你可以用三个反引号(`)作为开始 —— 就像你在浏览 精通 Markdown 时所学到的一样 —— 而且 GitHub 会尝试去推测你所写下的编程语言。
但如果你粘贴的像是 Vue、Typescript 或 JSX 这样的代码,你就需要明确指出才能获得高亮显示。
在首行注明 ``jsx`:
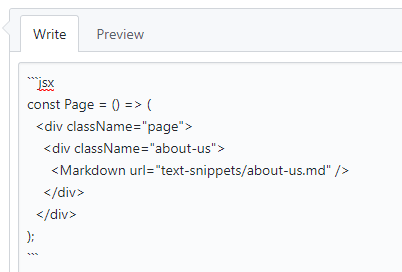
…这意味着代码段已经正确的呈现:
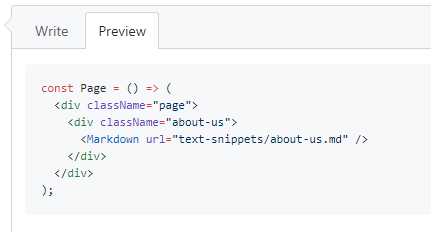
(顺便说一下,这些用法也可以用到 gist。 如果你给一个 gist 用上 .jsx 扩展名,你的 JSX 语法就会高亮显示。)
这里是所有被支持的语法的清单。
4 用 PR 中的魔法词来关闭工单
比方说你已经创建了一个用来修复 #234 工单的拉取请求。那么你就可以把 fixes #234 这段文字放在你的 PR 的描述中(或者是在 PR 的评论的任何位置)。
接下来,在合并 PR 时会自动关闭与之对应的工单。这是不是很酷?
这里是更详细的学习帮助。
5 链接到评论
是否你曾经想要链接到一个特定的评论但却无从着手?这是因为你不知道如何去做到这些。不过那都过去了,我的朋友,我告诉你啊,点击紧挨着名字的日期或时间,这就是如何链接到一个评论的方法。
嘿,这里有 gaearon 的照片!
6 链接到代码
那么你想要链接到代码的特定行么。我了解了。
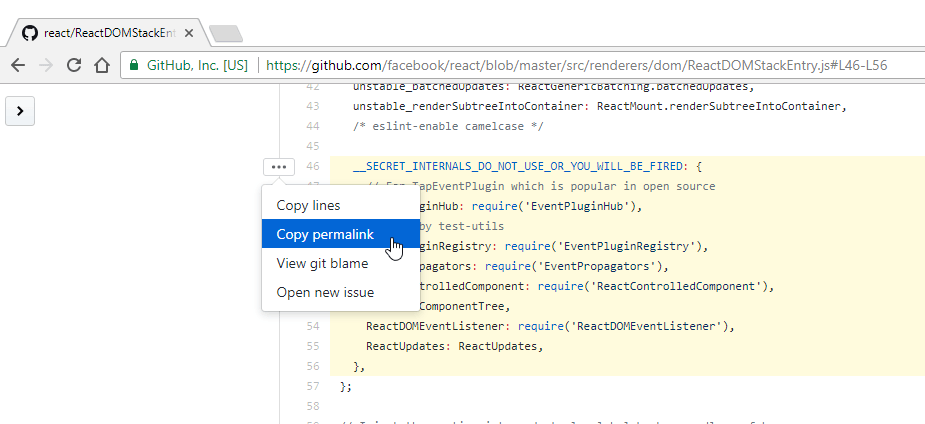
试试这个:在查看文件的时候,点击挨着代码的行号。
哇哦,你看到了么?URL 更新了,加上了行号!如果你按下 Shift 键并点击其他的行号,格里格里巴巴变!URL 再一次更新并且现在出现了行范围的高亮。
