您需要监控 Linux 服务器的性能吗?试试用这些内置命令和附加工具吧!大多数 Linux 发行版都附带了大量的监控工具。这些工具提供了获取系统活动的相关指标。您可以使用这些工具来查找性能问题的可能原因。本文提到的是一些基本的命令,用于系统分析和服务器调试等,例如:
- 找出系统瓶颈
- 磁盘(存储)瓶颈
- CPU 和内存瓶颈
- 网络瓶颈
1. top - 进程活动监控命令
top 命令会显示 Linux 的进程。它提供了一个运行中系统的实时动态视图,即实际的进程活动。默认情况下,它显示在服务器上运行的 CPU 占用率最高的任务,并且每五秒更新一次。
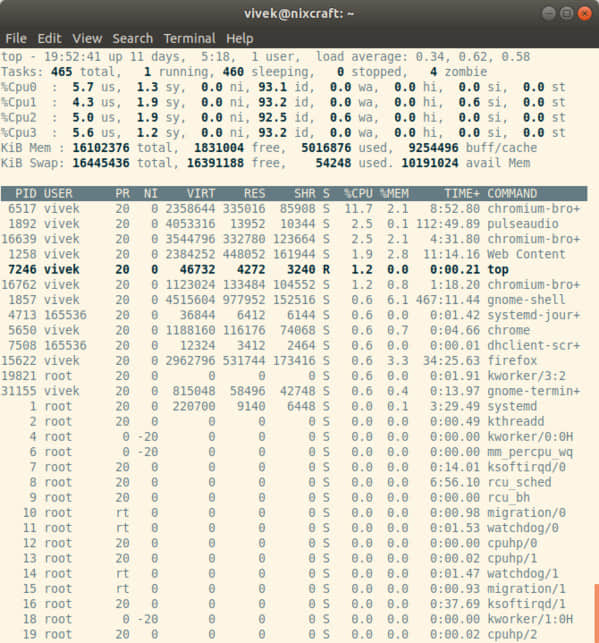
图 01:Linux top 命令
top 的常用快捷键
常用快捷键列表:
| 快捷键 | 用法 |
|---|
t | 是否显示汇总信息 |
m | 是否显示内存信息 |
A | 根据各种系统资源的利用率对进程进行排序,有助于快速识别系统中性能不佳的任务。 |
f | 进入 top 的交互式配置屏幕,用于根据特定的需求而设置 top 的显示。 |
o | 交互式地调整 top 每一列的顺序。 |
r | 调整优先级(renice) |
k | 杀掉进程(kill) |
z | 切换彩色或黑白模式 |
相关链接:Linux 如何查看 CPU 利用率?
2. vmstat - 虚拟内存统计
vmstat 命令报告有关进程、内存、分页、块 IO、中断和 CPU 活动等信息。
# vmstat 3
输出示例:
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 2540988 522188 5130400 0 0 2 32 4 2 4 1 96 0 0
1 0 0 2540988 522188 5130400 0 0 0 720 1199 665 1 0 99 0 0
0 0 0 2540956 522188 5130400 0 0 0 0 1151 1569 4 1 95 0 0
0 0 0 2540956 522188 5130500 0 0 0 6 1117 439 1 0 99 0 0
0 0 0 2540940 522188 5130512 0 0 0 536 1189 932 1 0 98 0 0
0 0 0 2538444 522188 5130588 0 0 0 0 1187 1417 4 1 96 0 0
0 0 0 2490060 522188 5130640 0 0 0 18 1253 1123 5 1 94 0 0
显示 Slab 缓存的利用率
# vmstat -m
获取有关活动和非活动内存页面的信息
# vmstat -a
相关链接:如何查看 Linux 的资源利用率从而找到系统瓶颈?
3. w - 找出登录的用户以及他们在做什么
w 命令 显示了当前登录在该系统上的用户及其进程。
# w username
# w vivek
输出示例:
17:58:47 up 5 days, 20:28, 2 users, load average: 0.36, 0.26, 0.24
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 10.1.3.145 14:55 5.00s 0.04s 0.02s vim /etc/resolv.conf
root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
4. uptime - Linux 系统运行了多久
uptime 命令可以用来查看服务器运行了多长时间:当前时间、已运行的时间、当前登录的用户连接数,以及过去 1 分钟、5 分钟和 15 分钟的系统负载平均值。
# uptime
输出示例:
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
1 可以被认为是最佳负载值。不同的系统会有不同的负载:对于单核 CPU 系统来说,1 到 3 的负载值是可以接受的;而对于 SMP(对称多处理)系统来说,负载可以是 6 到 10。
5. ps - 显示系统进程
ps 命令显示当前运行的进程。要显示所有的进程,请使用 -A 或 -e 选项:
# ps -A
输出示例:
PID TTY TIME CMD
1 ? 00:00:02 init
2 ? 00:00:02 migration/0
3 ? 00:00:01 ksoftirqd/0
4 ? 00:00:00 watchdog/0
5 ? 00:00:00 migration/1
6 ? 00:00:15 ksoftirqd/1
....
.....
4881 ? 00:53:28 java
4885 tty1 00:00:00 mingetty
4886 tty2 00:00:00 mingetty
4887 tty3 00:00:00 mingetty
4888 tty4 00:00:00 mingetty
4891 tty5 00:00:00 mingetty
4892 tty6 00:00:00 mingetty
4893 ttyS1 00:00:00 agetty
12853 ? 00:00:00 cifsoplockd
12854 ? 00:00:00 cifsdnotifyd
14231 ? 00:10:34 lighttpd
14232 ? 00:00:00 php-cgi
54981 pts/0 00:00:00 vim
55465 ? 00:00:00 php-cgi
55546 ? 00:00:00 bind9-snmp-stat
55704 pts/1 00:00:00 ps
ps 与 top 类似,但它提供了更多的信息。
显示长输出格式
# ps -Al
显示完整输出格式(它将显示传递给进程的命令行参数):
