如何使用Monit部署服务器监控系统
很多Linux系统管理员依赖一个集中式的远程监控系统(比如Nagios或者Cacti)来检查他们网络基础设备的健康状况。虽然集中式监控让管理员的生活更简单了,然而处理很多机器和服务时,专用的监控中心显然成为了一个单点故障,如果监控中心挂了或者因为什么原因(比如硬件或者网络故障)不可访问了,你就会失去整个网络基础设备情况的任何信息。
一个给你的监控系统增加冗余度的方法是安装独立的监控软件(作为后备),至少在网络中的关键/核心服务器上。这样在集中式监控系统挂掉的情况,你还有能力通过后备的监控方式来获取核心服务器的运行状况。
Monit是什么?

Monit是一个跨平台的用来监控Unix/linux系统(比如Linux、BSD、OSX、Solaris)的工具。Monit特别易于安装,而且非常轻量级(只有500KB大小),并且不依赖任何第三方程序、插件或者库。然而,Monit可以胜任全面监控、进程状态监控、文件系统变动监控、邮件通知和对核心服务的自定义动作等场景。易于安装、轻量级的实现以及强大的功能,让Monit成为一个理想的后备监控工具。
我已经在一些机器使用Monit几年了,而且我对它的可靠性非常满意。甚至作为全面的监控系统,对任何Linux系统管理员来说Monit也是非常有用和强大的。在这篇教程中,我会展示如何在一个本地服务器部署Monit(作为后备监控系统)来监控常见的服务。在部署过程中,我只会展示我们用到的部分。
在Linux安装Monit
Monit已经被包含在多数Linux发行版的软件仓库中了。
Debian、Ubuntu或者Linux Mint:
$ sudo aptitude install monit
Fedora或者CentOS/RHEL:
在CentOS/RHEL中,你必须首先启用EPEL或者Repoforge软件仓库.
# yum install monit
Monit自带一个文档完善的配置文件,其中包含了很多例子。主配置文件在/etc/monit.conf(Fedora/CentOS/RHEL 中),或者/etc/monit/monitrc(Debian/Ubuntu/Mint 中)。Monit配置文件有两部分:“Global”(全局)和“Services”(服务)。
Global Configuration: Web Status Page (全局配置:Web状态页面)
Monit可以使用邮件服务来发送通知,也可以使用HTTP/HTTPS页面来展示。我们先使用如下配置的web状态页面吧:
- Monit监听1966端口。
- 对web状态页面的访问是通过SSL加密的。
- 使用monituser/romania作为用户名/口令登录。
- 只允许通过localhost、myhost.mydomain.ro和在局域网内部(192.168.0.0/16)访问。
- Monit使用pem格式的SSL证书。
之后的步骤,我会使用一个基于Red Hat的系统。在基于Debian的系统中的步骤也是类似的。
首先,在/var/cert生成一个自签名的证书(monit.pem):
# mkdir /var/certs
# cd /etc/pki/tls/certs
# ./make-dummy-cert monit.pem
# cp monit.pem /var/certs
# chmod 0400 /var/certs/monit.pem
现在将下列代码片段放到Monit的主配置文件中。你可以创建一个空配置文件,或者基于自带的配置文件修改。
set httpd port 1966 and
SSL ENABLE
PEMFILE /var/certs/monit.pem
allow monituser:romania
allow localhost
allow 192.168.0.0/16
allow myhost.mydomain.ro
Global Configuration: Email Notification (全局配置:邮件通知)
然后,我们来设置Monit的邮件通知。我们至少需要一个可用的SMTP服务器来让Monit发送邮件。这样就可以(按照你的实际情况修改):
- 邮件服务器的机器名:smtp.monit.ro
- Monit使用的发件人:[email protected]
- 邮件的收件人:[email protected]
- 邮件服务器使用的SMTP端口:587(默认是25)
有了以上信息,邮件通知就可以这样配置:
set mailserver smtp.monit.ro port 587
set mail-format {
from: [email protected]