分享这个 URL 将会链接到这个文件的那些行。但等一下,链接所指向的是当前分支。如果文件发生变更了怎么办?也许一个文件当前状态的 永久链接 就是你以后需要的。
我比较懒,所以我已经在一张截图中做完了上面所有的步骤:
说起 URL…
7 像命令行一样使用 GitHub URL
使用 UI 来浏览 GitHub 有着很好的体验。但有些时候最快到达你想去的地方的方法就是在地址栏输入。举个例子,如果我想要跳转到一个我正在工作的分支,然后查看与 master 分支的差异,我就可以在我的仓库名称的后边输入 /compare/branch-name 。
这样就会访问到指定分支的 diff 页面。
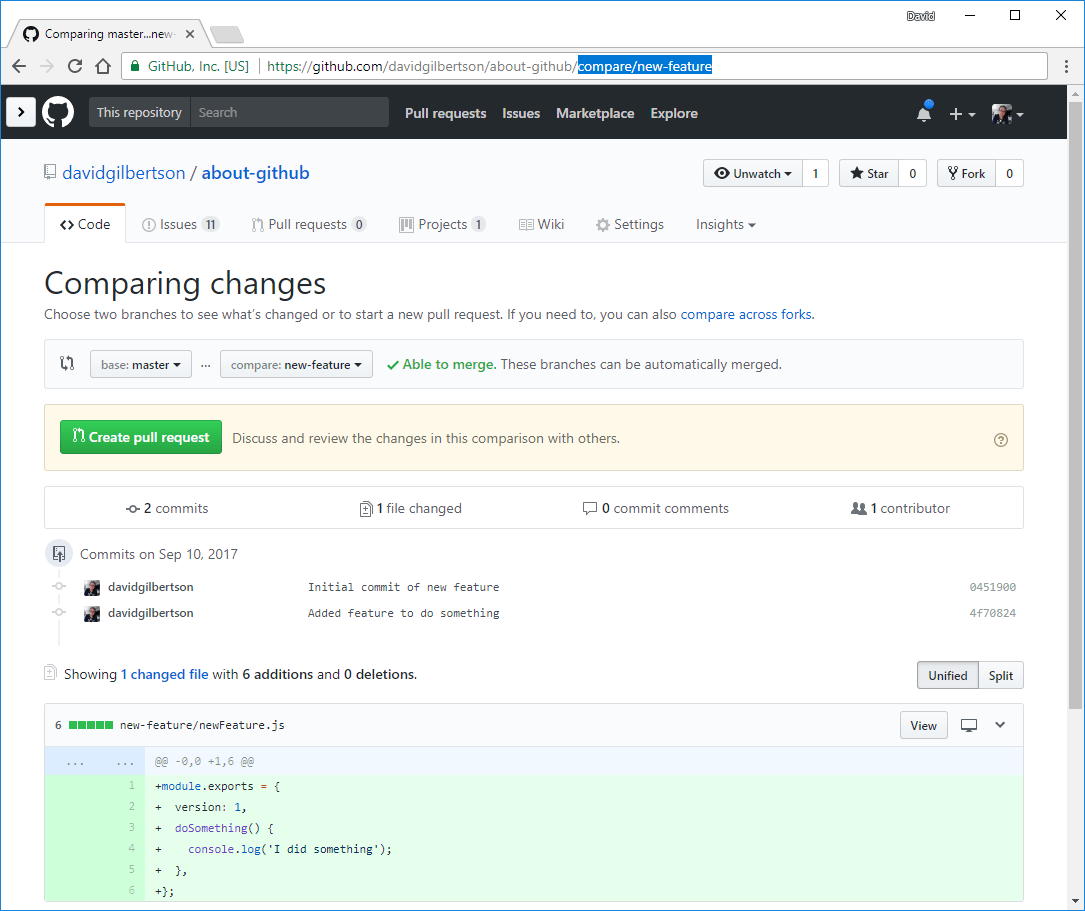
然而这就是与 master 分支的 diff,如果我要与 develoment 分支比较,我可以输入 /compare/development...my-branch。
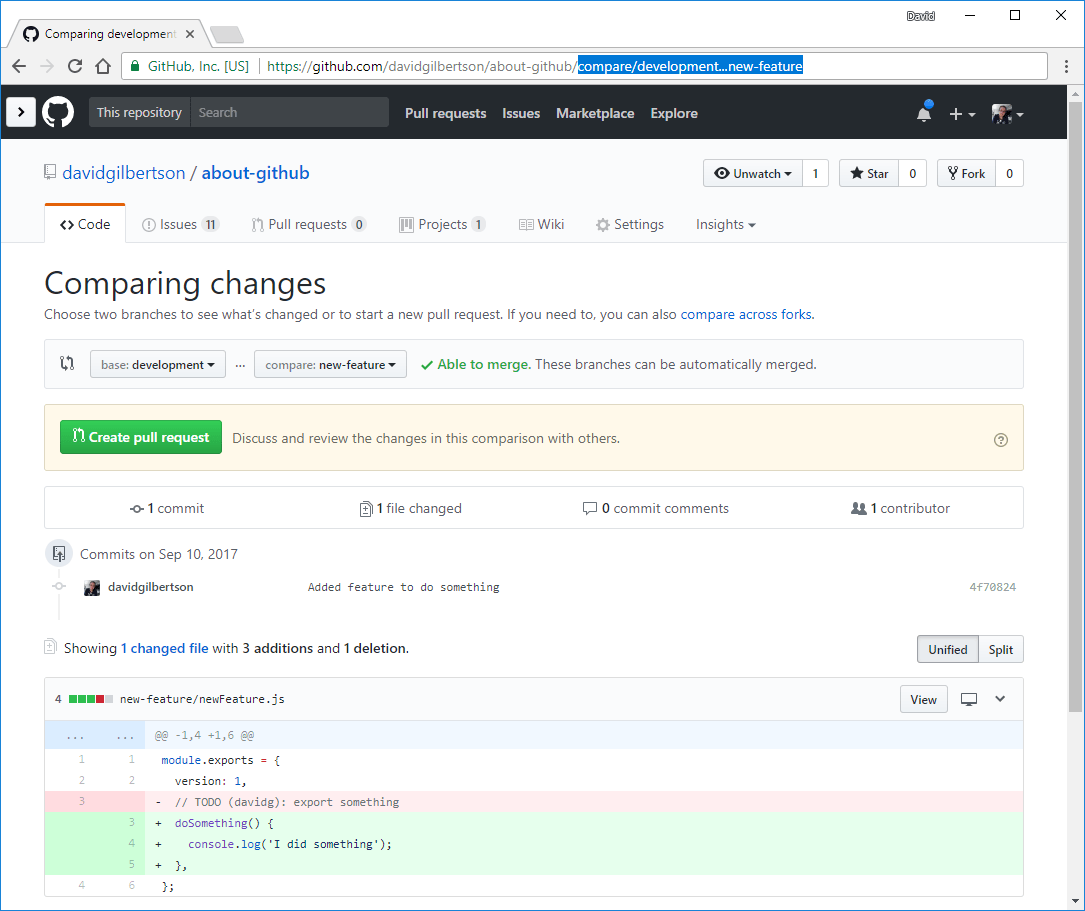
对于你这种键盘快枪手来说,ctrl+L 或 cmd+L 将会向上跳转光标进入 URL 那里(至少在 Chrome 中是这样)。这(再加上你的浏览器会自动补全)能够成为一种在分支间跳转的便捷方式。
专家技巧:使用方向键在 Chrome 的自动完成建议中移动同时按 shift+delete 来删除历史条目(例如,一旦分支被合并后)。
(我真的好奇如果我把快捷键写成 shift + delete 这样的话,是不是读起来会更加容易。但严格来说 ‘+’ 并不是快捷键的一部分,所以我并不觉得这很舒服。这一点纠结让 我 整晚难以入睡,Rhonda。)
8 在工单中创建列表
你想要在你的 工单 中看到一个复选框列表吗?
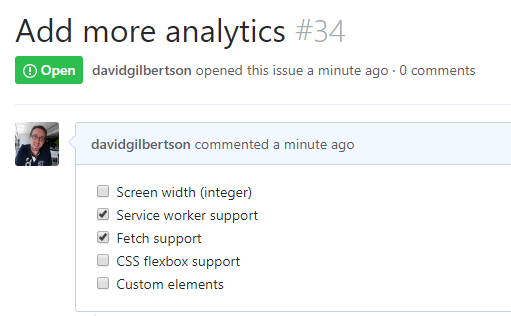
你想要在工单列表中显示为一个漂亮的 “2 of 5” 进度条吗?
