如果你正在运行 Swarm 模式的集群,或者只运行单台 Docker,你都会有下面的疑问:
我如何才能监控到它们都在干些什么?
这个问题的答案是“很不容易”。
你需要监控下面的参数:
- 容器的数量和状态。
- 一台容器是否已经移到另一个节点了,如果是,那是在什么时候,移动到哪个节点?
- 给定节点上运行着的容器数量。
- 一段时间内的通信峰值。
- 孤儿卷和网络(LCTT 译注:孤儿卷就是当你删除容器时忘记删除它的卷,这个卷就不会再被使用,但会一直占用资源)。
- 可用磁盘空间、可用 inode 数。
- 容器数量与连接在
docker0 和 docker_gwbridge 上的虚拟网卡数量不一致(LCTT 译注:当 docker 启动时,它会在宿主机器上创建一个名为 docker0 的虚拟网络接口)。 - 开启和关闭 Swarm 节点。
- 收集并集中处理日志。
本文的目标是介绍 Elasticsearch + Kibana + cAdvisor 的用法,使用它们来收集 Docker 容器的参数,分析数据并产生可视化报表。
阅读本文后你可以发现有一个监控仪表盘能够部分解决上述列出的问题。但如果只是使用 cAdvisor,有些参数就无法显示出来,比如 Swarm 模式的节点。
如果你有一些 cAdvisor 或其他工具无法解决的特殊需求,我建议你开发自己的数据收集器和数据处理器(比如 Beats),请注意我不会演示如何使用 Elasticsearch 来集中收集 Docker 容器的日志。
“你要如何才能监控到 Swarm 模式集群里面发生了什么事情?要做到这点很不容易。” —— @fntlnz
我们为什么要监控容器?
想象一下这个经典场景:你在管理一台或多台虚拟机,你把 tmux 工具用得很溜,用各种 session 事先设定好了所有基础的东西,包括监控。然后生产环境出问题了,你使用 top、htop、iotop、jnettop 各种 top 来排查,然后你准备好修复故障。
现在重新想象一下你有 3 个节点,包含 50 台容器,你需要在一个地方查看整洁的历史数据,这样你知道问题出在哪个地方,而不是把你的生命浪费在那些字符界面来赌你可以找到问题点。
什么是 Elastic Stack ?
Elastic Stack 就一个工具集,包括以下工具:
- Elasticsearch
- Kibana
- Logstash
- Beats
我们会使用其中一部分工具,比如使用 Elasticsearch 来分析基于 JSON 格式的文本,以及使用 Kibana 来可视化数据并产生报表。
另一个重要的工具是 Beats,但在本文中我们还是把精力放在容器上,官方的 Beats 工具不支持 Docker,所以我们选择原生兼容 Elasticsearch 的 cAdvisor。
cAdvisor 工具负责收集、整合正在运行的容器数据,并导出报表。在本文中,这些报表被到入到 Elasticsearch 中。
cAdvisor 有两个比较酷的特性:
- 它不只局限于 Docker 容器。
- 它有自己的 Web 服务器,可以简单地显示当前节点的可视化报表。
设置测试集群,或搭建自己的基础架构
和我以前的文章一样,我习惯提供一个简单的脚本,让读者不用花很多时间就能部署好和我一样的测试环境。你可以使用以下(非生产环境使用的)脚本来搭建一个 Swarm 模式的集群,其中一个容器运行着 Elasticsearch。
如果你有充足的时间和经验,你可以 搭建自己的基础架构 。
如果要继续阅读本文,你需要:
- 运行 Docker 进程的一个或多个节点(docker 版本号大于等于 1.12)。
- 至少有一个独立运行的 Elasticsearch 节点(版本号 2.4.X)。
重申一下,此 Elasticsearch 集群环境不能放在生产环境中使用。生产环境也不推荐使用单节点集群,所以如果你计划安装一个生产环境,请参考 Elastic 指南。
对喜欢尝鲜的用户的友情提示
我就是一个喜欢尝鲜的人(当然我也已经在生产环境中使用了最新的 alpha 版本),但是在本文中,我不会使用最新的 Elasticsearch 5.0.0 alpha 版本,我还不是很清楚这个版本的功能,所以我不想成为那个引导你们出错的关键。
所以本文中涉及的 Elasticsearch 版本为最新稳定版 2.4.0。
测试集群部署脚本
前面已经说过,我提供这个脚本给你们,让你们不必费神去部署 Swarm 集群和 Elasticsearch,当然你也可以跳过这一步,用你自己的 Swarm 模式引擎和你自己的 Elasticserch 节点。
