利用 DNS SRV 记录为 Postfix 提供负载平衡

2011 年 3 月,苹果公司提出 RFC 6186,描述了如何利用域名系统服务(DNS SRV)记录来查找电子邮件的提交以及访问服务。现在 Postfix 从 3.8.0 版本开始支持 RFC 中提出的设计。这个新增功能让你可以使用 DNS SRV 记录进行负载分配和自动配置。
DNS SRV 记录的形态
DNS SRV 记录定义在 RFC 2782 中,它指定在区域文件中,并且包含了服务名称、传输协议规范、优先级、权重、端口,以及提供该服务的主机。
_submission._tcp SRV 5 10 50 bruce.my-domain.com.
| 字段 | 值 | 意义 |
|---|---|---|
| 服务名称 | submission | 服务名为 submission |
| 传输协议规范 | tcp | 本服务使用 TCP 协议 |
| 优先级 | 5 | 服务器优先级设为 5(数值越小,优先级越高) |
| 权重 | 10 | 服务器应承担的负载部分 |
| 端口 | 50 | 服务器监听连接的端口 |
| 目标 | bruce.my-domain.com. | 提供此服务的服务器名称 |
记录解释
服务器选择算法
客户端应该按照 RFC 2782 中描述的方式解析 SRV 记录。这意味着,首先尝试联系拥有最高优先级(最小的优先级数字)的服务器。如果该服务器无回应,那么重试联系拥有同样或者更低优先级的下一台服务器。当有多台服务器拥有同样优先级的时候,应随机选择其中一台,但是必须确保选择记录的概率符合下列公式:
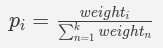
其中 i 是 SRV 记录的标识,k 是具有相同优先级的 SRV 记录的数量。
在现实中,这意味着如果你有两台服务器,其中一台的处理能力是另一台的三倍,那么你应该给第一台服务器的权重赋于另一台三倍的值。这样就能保证更强大的服务器会接收到大约 75% 的客户端请求,而另一台接收大约 25% 的请求。
这些原则使得 SRV 记录能够同时作为客户端自动配置及在服务器之间分配工作负载的工具。
看看以下这个记录的例子:
_submission._tcp SRV 0 0 2525 server-one
_submission._tcp SRV 1 75 2625 server-two
_submission._tcp SRV 1 25 2625 server-three
这里 server-one 总是会被首选来进行联系。如果 server-one 无回应,客户端就会将剩下优先级为 1 的两个记录顺序打乱,生成一个从 0 到 100 的随机数,如果第一条记录的运行总和大于或者等于这个随机数,它就会尝试去联系这个记录。否则,客户端会倒序联系所有服务器。注意,客户端会向它优先成功连接的服务器发送请求。
示例配置
请考虑以下这种情况。你想为大量的电脑配置 Postfix,使其通过公司的邮件服务器利用 SRV 记录转发外部电邮。为了达到这个目标,你需要在每台电脑的 Postfix 中配置 relayhost 参数,即邮件用户代理(MUA)。如果将 relayhost 参数的值设置为 $mydomain,你的机器将开始为你的域名查找 MX 记录,并尝试按照它们的优先级顺序发送邮件。这种方法虽然有效,但是可能会遇到负载平衡问题。Postfix 会使用优先级最高的服务器,直到其变为无响应才会联系其他备用服务器。此外,如果你在环境中使用了动态分配的端口,你无法指明哪个端口正在被特定的服务器使用。使用 SRV 记录,你可以应对这些挑战,并在需要改变服务器端口的时候维持服务器的平滑运行。
区域文件
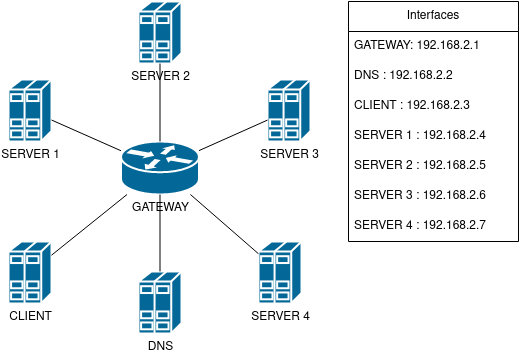
为了使得 DNS 服务器提供信息给客户端,可以参考以下使用服务器 server-one、server-two、server-three 作为中继,并把服务器 server-four 配置为接收测试邮件的区域文件示例。
$TTL 3600
@ IN SOA example-domain.com. root.example-domain.com. (
1571655122 ; 区域文件的序列号
1200 ; 刷新时间
180 ; 发生问题时的重试时间
1209600 ; 过期时间
10800 ) ; 查询失败时的最大缓存时间
;
IN NS ns1
IN A 192.168.2.0
;
ns1 IN A 192.168.2.2
server-one IN A 192.168.2.4
server-two IN A 192.168.2.5
server-three IN A 192.168.2.6
server-four IN A 192.168.2.7
_submission._tcp SRV 0 0 2525 server-one
_submission._tcp SRV 1 50 2625 server-two
_submission._tcp SRV 1 50 2625 server-three
@ MX 0 server-four
Postfix MUA 配置
设置客户端机器去查找 SRV 记录:
use_srv_lookup = submission
relayhost = example-domain.com:submission
通过这个配置,你的客户端机器上的 Postfix 实例会联络到 example-domain 的 DNS 服务器,然后获取邮件提交的 SRV 记录。在这个例子中,server-one 有最高的优先级,Postfix 会先试图连接它。然后,Postfix 随机的选择剩下的两个服务器其中一个去尝试连接。这个配置确保了大约有 50% 的机会会优先联系到服务器一。注意,SRV 记录的权重值并不等同于百分比。你也可以用 1 和 1 这样的值达到同样的目标。
同时,Postfix 也知道 server-one 在监听 2525 端口,而 server-two 在监听 2625 端口。如果你正在缓存检索到的 DNS 记录,并且你动态改变 SRV 记录,那么设置一个低的生存时间(TTL)对你的记录是很重要的。
整套设置
你可以通过下面的方式尝试这个配置,包含 podman 和在此处提供的 compose 文件:
$ git clone https://github.com/TomasKorbar/srv_article
$ cd srv_article/environment
$ podman-compose up
$ podman exec -it article_client /bin/bash
root@client # ./senddummy.sh
root@client # exit
完成配置之后,你可以检查日志,查看邮件是否经过 server-one 并最终投递到 server-four。
$ podman stop article_server1
$ podman exec -it article_client /bin/bash
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # ./senddummy.sh
root@client # exit
现在 server-one 已经关闭了,这六封邮件将会由 server-two 或者 server-three 中转发出去。
仔细看一下 Dockerfiles 以更深地理解这个配置。
通过执行:$ podman-compose down 完成示例的操作。
(题图:DA/241079fe-58d6-4dc6-8801-f0fd19dfd64b)
via: https://fedoramagazine.org/using-postfix-dns-srv-record-resolution-feature/
作者:Tomáš Korbař 选题:lujun9972 译者:ChatGPT 校对:wxy