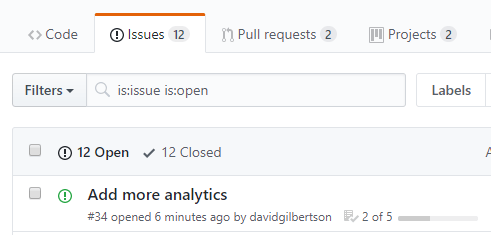
很好!你可以使用这些的语法创建交互式的复选框:
- [ ] Screen width (integer)
- [x] Service worker support
- [x] Fetch support
- [ ] CSS flexbox support
- [ ] Custom elements
它的表示方法是空格、破折号、再空格、左括号、填入空格(或者一个 x ),然后封闭括号,接着空格,最后是一些话。
然后你可以实际选中或取消选中这些框!出于一些原因这些对我来说看上去就像是技术魔法。你可以选中这些框! 同时底层的文本会进行更新。
他们接下来会想到什么魔法?
噢,如果你在一个 项目面板 上有这些工单的话,它也会在这里显示进度:
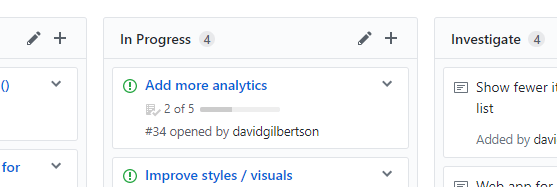
如果在我提到“在一个项目面板上”时你不知道我在说些什么,那么你会在本页下面进一步了解。
比如,在本页面下 2 厘米的地方。
9 GitHub 上的项目面板
我常常在大项目中使用 Jira 。而对于个人项目我总是会使用 Trello 。我很喜欢它们两个。
当我学会 GitHub 的几周后,它也有了自己的项目产品,就在我的仓库上的 Project 标签,我想我会照搬一套我已经在 Trello 上进行的任务。
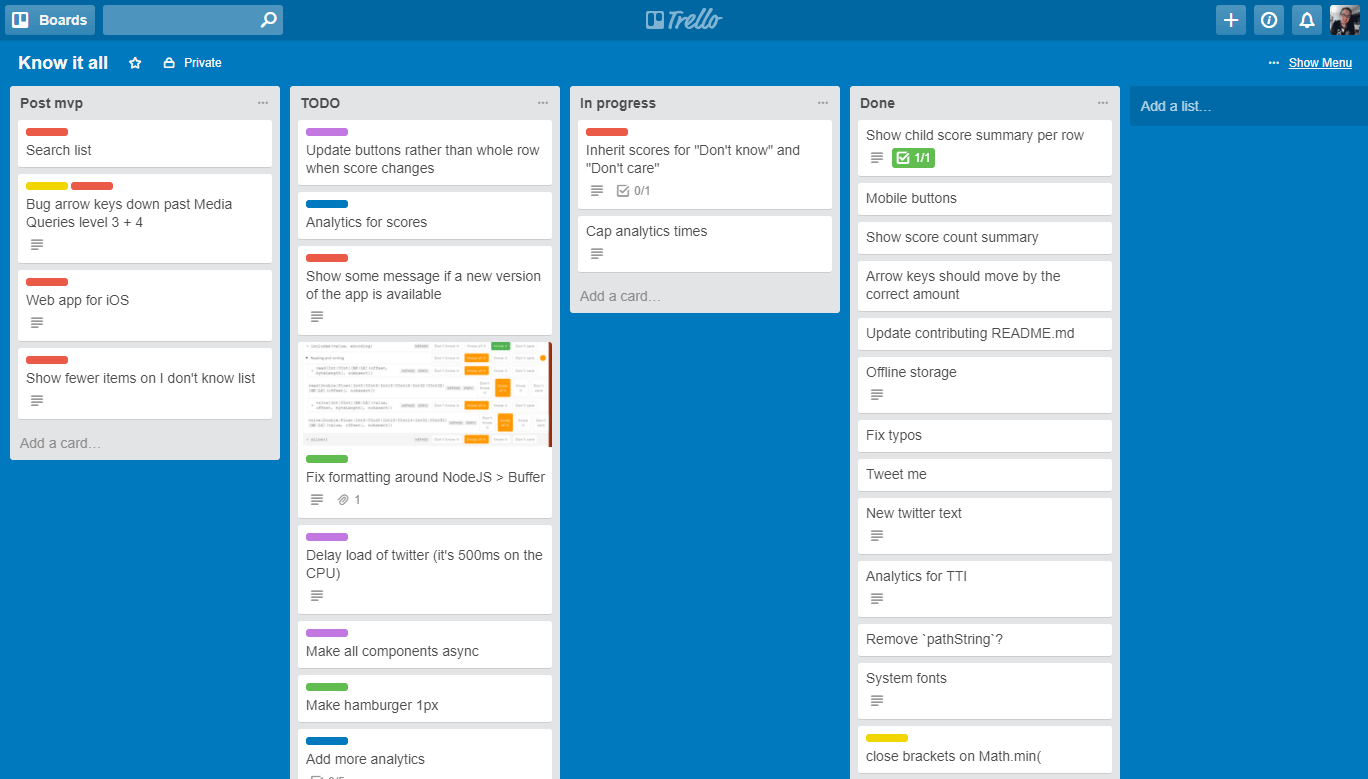
没有一个是有趣的任务
这里是在 GitHub 项目上相同的内容:
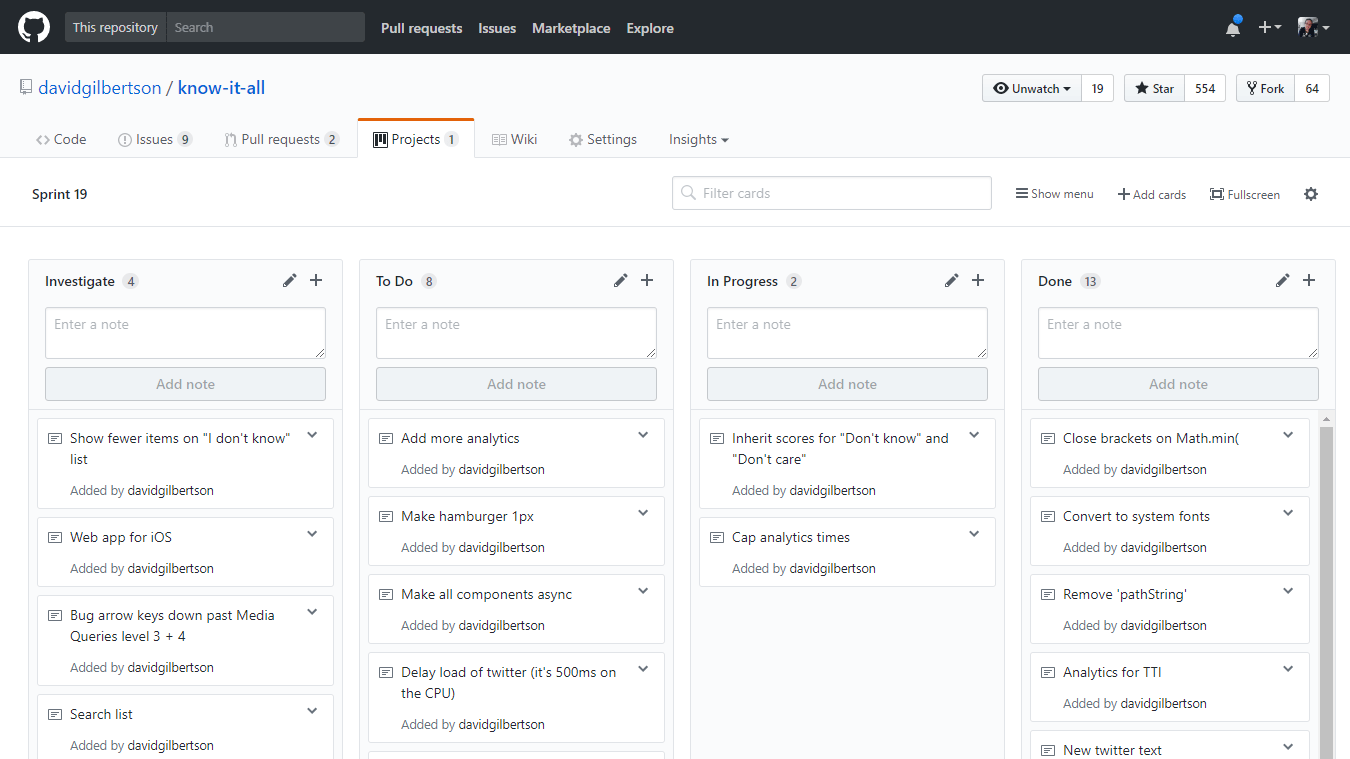
你的眼睛最终会适应这种没有对比的显示
出于速度的缘故,我把上面所有的都添加为 “ 备注 ” —— 意思是它们不是真正的 GitHub 工单。
但在 GitHub 上,管理任务的能力被集成在版本库的其他地方 —— 所以你可能想要从仓库添加已有的工单到面板上。
