Linux 系统中使用 logwatch 监控日志文件
Linux 操作系统和许多应用程序会创建特殊的文件来记录它们的运行事件,这些文件通常被称作“日志”。当要了解操作系统或第三方应用程序的行为或进行故障排查时,这些系统日志或特定的应用程序日志文件是必不可少的的工具。但是,日志文件并没有您们所谓的“清晰”或“容易”这种程度的可读性。手工分析原始的日志文件简直是浪费时间,并且单调乏味。出于这个原因,对于系统管理员来说,发现任何一款能把原始的日志文件转换成更人性化的记录摘要的工具,将会受益无穷。

logwatch 是一款用 Perl 语言编写的开源日志解析分析器。它能对原始的日志文件进行解析并转换成结构化格式的文档,也能根据您的使用情况和需求来定制报告。logwatch 的主要目的是生成更易于使用的日志摘要,并不是用来对日志进行实时的处理和监控的。正因为如此,logwatch 通常被设定好时间和频率的自动定时任务来调度运行或者是有需要日志处理的时候从命令行里手动运行。一旦日志报告生成,logwatch 可以通过电子邮件把这报告发送给您,您可以把它保存成文件或者直接显示在屏幕上。
Logwatch 报告的详细程度和报告覆盖范围是完全可定制化的。Logwatch 的日志处理引擎也是可扩展的,从某种意义上来说,如果您想在一个新的应用程序中使用 logwatch 功能的话,只需要为这个应用程序的日志文件编写一个日志处理脚本(使用 Perl 语言),然后挂接到 logwatch 上就行。
logwatch 有一点不好的就是,在它生成的报告中没有详细的时间戳信息,而原来的日志文件中是存在的。您只能知道被记录下来的一段时间之内的特定事件,如果想要知道精确的时间点的信息,就不得不去查看原日志文件了。
安装 Logwatch
在 Debian 系统或其派生的系统上:
# aptitude install logwatch
在基于 Red Hat 的发布系统上:
# yum install logwatch
配置 Logwatch
安装时,主要的配置文件(logwatch.conf)被放到 /etc/logwatch/conf 目录中。此文件(默认是空的)定义的设置选项会覆盖掉定义在 /usr/share/logwatch/default.conf/logwatch.conf 文件中的系统级设置。
在命令行中,启动 logwatch, 如果不带参数的话,将会使用 /etc/logwatch/conf/logwatch.conf 文件中定义的选项。但,只要一指定参数,它们就会覆盖 /etc/logwatch/conf/logwatch.conf 文件中的任意默认/自定义设置。
这篇文章里,我们会编辑 /etc/logwatch/conf/logwatch.conf 文件来对一些默认的设置项做些个性化设置。
Detail = <Low, Med, High, 或数字>
“Detail” 配置指令控制着 logwatch 报告的详细程度。它可以是个正整数,也可以是分别代表着10、5和0数字的 High、Med、Low 几个选项。
MailTo = [email protected]
如果您让把一份 logwatch 的报告邮件给您,就要使用 “MailTo” 这个配置指令。要把一份报告发送给多个用户,只需要把他们的邮件地址用空格格开,然后配置上去。但是,您需要在 logwatch 运行的服务器上配置好本地邮件传输代理(MTA)如,sendmail、 Postfix 等,这个配置指令项才能起作用。
Range = <Yesterday|Today|All>
"Range" 配置指令定义了生成 logwatch 报告的时间段信息。这个指令通常可选的值是 Yesterday、Today、All。当作用了“Rang = All”时,“Archive = yes” 这个指令项也必须配置上,那么所有的已存档的日志文件 (比如,/var/log/maillog、/var/log/maillog.X 或 /var/log/maillog.X.gz 文件)都会被处理到。
除了这些通用的 range 值,您也可以使用复杂点的选择值,如下所示:
- Range = "2 hours ago for that hour"
- Range = "-5 days"
- Range = "between -7 days and -3 days"
- Range = "since September 15, 2014"
- Range = "first Friday in October"
- Range = "2014/10/15 12:50:15 for that second"
要使用上面例子中自由形式的 range,您需要从 CPAN(注:Comprehensive Perl Archive Network) 上下载安装 Perl 的 Date::Manip 模块。关于 CPAN 模块的安装说明,请请参阅此帖 。
Service = <service-name-1>
Service = <service-name-2>
. . .
“Service” 选项指定想要监控的一个或多个服务。在 /usr/share/logwatch/scripts/services 目录下列出的服务都能被监控,它们已经涵盖了重要的系统服务(例如:pam,secure,iptables,syslogd 等),也涵盖了一些像 sudo、sshd、http、fail2ban、samba等主流的应用服务。如果您想添加新的服务到列表中,得编写一个相应的日志处理 Perl 脚本,并把它放在这个目录中。
如果这个选项要用来选择特定的服务话,您需要把 /usr/share/logwatch/default.conf/logwatch.conf 文件中的 "Service = All " 这一行注释掉。