执行这段脚本之前,你需要:
创建集群的脚本
现在万事俱备,你可以把下面的代码拷到 create-cluster.sh 文件中:
#!/usr/bin/env bash
#
# Create a Swarm Mode cluster with a single master and a configurable number of workers
workers=${WORKERS:-"worker1 worker2"}
#######################################
# Creates a machine on Digital Ocean
# Globals:
# DO_ACCESS_TOKEN The token needed to access DigitalOcean's API
# Arguments:
# $1 the actual name to give to the machine
#######################################
create_machine() {
docker-machine create \
-d digitalocean \
--digitalocean-access-token=$DO_ACCESS_TOKEN \
--digitalocean-size 2gb \
$1
}
#######################################
# Executes a command on the specified machine
# Arguments:
# $1 The machine on which to run the command
# $2..$n The command to execute on that machine
#######################################
machine_do() {
docker-machine ssh $@
}
main() {
if [ -z "$DO_ACCESS_TOKEN" ]; then
echo "Please export a DigitalOcean Access token: https://cloud.digitalocean.com/settings/api/tokens/new"
echo "export DO_ACCESS_TOKEN=<yourtokenhere>"
exit 1
fi
if [ -z "$WORKERS" ]; then
echo "You haven't provided your workers by setting the \$WORKERS environment variable, using the default ones: $workers"
fi
# Create the first and only master
echo "Creating the master"
create_machine master1
master_ip=$(docker-machine ip master1)
# Initialize the swarm mode on it
echo "Initializing the swarm mode"
machine_do master1 docker swarm init --advertise-addr $master_ip
# Obtain the token to allow workers to join
worker_tkn=$(machine_do master1 docker swarm join-token -q worker)
echo "Worker token: ${worker_tkn}"
# Create and join the workers
for worker in $workers; do
echo "Creating worker ${worker}"
create_machine $worker
machine_do $worker docker swarm join --token $worker_tkn $master_ip:2377
done
}
main $@
赋予它可执行权限:
chmod +x create-cluster.sh
创建集群
如文件名所示,我们可以用它来创建集群。默认情况下这个脚本会创建一个 master 和两个 worker,如果你想修改 worker 个数,可以设置环境变量 WORKERS。
现在就来创建集群吧。