你可以点击右上角的 添加卡片 ,然后找你想要添加的东西。在这里,特殊的搜索语法就派上用场了,举个例子,输入 is:pr is:open 然后现在你可以拖动任何开启的 PR 到项目面板上,或者要是你想清理一些 bug 的话就输入 label:bug。
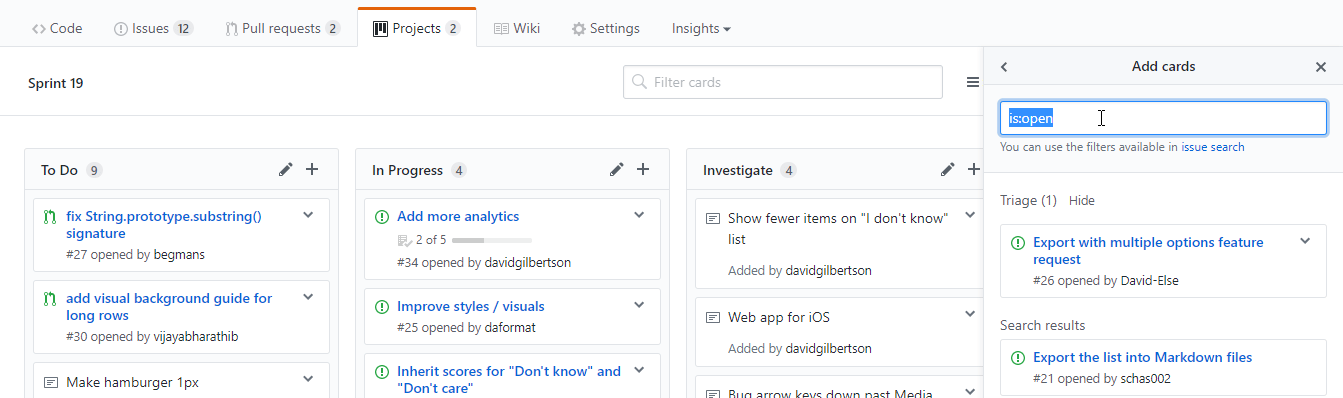
亦或者你可以将现有的备注转换为工单。
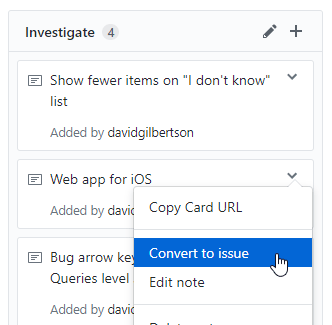
再或者,从一个现有工单的屏幕上,把它添加到右边面板的项目上。
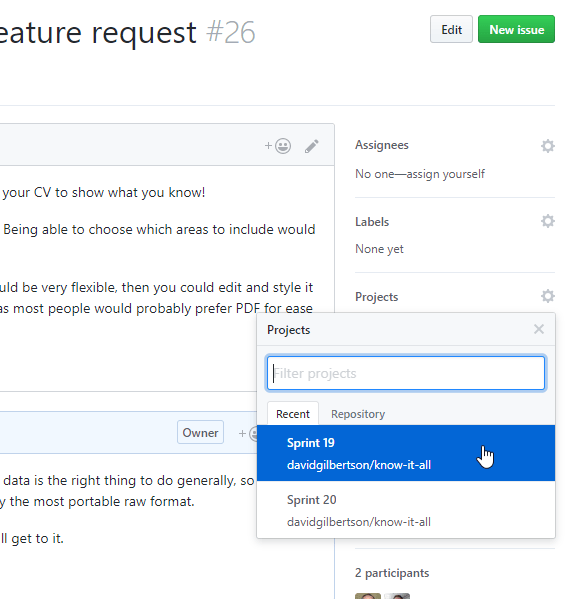
它们将会进入那个项目面板的分类列表,这样你就能决定放到哪一类。
在实现那些任务的同一个仓库下放置任务的内容有一个巨大(超大)的好处。这意味着今后的几年你能够在一行代码上做一个 git blame,可以让你找出最初在这个任务背后写下那些代码的根据,而不需要在 Jira、Trello 或其它地方寻找蛛丝马迹。
缺点
在过去的三周我已经对所有的任务使用 GitHub 取代 Jira 进行了测试(在有点看板风格的较小规模的项目上) ,到目前为止我都很喜欢。
但是我无法想象在 scrum(LCTT 译注:迭代式增量软件开发过程)项目上使用它,我想要在那里完成正确的工期估算、开发速度的测算以及所有的好东西怕是不行。
好消息是,GitHub 项目只有很少一些“功能”,并不会让你花很长时间去评估它是否值得让你去切换。因此要不要试试,你自己看着办。
无论如何,我听说过 ZenHub 并且在 10 分钟前第一次打开了它。它是对 GitHub 高效的延伸,可以让你估计你的工单并创建 epic 和 dependency。它也有 velocity 和 燃尽图 功能;这看起来可能是世界上最棒的东西了。
延伸阅读: GitHub help on Projects。
10 GitHub 维基
对于一堆非结构化页面(就像维基百科一样), GitHub 维基 提供的(下文我会称之为 Gwiki)就很优秀。