# ps -AlF
显示线程(轻量级进程(LWP)和线程的数量(NLWP))
# ps -AlFH
在进程后显示线程
# ps -AlLm
显示系统上所有的进程
# ps ax
# ps axu
显示进程树
# ps -ejH
# ps axjf
# pstree
显示进程的安全信息
# ps -eo euser,ruser,suser,fuser,f,comm,label
# ps axZ
# ps -eM
显示指定用户(如 vivek)运行的进程
# ps -U vivek -u vivek u
设置用户自定义的输出格式
# ps -eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,wchan:14,comm
# ps axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm
# ps -eopid,tt,user,fname,tmout,f,wchan
显示某进程(如 lighttpd)的 PID
# ps -C lighttpd -o pid=
或
# pgrep lighttpd
或
# pgrep -u vivek php-cgi
显示指定 PID(如 55977)的进程名称
# ps -p 55977 -o comm=
找出占用内存资源最多的前 10 个进程
# ps -auxf | sort -nr -k 4 | head -10
找出占用 CPU 资源最多的前 10 个进程
# ps -auxf | sort -nr -k 3 | head -10
相关链接:显示 Linux 上所有运行的进程
6. free - 内存使用情况
free 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。
# free
输出示例:
total used free shared buffers cached
Mem: 12302896 9739664 2563232 0 523124 5154740
-/+ buffers/cache: 4061800 8241096
Swap: 1052248 0 1052248
相关链接: 1. 获取 Linux 的虚拟内存的内存页大小(PAGESIZE) 2. 限制 Linux 每个进程的 CPU 使用率 3. 我的 Ubuntu 或 Fedora Linux 系统有多少内存?
7. iostat - CPU 平均负载和磁盘活动
iostat 命令用于汇报 CPU 的使用情况,以及设备、分区和网络文件系统(NFS)的 IO 统计信息。
# iostat
输出示例:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
avg-cpu: %user %nice %system %iowait %steal %idle
3.50 0.09 0.51 0.03 0.00 95.86
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 22.04 31.88 512.03 16193351 260102868
sda1 0.00 0.00 0.00 2166 180
sda2 22.04 31.87 512.03 16189010 260102688
sda3 0.00 0.00 0.00 1615 0
相关链接:如何跟踪 Linux 系统的 NFS 目录或磁盘的 IO 负载情况
8. sar - 监控、收集和汇报系统活动
sar 命令用于收集、汇报和保存系统活动信息。要查看网络统计,请输入:
# sar -n DEV | more
显示 24 日的网络统计:
# sar -n DEV -f /var/log/sa/sa24 | more
您还可以使用 sar 显示实时使用情况:
# sar 4 5
输出示例:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
06:45:12 PM CPU %user %nice %system %iowait %steal %idle
06:45:16 PM all 2.00 0.00 0.22 0.00 0.00 97.78
06:45:20 PM all 2.07 0.00 0.38 0.03 0.00 97.52
06:45:24 PM all 0.94 0.00 0.28 0.00 0.00 98.78
06:45:28 PM all 1.56 0.00 0.22 0.00 0.00 98.22
06:45:32 PM all 3.53 0.00 0.25 0.03 0.00 96.19
Average: all 2.02 0.00 0.27 0.01 0.00 97.70
相关链接:
9. mpstat - 监控多处理器的使用情况
mpstat 命令显示每个可用处理器的使用情况,编号从 0 开始。命令 mpstat -P ALL 显示了每个处理器的平均使用率:
# mpstat -P ALL
输出示例:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
06:48:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
06:48:11 PM all 3.50 0.09 0.34 0.03 0.01 0.17 0.00 95.86 1218.04
06:48:11 PM 0 3.44 0.08 0.31 0.02 0.00 0.12 0.00 96.04 1000.31
06:48:11 PM 1 3.10 0.08 0.32 0.09 0.02 0.11 0.00 96.28 34.93