./create-cluster.sh
你可以出去喝杯咖啡,因为这需要花点时间。
最后集群部署好了。
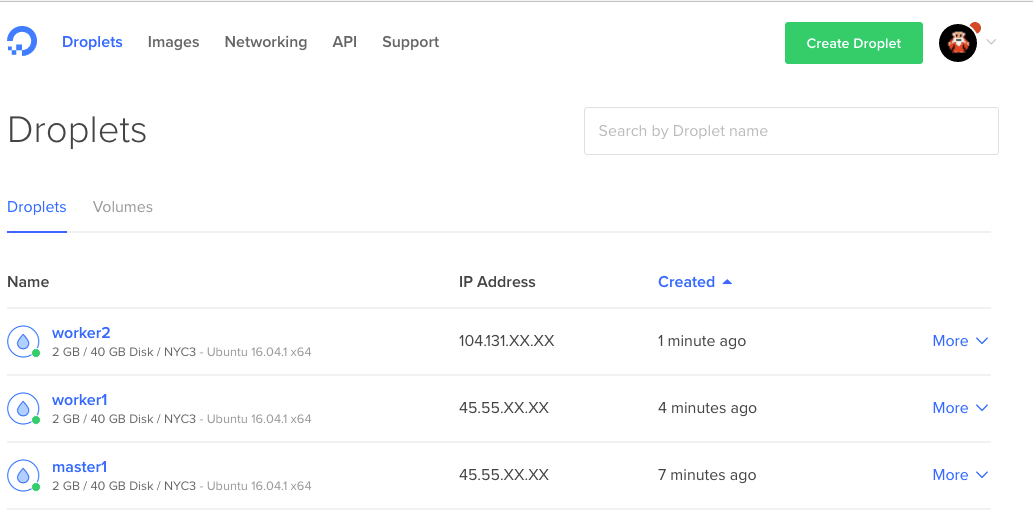
现在为了验证 Swarm 模式集群已经正常运行,我们可以通过 ssh 登录进 master:
docker-machine ssh master1
然后列出集群的节点:
docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
26fi3wiqr8lsidkjy69k031w2 * master1 Ready Active Leader
dyluxpq8sztj7kmwlzs51u4id worker2 Ready Active
epglndegvixag0jztarn2lte8 worker1 Ready Active
安装 Elasticsearch 和 Kibana
注意,从现在开始所有的命令都运行在主节点 master1 上。
在生产环境中,你可能会把 Elasticsearch 和 Kibana 安装在一个单独的、大小合适的实例集合中。但是在我们的实验中,我们还是把它们和 Swarm 模式集群安装在一起。
为了将 Elasticsearch 和 cAdvisor 连通,我们需要创建一个自定义的网络,因为我们使用了集群,并且容器可能会分布在不同的节点上,我们需要使用 overlay 网络(LCTT 译注:overlay 网络是指在不改变现有网络基础设施的前提下,通过某种约定通信协议,把二层报文封装在 IP 报文之上的新的数据格式,是目前最主流的容器跨节点数据传输和路由方案)。
也许你会问,“为什么还要网络?我们不是可以用 link 吗?” 请考虑一下,自从引入用户定义网络后,link 机制就已经过时了。
以下内容摘自 Docker 文档:
在 Docker network 特性出来以前,你可以使用 Docker link 特性实现容器互相发现、安全通信。而在 network 特性出来以后,你还可以使用 link,但是当容器处于默认桥接网络或用户自定义网络时,它们的表现是不一样的。
现在创建 overlay 网络,名称为 monitoring:
docker network create monitoring -d overlay
Elasticsearch 容器
docker service create --network=monitoring \
--mount type=volume,target=/usr/share/elasticsearch/data \
--constraint node.hostname==worker1 \
--name elasticsearch elasticsearch:2.4.0
注意 Elasticsearch 容器被限定在 worker1 节点,这是因为它运行时需要依赖 worker1 节点上挂载的卷。
Kibana 容器
docker service create --network=monitoring --name kibana -e ELASTICSEARCH_URL="http://elasticsearch:9200" -p 5601:5601 kibana:4.6.0
如你所见,我们启动这两个容器时,都让它们加入 monitoring 网络,这样一来它们可以通过名称(如 Kibana)被相同网络的其他服务访问。
现在,通过 routing mesh 机制,我们可以使用浏览器访问服务器的 IP 地址来查看 Kibana 报表界面。
获取 master1 实例的公共 IP 地址:
docker-machine ip master1
打开浏览器输入地址:http://[master1 的 ip 地址]:5601/status
所有项目都应该是绿色:
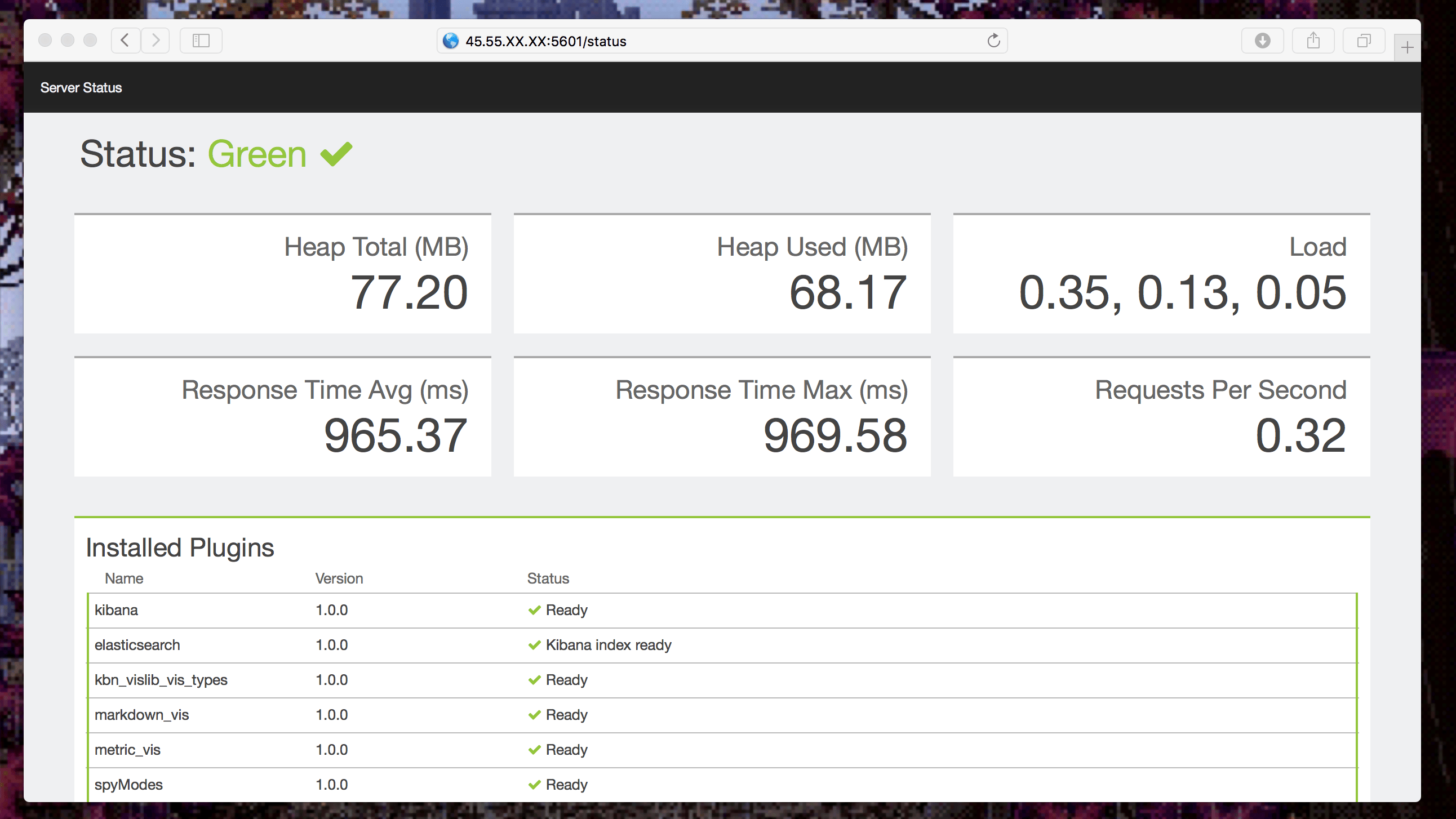
让我们接下来开始收集数据!
收集容器的运行数据
收集数据之前,我们需要创建一个服务,以全局模式运行 cAdvisor,为每个有效节点设置一个定时任务。
这个服务与 Elasticsearch 处于相同的网络,以便于 cAdvisor 可以推送数据给 Elasticsearch。
docker service create --network=monitoring --mode global --name cadvisor \
--mount type=bind,source=/,target=/rootfs,readonly=true \