结构化的页面集合并没那么多,比如说你的文档。这里没办法说“这个页面是那个页面的子页”,或者有像‘下一节’和‘上一节’这样的按钮。Hansel 和 Gretel 将会完蛋,因为这里没有面包屑导航(LCTT 译注:引自童话故事《糖果屋》)。
(边注,你有读过那个故事吗? 这是个残酷的故事。两个混蛋小子将饥肠辘辘的老巫婆烧死在她自己的火炉里。毫无疑问她是留下来收拾残局的。我想这就是为什么如今的年轻人是如此的敏感 —— 今天的睡前故事太不暴力了。)
继续 —— 把 Gwiki 拿出来接着讲,我输入一些 NodeJS 文档中的内容作为维基页面,然后创建一个侧边栏以模拟一些真实结构。这个侧边栏会一直存在,尽管它无法高亮显示你当前所在的页面。
其中的链接必须手动维护,但总的来说,我认为这已经很好了。如果你觉得有需要的话可以看一下。
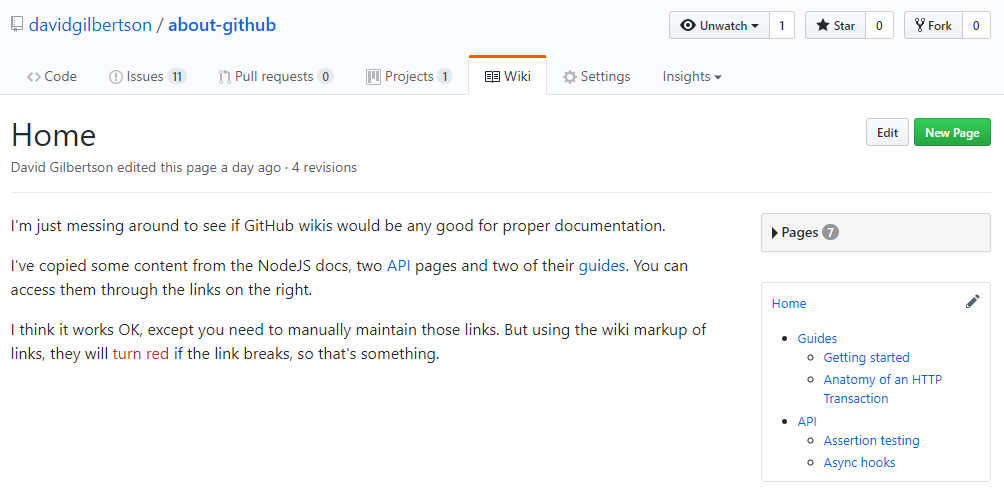
它将不会与像 GitBook(它使用了 Redux 文档)或定制的网站这样的东西相比较。但它八成够用了,而且它就在你的仓库里。
我是它的一个粉丝。
我的建议:如果你已经拥有不止一个 README.md 文件,并且想要一些不同的页面作为用户指南或是更详细的文档,那么下一步你就需要停止使用 Gwiki 了。
如果你开始觉得缺少的结构或导航非常有必要的话,去切换到其他的产品吧。
11 GitHub 页面(带有 Jekyll)
你可能已经知道了可以使用 GitHub 页面 来托管静态站点。如果你不知道的话现在就可以去试试。不过这一节确切的说是关于使用 Jekyll 来构建一个站点。
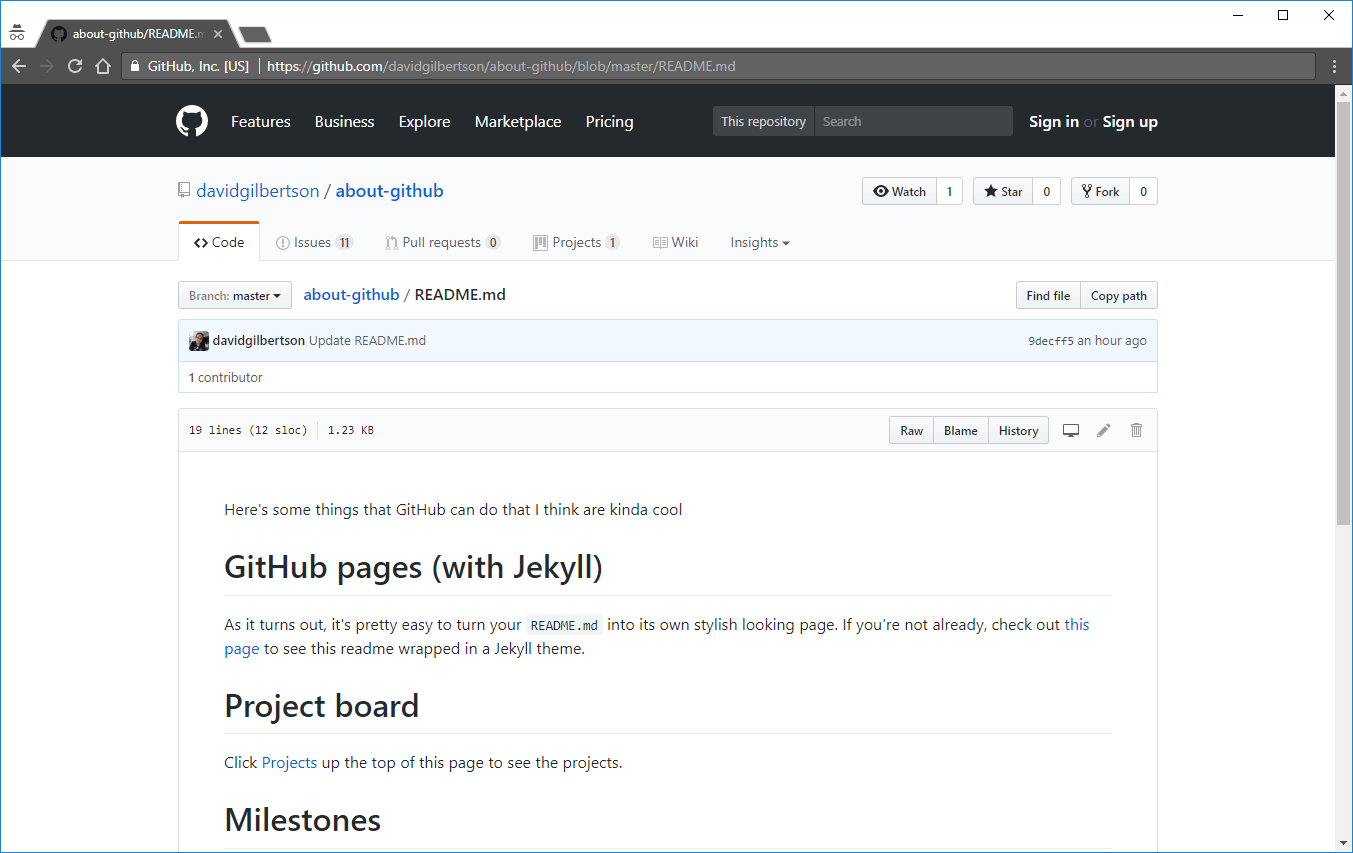
最简单的来说, GitHub 页面 + Jekyll 会将你的 README.md 呈现在一个漂亮的主题中。举个例子,看看我的 关于 github 中的 readme 页面:
点击 GitHub 上我的站点的 设置 标签,开启 GitHub 页面功能,然后挑选一个 Jekyll 主题……