06:48:11 PM 2 4.16 0.11 0.36 0.02 0.00 0.11 0.00 95.25 0.00
06:48:11 PM 3 3.77 0.11 0.38 0.03 0.01 0.24 0.00 95.46 44.80
06:48:11 PM 4 2.96 0.07 0.29 0.04 0.02 0.10 0.00 96.52 25.91
06:48:11 PM 5 3.26 0.08 0.28 0.03 0.01 0.10 0.00 96.23 14.98
06:48:11 PM 6 4.00 0.10 0.34 0.01 0.00 0.13 0.00 95.42 3.75
06:48:11 PM 7 3.30 0.11 0.39 0.03 0.01 0.46 0.00 95.69 76.89
相关链接:多处理器的 Linux 上单独显示每个 CPU 的使用率.
10. pmap - 监控进程的内存使用情况
pmap 命令用以显示进程的内存映射,使用此命令可以查找内存瓶颈。
# pmap -d PID
显示 PID 为 47394 的进程的内存信息,请输入:
# pmap -d 47394
输出示例:
47394: /usr/bin/php-cgi
Address Kbytes Mode Offset Device Mapping
0000000000400000 2584 r-x-- 0000000000000000 008:00002 php-cgi
0000000000886000 140 rw--- 0000000000286000 008:00002 php-cgi
00000000008a9000 52 rw--- 00000000008a9000 000:00000 [ anon ]
0000000000aa8000 76 rw--- 00000000002a8000 008:00002 php-cgi
000000000f678000 1980 rw--- 000000000f678000 000:00000 [ anon ]
000000314a600000 112 r-x-- 0000000000000000 008:00002 ld-2.5.so
000000314a81b000 4 r---- 000000000001b000 008:00002 ld-2.5.so
000000314a81c000 4 rw--- 000000000001c000 008:00002 ld-2.5.so
000000314aa00000 1328 r-x-- 0000000000000000 008:00002 libc-2.5.so
000000314ab4c000 2048 ----- 000000000014c000 008:00002 libc-2.5.so
.....
......
..
00002af8d48fd000 4 rw--- 0000000000006000 008:00002 xsl.so
00002af8d490c000 40 r-x-- 0000000000000000 008:00002 libnss_files-2.5.so
00002af8d4916000 2044 ----- 000000000000a000 008:00002 libnss_files-2.5.so
00002af8d4b15000 4 r---- 0000000000009000 008:00002 libnss_files-2.5.so
00002af8d4b16000 4 rw--- 000000000000a000 008:00002 libnss_files-2.5.so
00002af8d4b17000 768000 rw-s- 0000000000000000 000:00009 zero (deleted)
00007fffc95fe000 84 rw--- 00007ffffffea000 000:00000 [ stack ]
ffffffffff600000 8192 ----- 0000000000000000 000:00000 [ anon ]
mapped: 933712K writeable/private: 4304K shared: 768000K
最后一行非常重要:
mapped: 933712K 映射到文件的内存量writeable/private: 4304K 私有地址空间shared: 768000K 此进程与其他进程共享的地址空间
相关链接:使用 pmap 命令查看 Linux 上单个程序或进程使用的内存
11. netstat - Linux 网络统计监控工具
netstat 命令显示网络连接、路由表、接口统计、伪装连接和多播连接等信息。
# netstat -tulpn
# netstat -nat
12. ss - 网络统计
ss 命令用于获取套接字统计信息。它可以显示类似于 netstat 的信息。不过 netstat 几乎要过时了,ss 命令更具优势。要显示所有 TCP 或 UDP 套接字:
# ss -t -a
或
# ss -u -a
显示所有带有 SELinux 安全上下文 的 TCP 套接字:
# ss -t -a -Z
请参阅以下关于 ss 和 netstat 命令的资料:
13. iptraf - 获取实时网络统计信息
iptraf 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可以生成多种网络统计信息,包括 TCP 信息、UDP 计数、ICMP 和 OSPF 信息、以太网负载信息、节点统计信息、IP 校验错误等。它以简单的格式提供了以下信息:
- 基于 TCP 连接的网络流量统计
- 基于网络接口的 IP 流量统计
- 基于协议的网络流量统计
- 基于 TCP/UDP 端口和数据包大小的网络流量统计
- 基于二层地址的网络流量统计

