如何在 Ubuntu 上使用 Grafana 监控 Docker
Grafana 是一个有着丰富指标的开源控制面板。在可视化大规模测量数据的时候是非常有用的。根据不同的指标数据,它提供了一个强大、优雅的来创建、分享和浏览数据的方式。
它提供了丰富多样、灵活的图形选项。此外,针对 数据源 ,它支持许多不同的存储后端。每个数据源都有针对特定数据源的特性和功能所定制的查询编辑器。Grafana 提供了对下述数据源的正式支持:Graphite、InfluxDB、OpenTSDB、 Prometheus、Elasticsearch 和 Cloudwatch。
每个数据源的查询语言和能力显然是不同的,你可以将来自多个数据源的数据混合到一个单一的仪表盘上,但每个 面板 被绑定到属于一个特定 组织 的特定数据源上。它支持验证登录和基于角色的访问控制方案。它是作为一个独立软件部署,使用 Go 和 JavaScript 编写的。

在这篇文章,我将讲解如何在 Ubuntu 16.04 上安装 Grafana 并使用这个软件配置 Docker 监控。
先决条件
- 安装好 Docker 的服务器
安装 Grafana
我们可以在 Docker 中构建我们的 Grafana。 有一个官方提供的 Grafana Docker 镜像。请运行下述命令来构建Grafana 容器。
root@ubuntu:~# docker run -i -p 3000:3000 grafana/grafana
Unable to find image 'grafana/grafana:latest' locally
latest: Pulling from grafana/grafana
5c90d4a2d1a8: Pull complete
b1a9a0b6158e: Pull complete
acb23b0d58de: Pull complete
Digest: sha256:34ca2f9c7986cb2d115eea373083f7150a2b9b753210546d14477e2276074ae1
Status: Downloaded newer image for grafana/grafana:latest
t=2016-07-27T15:20:19+0000 lvl=info msg="Starting Grafana" logger=main version=3.1.0 commit=v3.1.0 compiled=2016-07-12T06:42:28+0000
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/usr/share/grafana/conf/defaults.ini
t=2016-07-27T15:20:19+0000 lvl=info msg="Config loaded from" logger=settings file=/etc/grafana/grafana.ini
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.data=/var/lib/grafana"
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.logs=/var/log/grafana"
t=2016-07-27T15:20:19+0000 lvl=info msg="Config overriden from command line" logger=settings arg="default.paths.plugins=/var/lib/grafana/plugins"
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Home" logger=settings path=/usr/share/grafana
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Data" logger=settings path=/var/lib/grafana
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Logs" logger=settings path=/var/log/grafana
t=2016-07-27T15:20:19+0000 lvl=info msg="Path Plugins" logger=settings path=/var/lib/grafana/plugins