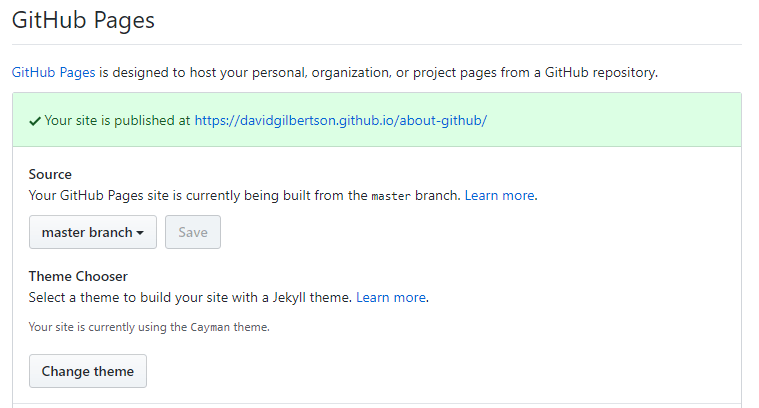
我就会得到一个 Jekyll 主题的页面:
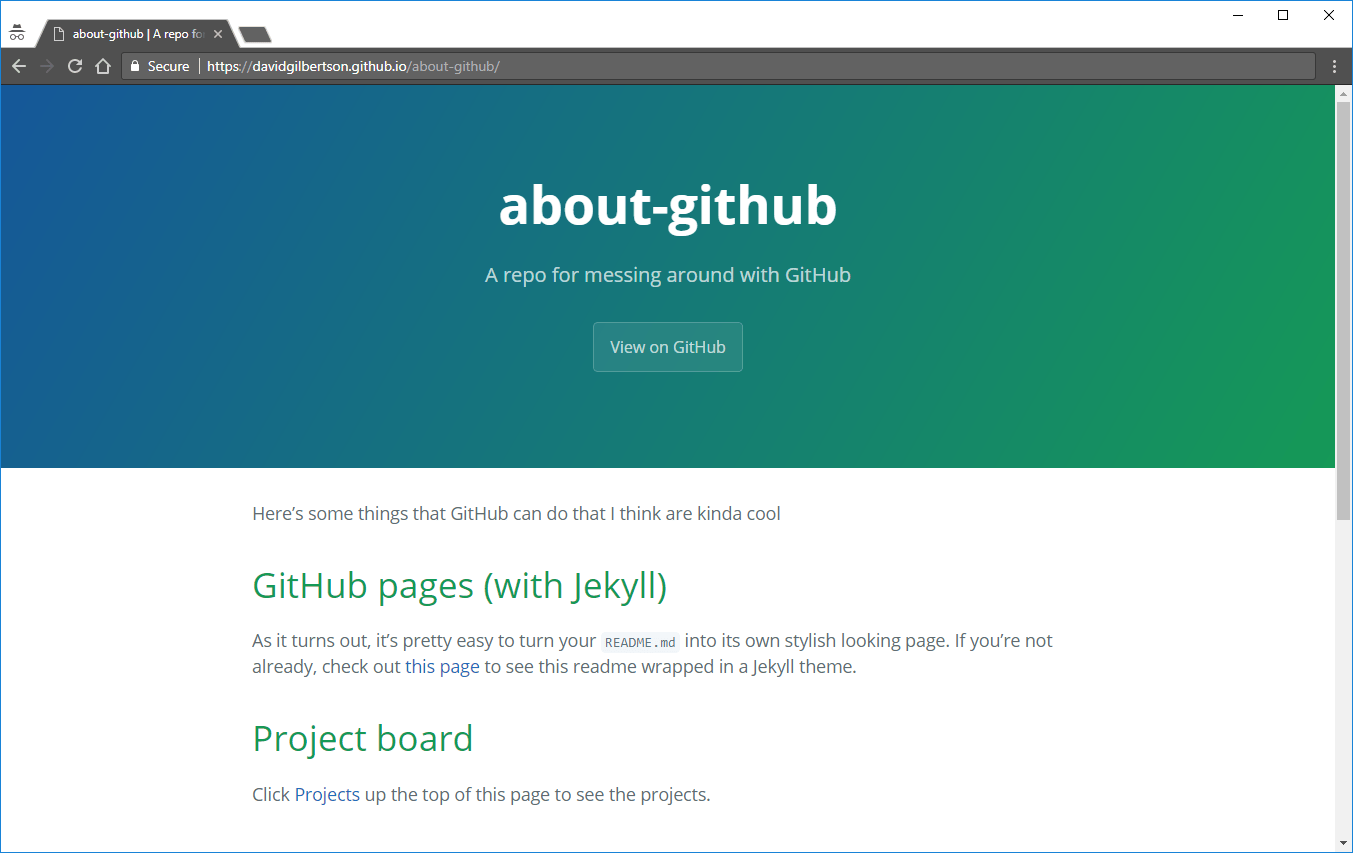
由此我可以构建一个主要基于易于编辑的 markdown 文件的静态站点,其本质上是把 GitHub 变成一个 CMS(LCTT 译注:内容管理系统)。
我还没有真正的使用过它,但这就是 React 和 Bootstrap 网站构建的过程,所以并不可怕。
注意,在本地运行它需要 Ruby (Windows 用户会彼此交换一下眼神,然后转头看向其它的方向。macOS 用户会发出这样这样的声音 “出什么问题了,你要去哪里?Ruby 可是一个通用平台!GEMS 万岁!”)。
(这里也有必要加上,“暴力或威胁的内容或活动” 在 GitHub 页面上是不允许的,因此你不能去部署你的 Hansel 和 Gretel 重启之旅了。)
我的意见
为了这篇文章,我对 GitHub 页面 + Jekyll 研究越多,就越觉得这件事情有点奇怪。
“拥有你自己的网站,让所有的复杂性远离”这样的想法是很棒的。但是你仍然需要在本地生成配置。而且可怕的是需要为这样“简单”的东西使用很多 CLI(LCTT 译注:命令行界面)命令。
我只是略读了入门部分的七页,给我的感觉像是我才是那个小白。此前我甚至从来没有学习过所谓简单的 “Front Matter” 的语法或者所谓简单的 “Liquid 模板引擎” 的来龙去脉。
我宁愿去手工编写一个网站。
老实说我有点惊讶 Facebook 使用它来写 React 文档,因为他们能够用 React 来构建他们的帮助文档,并且在一天之内预渲染到静态的 HTML 文件。
他们所需要做的就是利用已有的 Markdown 文件,就像跟使用 CMS 一样。
我想是这样……
12 使用 GitHub 作为 CMS
比如说你有一个带有一些文本的网站,但是你并不想在 HTML 的标记中储存那些文本。