Format = <text|html>
“Format” 配置指令定义了一份 logwatch 报告的格式(比如 text 或者 HTML)。
Output = <file|mail|stdout>
"Output" 配置指令定义生成的 logwatch 报告要发送的目的地。它能被保存成文件(file),生成电子邮件(mail)或者是直接在屏幕上显示(stdout)。
用 Logwatch 来分析日志文件
要弄明白怎么使用 logwatch 来分析日志文件,可以参考下面的 logwatch.conf 文件例子:
Detail = High
MailTo = [email protected]
Range = Today
Service = http
Service = postfix
Service = zz-disk_space
Format = html
Output = mail
使用这些设置,logwatch 将会处理三个应用服务(http、postfix 和 zz-disk\_space)当天产生的日志,生成一份非常详细的 HTML 格式报告,然后邮件给您。
如果您不想个性化 /etc/logwatch/conf/logwatch.conf,您可以不修改此文件让其默认,然后在命令行里运行如下所示的命令。也会得到同样的输出。
# logwatch --detail 10 --mailto [email protected] --range today --service http --service postfix --service zz-disk_space --format html --output mail
电子邮件发送的报告样子如图示:
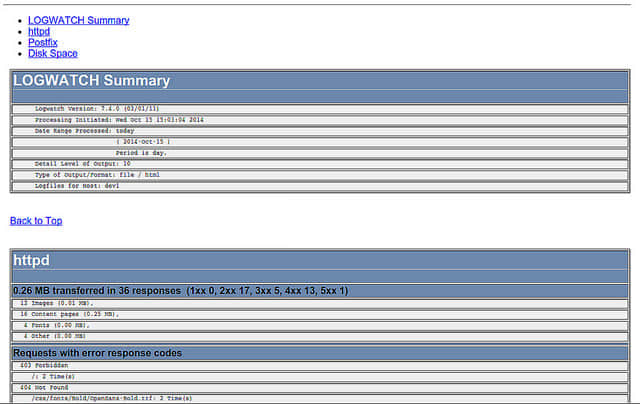
这份电子邮件头部包含指向导航到报告细节的链接,在每个选中的服务细节,也会有“返回顶部”的链接。
接收人很少的情况下您可能会使用电子邮件发送报告这个选项。其它情况下,您可能会把让其生成为 HTML 格式的报告,这样每个想看这份报告的人都可以从网络共享里看到。只需要把上面例子中的配置做些修改就可以实现:
Detail = High
Range = Today
Service = http
Service = postfix
Service = zz-disk_space
Format = html
Output = file
Filename = /var/www/html/logs/dev1.html
同样的,也可以在命令行中运行如下的命令。
# logwatch --detail 10 --range today --service http --service postfix --service zz-disk_space --format html --output file --filename /var/www/html/logs/dev1.html
最后,让我们使用 cron 来配置 logwatch 的定时执行任务。下面的例子中,将会在每个工作日的下午 12:15 分运行 logwatch 调度任务。
# crontab -e
15 12 * * 1,2,3,4,5 /sbin/logwatch
希望这会有所帮助。欢迎到社区发表评论或分享自己的心得和体会!
via: http://xmodulo.com/monitor-log-file-linux-logwatch.html
作者:Gabriel Cánepa 译者:runningwater 校对:wxy











 使用Linux watch命令监测syslog
使用Linux watch命令监测syslog 带管道的watch命令
带管道的watch命令