t=2016-07-27T15:20:19+0000 lvl=info msg="Initializing DB" logger=sqlstore dbtype=sqlite3
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist table v2"
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create playlist item table v2"
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v2"
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="drop preferences table v3"
t=2016-07-27T15:20:20+0000 lvl=info msg="Executing migration" logger=migrator id="create preferences table v3"
t=2016-07-27T15:20:20+0000 lvl=info msg="Created default admin user: [admin]"
t=2016-07-27T15:20:20+0000 lvl=info msg="Starting plugin search" logger=plugins
t=2016-07-27T15:20:20+0000 lvl=info msg="Server Listening" logger=server address=0.0.0.0:3000 protocol=http subUrl=
我们可以通过运行此命令确认 Grafana 容器的工作状态 docker ps -a 或通过这个URL访问 http://Docker IP:3000。
所有的 Grafana 配置设置都使用环境变量定义,在使用容器技术时这个是非常有用的。Grafana 配置文件路径为 /etc/grafana/grafana.ini。
理解配置项
Grafana 可以在它的 ini 配置文件中指定几个配置选项,或可以使用前面提到的环境变量来指定。
配置文件位置
通常配置文件路径:
- 默认配置文件路径 :
$WORKING_DIR/conf/defaults.ini - 自定义配置文件路径 :
$WORKING_DIR/conf/custom.ini
PS:当你使用 deb、rpm 或 docker 镜像安装 Grafana 时,你的配置文件在 /etc/grafana/grafana.ini。
理解配置变量
现在我们看一些配置文件中的变量:
instance_name:这是 Grafana 服务器实例的名字。默认值从${HOSTNAME}获取,其值是环境变量HOSTNAME,如果该变量为空或不存在,Grafana 将会尝试使用系统调用来获取机器名。[paths]:这些路径通常都是在 init.d 脚本或 systemd service 文件中通过命令行指定。data:这个是 Grafana 存储 sqlite3 数据库(如果使用)、基于文件的会话(如果使用),和其他数据的路径。logs:这个是 Grafana 存储日志的路径。
[server]http_addr:应用监听的 IP 地址,如果为空,则监听所有的接口。http_port:应用监听的端口,默认是 3000,你可以使用下面的命令将你的 80 端口重定向到 3000 端口:$iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 3000root_url: 这个 URL 用于从浏览器访问 Grafana 。cert_file: 证书文件的路径(如果协议是 HTTPS)。cert_key: 证书密钥文件的路径(如果协议是 HTTPS)。
[database]:Grafana 使用数据库来存储用户和仪表盘以及其他信息,默认配置为使用内嵌在 Grafana 主二进制文件中的 SQLite3。type:你可以根据你的需求选择 MySQL、Postgres、SQLite3。path:仅用于选择 SQLite3 数据库时,这个是数据库所存储的路径。host:仅适用 MySQL 或者 Postgres。它包括 IP 地址或主机名以及端口。例如,Grafana 和 MySQL 运行在同一台主机上设置如:host = 127.0.0.1:3306。name:Grafana 数据库的名称,把它设置为 Grafana 或其它名称。user:数据库用户(不适用于 SQLite3)。password:数据库用户密码(不适用于 SQLite3)。