取而代之,你想要把这堆文本存放到某个地方,以便非开发者也可以很容易地编辑。也许要使用某种形式的版本控制。甚至还可能需要一个审查过程。
这里是我的建议:在你的版本库中使用 markdown 文件存储文本。然后在你的前端使用插件来获取这些文本块并在页面呈现。
我是 React 的支持者,因此这里有一个 <Markdown> 插件的示例,给出一些 markdown 的路径,它就会被获取、解析,并以 HTML 的形式呈现。
(我正在使用 marked npm 包来将 markdown 解析为 HTML。)
这里是我的示例仓库 /text-snippets,里边有一些 markdown 文件 。
(你也可以使用 GitHub API 来获取内容 —— 但我不确定你是否能搞定。)
你可以像这样使用插件:
如此,GitHub 就是你的 CMS 了,可以说,不管有多少文本块都可以放进去。
上边的示例只是在浏览器上安装好插件后获取 markdown 。如果你想要一个静态站点那么你需要服务器端渲染。
有个好消息!没有什么能阻止你从服务器中获取所有的 markdown 文件 (并配上各种为你服务的缓存策略)。如果你沿着这条路继续走下去的话,你可能会想要去试试使用 GitHub API 去获取目录中的所有 markdown 文件的列表。
奖励环节 —— GitHub 工具!
我曾经使用过一段时间的 Chrome 的扩展 Octotree,而且现在我推荐它。虽然不是吐血推荐,但不管怎样我还是推荐它。
它会在左侧提供一个带有树状视图的面板以显示当前你所查看的仓库。
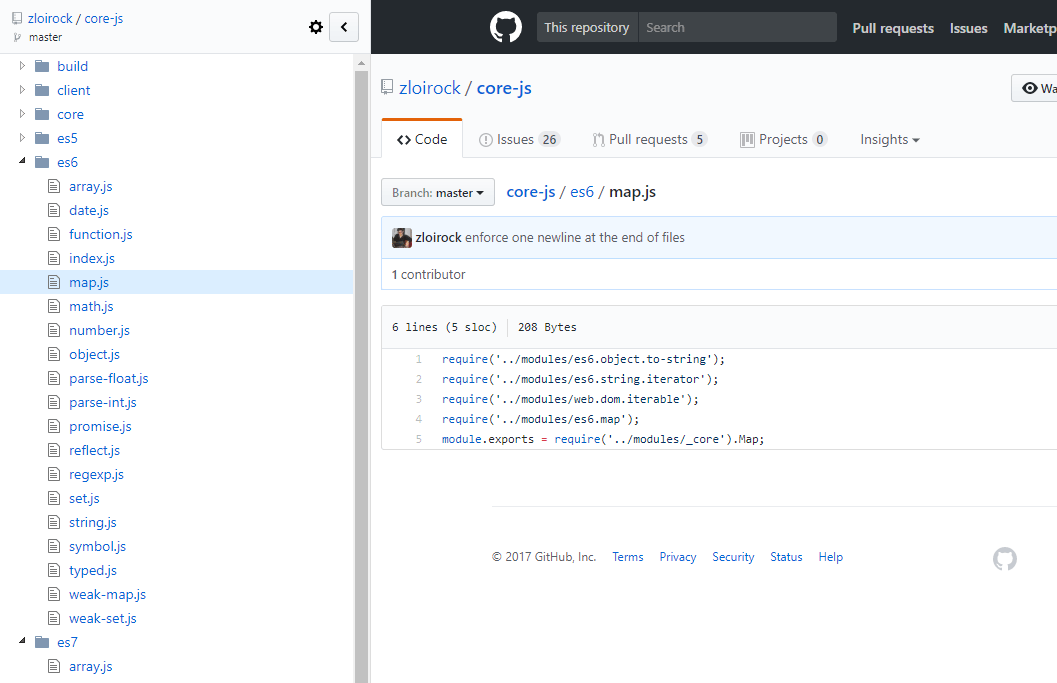
从这个视频中我了解到了 octobox ,到目前为止看起来还不错。它是一个 GitHub 工单的收件箱。这一句介绍就够了。
说到颜色,在上面所有的截图中我都使用了亮色主题,所以希望不要闪瞎你的双眼。不过说真的,我看到的其他东西都是黑色的主题,为什么我非要忍受 GitHub 这个苍白的主题呐?
