为什么 0.1 + 0.2 = 0.30000000000000004?

嗨!昨天我试着写点关于浮点数的东西,我发现自己对这个 64 位浮点数的计算方法很好奇:
>>> 0.1 + 0.2
0.30000000000000004
我意识到我并没有完全理解它是如何计算的。我的意思是,我知道浮点计算是不精确的,你不能精确地用二进制表示 0.1,但是:肯定有一个浮点数比 0.30000000000000004 更接近 0.3!那为什么答案是 0.30000000000000004 呢?
如果你不想阅读一大堆计算过程,那么简短的答案是: 0.1000000000000000055511151231257827021181583404541015625 + 0.200000000000000011102230246251565404236316680908203125 正好位于两个浮点数之间,即 0.299999999999999988897769753748434595763683319091796875 (通常打印为 0.3) 和 0.3000000000000000444089209850062616169452667236328125(通常打印为 0.30000000000000004)。答案是 0.30000000000000004,因为它的尾数是偶数。
浮点加法是如何计算的
以下是浮点加法的简要计算原理:
- 把它们精确的数字加在一起
- 将结果四舍五入到最接近的浮点数
让我们用这些规则来计算 0.1 + 0.2。我昨天才刚了解浮点加法的计算原理,所以在这篇文章中我可能犯了一些错误,但最终我得到了期望的答案。
第一步:0.1 和 0.2 到底是多少
首先,让我们用 Python 计算 0.1 和 0.2 的 64 位浮点值。
>>> f"{0.1:.80f}"
'0.10000000000000000555111512312578270211815834045410156250000000000000000000000000'
>>> f"{0.2:.80f}"
'0.20000000000000001110223024625156540423631668090820312500000000000000000000000000'
这确实很精确:因为浮点数是二进制的,你也可以使用十进制来精确的表示。但有时你只是需要一大堆数字:)
第二步:相加
接下来,把它们加起来。我们可以将小数部分作为整数加起来得到确切的答案:
>>> 1000000000000000055511151231257827021181583404541015625 + 2000000000000000111022302462515654042363166809082031250
3000000000000000166533453693773481063544750213623046875
所以这两个浮点数的和是 0.3000000000000000166533453693773481063544750213623046875。
但这并不是最终答案,因为它不是一个 64 位浮点数。
第三步:查找最接近的浮点数
现在,让我们看看接近 0.3 的浮点数。下面是最接近 0.3 的浮点数(它通常写为 0.3,尽管它不是确切值):
>>> f"{0.3:.80f}"
'0.29999999999999998889776975374843459576368331909179687500000000000000000000000000'
我们可以通过 struct.pack 将 0.3 序列化为 8 字节来计算出它之后的下一个浮点数,加上 1,然后使用 struct.unpack:
>>> struct.pack("!d", 0.3)
b'?\xd3333333'
# 手动加 1
>>> next_float = struct.unpack("!d", b'?\xd3333334')[0]
>>> next_float
0.30000000000000004
>>> f"{next_float:.80f}"
'0.30000000000000004440892098500626161694526672363281250000000000000000000000000000'
当然,你也可以用 math.nextafter:
>>> math.nextafter(0.3, math.inf)
0.30000000000000004
所以 0.3 附近的两个 64 位浮点数是 0.299999999999999988897769753748434595763683319091796875 和 0.3000000000000000444089209850062616169452667236328125。
第四步:找出哪一个最接近
结果证明 0.3000000000000000166533453693773481063544750213623046875 正好在 0.299999999999999988897769753748434595763683319091796875 和 0.3000000000000000444089209850062616169452667236328125 的中间。
你可以通过以下计算看到:
>>> (3000000000000000444089209850062616169452667236328125000 + 2999999999999999888977697537484345957636833190917968750) // 2 == 3000000000000000166533453693773481063544750213623046875
True
所以它们都不是最接近的。
如何知道四舍五入到哪一个?