ssl_mode:对于 Postgres,使用disable,require,或verify-full等值。对于 MySQL,使用true,false,或skip-verify。ca_cert_path:(只适用于 MySQL)CA 证书文件路径,在多数 Linux 系统中,证书可以在/etc/ssl/certs找到。client_key_path:(只适用于 MySQL)客户端密钥的路径,只在服务端需要用户端验证时使用。client_cert_path:(只适用于 MySQL)客户端证书的路径,只在服务端需要用户端验证时使用。server_cert_name:(只适用于 MySQL)MySQL 服务端使用的证书的通用名称字段。如果ssl_mode设置为skip-verify时可以不设置。
[security]admin_user:这个是 Grafana 默认的管理员用户的用户名,默认设置为 admin。admin_password:这个是 Grafana 默认的管理员用户的密码,在第一次运行时设置,默认为 admin。login_remember_days:保持登录/记住我的持续天数。secret_key:用于保持登录/记住我的 cookies 的签名。
设置监控的重要组件
我们可以使用下面的组件来创建我们的 Docker 监控系统。
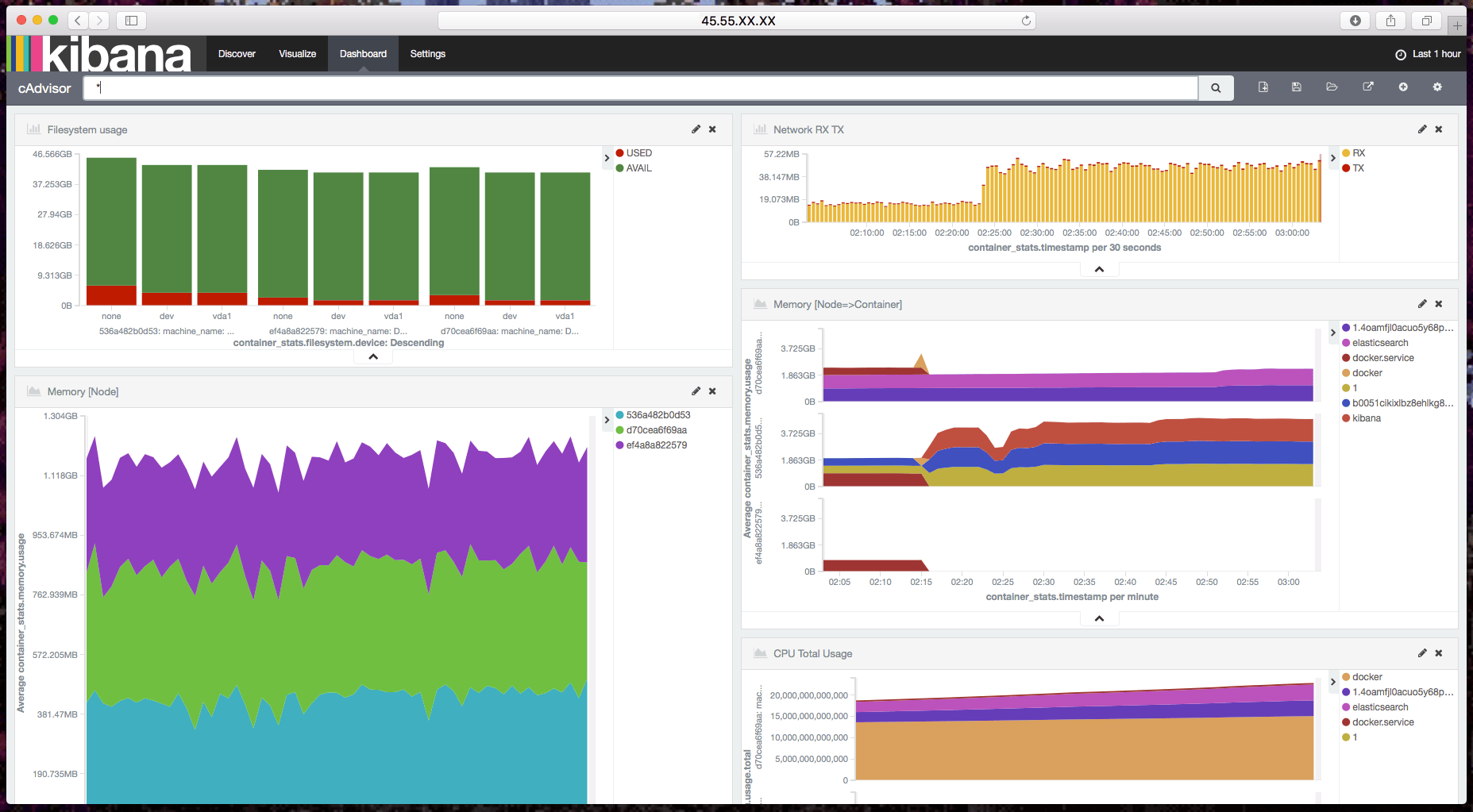
cAdvisor:它被称为 Container Advisor。它给用户提供了一个资源利用和性能特征的解读。它会收集、聚合、处理、导出运行中的容器的信息。你可以通过这个文档了解更多。InfluxDB:这是一个包含了时间序列、度量和分析数据库。我们使用这个数据源来设置我们的监控。cAdvisor 只展示实时信息,并不保存这些度量信息。Influx Db 帮助保存 cAdvisor 提供的监控数据,以展示非某一时段的数据。Grafana Dashboard:它可以帮助我们在视觉上整合所有的信息。这个强大的仪表盘使我们能够针对 InfluxDB 数据存储进行查询并将他们放在一个布局合理好看的图表中。
Docker 监控的安装
我们需要一步一步的在我们的 Docker 系统中安装以下每一个组件:
安装 InfluxDB
我们可以使用这个命令来拉取 InfluxDB 镜像,并部署了 influxDB 容器。
root@ubuntu:~# docker run -d -p 8083:8083 -p 8086:8086 --expose 8090 --expose 8099 -e PRE_CREATE_DB=cadvisor --name influxsrv tutum/influxdb:0.8.8
Unable to find image 'tutum/influxdb:0.8.8' locally
0.8.8: Pulling from tutum/influxdb
a3ed95caeb02: Already exists
23efb549476f: Already exists
aa2f8df21433: Already exists
ef072d3c9b41: Already exists
c9f371853f28: Already exists
a248b0871c3c: Already exists
749db6d368d0: Already exists
7d7c7d923e63: Pull complete
e47cc7808961: Pull complete
1743b6eeb23f: Pull complete
Digest: sha256:8494b31289b4dbc1d5b444e344ab1dda3e18b07f80517c3f9aae7d18133c0c42
Status: Downloaded newer image for tutum/influxdb:0.8.8
d3b6f7789e0d1d01fa4e0aacdb636c221421107d1df96808ecbe8e241ceb1823
-p 8083:8083 : user interface, log in with username-admin, pass-admin
-p 8086:8086 : interaction with other application
--name influxsrv : container have name influxsrv, use to cAdvisor link it.
你可以测试 InfluxDB 是否安装好,通过访问这个 URL http://你的 IP 地址:8083,用户名和密码都是 ”root“。