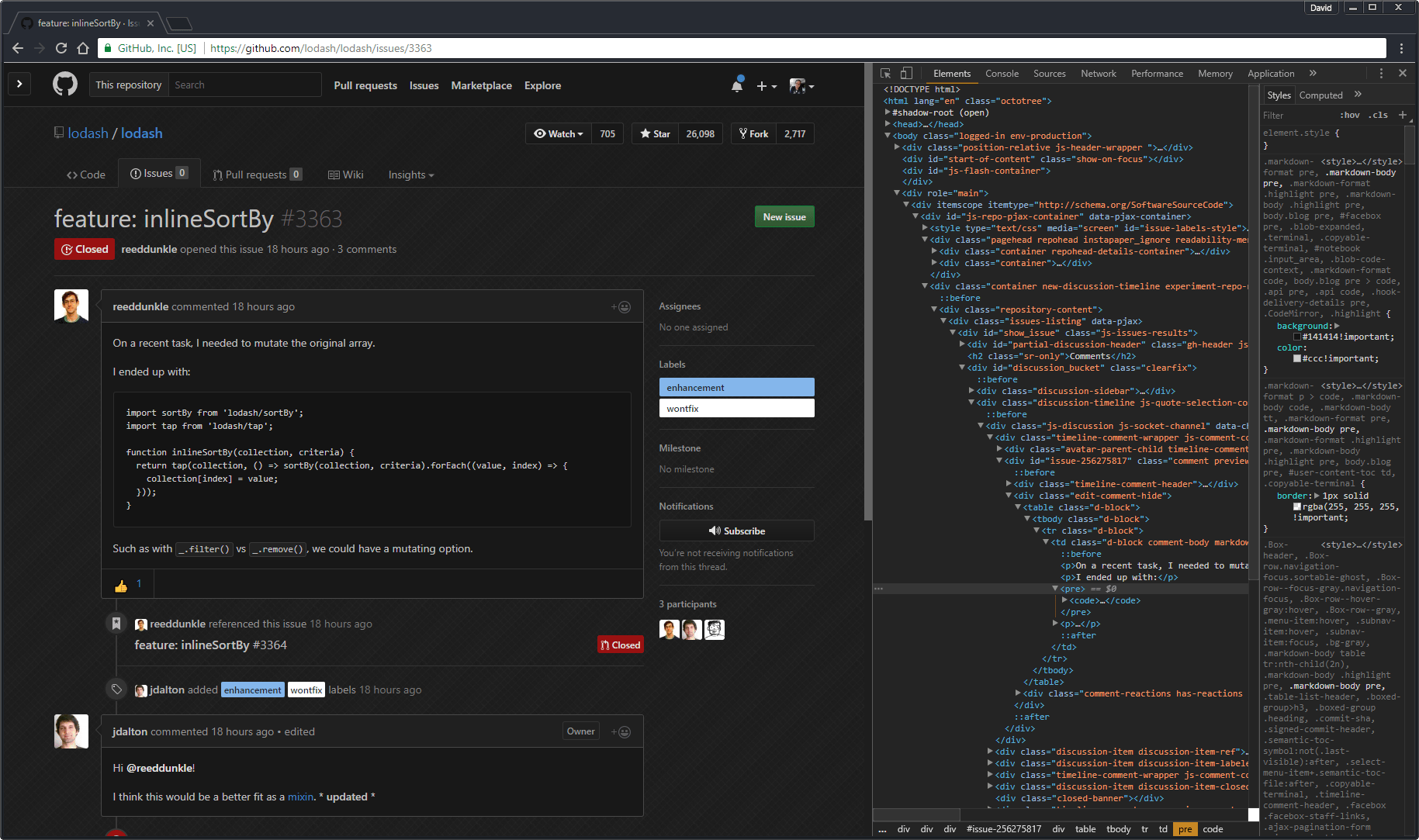
这是由 Chrome 扩展 Stylish(它可以在任何网站使用主题)和 GitHub Dark 风格的一个组合。要完全黑化,那黑色主题的 Chrome 开发者工具(这是内建的,在设置中打开) 以及 Atom One Dark for Chrome 主题你肯定也需要。
Bitbucket
这些内容不适合放在这篇文章的任何地方,但是如果我不称赞 Bitbucket 的话,那就不对了。
两年前我开始了一个项目并花了大半天时间评估哪一个 git 托管服务更适合,最终 Bitbucket 赢得了相当不错的成绩。他们的代码审查流程遥遥领先(这甚至比 GitHub 拥有的指派审阅者的概念要早很长时间)。
GitHub 后来在这次审查竞赛中追了上来,干的不错。不幸的是在过去的一年里我没有机会再使用 Bitbucket —— 也许他们依然在某些方面领先。所以,我会力劝每一个选择 git 托管服务的人考虑一下 Bitbucket 。
结尾
就是这样!我希望这里至少有三件事是你此前并不知道的,祝好。
修订:在评论中有更多的技巧;请尽管留下你自己喜欢的技巧。真的,真心祝好。
(题图:orig08.deviantart.net)
via: https://hackernoon.com/12-cool-things-you-can-do-with-github-f3e0424cf2f0
作者:David Gilbertson 译者:softpaopao 校对:wxy