--mount type=bind,source=/var/run,target=/var/run,readonly=false \
--mount type=bind,source=/sys,target=/sys,readonly=true \
--mount type=bind,source=/var/lib/docker/,target=/var/lib/docker,readonly=true \
google/cadvisor:latest \
-storage_driver=elasticsearch \
-storage_driver_es_host="http://elasticsearch:9200"
注意:如果你想配置 cAdvisor 选项,参考这里。
现在 cAdvisor 在发送数据给 Elasticsearch,我们通过定义一个索引模型来检索 Kibana 中的数据。有两种方式可以做到这一点:通过 Kibana 或者通过 API。在这里我们使用 API 方式实现。
我们需要在一个连接到 monitoring 网络的正在运行的容器中运行索引创建命令,你可以在 cAdvisor 容器中拿到 shell,不幸的是 Swarm 模式在开启服务时会在容器名称后面附加一个唯一的 ID 号,所以你需要手动指定 cAdvisor 容器的名称。
拿到 shell:
docker exec -ti <cadvisor-container-name> sh
创建索引:
curl -XPUT http://elasticsearch:9200/.kibana/index-pattern/cadvisor -d '{"title" : "cadvisor*", "timeFieldName": "container_stats.timestamp"}'
如果你够懒,可以只执行下面这一句:
docker exec $(docker ps | grep cadvisor | awk '{print $1}' | head -1) curl -XPUT http://elasticsearch:9200/.kibana/index-pattern/cadvisor -d '{"title" : "cadvisor*", "timeFieldName": "container_stats.timestamp"}'
把数据汇总成报表
你现在可以使用 Kibana 来创建一份美观的报表了。但是不要着急,我为你们建了一份报表和一些图形界面来方便你们入门。
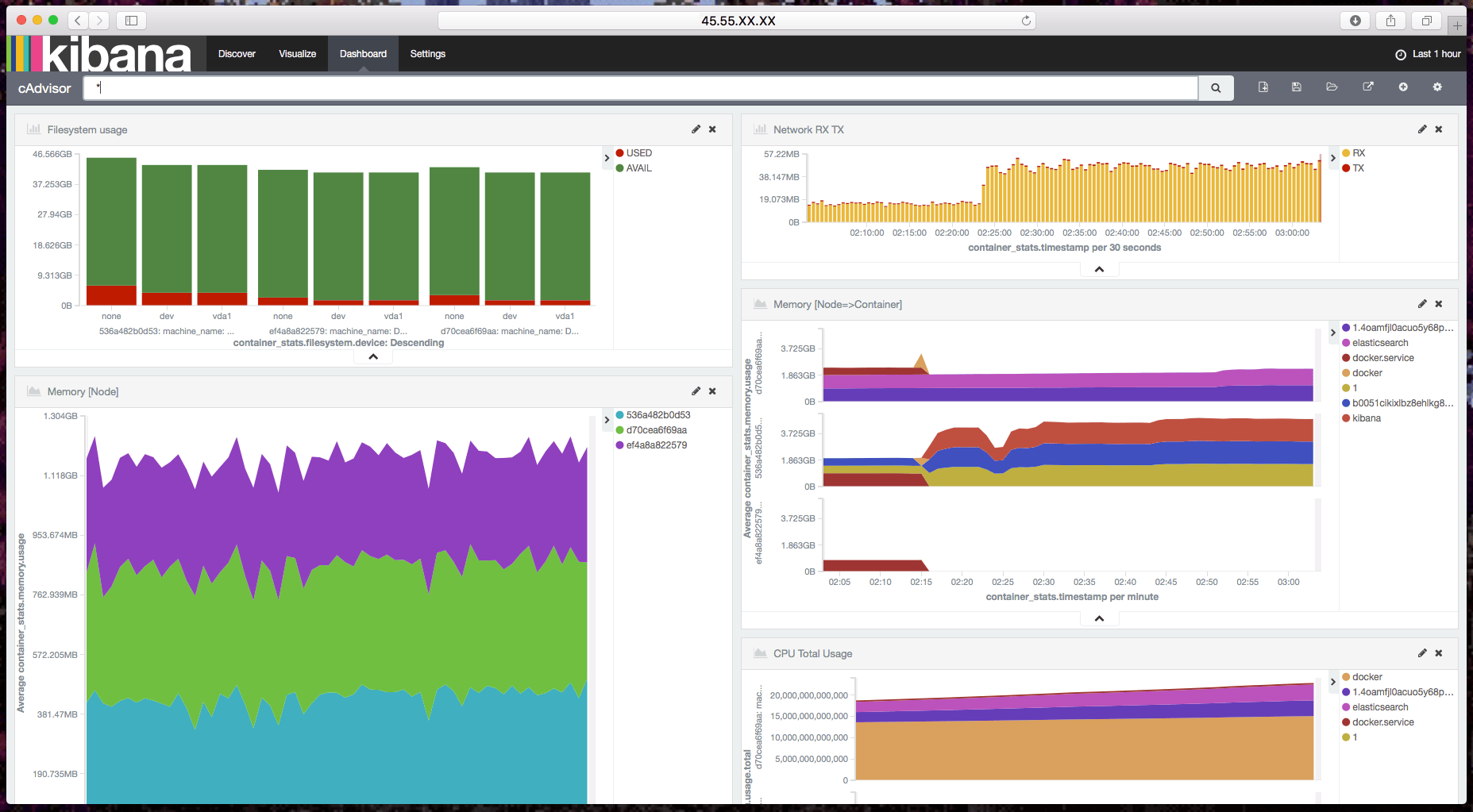
访问 Kibana 界面 => Setting => Objects => Import,然后选择包含以下内容的 JSON 文件,就可以导入我的配置信息了:
[
{
"_id": "cAdvisor",
"_type": "dashboard",
"_source": {
"title": "cAdvisor",
"hits": 0,
"description": "",
"panelsJSON": "[{\"id\":\"Filesystem-usage\",\"type\":\"visualization\",\"panelIndex\":1,\"size_x\":6,\"size_y\":3,\"col\":1,\"row\":1},{\"id\":\"Memory-[Node-equal->Container]\",\"type\":\"visualization\",\"panelIndex\":2,\"size_x\":6,\"size_y\":4,\"col\":7,\"row\":4},{\"id\":\"memory-usage-by-machine\",\"type\":\"visualization\",\"panelIndex\":3,\"size_x\":6,\"size_y\":6,\"col\":1,\"row\":4},{\"id\":\"CPU-Total-Usage\",\"type\":\"visualization\",\"panelIndex\":4,\"size_x\":6,\"size_y\":5,\"col\":7,\"row\":8},{\"id\":\"Network-RX-TX\",\"type\":\"visualization\",\"panelIndex\":5,\"size_x\":6,\"size_y\":3,\"col\":7,\"row\":1}]",
"optionsJSON": "{\"darkTheme\":false}",