图 02:常规接口统计:基于网络接口的 IP 流量统计

图 03:基于 TCP 连接的网络流量统计
相关链接:在 Centos / RHEL / Fedora Linux 上安装 IPTraf 以获取网络统计信息
14. tcpdump - 详细的网络流量分析
tcpdump 命令是简单的分析网络通信的命令。您需要充分了解 TCP/IP 协议才便于使用此工具。例如,要显示有关 DNS 的流量信息,请输入:
# tcpdump -i eth1 'udp port 53'
查看所有去往和来自端口 80 的 IPv4 HTTP 数据包,仅打印真正包含数据的包,而不是像 SYN、FIN 和仅含 ACK 这类的数据包,请输入:
# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
显示所有目标地址为 202.54.1.5 的 FTP 会话,请输入:
# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'
打印所有目标地址为 192.168.1.5 的 HTTP 会话:
# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'
使用 wireshark 查看文件的详细内容,请输入:
# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80
15. iotop - I/O 监控
iotop 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程的顺序显示 I/O 使用情况。
$ sudo iotop
输出示例:

相关链接:Linux iotop:什么进程在增加硬盘负载
16. htop - 交互式的进程查看器
htop 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它比 top 命令更简单易用。您无需使用 PID、无需离开 htop 界面,便可以杀掉进程或调整其调度优先级。
$ htop
输出示例:

相关链接:CentOS / RHEL:安装 htop——交互式文本模式进程查看器
17. atop - 高级版系统与进程监控工具
atop 是一个非常强大的交互式 Linux 系统负载监控器,它从性能的角度显示最关键的硬件资源信息。您可以快速查看 CPU、内存、磁盘和网络性能。它还可以从进程的级别显示哪些进程造成了相关 CPU 和内存的负载。
$ atop

相关链接:CentOS / RHEL:安装 atop 工具——高级系统和进程监控器
18. ac 和 lastcomm
您一定需要监控 Linux 服务器上的进程和登录活动吧。psacct 或 acct 软件包中包含了多个用于监控进程活动的工具,包括:
ac 命令:显示有关用户连接时间的统计信息- lastcomm 命令:显示已执行过的命令
accton 命令:打开或关闭进程账号记录功能sa 命令:进程账号记录信息的摘要
相关链接:如何对 Linux 系统的活动做详细的跟踪记录
19. monit - 进程监控器
monit 是一个免费且开源的进程监控软件,它可以自动重启停掉的服务。您也可以使用 Systemd、daemontools 或其他类似工具来达到同样的目的。本教程演示如何在 Debian 或 Ubuntu Linux 上安装和配置 monit 作为进程监控器。
20. NetHogs - 找出占用带宽的进程
NetHogs 是一个轻便的网络监控工具,它按照进程名称(如 Firefox、wget 等)对带宽进行分组。如果网络流量突然爆发,启动 NetHogs,您将看到哪个进程(PID)导致了带宽激增。
$ sudo nethogs

相关链接:Linux:使用 Nethogs 工具查看每个进程的带宽使用情况
21. iftop - 显示主机上网络接口的带宽使用情况
iftop 命令监听指定接口(如 eth0)上的网络通信情况。它显示了一对主机的带宽使用情况。
$ sudo iftop

22. vnstat - 基于控制台的网络流量监控工具
vnstat 是一个简单易用的基于控制台的网络流量监视器,它为指定网络接口保留每小时、每天和每月网络流量日志。
$ vnstat

相关链接:
23. nmon - Linux 系统管理员的调优和基准测量工具
nmon 是 Linux 系统管理员用于性能调优的利器,它在命令行显示 CPU、内存、网络、磁盘、文件系统、NFS、消耗资源最多的进程和分区信息。
$ nmon

相关链接:安装并使用 nmon 工具来监控 Linux 系统的性能
24. glances - 密切关注 Linux 系统
glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供了大量的信息,还可以工作于客户端-服务器模式下。
$ glances

