详解 Linux 中的虚拟文件系统
虚拟文件系统是一种神奇的抽象,它使得 “一切皆文件” 哲学在 Linux 中成为了可能。

什么是文件系统?根据早期的 Linux 贡献者和作家 Robert Love 所说,“文件系统是一个遵循特定结构的数据的分层存储。” 不过,这种描述也同样适用于 VFAT( 虚拟文件分配表 )、Git 和Cassandra(一种 NoSQL 数据库)。那么如何区别文件系统呢?
文件系统基础概念
Linux 内核要求文件系统必须是实体,它还必须在持久对象上实现 open()、read() 和 write() 方法,并且这些实体需要有与之关联的名字。从 面向对象编程 的角度来看,内核将通用文件系统视为一个抽象接口,这三大函数是“虚拟”的,没有默认定义。因此,内核的默认文件系统实现被称为虚拟文件系统(VFS)。

如果我们能够 open()、read() 和 write(),它就是一个文件,如这个主控台会话所示。
VFS 是著名的类 Unix 系统中 “一切皆文件” 概念的基础。让我们看一下它有多奇怪,上面的小小演示体现了字符设备 /dev/console 实际的工作。该图显示了一个在虚拟电传打字控制台(tty)上的交互式 Bash 会话。将一个字符串发送到虚拟控制台设备会使其显示在虚拟屏幕上。而 VFS 甚至还有其它更奇怪的属性。例如,它可以在其中寻址。
我们熟悉的文件系统如 ext4、NFS 和 /proc 都在名为 file\_operations 的 C 语言数据结构中提供了三大函数的定义。此外,个别的文件系统会以熟悉的面向对象的方式扩展和覆盖了 VFS 功能。正如 Robert Love 指出的那样,VFS 的抽象使 Linux 用户可以轻松地将文件复制到(或复制自)外部操作系统或抽象实体(如管道),而无需担心其内部数据格式。在用户空间这一侧,通过系统调用,进程可以使用文件系统方法之一 read() 从文件复制到内核的数据结构中,然后使用另一种文件系统的方法 write() 输出数据。
属于 VFS 基本类型的函数定义本身可以在内核源代码的 fs/*.c 文件 中找到,而 fs/ 的子目录中包含了特定的文件系统。内核还包含了类似文件系统的实体,例如 cgroup、/dev 和 tmpfs,在引导过程的早期需要它们,因此定义在内核的 init/ 子目录中。请注意,cgroup、/dev 和 tmpfs 不会调用 file_operations 的三大函数,而是直接读取和写入内存。
下图大致说明了用户空间如何访问通常挂载在 Linux 系统上的各种类型文件系统。像管道、dmesg 和 POSIX 时钟这样的结构在此图中未显示,它们也实现了 struct file_operations,而且其访问也要通过 VFS 层。