subject: $SERVICE $EVENT at $DATE on $HOST
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
Yours sincerely,
Monit
}
set alert [email protected]
就像你看到的,Monit会提供几个内部变量($DATE、$EVENT、$HOST等),你可以按照你的需求自定义邮件内容。如果你想要从Monit所在机器发送邮件,就需要一个已经安装的与sendmail兼容的程序(如postfix或者ssmtp)。
Global Configuration: Monit Daemon (全局配置:Monit守护进程)
接下来就该配置Monit守护进程了。可以将其设置成这样:
- 在120秒后进行第一次检测。
- 每3分钟检测一次服务。
- 使用syslog来记录日志。
如下代码段可以满足上述需求。
set daemon 120
with start delay 240
set logfile syslog facility log_daemon
我们必须定义“idfile”,Monit守护进程的一个独一无二的ID文件;以及“eventqueue”,当monit的邮件因为SMTP或者网络故障发不出去,邮件会暂存在这里;以及确保/var/monit路径是存在的。然后使用下边的配置就可以了。
set idfile /var/monit/id
set eventqueue
basedir /var/monit
测试全局配置
现在“Global”部分就完成了。Monit配置文件看起来像这样:
# Global Section
# status webpage and acl's
set httpd port 1966 and
SSL ENABLE
PEMFILE /var/certs/monit.pem
allow monituser:romania
allow localhost
allow 192.168.0.0/16
allow myhost.mydomain.ro
# mail-server
set mailserver smtp.monit.ro port 587
# email-format
set mail-format {
from: [email protected]
subject: $SERVICE $EVENT at $DATE on $HOST
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
Yours sincerely,
Monit
}
set alert [email protected]
# delay checks
set daemon 120
with start delay 240
set logfile syslog facility log_daemon
# idfile and mail queue path
set idfile /var/monit/id
set eventqueue
basedir /var/monit
现在是时候验证我们的工作了,你可以通过运行如下命令来验证存在的配置文件(/etc/monit.conf):
# monit -t
Control file syntax OK
如果monit提示任何错误,请再检查下配置文件。幸运的是,错误/警告信息是可以帮助你发现问题的,比如:
monit: Cannot stat the SSL server PEM file '/var/certs/monit.pem' -- No such file or directory
/etc/monit/monitrc:10: Warning: hostname did not resolve 'smtp.monit.ro'
一旦你确认配置文件没问题了,可以启动monit守护进程,然后等2到3分钟:
# service monit start
如果你使用的是systemd,运行:
# systemctl start monit
现在打开一个浏览器窗口,然后访问https://<monit_host>:1966。将<monit_host>替换成Monit所在机器的机器名或者IP地址。
如果你使用的是自签名的SSL证书,你会在浏览器中看到一个警告信息。继续访问即可。
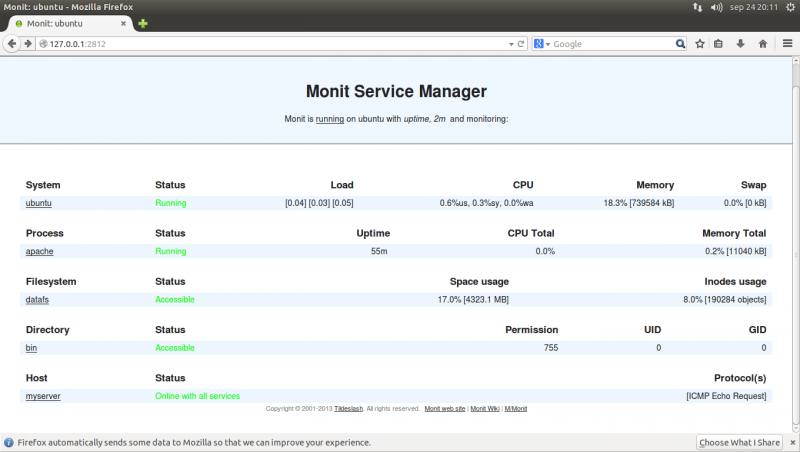
你完成登录后,就会看到这个页面。
在这个教程的其余部分,我们演示监控一个本地服务器和常见服务的方法。你会在官方wiki页面看到很多有用的例子。其中的多数是可以直接复制粘贴的!