相关链接:Linux:通过 Glances 监控器密切关注您的系统
25. strace - 查看系统调用
想要跟踪 Linux 系统的调用和信号吗?试试 strace 命令吧。它对于调试网页服务器和其他服务器问题很有用。了解如何利用其 追踪进程 并查看它在做什么。
26. /proc 文件系统 - 各种内核信息
/proc 文件系统提供了不同硬件设备和 Linux 内核的详细信息。更多详细信息,请参阅 Linux 内核 /proc 文档。常见的 /proc 例子:
# cat /proc/cpuinfo
# cat /proc/meminfo
# cat /proc/zoneinfo
# cat /proc/mounts
27. Nagios - Linux 服务器和网络监控
Nagios 是一款普遍使用的开源系统和网络监控软件。您可以轻松地监控所有主机、网络设备和服务,当状态异常和恢复正常时它都会发出警报通知。FAN 是“全自动 Nagios”的缩写。FAN 的目标是提供包含由 Nagios 社区提供的大多数工具包的 Nagios 安装。FAN 提供了标准 ISO 格式的 CD-Rom 镜像,使安装变得更加容易。除此之外,为了改善 Nagios 的用户体验,发行版还包含了大量的工具。
28. Cacti - 基于 Web 的 Linux 监控工具
Cacti 是一个完整的网络图形化解决方案,旨在充分利用 RRDTool 的数据存储和图形功能。Cacti 提供了快速轮询器、高级图形模板、多种数据采集方法和用户管理功能。这些功能被包装在一个直观易用的界面中,确保可以实现从局域网到拥有数百台设备的复杂网络上的安装。它可以提供有关网络、CPU、内存、登录用户、Apache、DNS 服务器等的数据。了解如何在 CentOS / RHEL 下 安装和配置 Cacti 网络图形化工具。
29. KDE 系统监控器 - 实时系统报告和图形化显示
KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通过 ssh 会话运行。它提供了许多功能,比如可以监控本地和远程主机的客户端-服务器模式。前端图形界面使用传感器来检索信息。传感器可以返回简单的值或更复杂的信息,如表格。每种类型的信息都有一个或多个显示界面,并被组织成工作表的形式,这些工作表可以分别保存和加载。所以,KSysguard 不仅是一个简单的任务管理器,还是一个控制大型服务器平台的强大工具。

图 05:KDE System Guard {图片来源:维基百科}
详细用法,请参阅 KSysguard 手册。
30. GNOME 系统监控器
系统监控程序能够显示系统基本信息,并监控系统进程、系统资源使用情况和文件系统。您还可以用其修改系统行为。虽然不如 KDE System Guard 强大,但它提供的基本信息对新用户还是有用的:
- 显示关于计算机硬件和软件的各种基本信息
- Linux 内核版本
- GNOME 版本
- 硬件
- 安装的内存
- 处理器和速度
- 系统状况
- 可用磁盘空间
- 进程
- 内存和交换空间
- 网络使用情况
- 文件系统
- 列出所有挂载的文件系统及其基本信息

图 06:Gnome 系统监控程序
福利:其他工具
更多工具:
- nmap - 扫描服务器的开放端口
- lsof - 列出打开的文件和网络连接等
- ntop 基于网页的工具 -
ntop 是查看网络使用情况的最佳工具,与 top 命令之于进程的方式类似,即网络流量监控工具。您可以查看网络状态和 UDP、TCP、DNS、HTTP 等协议的流量分发。 - Conky - X Window 系统下的另一个很好的监控工具。它具有很高的可配置性,能够监视许多系统变量,包括 CPU 状态、内存、交换空间、磁盘存储、温度、进程、网络接口、电池、系统消息和电子邮件等。
- GKrellM - 它可以用来监控 CPU 状态、主内存、硬盘、网络接口、本地和远程邮箱及其他信息。
- mtr -
mtr 将 traceroute 和 ping 程序的功能结合在一个网络诊断工具中。 - vtop - 图形化活动监控终端
如果您有其他推荐的系统监控工具,欢迎在评论区分享。
关于作者
作者 Vivek Gite 是 nixCraft 的创建者,也是经验丰富的系统管理员,以及 Linux 操作系统和 Unix shell 脚本的培训师。他的客户遍布全球,行业涉及 IT、教育、国防航天研究以及非营利部门等。您可以在 Twitter、Facebook 和 Google+ 上关注他。
via: https://www.cyberciti.biz/tips/top-linux-monitoring-tools.html
作者:Vivek Gite 译者:jessie-pang 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出