VFS 是个“垫片层”,位于系统调用和特定 file_operations 的实现(如 ext4 和 procfs)之间。然后,file_operations 函数可以与特定于设备的驱动程序或内存访问器进行通信。tmpfs、devtmpfs 和 cgroup 不使用 file_operations 而是直接访问内存。
VFS 的存在促进了代码重用,因为与文件系统相关的基本方法不需要由每种文件系统类型重新实现。代码重用是一种被广泛接受的软件工程最佳实践!唉,但是如果重用的代码引入了严重的错误,那么继承常用方法的所有实现都会受到影响。
/tmp:一个小提示
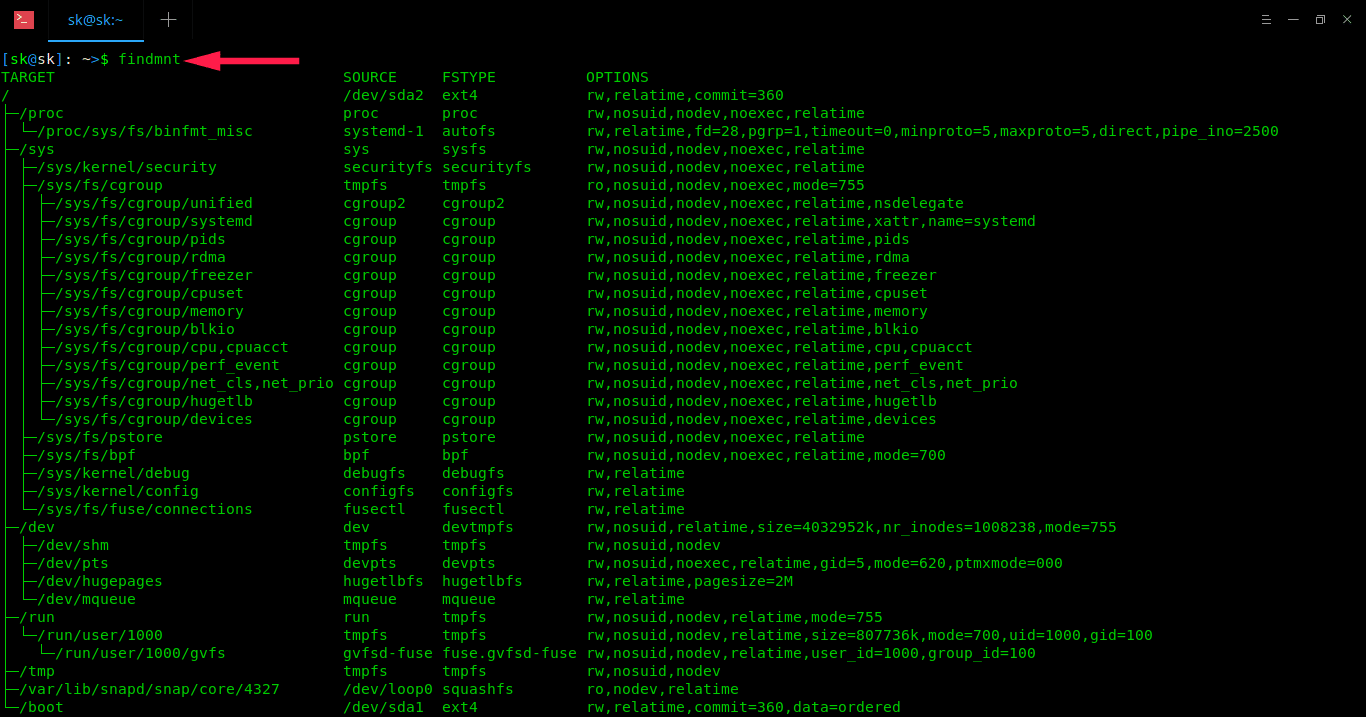
找出系统中存在的 VFS 的简单方法是键入 mount | grep -v sd | grep -v :/,在大多数计算机上,它将列出所有未驻留在磁盘上,同时也不是 NFS 的已挂载文件系统。其中一个列出的 VFS 挂载肯定是 /tmp,对吧?

谁都知道把 /tmp 放在物理存储设备上简直是疯了!图片:https://tinyurl.com/ybomxyfo
为什么把 /tmp 留在存储设备上是不可取的?因为 /tmp 中的文件是临时的(!),并且存储设备比内存慢,所以创建了 tmpfs 这种文件系统。此外,比起内存,物理设备频繁写入更容易磨损。最后,/tmp 中的文件可能包含敏感信息,因此在每次重新启动时让它们消失是一项功能。
不幸的是,默认情况下,某些 Linux 发行版的安装脚本仍会在存储设备上创建 /tmp。如果你的系统出现这种情况,请不要绝望。按照一直优秀的 Arch Wiki 上的简单说明来解决问题就行,记住分配给 tmpfs 的内存就不能用于其他目的了。换句话说,包含了大文件的庞大的 tmpfs 可能会让系统耗尽内存并崩溃。
另一个提示:编辑 /etc/fstab 文件时,请务必以换行符结束,否则系统将无法启动。(猜猜我怎么知道。)
/proc 和 /sys
除了 /tmp 之外,大多数 Linux 用户最熟悉的 VFS 是 /proc 和 /sys。(/dev 依赖于共享内存,而没有 file_operations 结构)。为什么有两种呢?让我们来看看更多细节。
procfs 为用户空间提供了内核及其控制的进程的瞬时状态的快照。在 /proc 中,内核发布有关其提供的设施的信息,如中断、虚拟内存和调度程序。此外,/proc/sys 是存放可以通过 sysctl 命令配置的设置的地方,可供用户空间访问。单个进程的状态和统计信息在 /proc/<PID> 目录中报告。