Service Configuration: CPU/Memory Monitoring (服务配置:CPU、内存监控)
我们先来监控本地服务器的CPU、内存占用。复制如下代码段到配置文件中。
check system localhost
if loadavg (1min) > 10 then alert
if loadavg (5min) > 6 then alert
if memory usage > 75% then alert
if cpu usage (user) > 70% then alert
if cpu usage (system) > 60% then alert
if cpu usage (wait) > 75% then alert
你可以很容易理解上边的配置。最上边的check是指每个监控周期(全局配置里设置的120秒)都对本机进行下面的操作。如果满足了任何条件,monit守护进程就会使用邮件发送一条报警。
如果某个监控项不需要每个周期都检查,可以使用如下格式,它会每240秒检查一次平均负载。
if loadavg (1min) > 10 for 2 cycles then alert
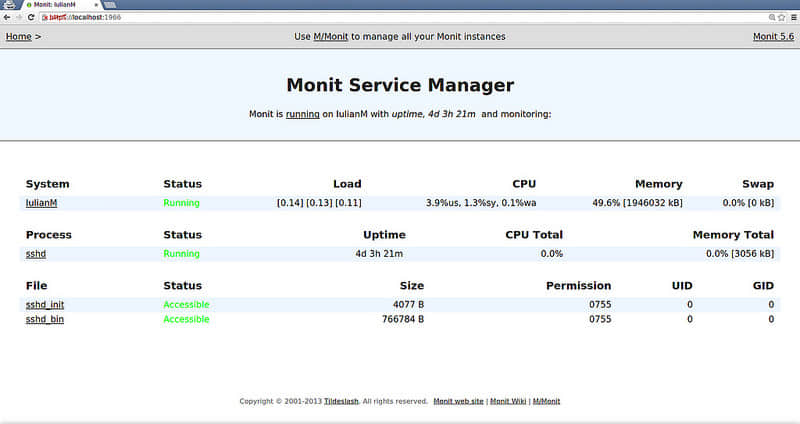
Service Configuration: SSH Service Monitoring (服务配置:SSH服务监控)
先检查我们的sshd是否安装在/usr/sbin/sshd:
check file sshd_bin with path /usr/sbin/sshd
我们还想检查sshd的启动脚本是否存在:
check file sshd_init with path /etc/init.d/sshd
最后,我们还想检查sshd守护进程是否存活,并且在监听22端口:
check process sshd with pidfile /var/run/sshd.pid
start program "/etc/init.d/sshd start"
stop program "/etc/init.d/sshd stop"
if failed port 22 protocol ssh then restart
if 5 restarts within 5 cycles then timeout
我们可以这样解释上述配置:我们检查是否存在名为sshd的进程,并且有一个保存其pid的文件存在(/var/run/sshd.pid)。如果任何一个不存在,我们就使用启动脚本重启sshd。我们检查是否有进程在监听22端口,并且使用的是SSH协议。如果没有,我们还是重启sshd。如果在最近的5个监控周期(5x120秒)至少重启5次了,sshd就被认为是不能用的,我们就不再检查了。
Service Configuration: SMTP Service Monitoring (服务配置:SMTP服务监控)
现在我们来设置一个检查远程SMTP服务器(如192.168.111.102)的监控。假定SMTP服务器运行着SMTP、IMAP、SSH服务。
check host MAIL with address 192.168.111.102
if failed icmp type echo within 10 cycles then alert
if failed port 25 protocol smtp then alert
else if recovered then exec "/scripts/mail-script"
if failed port 22 protocol ssh then alert
if failed port 143 protocol imap then alert
我们检查远程主机是否响应ICMP协议。如果我们在10个周期内没有收到ICMP回应,就发送一条报警。如果监测到25端口上的SMTP协议是异常的,就发送一条报警。如果在一次监测失败后又监测成功了,就运行一个脚本(/scripts/mail-script)。如果检查22端口上的SSH或者143端口上的IMAP协议不正常,同样发送报警。
总结
在这个教程,我演示了如何在本地服务器设置Monit,当然这只是Monit功能的冰山一角。你可以花些时间阅读Monit的man手册(写得很好)。Monit可以为任何Linux系统管理员做很多事情,并且具有非常优美和易于理解的语法。如果你将一个集中式的远程监控系统和Monit一同使用,你会得到一个更可靠的监控系统。你感觉Monit怎么样?
via: http://xmodulo.com/server-monitoring-system-monit.html
作者:Iulian Murgulet 译者:goreliu 校对:wxy

























 更多信息可以在
更多信息可以在