我们可以在这个界面上创建我们所需的数据库。

安装 cAdvisor
我们的下一个步骤是安装 cAdvisor 容器,并将其链接到 InfluxDB 容器。你可以使用此命令来创建它。
root@ubuntu:~# docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --link influxsrv:influxsrv --name=cadvisor google/cadvisor:latest -storage_driver_db=cadvisor -storage_driver_host=influxsrv:8086
Unable to find image 'google/cadvisor:latest' locally
latest: Pulling from google/cadvisor
09d0220f4043: Pull complete
151807d34af9: Pull complete
14cd28dce332: Pull complete
Digest: sha256:8364c7ab7f56a087b757a304f9376c3527c8c60c848f82b66dd728980222bd2f
Status: Downloaded newer image for google/cadvisor:latest
3bfdf7fdc83872485acb06666a686719983a1172ac49895cd2a260deb1cdde29
root@ubuntu:~#
--publish=8080:8080 : user interface
--link=influxsrv:influxsrv: link to container influxsrv
-storage_driver=influxdb: set the storage driver as InfluxDB
Specify what InfluxDB instance to push data to:
-storage_driver_host=influxsrv:8086: The ip:port of the database. Default is ‘localhost:8086’
-storage_driver_db=cadvisor: database name. Uses db ‘cadvisor’ by default
你可以通过访问这个地址来测试安装 cAdvisor 是否正常 http://你的 IP 地址:8080。 这将为你的 Docker 主机和容器提供统计信息。

安装 Grafana 控制面板
最后,我们需要安装 Grafana 仪表板并连接到 InfluxDB,你可以执行下面的命令来设置它。
root@ubuntu:~# docker run -d -p 3000:3000 -e INFLUXDB_HOST=localhost -e INFLUXDB_PORT=8086 -e INFLUXDB_NAME=cadvisor -e INFLUXDB_USER=root -e INFLUXDB_PASS=root --link influxsrv:influxsrv --name grafana grafana/grafana
f3b7598529202b110e4e6b998dca6b6e60e8608d75dcfe0d2b09ae408f43684a
现在我们可以登录 Grafana 来配置数据源. 访问 http://你的 IP 地址:3000 或 http://你的 IP 地址(如果你在前面做了端口映射的话):
- 用户名 - admin
- 密码 - admin
一旦我们安装好了 Grafana,我们可以连接 InfluxDB。登录到仪表盘并且点击面板左上方角落的 Grafana 图标(那个火球)。点击 数据源 来配置。

现在你可以添加新的 图形 到我们默认的数据源 InfluxDB。

我们可以通过在 测量 页面编辑和调整我们的查询以调整我们的图形。


关于 Docker 监控,你可用从此了解更多信息。 感谢你的阅读。我希望你可以留下有价值的建议和评论。希望你有个美好的一天。
via: http://linoxide.com/linux-how-to/monitor-docker-containers-grafana-ubuntu/
作者:Saheetha Shameer 译者:Bestony 校对:wxy