"uiStateJSON": "{}",
"version": 1,
"timeRestore": false,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{\"filter\":[{\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}}}]}"
}
}
},
{
"_id": "Network",
"_type": "search",
"_source": {
"title": "Network",
"description": "",
"hits": 0,
"columns": [
"machine_name",
"container_Name",
"container_stats.network.name",
"container_stats.network.interfaces",
"container_stats.network.rx_bytes",
"container_stats.network.rx_packets",
"container_stats.network.rx_dropped",
"container_stats.network.rx_errors",
"container_stats.network.tx_packets",
"container_stats.network.tx_bytes",
"container_stats.network.tx_dropped",
"container_stats.network.tx_errors"
],
"sort": [
"container_stats.timestamp",
"desc"
],
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"analyze_wildcard\":true,\"query\":\"*\"}},\"highlight\":{\"pre_tags\":[\"@kibana-highlighted-field@\"],\"post_tags\":[\"@/kibana-highlighted-field@\"],\"fields\":{\"*\":{}},\"fragment_size\":2147483647},\"filter\":[]}"
}
}
},
{
"_id": "Filesystem-usage",
"_type": "visualization",
"_source": {
"title": "Filesystem usage",
"visState": "{\"title\":\"Filesystem usage\",\"type\":\"histogram\",\"params\":{\"addLegend\":true,\"addTimeMarker\":false,\"addTooltip\":true,\"defaultYExtents\":false,\"mode\":\"stacked\",\"scale\":\"linear\",\"setYExtents\":false,\"shareYAxis\":true,\"times\":[],\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.filesystem.usage\",\"customLabel\":\"USED\"}},{\"id\":\"2\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":false}},{\"id\":\"3\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.filesystem.capacity\",\"customLabel\":\"AVAIL\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.filesystem.device\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}}],\"listeners\":{}}",