/proc/meminfo 是一个空文件,但仍包含有价值的信息。
/proc 文件的行为说明了 VFS 可以与磁盘上的文件系统不同。一方面,/proc/meminfo 包含了可由命令 free 展现出来的信息。另一方面,它还是空的!怎么会这样?这种情况让人联想起康奈尔大学物理学家 N. David Mermin 在 1985 年写的一篇名为《没有人看见月亮的情况吗?现实和量子理论》。事实是当进程从 /proc 请求数据时内核再收集有关内存的统计信息,而且当没有人查看它时,/proc 中的文件实际上没有任何内容。正如 Mermin 所说,“这是一个基本的量子学说,一般来说,测量不会揭示被测属性的预先存在的价值。”(关于月球的问题的答案留作练习。)

当没有进程访问它们时,/proc 中的文件为空。(来源)
procfs 的空文件是有道理的,因为那里可用的信息是动态的。sysfs 的情况则不同。让我们比较一下 /proc 与 /sys 中不为空的文件数量。

procfs 只有一个不为空的文件,即导出的内核配置,这是一个例外,因为每次启动只需要生成一次。另一方面,/sys 有许多更大一些的文件,其中大多数由一页内存组成。通常,sysfs 文件只包含一个数字或字符串,与通过读取 /proc/meminfo 等文件生成的信息表格形成鲜明对比。
sysfs 的目的是将内核称为 “kobject” 的可读写属性公开给用户空间。kobject 的唯一目的是引用计数:当删除对 kobject 的最后一个引用时,系统将回收与之关联的资源。然而,/sys 构成了内核著名的“到用户空间的稳定 ABI”,它的大部分内容在任何情况下都没有人能“破坏”。但这并不意味着 sysfs 中的文件是静态,这与易失性对象的引用计数相反。
内核的稳定 ABI 限制了 /sys 中可能出现的内容,而不是任何给定时刻实际存在的内容。列出 sysfs 中文件的权限可以了解如何设置或读取设备、模块、文件系统等的可配置、可调参数。逻辑上强调 procfs 也是内核稳定 ABI 的一部分的结论,尽管内核的文档没有明确说明。

sysfs 中的文件确切地描述了实体的每个属性,并且可以是可读的、可写的,或两者兼而有之。文件中的“0”表示 SSD 不可移动的存储设备。
用 eBPF 和 bcc 工具一窥 VFS 内部
了解内核如何管理 sysfs 文件的最简单方法是观察它的运行情况,在 ARM64 或 x86\_64 上观看的最简单方法是使用 eBPF。eBPF( 扩展的伯克利数据包过滤器 )由在内核中运行的虚拟机组成,特权用户可以从命令行进行查询。内核源代码告诉读者内核可以做什么;而在一个启动的系统上运行 eBPF 工具会显示内核实际上做了什么。
令人高兴的是,通过 bcc 工具入门使用 eBPF 非常容易,这些工具在主要 Linux 发行版的软件包 中都有,并且已经由 Brendan Gregg 给出了充分的文档说明。bcc 工具是带有小段嵌入式 C 语言片段的 Python 脚本,这意味着任何对这两种语言熟悉的人都可以轻松修改它们。据当前统计,bcc/tools 中有 80 个 Python 脚本,使得系统管理员或开发人员很有可能能够找到与她/他的需求相关的已有脚本。
要了解 VFS 在正在运行中的系统上的工作情况,请尝试使用简单的 vfscount 或 vfsstat 脚本,这可以看到每秒都会发生数十次对 vfs_open() 及其相关的调用。

vfsstat.py 是一个带有嵌入式 C 片段的 Python 脚本,它只是计数 VFS 函数调用。
作为一个不太重要的例子,让我们看一下在运行的系统上插入 USB 记忆棒时 sysfs 中会发生什么。