在浮点数的二进制表示中,有一个数字称为“尾数”。这种情况下(结果正好在两个连续的浮点数之间),它将四舍五入到偶数尾数的那个。
在本例中为 0.300000000000000044408920985006261616945266723632812500。
我们之前就见到了这个数字的尾数:
- 0.30000000000000004 是
struct.unpack('!d', b'?\xd3333334')的结果 - 0.3 是
struct.unpack('!d', b'?\xd3333333')的结果
0.30000000000000004 的大端十六进制表示的最后一位数字是 4,它的尾数是偶数(因为尾数在末尾)。
我们用二进制来算一下
之前我们都是使用十进制来计算的,这样读起来更直观。但是计算机并不会使用十进制,而是用 2 进制,所以我想知道它是如何计算的。
我不认为本文的二进制计算部分特别清晰,但它写出来对我很有帮助。有很多数字,读起来可能很糟糕。
64 位浮点数如何计算:指数和尾数
64 位浮点数由 2 部分整数构成:指数和尾数,还有 1 比特 符号位.
以下是指数和尾数对应于实际数字的方程:
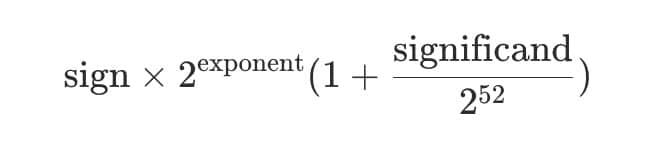
例如,如果指数是 1,尾数是 2**51,符号位是正的,那么就可以得到:
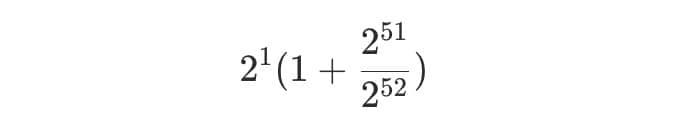
它等于 2 * (1 + 0.5),即 3。
步骤 1:获取 0.1 和 0.2 的指数和尾数
我用 Python 编写了一些低效的函数来获取正浮点数的指数和尾数:
def get_exponent(f):
# 获取前 52 个字节
bytestring = struct.pack('!d', f)
return int.from_bytes(bytestring, byteorder='big') >> 52
def get_significand(f):
# 获取后 52 个字节
bytestring = struct.pack('!d', f)
x = int.from_bytes(bytestring, byteorder='big')
exponent = get_exponent(f)
return x ^ (exponent << 52)
我忽略了符号位(第一位),因为我们只需要处理 0.1 和 0.2,它们都是正数。
首先,让我们获取 0.1 的指数和尾数。我们需要减去 1023 来得到实际的指数,因为浮点运算就是这么计算的。
>>> get_exponent(0.1) - 1023
-4
>>> get_significand(0.1)
2702159776422298
它们根据 2**指数 + 尾数 / 2**(52 - 指数) 这个公式得到 0.1。
下面是 Python 中的计算:
>>> 2**-4 + 2702159776422298 / 2**(52 + 4)
0.1
(你可能会担心这种计算的浮点精度问题,但在本例中,我很确定它没问题。因为根据定义,这些数字没有精度问题 -- 从 2**-4 开始的浮点数以 1/2**(52 + 4) 步长递增。)
0.2 也一样:
>>> get_exponent(0.2) - 1023
-3
>>> get_significand(0.2)
2702159776422298
它们共同工作得到 0.2:
>>> 2**-3 + 2702159776422298 / 2**(52 + 3)
0.2
(顺便说一下,0.1 和 0.2 具有相同的尾数并不是巧合 —— 因为 x 和 2*x 总是有相同的尾数。)
步骤 2:重新计算 0.1 以获得更大的指数
0.2 的指数比 0.1 大 -- -3 大于 -4。
所以我们需要重新计算:
2**-4 + 2702159776422298 / 2**(52 + 4)
等于 X / 2**(52 + 3)
如果我们解出 2**-4 + 2702159776422298 / 2**(52 + 4) = X / 2**(52 + 3),我们能得到:
X = 2**51 + 2702159776422298 / 2
在 Python 中,我们很容易得到:
>>> 2**51 + 2702159776422298 //2
3602879701896397
步骤 3:添加符号位
现在我们试着做加法:
2**-3 + 2702159776422298 / 2**(52 + 3) + 3602879701896397 / 2**(52 + 3)
我们需要将 2702159776422298 和 3602879701896397 相加:
>>> 2702159776422298 + 3602879701896397
6305039478318695
棒。但是 6305039478318695 比 2**52-1(尾数的最大值)大,问题来了:
>>> 6305039478318695 > 2**52
True
第四步:增加指数
目前结果是:
2**-3 + 6305039478318695 / 2**(52 + 3)
首先,它减去 2**52:
2**-2 + 1801439850948199 / 2**(52 + 3)
完美,但最后的 2**(52 + 3) 需要改为 2**(52 + 2)。
我们需要将 1801439850948199 除以 2。这就是难题的地方 -- 1801439850948199 是一个奇数!