"uiStateJSON": "{\"vis\":{\"colors\":{\"Average container_stats.filesystem.available\":\"#E24D42\",\"Average container_stats.filesystem.base_usage\":\"#890F02\",\"Average container_stats.filesystem.capacity\":\"#3F6833\",\"Average container_stats.filesystem.usage\":\"#E24D42\",\"USED\":\"#BF1B00\",\"AVAIL\":\"#508642\"}}}",
"description": "",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"analyze_wildcard\":true,\"query\":\"*\"}},\"filter\":[]}"
}
}
},
{
"_id": "CPU-Total-Usage",
"_type": "visualization",
"_source": {
"title": "CPU Total Usage",
"visState": "{\"title\":\"CPU Total Usage\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.cpu.usage.total\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"container_Name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":true}}],\"listeners\":{}}",
"uiStateJSON": "{}",
"description": "",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}},\"filter\":[]}"
}
}
},
{
"_id": "memory-usage-by-machine",
"_type": "visualization",
"_source": {
"title": "Memory [Node]",
"visState": "{\"title\":\"Memory [Node]\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.memory.usage\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}}],\"listeners\":{}}",
"uiStateJSON": "{}",
"description": "",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"*\",\"analyze_wildcard\":true}},\"filter\":[]}"
}
}
},
{
"_id": "Network-RX-TX",
"_type": "visualization",
"_source": {
"title": "Network RX TX",
"visState": "{\"title\":\"Network RX TX\",\"type\":\"histogram\",\"params\":{\"addLegend\":true,\"addTimeMarker\":true,\"addTooltip\":true,\"defaultYExtents\":false,\"mode\":\"stacked\",\"scale\":\"linear\",\"setYExtents\":false,\"shareYAxis\":true,\"times\":[],\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.network.rx_bytes\",\"customLabel\":\"RX\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"s\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.network.tx_bytes\",\"customLabel\":\"TX\"}}],\"listeners\":{}}",
"uiStateJSON": "{\"vis\":{\"colors\":{\"RX\":\"#EAB839\",\"TX\":\"#BF1B00\"}}}",
"description": "",