用 eBPF 观察插入 USB 记忆棒时 /sys 中会发生什么,简单的和复杂的例子。
在上面的第一个简单示例中,只要 sysfs_create_files() 命令运行,trace.py bcc 工具脚本就会打印出一条消息。我们看到 sysfs_create_files() 由一个 kworker 线程启动,以响应 USB 棒的插入事件,但是它创建了什么文件?第二个例子说明了 eBPF 的强大能力。这里,trace.py 正在打印内核回溯(-K 选项)以及 sysfs_create_files() 创建的文件的名称。单引号内的代码段是一些 C 源代码,包括一个易于识别的格式字符串,所提供的 Python 脚本引入 LLVM 即时编译器(JIT) 来在内核虚拟机内编译和执行它。必须在第二个命令中重现完整的 sysfs_create_files() 函数签名,以便格式字符串可以引用其中一个参数。在此 C 片段中出错会导致可识别的 C 编译器错误。例如,如果省略 -I 参数,则结果为“无法编译 BPF 文本”。熟悉 C 或 Python 的开发人员会发现 bcc 工具易于扩展和修改。
插入 USB 记忆棒后,内核回溯显示 PID 7711 是一个 kworker 线程,它在 sysfs 中创建了一个名为 events 的文件。使用 sysfs_remove_files() 进行相应的调用表明,删除 USB 记忆棒会导致删除该 events 文件,这与引用计数的想法保持一致。在 USB 棒插入期间(未显示)在 eBPF 中观察 sysfs_create_link() 表明创建了不少于 48 个符号链接。
无论如何,events 文件的目的是什么?使用 cscope 查找函数 __device_add_disk() 显示它调用 disk_add_events(),并且可以将 “mediachange” 或 “ejectrequest” 写入到该文件。这里,内核的块层通知用户空间该 “磁盘” 的出现和消失。考虑一下这种检查 USB 棒的插入的工作原理的方法与试图仅从源头中找出该过程的速度有多快。
只读根文件系统使得嵌入式设备成为可能
确实,没有人通过拔出电源插头来关闭服务器或桌面系统。为什么?因为物理存储设备上挂载的文件系统可能有挂起的(未完成的)写入,并且记录其状态的数据结构可能与写入存储器的内容不同步。当发生这种情况时,系统所有者将不得不在下次启动时等待 fsck 文件系统恢复工具 运行完成,在最坏的情况下,实际上会丢失数据。
然而,狂热爱好者会听说许多物联网和嵌入式设备,如路由器、恒温器和汽车现在都运行着 Linux。许多这些设备几乎完全没有用户界面,并且没有办法干净地让它们“解除启动”。想一想启动电池耗尽的汽车,其中运行 Linux 的主机设备 的电源会不断加电断电。当引擎最终开始运行时,系统如何在没有长时间 fsck 的情况下启动呢?答案是嵌入式设备依赖于只读根文件系统(简称 ro-rootfs)。