>>> 1801439850948199 / 2
900719925474099.5
它正好在两个整数之间,所以我们四舍五入到最接近它的偶数(这是浮点运算规范要求的),所以最终的浮点结果是:
>>> 2**-2 + 900719925474100 / 2**(52 + 2)
0.30000000000000004
它就是我们预期的结果:
>>> 0.1 + 0.2
0.30000000000000004
在硬件中它可能并不是这样工作的
在硬件中做浮点数加法,以上操作方式可能并不完全一模一样(例如,它并不是求解 “X”),我相信有很多有效的技巧,但我认为思想是类似的。
打印浮点数是非常奇怪的
我们之前说过,浮点数 0.3 不等于 0.3。它实际上是:
>>> f"{0.3:.80f}"
'0.29999999999999998889776975374843459576368331909179687500000000000000000000000000'
但是当你打印它时,为什么会显示 0.3?
计算机实际上并没有打印出数字的精确值,而是打印出了最短的十进制数 d,其中 f 是最接近 d 的浮点数。
事实证明,有效做到这一点很不简单,有很多关于它的学术论文,比如 快速且准确地打印浮点数、如何准确打印浮点数 等。
如果计算机打印出浮点数的精确值,会不会更直观一些?
四舍五入到一个干净的十进制值很好,但在某种程度上,我觉得如果计算机只打印一个浮点数的精确值可能会更直观 -- 当你得到一个奇怪的结果时,它可能会让你看起来不那么惊讶。
对我来说,0.1000000000000000055511151231257827021181583404541015625 + 0.200000000000000011102230246251565404236316680908203125 = 0.3000000000000000444089209850062616169452667236328125 比 0.1 + 0.2 = 0.30000000000000000004 惊讶少一点。
这也许是一个坏主意,因为它肯定会占用大量的屏幕空间。
PHP 快速说明
有人在评论中指出在 PHP 中 <?php echo (0.1 + 0.2 );?> 会输出 0.3,这是否说明在 PHP 中浮点运算不一样?
非也 —— 我在 这里 运行:
<?php echo (0.1 + 0.2 )- 0.3);?>,得到了与 Python 完全相同的答案:5.5511151231258E-17。因此,浮点运算的基本原理是一样的。
我认为在 PHP 中 0.1 + 0.2 输出 0.3 的原因是 PHP 显示浮点数的算法没有 Python 精确 —— 即使这个数字不是最接近 0.3 的浮点数,它也会显示 0.3。
总结
我有点怀疑是否有人能耐心完成以上所有些算术,但它写出来对我很有帮助,所以我还是发表了这篇文章,希望它能有所帮助。
(题图:MJ/53e9a241-14c6-4dc7-87d0-f9801cd2d7ab)
via: https://jvns.ca/blog/2023/02/08/why-does-0-1-plus-0-2-equal-0-30000000000000004/
作者:Julia Evans 选题:lkxed 译者:MjSeven 校对:wxy