"savedSearchId": "Network",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{\"filter\":[]}"
}
}
},
{
"_id": "Memory-[Node-equal->Container]",
"_type": "visualization",
"_source": {
"title": "Memory [Node=>Container]",
"visState": "{\"title\":\"Memory [Node=>Container]\",\"type\":\"area\",\"params\":{\"shareYAxis\":true,\"addTooltip\":true,\"addLegend\":true,\"smoothLines\":false,\"scale\":\"linear\",\"interpolate\":\"linear\",\"mode\":\"stacked\",\"times\":[],\"addTimeMarker\":false,\"defaultYExtents\":false,\"setYExtents\":false,\"yAxis\":{}},\"aggs\":[{\"id\":\"1\",\"type\":\"avg\",\"schema\":\"metric\",\"params\":{\"field\":\"container_stats.memory.usage\"}},{\"id\":\"2\",\"type\":\"date_histogram\",\"schema\":\"segment\",\"params\":{\"field\":\"container_stats.timestamp\",\"interval\":\"auto\",\"customInterval\":\"2h\",\"min_doc_count\":1,\"extended_bounds\":{}}},{\"id\":\"3\",\"type\":\"terms\",\"schema\":\"group\",\"params\":{\"field\":\"container_Name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\"}},{\"id\":\"4\",\"type\":\"terms\",\"schema\":\"split\",\"params\":{\"field\":\"machine_name\",\"size\":5,\"order\":\"desc\",\"orderBy\":\"1\",\"row\":true}}],\"listeners\":{}}",
"uiStateJSON": "{}",
"description": "",
"version": 1,
"kibanaSavedObjectMeta": {
"searchSourceJSON": "{\"index\":\"cadvisor*\",\"query\":{\"query_string\":{\"query\":\"* NOT container_Name.raw: \\\\\\\"/\\\\\\\" AND NOT container_Name.raw: \\\\\\\"/docker\\\\\\\"\",\"analyze_wildcard\":true}},\"filter\":[]}"
}
}
}
]
这里还有很多东西可以玩,你也许想自定义报表界面,比如添加内存页错误状态,或者收发包的丢包数。如果你能实现开头列表处我没能实现的项目,那也是很好的。
总结
正确监控需要大量时间和精力,容器的 CPU、内存、IO、网络和磁盘,监控的这些参数还只是整个监控项目中的沧海一粟而已。
我不知道你做到了哪一阶段,但接下来的任务也许是:
- 收集运行中的容器的日志
- 收集应用的日志
- 监控应用的性能
- 报警
- 监控健康状态
如果你有意见或建议,请留言。祝你玩得开心。
现在你可以关掉这些测试系统了:
docker-machine rm master1 worker{1,2}
via: https://blog.codeship.com/monitoring-docker-containers-with-elasticsearch-and-cadvisor/
作者:Lorenzo Fontana 译者:bazz2 校对:wxy
本文由 LCTT 原创编译,Linux中国 荣誉推出