ro-rootfs 是嵌入式系统不经常需要 fsck 的原因。 来源:https://tinyurl.com/yxoauoub
ro-rootfs 提供了许多优点,虽然这些优点不如耐用性那么显然。一个是,如果 Linux 进程不可以写入,那么恶意软件也无法写入 /usr 或 /lib。另一个是,基本上不可变的文件系统对于远程设备的现场支持至关重要,因为支持人员拥有理论上与现场相同的本地系统。也许最重要(但也是最微妙)的优势是 ro-rootfs 迫使开发人员在项目的设计阶段就决定好哪些系统对象是不可变的。处理 ro-rootfs 可能经常是不方便甚至是痛苦的,编程语言中的常量变量经常就是这样,但带来的好处很容易偿还这种额外的开销。
对于嵌入式开发人员,创建只读根文件系统确实需要做一些额外的工作,而这正是 VFS 的用武之地。Linux 需要 /var 中的文件可写,此外,嵌入式系统运行的许多流行应用程序会尝试在 $HOME 中创建配置的点文件。放在家目录中的配置文件的一种解决方案通常是预生成它们并将它们构建到 rootfs 中。对于 /var,一种方法是将其挂载在单独的可写分区上,而 / 本身以只读方式挂载。使用绑定或叠加挂载是另一种流行的替代方案。
绑定和叠加挂载以及在容器中的使用
运行 man mount 是了解 绑定挂载 和 叠加挂载 的最好办法,这种方法使得嵌入式开发人员和系统管理员能够在一个路径位置创建文件系统,然后以另外一个路径将其提供给应用程序。对于嵌入式系统,这代表着可以将文件存储在 /var 中的不可写闪存设备上,但是在启动时将 tmpfs 中的路径叠加挂载或绑定挂载到 /var 路径上,这样应用程序就可以在那里随意写它们的内容了。下次加电时,/var 中的变化将会消失。叠加挂载为 tmpfs 和底层文件系统提供了联合,允许对 ro-rootfs 中的现有文件进行直接修改,而绑定挂载可以使新的空 tmpfs 目录在 ro-rootfs 路径中显示为可写。虽然叠加文件系统是一种适当的文件系统类型,而绑定挂载由 VFS 命名空间工具 实现的。
根据叠加挂载和绑定挂载的描述,没有人会对 Linux 容器 中大量使用它们感到惊讶。让我们通过运行 bcc 的 mountsnoop 工具监视当使用 systemd-nspawn 启动容器时会发生什么:

在 mountsnoop.py 运行的同时,system-nspawn 调用启动容器。
让我们看看发生了什么:

在容器 “启动” 期间运行 mountsnoop 可以看到容器运行时很大程度上依赖于绑定挂载。(仅显示冗长输出的开头)
这里,systemd-nspawn 将主机的 procfs 和 sysfs 中的选定文件按其 rootfs 中的路径提供给容器。除了设置绑定挂载时的 MS_BIND 标志之外,mount 系统调用的一些其它标志用于确定主机命名空间和容器中的更改之间的关系。例如,绑定挂载可以将 /proc 和 /sys 中的更改传播到容器,也可以隐藏它们,具体取决于调用。
总结
理解 Linux 内部结构看似是一项不可能完成的任务,因为除了 Linux 用户空间应用程序和 glibc 这样的 C 库中的系统调用接口,内核本身也包含大量代码。取得进展的一种方法是阅读一个内核子系统的源代码,重点是理解面向用户空间的系统调用和头文件以及主要的内核内部接口,这里以 file_operations 表为例。file_operations 使得“一切都是文件”得以可以实际工作,因此掌握它们收获特别大。顶级 fs/ 目录中的内核 C 源文件构成了虚拟文件系统的实现,虚拟文件系统是支持流行的文件系统和存储设备的广泛且相对简单的互操作性的垫片层。通过 Linux 命名空间进行绑定挂载和覆盖挂载是 VFS 魔术,它使容器和只读根文件系统成为可能。结合对源代码的研究,eBPF 内核工具及其 bcc 接口使得探测内核比以往任何时候都更简单。
非常感谢 Akkana Peck 和 Michael Eager 的评论和指正。
Alison Chaiken 也于 3 月 7 日至 10 日在加利福尼亚州帕萨迪纳举行的第 17 届南加州 Linux 博览会(SCaLE 17x)上演讲了本主题。
via: https://opensource.com/article/19/3/virtual-filesystems-linux
作者:Alison Chariken 选题:lujun9972 译者:wxy 校对:wxy












{kind=link}
{kind=link}
{kind=link}
{kind=link}